Visual-Redundancy-Controlled Parallel Decoding for Diffusion-Based Multimodal Large Language Models
Pith reviewed 2026-06-29 23:07 UTC · model grok-4.3
The pith
Diffusion-based multimodal models gain accuracy when parallel decoding selects tokens with non-overlapping visual grounding.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
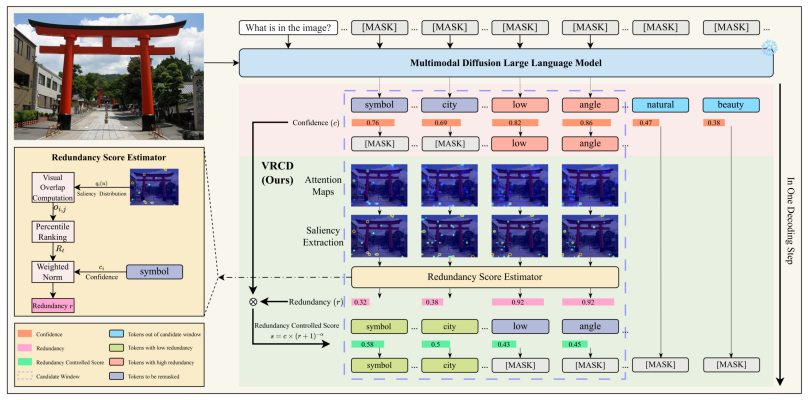
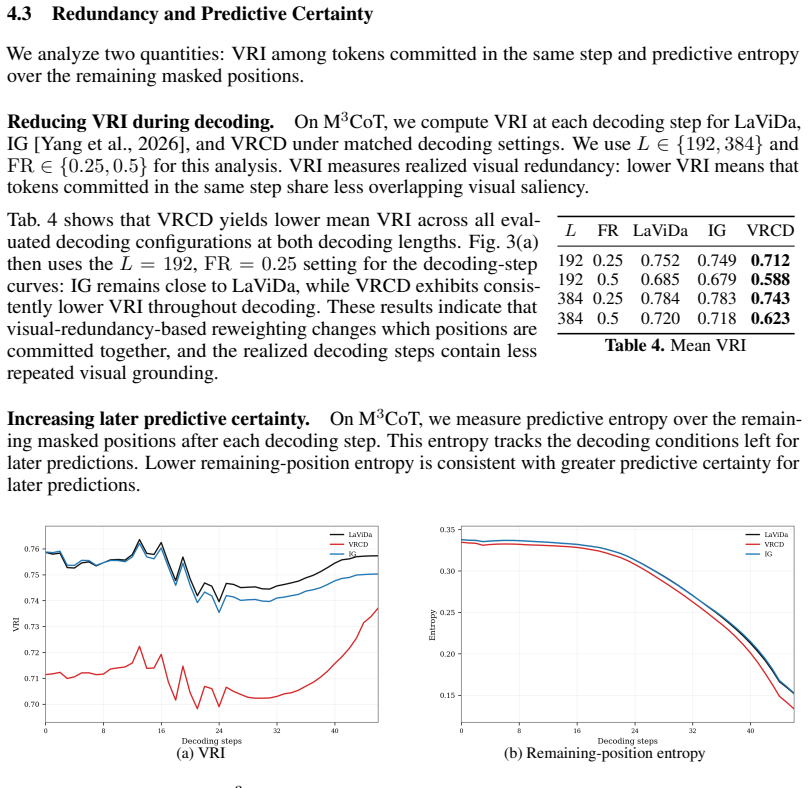
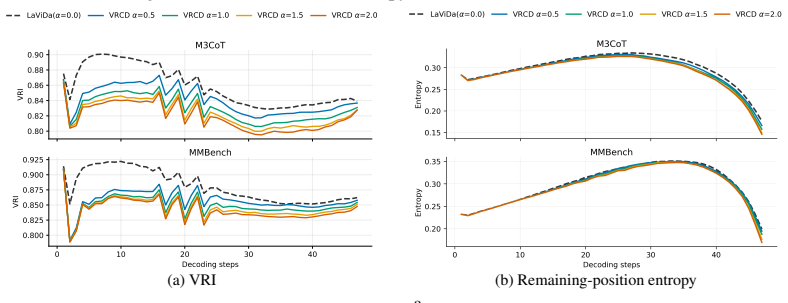
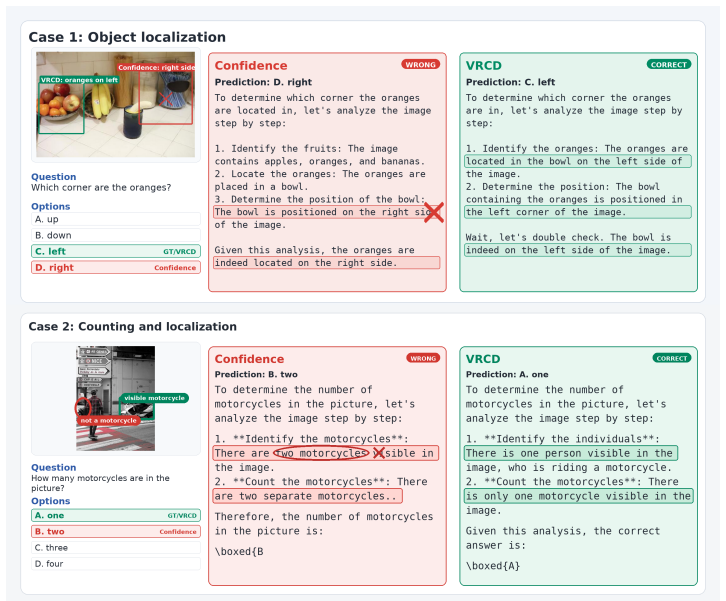
In diffusion-based MLLMs, each decoding step requires choosing which masked positions to commit together. Confidence-based methods rank positions independently and often commit tokens whose visual grounding overlaps, leaving less diverse visual context for remaining positions. VRCD computes the Visual Redundancy Index from token-to-image attention maps and re-ranks positions to favor visually complementary commitments, reducing redundancy and entropy while preserving reliability.
What carries the argument
The Visual Redundancy Index (VRI), which quantifies visual grounding overlap among tokens selected in one parallel step using token-to-image attention maps, together with the VRCD selection procedure that minimizes VRI during position choice.
If this is right
- VRCD reduces visual redundancy and remaining-position entropy with only modest added runtime.
- In longer decoding runs it delivers relative accuracy gains of up to 18.8 percent on M^3CoT and 6.9 percent on MMBench compared with confidence-based decoding.
- The method is training-free and applies at inference time across multiple multimodal benchmarks.
- Position selection now balances prediction reliability with visual complementarity rather than reliability alone.
Where Pith is reading between the lines
- The same attention-driven complementarity principle could be tested in non-diffusion parallel generation settings such as masked language modeling with visual inputs.
- If attention maps prove stable across model scales, VRCD might serve as a lightweight plug-in for any diffusion MLLM without architecture changes.
- Measuring redundancy at the step level may surface new diagnostics for how visual information is consumed during generation.
- Extending VRI to video frames or multi-image inputs would test whether the overlap problem generalizes beyond single images.
Load-bearing premise
Token-to-image attention maps provide a reliable proxy for the actual visual grounding regions that support each token.
What would settle it
An experiment in which replacing attention-based VRI with random or confidence-only selection produces the same accuracy as VRCD, or in which attention maps fail to predict measured grounding overlap on held-out image-token pairs.
Figures

read the original abstract
Diffusion-based multimodal large language models (dMLLMs) decode by iteratively predicting tokens at multiple masked positions in parallel. This turns each decoding step into a position-selection problem: the model must choose not only which predictions are reliable in isolation, but also which positions should be committed together as context for later decoding steps. Existing confidence-based decoding ranks masked positions independently and commits the top-K positions, largely ignoring whether the committed tokens provide complementary visual grounding. We identify a step-level limitation of this strategy in multimodal settings: high-confidence tokens selected in the same step can rely on overlapping visual grounding, introducing visual redundancy among the committed tokens and leaving less complementary visual grounding available for later decoding. To quantify this effect, we introduce the Visual Redundancy Index (VRI), which measures visual grounding overlap among tokens committed in parallel. To control this redundancy during decoding, we propose Visual-Redundancy-Controlled Decoding (VRCD), a training-free inference-time decoding method that uses token-to-image attention to prioritize visually complementary positions. Across diverse multimodal benchmarks, VRCD reduces visual redundancy and remaining-position entropy with modest runtime overhead. In longer decoding experiments, it also achieves relative accuracy gains of up to 18.8% on M^3CoT and 6.9% on MMBench over confidence-based decoding. Code is available at https://github.com/infiniteYuanyl/VRCD.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that diffusion-based multimodal LLMs suffer from visual redundancy in parallel decoding when high-confidence tokens overlap in visual grounding; it introduces the Visual Redundancy Index (VRI) computed from token-to-image attention maps to quantify this overlap and proposes the training-free Visual-Redundancy-Controlled Decoding (VRCD) method to select complementary positions, reporting that VRCD reduces redundancy/entropy and yields relative accuracy gains of up to 18.8% on M^3CoT and 6.9% on MMBench versus confidence-based decoding.
Significance. If the attention-proxy premise is validated, the work identifies an under-appreciated step-level limitation in multimodal parallel decoding and supplies a lightweight inference-time control that could improve accuracy without retraining; the public code release is a strength.
major comments (2)
- [Abstract] Abstract (premise for VRI and VRCD): the claim that token-to-image attention maps reliably proxy visual grounding overlap is stated without any correlation check, ablation against direct grounding measures, or analysis of whether attention is content-driven versus position-biased; this assumption is load-bearing for attributing the reported accuracy deltas to reduced redundancy rather than incidental effects.
- [Abstract] Abstract (experimental claims): the accuracy gains are reported without error bars, without specifying how baselines were matched on decoding length or compute, and without ablation isolating the contribution of the VRI-based selection versus other implementation choices.
minor comments (1)
- [Abstract] Abstract: the phrase 'longer decoding experiments' is undefined; the number of parallel steps, mask schedules, and exact baseline configurations should be stated explicitly.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the premise underlying VRI/VRCD and on the experimental reporting. We address each major comment below with point-by-point responses and indicate where revisions will be made.
read point-by-point responses
-
Referee: [Abstract] Abstract (premise for VRI and VRCD): the claim that token-to-image attention maps reliably proxy visual grounding overlap is stated without any correlation check, ablation against direct grounding measures, or analysis of whether attention is content-driven versus position-biased; this assumption is load-bearing for attributing the reported accuracy deltas to reduced redundancy rather than incidental effects.
Authors: We agree that an explicit validation of the attention proxy would strengthen the attribution. Token-to-image attention is a standard proxy for visual grounding in the multimodal literature, and our experiments show that VRI derived from it consistently reduces measured redundancy while improving accuracy. Nevertheless, the concern is valid: without a direct correlation study or position-bias analysis the causal link remains partly inferential. In revision we will add a dedicated subsection discussing this assumption, including qualitative examples of attention overlap versus content-driven grounding and a brief note on potential position biases, while retaining the core method. revision: yes
-
Referee: [Abstract] Abstract (experimental claims): the accuracy gains are reported without error bars, without specifying how baselines were matched on decoding length or compute, and without ablation isolating the contribution of the VRI-based selection versus other implementation choices.
Authors: These reporting omissions are fair criticisms. The original experiments matched baselines on the same number of decoding steps and total compute budget, but this was not stated explicitly, error bars from repeated runs were omitted, and no isolated ablation of the VRI term was presented. In the revised manuscript we will (i) report mean accuracy with standard deviation over three random seeds, (ii) add a paragraph clarifying the exact matching protocol for step count and FLOPs, and (iii) include a new ablation table that isolates the VRI-based selection from other implementation details such as the entropy term. revision: yes
Circularity Check
No circularity: heuristic method uses external attention maps
full rationale
The paper introduces VRI and VRCD as a training-free inference method that computes visual redundancy from existing token-to-image attention maps and selects positions accordingly. No derivation chain reduces a claimed prediction or result to a fitted parameter or self-referential definition by construction. The abstract and description present the approach as depending on pre-existing attention outputs rather than any internal fit or self-citation load-bearing step. This is the common case of an independent heuristic whose validity rests on empirical performance rather than tautological construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Token-to-image attention maps accurately reflect the visual grounding of tokens being decoded.
invented entities (1)
-
Visual Redundancy Index (VRI)
no independent evidence
Reference graph
Works this paper leans on
-
[2]
Flamingo: a Visual Language Model for Few-Shot Learning
URL https://arxiv. org/abs/2204.14198. Marianne Arriola, Aaron Gokaslan, Justin T. Chiu, Zhihan Yang, Zhixuan Qi, Jiaqi Han, Sub- ham Sekhar Sahoo, and V olodymyr Kuleshov. Block diffusion: Interpolating between autoregres- sive and diffusion language models.arXiv preprint arXiv:2503.09573,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Johnson, Jonathan Ho, Daniel Tarlow, and Rianne van den Berg
Jacob Austin, Daniel D. Johnson, Jonathan Ho, Daniel Tarlow, and Rianne van den Berg. Structured denoising diffusion models in discrete state-spaces.arXiv preprint arXiv:2107.03006,
-
[4]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. Qwen-vl: A versatile vision-language model for understanding, localization, text reading, and beyond.arXiv preprint arXiv:2308.12966,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
URL https://arxiv.org/ abs/2308.12966. Jieneng Chen, Luoxin Ye, Ju He, Zhao-Yang Wang, Daniel Khashabi, and Alan Yuille. Efficient large multi-modal models via visual context compression.arXiv preprint arXiv:2406.20092, 2024a. Qiguang Chen, Libo Qin, Jin Zhang, Zhi Chen, Xiao Xu, and Wanxiang Che. M 3CoT: A novel benchmark for multi-domain multi-step mult...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/2024.acl-long 2024
-
[6]
Ziyu Chen, Xinbei Jiang, Peng Sun, and Tao Lin. Optimizing decoding paths in masked diffusion models by quantifying uncertainty.arXiv preprint arXiv:2512.21336,
-
[7]
Hengyu Fu, Baihe Huang, Virginia Adams, Charles Wang, Venkat Srinivasan, and Jiantao Jiao. From bits to rounds: Parallel decoding with exploration for diffusion language models.arXiv preprint arXiv:2511.21103,
-
[8]
Feng Hong, Geng Yu, Yushi Ye, Haicheng Huang, Huangjie Zheng, Ya Zhang, Yanfeng Wang, and Jiangchao Yao. Wide-in, narrow-out: Revokable decoding for efficient and effective dllms.arXiv preprint arXiv:2507.18578,
-
[9]
Accelerating diffusion llms via adaptive parallel decoding.arXiv preprint arXiv:2506.00413,
Daniel Israel, Guy Van den Broeck, and Aditya Grover. Accelerating diffusion llms via adaptive parallel decoding.arXiv preprint arXiv:2506.00413,
-
[10]
Learning Unmasking Policies for Diffusion Language Models
Metod Jazbec, Theo X. Olausson, Louis Bethune, Pierre Ablin, Michael Kirchhof, Joao Monteiro, Victor Turrisi, Jason Ramapuram, and Marco Cuturi. Learning unmasking policies for diffusion language models.arXiv preprint arXiv:2512.09106,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
DAPD: Dependency-Aware Parallel Decoding via Attention for Diffusion LLMs
Bumjun Kim, Dongjae Jeon, Moongyu Jeon, and Albert No. Dependency-aware parallel decoding via attention for diffusion llms.arXiv preprint arXiv:2603.12996,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Sanghyun Lee, Seungryong Kim, Jongho Park, and Dongmin Park. Lookahead unmasking elicits accurate decoding in diffusion language models.arXiv preprint arXiv:2511.05563,
-
[13]
Duo Li, Zuhao Yang, Xiaoqin Zhang, Ling Shao, and Shijian Lu. A comprehensive study on visual token redundancy for discrete diffusion-based multimodal large language models.arXiv preprint arXiv:2511.15098, 2025a. Hongliang Li, Jiaxin Zhang, Wenhui Liao, Dezhi Peng, Kai Ding, and Lianwen Jin. Redundancylens: Revealing and exploiting visual token processing...
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Shufan Li, Jiuxiang Gu, Kangning Liu, Zhe Lin, Zijun Wei, Aditya Grover, and Jason Kuen. Sparse- lavida: Sparse multimodal discrete diffusion language models.arXiv preprint arXiv:2512.14008, 2025c. Shufan Li, Konstantinos Kallidromitis, Hritik Bansal, Akash Gokul, Yusuke Kato, Kazuki Kozuka, Jason Kuen, Zhe Lin, Kai-Wei Chang, and Aditya Grover. Lavida: A...
-
[15]
URLhttps://arxiv.org/abs/2304.08485. Yuan Liu, Haodong Duan, Yuanhan Zhang, Bo Li, Songyang Zhang, Wangbo Zhao, Yike Yuan, Jiaqi Wang, Conghui He, Ziwei Liu, Kai Chen, and Dahua Lin. MMBench: Is your multi-modal model an all-around player? InEuropean Conference on Computer Vision, pages 216–233. Springer,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Discrete Diffusion Modeling by Estimating the Ratios of the Data Distribution
Aaron Lou, Chenlin Meng, and Stefano Ermon. Discrete diffusion modeling by estimating the ratios of the data distribution.arXiv preprint arXiv:2310.16834,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Plan for Speed: Dilated Scheduling for Masked Diffusion Language Models
URL https://proceedings.neurips.cc/paper_files/paper/ 2022/file/11332b6b6cf4485b84afadb1352d3a9a-Paper-Conference.pdf. Omer Luxembourg, Haim Permuter, and Eliya Nachmani. Plan for speed: Dilated scheduling for masked diffusion language models.arXiv preprint arXiv:2506.19037,
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[18]
Large Language Diffusion Models
Shen Nie, Fengqi Zhu, Zebin You, Xiaolu Zhang, Jingyang Ou, Jun Hu, Jun Zhou, Yankai Lin, Ji- Rong Wen, and Chongxuan Li. Large language diffusion models.arXiv preprint arXiv:2502.09992,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Dependency-Guided Parallel Decoding in Discrete Diffusion Language Models
Liran Ringel, Ameen Ali, and Yaniv Romano. Dependency-guided parallel decoding in discrete diffusion language models.arXiv preprint arXiv:2604.02560,
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Chiu, Alexander Rush, and Volodymyr Kuleshov
Subham Sekhar Sahoo, Marianne Arriola, Yair Schiff, Aaron Gokaslan, Edgar Marroquin, Justin T. Chiu, Alexander Rush, and V olodymyr Kuleshov. Simple and effective masked diffusion language models.arXiv preprint arXiv:2406.07524,
-
[21]
Remasking discrete diffusion models with inference-time scaling.arXiv preprint arXiv:2503.00307,
Guanghan Wang, Yair Schiff, Subham Sekhar Sahoo, and V olodymyr Kuleshov. Remasking discrete diffusion models with inference-time scaling.arXiv preprint arXiv:2503.00307,
-
[22]
Yi Xin et al. Lumina-dimoo: An omni diffusion large language model for multi-modal generation and understanding.arXiv preprint arXiv:2510.06308,
-
[23]
PyramidDrop: Accelerating Your Large Vision-Language Models via Pyramid Visual Redundancy Reduction
Long Xing, Qidong Huang, Xiaoyi Dong, Jiajie Lu, Pan Zhang, Yuhang Zang, Yuhang Cao, Conghui He, Jiaqi Wang, Feng Wu, and Dahua Lin. Pyramiddrop: Accelerating your large vision-language models via pyramid visual redundancy reduction.arXiv preprint arXiv:2410.17247,
work page internal anchor Pith review Pith/arXiv arXiv
- [24]
-
[25]
11 Dingchen Yang, Bowen Cao, Anran Zhang, Weibo Gu, Winston Hu, and Guang Chen. Beyond inter- mediate states: Explaining visual redundancy through language.arXiv preprint arXiv:2503.20540, 2025a. Kaisen Yang, Jayden Teoh, Kaicheng Yang, Yitong Zhang, and Alex Lamb. Improving sampling for masked diffusion models via information gain.arXiv preprint arXiv:26...
-
[26]
MMaDA: Multimodal Large Diffusion Language Models
Ling Yang, Ye Tian, Bowen Li, Xinchen Zhang, Ke Shen, Yunhai Tong, and Mengdi Wang. Mmada: Multimodal large diffusion language models.arXiv preprint arXiv:2505.15809, 2025b. Jiacheng Ye, Zhihui Xie, Lin Zheng, Jiahui Gao, Zirui Wu, Xin Jiang, Zhenguo Li, and Lingpeng Kong. Dream 7b: Diffusion large language models.arXiv preprint arXiv:2508.15487,
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
LLaDA-V: Large Language Diffusion Models with Visual Instruction Tuning
Zebin You, Shen Nie, Xiaolu Zhang, Jun Hu, Jun Zhou, Zhiwu Lu, Ji-Rong Wen, and Chongxuan Li. Llada-v: Large language diffusion models with visual instruction tuning.arXiv preprint arXiv:2505.16933,
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
Runpeng Yu, Xinyin Ma, and Xinchao Wang. Dimple: Discrete diffusion multimodal large language model with parallel decoding.arXiv preprint arXiv:2505.16990,
-
[29]
Renshan Zhang, Rui Shao, Gongwei Chen, Miao Zhang, Kaiwen Zhou, Weili Guan, and Liqiang Nie. Falcon: Resolving visual redundancy and fragmentation in high-resolution multimodal large language models via visual registers.arXiv preprint arXiv:2501.16297,
-
[30]
Shaorong Zhang, Longxuan Yu, Rob Brekelmans, Luhan Tang, Salman Asif, and Greg Ver Steeg. Generation order and parallel decoding in masked diffusion models: An information-theoretic perspective.arXiv preprint arXiv:2602.00286,
-
[31]
Yangyang Zhong, Yanmei Gu, Zhengqing Zang, Xiaomeng Li, Yuqi Ding, Xibei Jia, et al. Parallelism and generation order in masked diffusion language models: Limits today, potential tomorrow. arXiv preprint arXiv:2601.15593,
work page internal anchor Pith review Pith/arXiv arXiv
-
[33]
MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models
URLhttps://arxiv.org/abs/2304.10592. 12 A Appendix A.1 Full VRCD Procedure and Implementation Details This section provides the full pseudocode of VRCD and specifies the implementation details that are summarized in the main paper. Algorithm 1Visual-Redundancy-Controlled Decoding (VRCD) at decoding stept Require: masked positions Ct, per-step commit size ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
The grid uses λ∈ {1.5,2.0,2.5,3.0} with FR∈ {0.125,0.25,0.5} . We exclude λ= 1.0 , which would leave the candidate window identical to the positions selected by confidence-based de- coding. Tab. 11 reports M3CoT accuracy. In this grid, λ= 2.5 gives the best value at all three FR settings. FR Confidenceλ= 1.5λ= 2.0λ= 2.5λ= 3.0 0.125 36.43 37.17 37.9438.093...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.