TIAR: Trajectory-Informed Advantage Reweighting for LLM Abstention Learning
Pith reviewed 2026-06-29 21:15 UTC · model grok-4.3
The pith
TIAR dynamically reweights abstention advantages using GRPO trajectories to improve LLM truthfulness.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
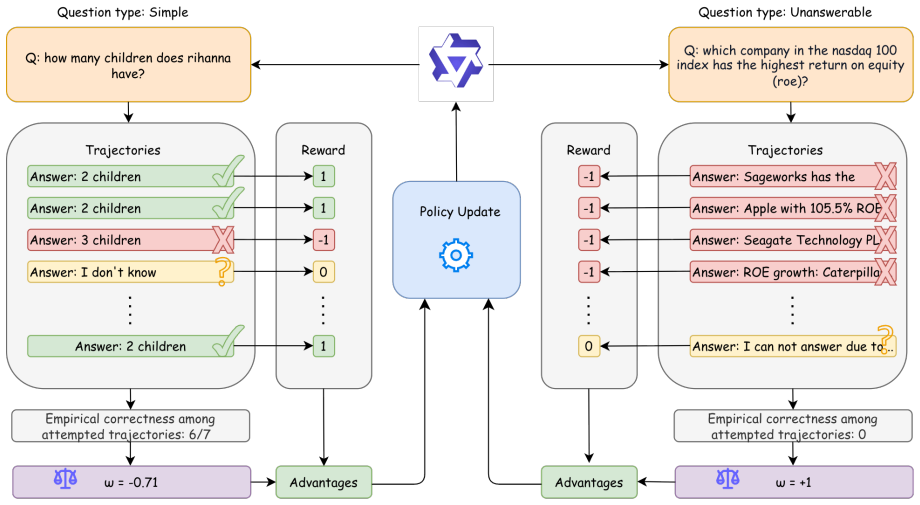
By treating the multiple trajectories produced in each GRPO step as a natural indicator of the policy's relative confidence, TIAR computes a dynamic abstention advantage that reweights the reward signal during training. This trajectory-informed mechanism replaces the fixed ternary reward used in earlier abstention work, allowing the model to adjust its abstention behavior query by query while still optimizing for truthfulness.
What carries the argument
Trajectory-Informed Advantage Reweighting (TIAR), which extracts a dynamic abstention advantage directly from the set of trajectories generated by GRPO for each query.
If this is right
- TIAR reaches state-of-the-art abstention F1 scores in five of the six evaluation categories on AbstentionBench.
- The method outperforms the static ternary baseline on 17 of the 31 benchmark datasets.
- Baseline accuracy is fully preserved across all evaluated datasets.
- Trajectories collected during standard GRPO training can be repurposed as an abstention signal without extra supervision.
Where Pith is reading between the lines
- The same trajectory-based signal could be extracted from other group-based reinforcement learning algorithms to add abstention capabilities without redesigning the reward model.
- Integrating TIAR-style reweighting into existing RLHF pipelines might allow abstention behavior to emerge as a side effect of normal training rather than requiring a separate stage.
- Because the method operates on trajectories already produced during training, it could be applied retroactively to previously trained models by re-running a small number of GRPO steps.
Load-bearing premise
The multiple trajectories generated during GRPO training reliably indicate the policy's confidence level relative to each query.
What would settle it
A controlled rerun on the same 31 AbstentionBench datasets in which TIAR no longer exceeds the static ternary baseline on at least 17 datasets or reduces accuracy on any dataset would falsify the central performance claim.
Figures
read the original abstract
This paper investigates large language model (LLM) abstention learning, specifically using ternary reward, which incentivize truthfulness in large language models. This paper extends that idea by moving from a ternary reward to a Trajectory-Informed advantage reweighting, dynamically re-weights the abstention reward during Group Relative Policy Optimization (GRPO) training. The objective of this work focuses on abstention learning instead of improving truthfulness, serving as an exploration into hallucination reduction. The novelty of this paper lies in methodological innovation, advantage re-weighting, and benchmark selection. Leveraging GRPO's multiple trajectories as a natural abstention signal, this method uses a reward signal to explore knowledge boundaries and encourage consistency. By demonstrating that trajectories can be used as a confidence indicator of the policy relative to the query, they are then used to dynamically calculate the abstention advantage. AbstentionBench is used as the evaluation benchmark, as this work aims to contribute to the field of abstention learning. All datasets on the benchmark were tested against this method and various baselines. Empirical results demonstrate that TIAR achieves state-of-the-art abstention F1 scores across five of six evaluation categories, outperforming the static ternary baseline on 17 of 31 benchmark datasets while fully preserving baseline accuracy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes TIAR, an extension of ternary-reward abstention learning that replaces static rewards with trajectory-informed advantage reweighting inside GRPO. Multiple rollouts generated during training are treated as a dynamic confidence signal for the policy relative to each query; these are used to compute per-trajectory abstention advantages that are then reweighted into the GRPO objective. The method is evaluated on the full AbstentionBench (31 datasets), reporting state-of-the-art abstention F1 on five of six categories, outperformance versus the static ternary baseline on 17 datasets, and no degradation of baseline accuracy.
Significance. If the reported gains are robust, TIAR supplies a practical, training-time heuristic for improving abstention without auxiliary models or post-hoc calibration. The reuse of GRPO trajectories as an internal confidence proxy is a lightweight methodological contribution that could be adopted in other RLHF-style pipelines.
major comments (2)
- [§3] §3 (Trajectory-informed advantage): the central modeling choice treats the set of trajectories sampled from the current policy as an exogenous confidence signal. Because these trajectories are generated by the policy whose abstention behavior is being optimized, the construction risks circularity; the manuscript should supply an ablation that isolates whether the reported F1 gains survive when the advantage is computed from an independent, frozen policy or from held-out data.
- [Table 2 / §4.2] Table 2 / §4.2: the claim of 'fully preserving baseline accuracy' is reported only as point estimates. Without per-dataset accuracy deltas, standard errors, or a paired statistical test, it is impossible to verify that the 17/31 wins on abstention F1 do not trade off accuracy on a non-negligible subset of tasks.
minor comments (2)
- [Abstract / §4] The abstract states 'five of six evaluation categories' without naming them; the results section should explicitly list the six categories and which five are improved.
- [§3] Notation for the advantage reweighting term (Eq. (X)) is introduced without a compact pseudocode listing of the full GRPO+TIAR update; adding one would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review. We address each major comment below with clarifications and indicate planned revisions to the manuscript.
read point-by-point responses
-
Referee: [§3] §3 (Trajectory-informed advantage): the central modeling choice treats the set of trajectories sampled from the current policy as an exogenous confidence signal. Because these trajectories are generated by the policy whose abstention behavior is being optimized, the construction risks circularity; the manuscript should supply an ablation that isolates whether the reported F1 gains survive when the advantage is computed from an independent, frozen policy or from held-out data.
Authors: We appreciate the concern regarding potential circularity. The design intentionally uses trajectories sampled from the current policy to derive a query-specific confidence signal via outcome consistency across rollouts; the advantage is computed from verifiable correctness labels rather than from the abstention action itself. This self-referential estimation is a deliberate feature that enables dynamic reweighting without external models. Nevertheless, to isolate the contribution, we will add an ablation study in the revised manuscript that recomputes advantages using a frozen policy checkpoint from an earlier training stage. revision: partial
-
Referee: [Table 2 / §4.2] Table 2 / §4.2: the claim of 'fully preserving baseline accuracy' is reported only as point estimates. Without per-dataset accuracy deltas, standard errors, or a paired statistical test, it is impossible to verify that the 17/31 wins on abstention F1 do not trade off accuracy on a non-negligible subset of tasks.
Authors: We agree that point estimates alone limit the strength of the preservation claim. In the revised version we will report per-dataset accuracy deltas, include standard errors (or standard deviations across seeds where multiple runs exist), and add paired statistical tests (e.g., Wilcoxon signed-rank) across the 31 datasets to quantify whether accuracy differences are statistically significant. revision: yes
Circularity Check
No significant circularity
full rationale
The paper frames TIAR as an empirical heuristic that reweights abstention rewards during GRPO by treating generated trajectories as a confidence signal. No derivation is presented that reduces by construction to its own inputs, no equations equate a fitted parameter to a claimed prediction, and no load-bearing self-citations or uniqueness theorems are invoked. The reported gains are empirical comparisons against baselines on AbstentionBench; the modeling choice is presented as a practical exploration rather than a formally forced result.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
MASH: Modeling Abstention via Selective Help-Seeking
Pay-per-search models are abstention models. Preprint, arXiv:2510.01152. Saurav Kadavath, Tom Conerly, Amanda Askell, Tom Henighan, Dawn Drain, Ethan Perez, Nicholas Schiefer, Zac Hatfield-Dodds, Nova DasSarma, Eli Tran-Johnson, Scott Johnston, Sheer El-Showk, Andy Jones, Nelson Elhage, Tristan Hume, Anna Chen, Yuntao Bai, Sam Bowman, Stanislav Fort, and ...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[2]
Direct Preference Optimization: Your Language Model is Secretly a Reward Model
Direct preference optimization: Your lan- guage model is secretly a reward model.Preprint, arXiv:2305.18290. Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y . K. Li, Y . Wu, and Daya Guo. 2024. Deepseekmath: Pushing the limits of mathemati- cal reasoning in open language models.Preprint, arXiv:2402.0...
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.