How Accurate are Video Quality Models for Diffusion-Based Video Super-Resolution?
Pith reviewed 2026-06-29 19:13 UTC · model grok-4.3
The pith
No tested video quality model reaches sufficient accuracy to replace subjective testing for diffusion-based video super-resolution.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
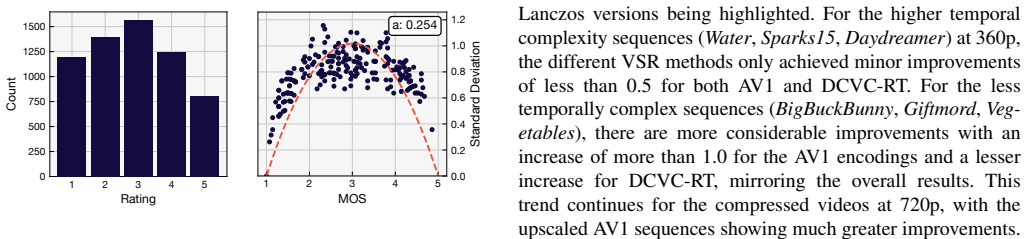
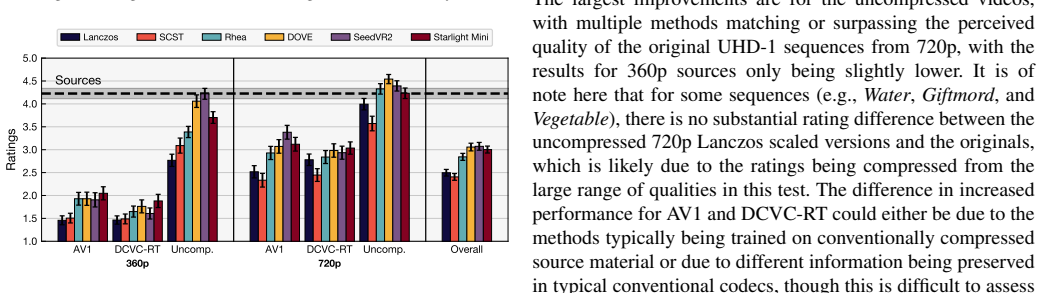
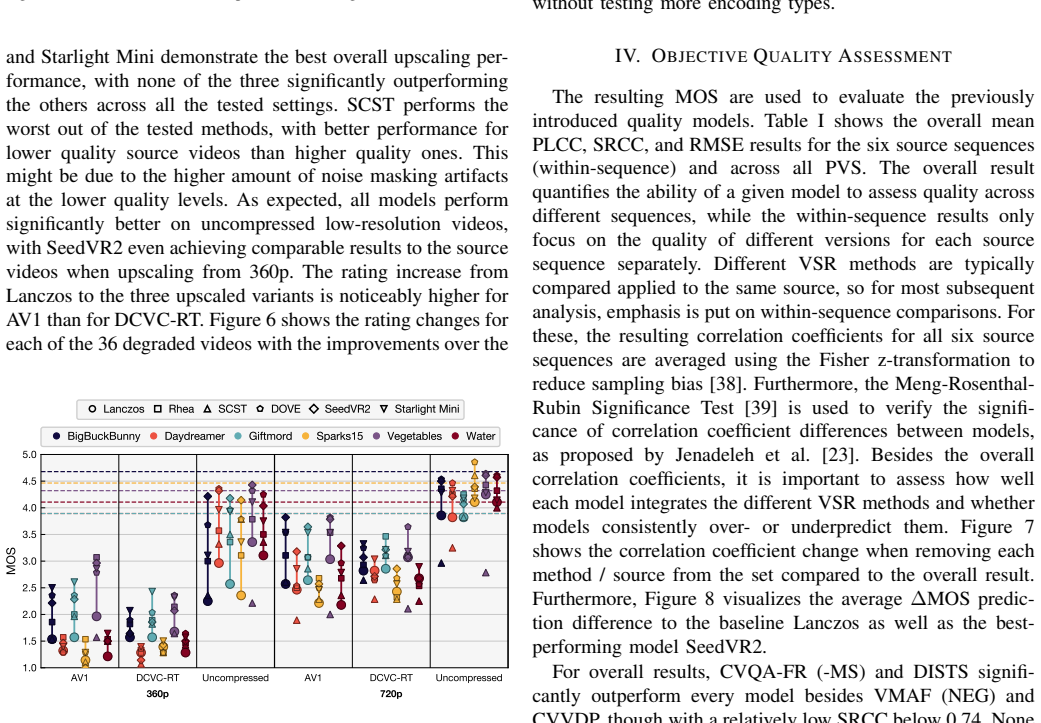
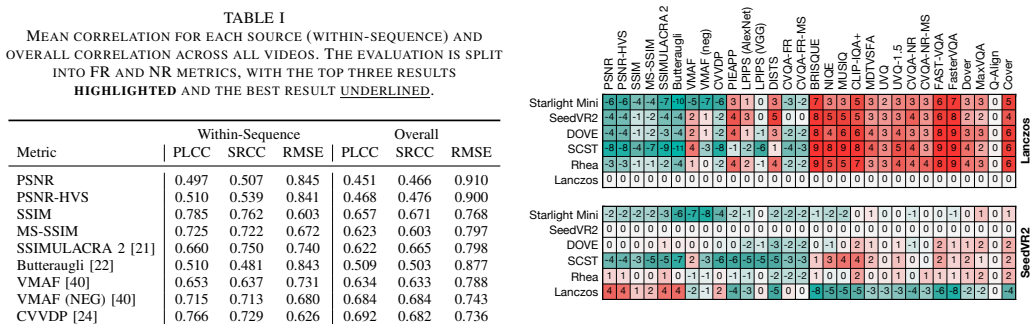
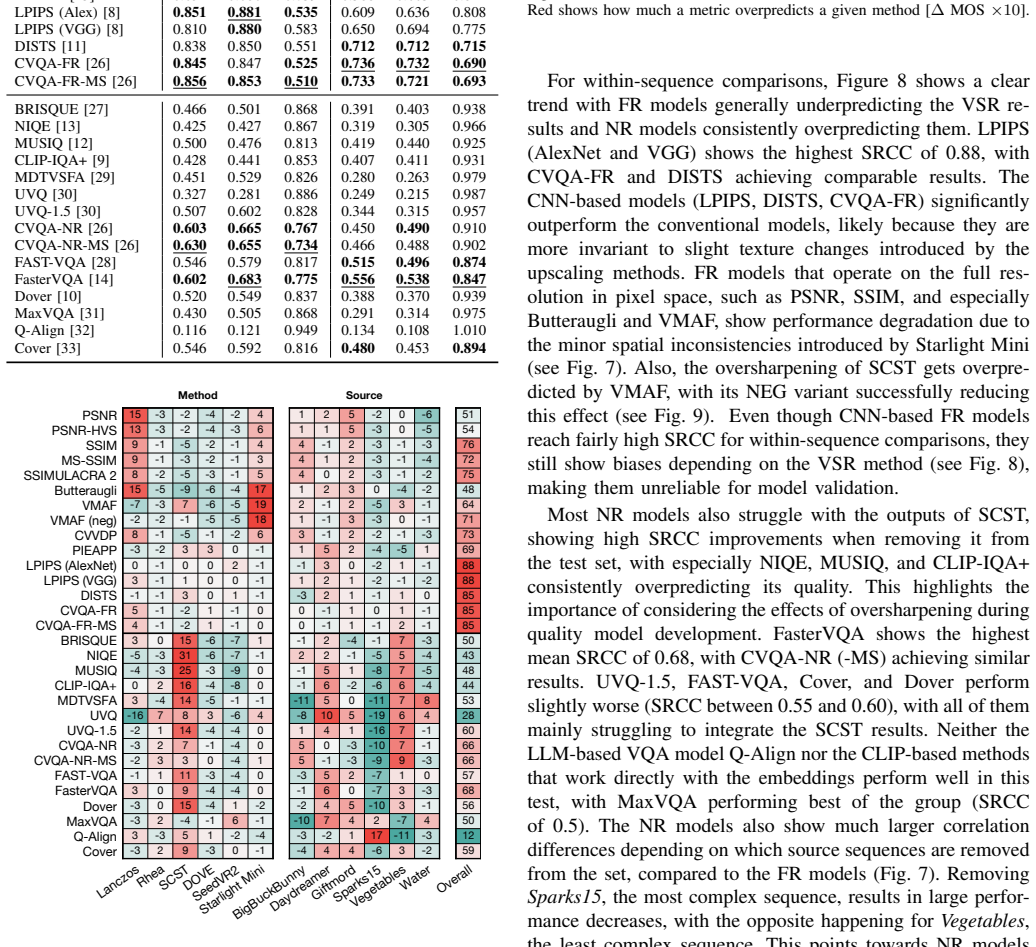
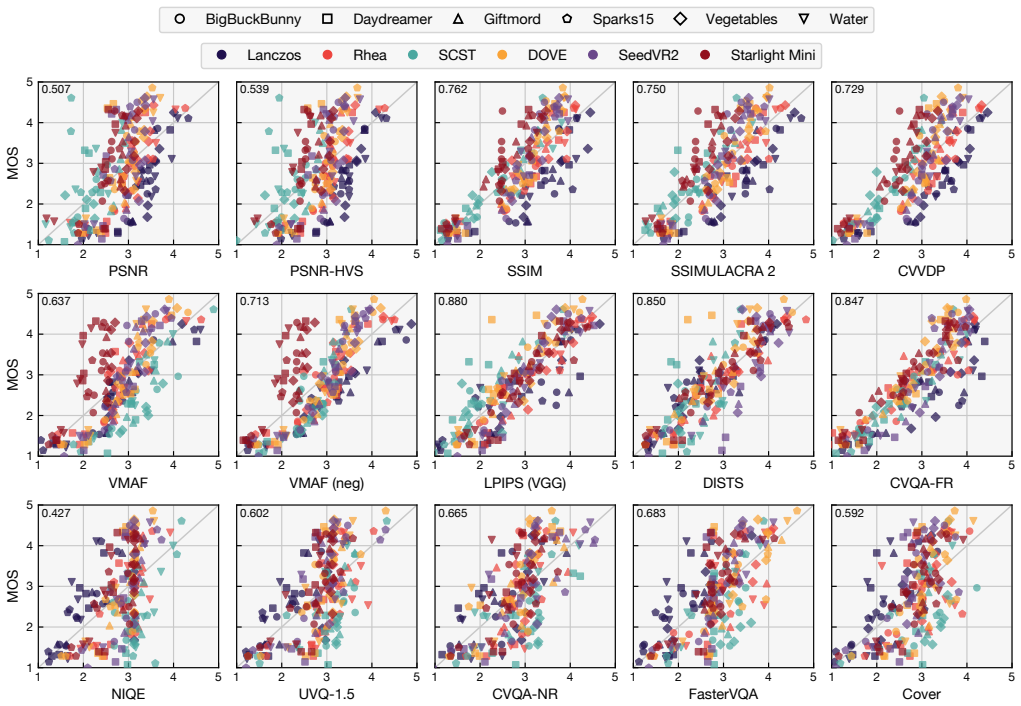
When six upscaling methods (Lanczos, Rhea, SCST, DOVE, SeedVR2, Starlight Mini) are applied to AV1- and DCVC-RT-compressed as well as uncompressed low-resolution content and displayed on UHD-1/4K screens, none of the tested full- or no-reference quality models achieve correlation levels high enough to replace subjective testing. CNN-based full-reference models outperform others but still overestimate the overly sharp output of SCST and fail on the spatial inconsistencies produced by Starlight Mini.
What carries the argument
Direct comparison of objective model scores against subjective human ratings collected for within-sequence performance on diffusion-based VSR outputs.
If this is right
- CNN-based full-reference models exhibit significantly higher correlation than conventional full-reference or no-reference models on these outputs.
- Most models overestimate the sharpness produced by SCST.
- VMAF underperforms mainly because of spatial inconsistencies introduced by Starlight Mini.
- Subjective testing must remain part of the evaluation pipeline for diffusion-based video super-resolution.
- The released dataset of videos, ratings, and model scores can be used to benchmark future metrics.
Where Pith is reading between the lines
- Models trained on traditional compression or scaling artifacts will likely need retraining or new features to handle the distinct error patterns of diffusion generators.
- The open dataset provides a concrete test bed for developing or fine-tuning metrics targeted at generative video restoration.
- The same evaluation gap may appear when applying current quality models to other diffusion-based video tasks such as frame interpolation or denoising.
Load-bearing premise
The collected subjective ratings serve as reliable ground truth for perceptual quality across the tested upscaling methods, viewing conditions, and content types.
What would settle it
A new subjective test on the same or similar diffusion VSR sequences in which at least one of the tested models reaches correlation coefficients high enough to be considered a substitute for human ratings.
Figures

read the original abstract
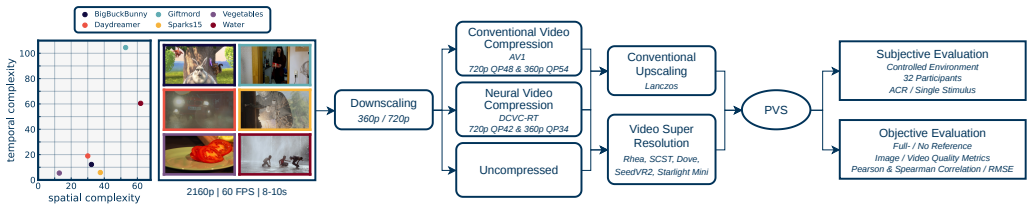
Recent video super-resolution (VSR) approaches use deep neural networks to enhance low-quality input videos and recover visual detail, with diffusion-based methods in particular showing promising results. In this paper, we investigate whether existing video quality models can be used to assess the performance of these diffusion-based VSR methods, by comparing model predictions with results from a subjective test. The study compares six upscaling methods (Lanczos, Rhea, SCST, DOVE, SeedVR2, Starlight Mini) applied to both compressed (AV1 and DCVC-RT) and uncompressed low-resolution videos considering the play-out on a UHD-1/4K screen. A range of full- and no-reference quality models are used to assess their applicability to this new type of quality degradation, focusing on within-sequence performance. The results highlight that CNN-based full-reference models, such as LPIPS, DISTS, and CVQA-FR show significantly higher correlation coefficients than both conventional full- as well as the tested no-reference models. Most overestimate the overly sharp results of SCST, with VMAF mainly failing due to spatial inconsistencies introduced by Starlight Mini. None of the tested video quality models reach sufficient accuracy so as to replace complementary subjective testing. The reference, degraded and upscaled videos, as well as the user ratings and model scores are made available with the paper at https://github.com/Telecommunication-Telemedia-Assessment/AVT-VQDB-UHD-1-VSR as open data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper conducts an empirical comparison of full-reference and no-reference video quality assessment (VQA) models against subjective ratings collected for six upscaling methods (including diffusion-based VSR approaches such as DOVE, SeedVR2, and Starlight Mini) applied to both compressed (AV1, DCVC-RT) and uncompressed low-resolution content, viewed on UHD-1/4K displays. It reports that CNN-based FR models (LPIPS, DISTS, CVQA-FR) achieve the highest correlations but still overestimate sharpness artifacts and fail to capture spatial inconsistencies, concluding that no tested model reaches sufficient accuracy to replace subjective testing. The reference, degraded, and enhanced sequences plus ratings and model scores are released as open data.
Significance. If the subjective ground truth is reliable, the work provides a useful benchmark showing that current VQA models are inadequate for diffusion-induced artifacts in VSR, particularly spatial inconsistencies and over-sharpening. The public release of the full dataset (videos, ratings, and scores) is a clear strength that enables future reproducibility and model development.
major comments (2)
- [Subjective test / results sections] Subjective test description (likely §3 or §4): the manuscript provides no quantitative indicators of data reliability such as number of participants, inter-rater agreement (e.g., ICC or Cronbach’s alpha), outlier screening criteria, or comparison against anchor conditions. Because the central claim—that no VQA model is accurate enough to replace subjective testing—rests entirely on treating the collected ratings as authoritative ground truth, the absence of these checks leaves the reported correlation gaps (even for LPIPS/DISTS) open to reinterpretation as possible artifacts of noisy or biased subjective data.
- [Results / discussion] Results and discussion (likely §5): the claim that “none of the tested video quality models reach sufficient accuracy” is presented without explicit numerical thresholds for what constitutes “sufficient” (e.g., minimum Pearson/Spearman correlation or RMSE relative to subjective variance). Without such criteria or statistical significance tests comparing model performance to the subjective variability, it is difficult to judge whether the observed gaps are practically meaningful or merely within the noise of the subjective data.
minor comments (2)
- [Abstract / methods] The abstract states that the study focuses on “within-sequence performance,” but the manuscript does not define this term or clarify how it differs from standard across-sequence evaluation.
- [Tables / figures] Table or figure captions listing the six upscaling methods should explicitly note which are diffusion-based to help readers map the results to the title.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will revise the manuscript accordingly to strengthen the presentation of the subjective methodology and the interpretation of results.
read point-by-point responses
-
Referee: Subjective test description lacks quantitative indicators of data reliability such as number of participants, inter-rater agreement (ICC or Cronbach’s alpha), outlier screening criteria, or comparison against anchor conditions. This questions treating the ratings as authoritative ground truth.
Authors: We agree these reliability metrics are essential. The manuscript text does not report them explicitly, although the raw ratings are released publicly. In revision we will add a dedicated subsection in the subjective test description reporting participant count, inter-rater agreement (ICC), outlier screening, and any anchor conditions used, thereby reinforcing the validity of the ground-truth ratings. revision: yes
-
Referee: The claim that none of the tested models reach sufficient accuracy lacks explicit numerical thresholds (e.g., minimum Pearson/Spearman correlation or RMSE) and statistical significance tests against subjective variability.
Authors: We concur that explicit criteria would improve rigor. In the revised discussion we will define sufficient accuracy by reference to common VQA literature thresholds and will add statistical comparisons of model performance relative to the observed variance in subjective scores, clarifying whether the reported gaps are practically meaningful. revision: yes
Circularity Check
No circularity: purely empirical comparison with external ground truth
full rationale
The paper conducts an empirical study comparing objective video quality model outputs to results from a new subjective test on six upscaling methods (including diffusion-based VSR) under specified viewing conditions. No derivations, equations, fitted parameters, or self-citation chains are present that would reduce any claim to its own inputs by construction. The central conclusion (insufficient model accuracy to replace subjective testing) rests on direct correlation measurements against the collected ratings and the released open dataset, which constitutes independent external benchmarking rather than any self-referential loop.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Subjective ratings collected under the described viewing conditions represent true perceptual quality for the tested content and methods.
Reference graph
Works this paper leans on
-
[1]
VCA: Video Complexity Analyzer
V . V . Menon, C. Feldmann, H. Amirpour, M. Ghanbari, and C. Timmerer. “VCA: Video Complexity Analyzer”. In:Proc 13th ACM Multimed. Syst. Conf. Athlone Ireland: ACM, June 14, 2022, pp. 259–264
2022
-
[2]
A Survey of Deep Learning Video Super-Resolution
A. A. Baniya, T.-K. Lee, P. W. Eklund, and S. Aryal. “A Survey of Deep Learning Video Super-Resolution”. In:IEEE Trans. Emerg. Top. Comput. Intell.8.4 (Aug. 2024), pp. 2655– 2676
2024
-
[3]
Upscale-A- Video: Temporal-Consistent Diffusion Model for Real-World Video Super-Resolution
S. Zhou, P. Yang, J. Wang, Y . Luo, and C. C. Loy. “Upscale-A- Video: Temporal-Consistent Diffusion Model for Real-World Video Super-Resolution”. In:Conf. Comput. Vis. Pattern Recognit.Seattle, USA: IEEE, June 16, 2024, pp. 2535–2545
2024
-
[4]
Self-Supervised Con- trolNet with Spatio-Temporal Mamba for Real-world Video Super-resolution
S. Shi, J. Xu, L. Lu, Z. Li, and K. Hu. “Self-Supervised Con- trolNet with Spatio-Temporal Mamba for Real-world Video Super-resolution”. In:Conf. Comput. Vis. Pattern Recognit. Nashville, USA: IEEE, June 10, 2025, pp. 7385–7395
2025
-
[5]
SeedVR: Seeding Infinity in Diffusion Trans- former Towards Generic Video Restoration
J. Wang et al. “SeedVR: Seeding Infinity in Diffusion Trans- former Towards Generic Video Restoration”. In:Conf. Com- put. Vis. Pattern Recognit.Nashville, USA: IEEE, June 10, 2025, pp. 2161–2172
2025
-
[6]
Chen et al.DOVE: Efficient One-Step Diffusion Model for Real-World Video Super-Resolution
Z. Chen et al.DOVE: Efficient One-Step Diffusion Model for Real-World Video Super-Resolution. May 22, 2025. arXiv: 2505.16239. Pre-published
-
[7]
Wang et al.SeedVR2: One-Step Video Restoration via Diffusion Adversarial Post-Training
J. Wang et al.SeedVR2: One-Step Video Restoration via Diffusion Adversarial Post-Training. June 5, 2025. arXiv: 2506.05301. Pre-published
-
[8]
The Unreasonable Effectiveness of Deep Features as a Perceptual Metric
R. Zhang, P. Isola, A. A. Efros, E. Shechtman, and O. Wang. “The Unreasonable Effectiveness of Deep Features as a Perceptual Metric”. In:Conf Comput. Vis. Pattern Recognit. Salt Lake City, UT: IEEE, June 2018, pp. 586–595
2018
-
[9]
Exploring CLIP for Assessing the Look and Feel of Images
J. Wang, K. C. Chan, and C. C. Loy. “Exploring CLIP for Assessing the Look and Feel of Images”. In:AAAI37.2 (June 26, 2023), pp. 2555–2563
2023
-
[10]
Exploring Video Quality Assessment on User Generated Contents from Aesthetic and Technical Perspec- tives
H. Wu et al. “Exploring Video Quality Assessment on User Generated Contents from Aesthetic and Technical Perspec- tives”. In:Int Conf Comput. Vis.Paris, France: IEEE, Oct. 1, 2023, pp. 20087–20097
2023
-
[11]
Image Quality Assessment: Unifying Structure and Texture Similar- ity
K. Ding, K. Ma, S. Wang, and E. P. Simoncelli. “Image Quality Assessment: Unifying Structure and Texture Similar- ity”. In:IEEE Trans. Pattern Anal. Mach. Intell.(May 2020), pp. 2567–2581
2020
-
[12]
MUSIQ: Multi-scale Image Quality Transformer
J. Ke, Q. Wang, Y . Wang, P. Milanfar, and F. Yang. “MUSIQ: Multi-scale Image Quality Transformer”. In:Int. Conf. Com- put. Vis.Montreal, QC, Canada: IEEE, Oct. 2021, pp. 5128– 5137
2021
-
[13]
Making a “Completely Blind
A. Mittal, R. Soundararajan, and A. C. Bovik. “Making a “Completely Blind” Image Quality Analyzer”. In:IEEE Signal Process. Lett.20.3 (Mar. 2013), pp. 209–212
2013
-
[14]
Neighbourhood Representative Sampling for Efficient End-to-End Video Quality Assessment
H. Wu et al. “Neighbourhood Representative Sampling for Efficient End-to-End Video Quality Assessment”. In:Trans. Pattern Anal. Mach. Intell.45.12 (Dec. 2023), pp. 15185– 15202
2023
-
[15]
A Comparative Study of Super-Resolution Algorithms for Video Streaming Appli- cation
X. He, Y . Qiao, B. Lee, and Y . Ye. “A Comparative Study of Super-Resolution Algorithms for Video Streaming Appli- cation”. In:Multimed. Tools Appl.83.14 (Oct. 13, 2023), pp. 43493–43512
2023
-
[16]
AIM 2024 Challenge on Video Super- Resolution Quality Assessment: Methods and Results
I. Molodetskikh et al. “AIM 2024 Challenge on Video Super- Resolution Quality Assessment: Methods and Results”. In: Comput. Vis. – ECCV 2024 Workshop. Berlin, Heidelberg: Springer-Verlag, 2025, pp. 160–177
2024
-
[17]
VSRQAD: Video Super-Resolution Quality Assess- ment Dataset and Benchmark
A. Borisov, E. Bogatyrev, K. Abud, I. Molodetskikh, and D. Vatolin. “VSRQAD: Video Super-Resolution Quality Assess- ment Dataset and Benchmark”. In:IEEE Access14 (2026), pp. 60229–60251
2026
-
[18]
A VT-VQDB-UHD-1: A Large Scale Video Quality Database for UHD-1
R. R. Ramachandra Rao, S. Göring, W. Robitza, B. Feiten, and A. Raake. “A VT-VQDB-UHD-1: A Large Scale Video Quality Database for UHD-1”. In:Int. Symp. Multimed.San Diego, USA: IEEE, Dec. 2019, pp. 17–177
2019
-
[19]
Towards Practical Real-Time Neural Video Compression
Z. Jia et al. “Towards Practical Real-Time Neural Video Compression”. In:Proc. Comput. Vis. Pattern Recognit. Conf. June 2025, pp. 12543–12552
2025
-
[20]
Panda-70M: Captioning 70M Videos with Multiple Cross-Modality Teachers
T.-S. Chen et al. “Panda-70M: Captioning 70M Videos with Multiple Cross-Modality Teachers”. In:Conf. Comput. Vis. Pattern Recognit.Seattle, USA: IEEE, June 16, 2024, pp. 13320–13331
2024
-
[21]
Cloudinary, 2022.URL: https://github.com/cloudinary/ssimulacra2 (visited on 01/09/2026)
Jon Sneyers.SSIMULACRA 2 - Structural SIMilarity Unveil- ing Local And Compression Related Artifacts. Cloudinary, 2022.URL: https://github.com/cloudinary/ssimulacra2 (visited on 01/09/2026)
2022
-
[22]
Google, 2016.URL: https : / / github.com/google/butteraugli (visited on 01/07/2026)
Jyrki Alakuijala.Butteraugli - A Tool for Measuring Perceived Differences between Images. Google, 2016.URL: https : / / github.com/google/butteraugli (visited on 01/07/2026)
2016
-
[23]
Subjective Visual Quality Assessment for High-Fidelity Learning-Based Image Compression
M. Jenadeleh et al. “Subjective Visual Quality Assessment for High-Fidelity Learning-Based Image Compression”. In: 17th Int. Conf. Qual. Multimed. Exp.Madrid, Spain: IEEE, Sept. 30, 2025, pp. 1–7
2025
-
[24]
ColorVideoVDP: A Visual Difference Predictor for Image, Video and Display Distortions
R. K. Mantiuk, P. Hanji, M. Ashraf, Y . Asano, and A. Chapiro. “ColorVideoVDP: A Visual Difference Predictor for Image, Video and Display Distortions”. In:ACM Trans. Graph.43.4 (July 19, 2024), pp. 1–20
2024
-
[25]
PieAPP: Percep- tual Image-Error Assessment Through Pairwise Preference
E. Prashnani, H. Cai, Y . Mostofi, and P. Sen. “PieAPP: Percep- tual Image-Error Assessment Through Pairwise Preference”. In:Conf. Comput. Vis. Pattern Recognit.Salt Lake City, UT: IEEE, June 2018, pp. 1808–1817
2018
-
[26]
Deep Learning Based Full-Reference and No-Reference Quality Assessment Models for Compressed UGC Videos
W. Sun, T. Wang, X. Min, F. Yi, and G. Zhai. “Deep Learning Based Full-Reference and No-Reference Quality Assessment Models for Compressed UGC Videos”. In:Int Conf Multimed. Expo Workshop. 2021, pp. 1–6
2021
-
[27]
No-Reference Image Quality Assessment in the Spatial Domain
A. Mittal, A. K. Moorthy, and A. C. Bovik. “No-Reference Image Quality Assessment in the Spatial Domain”. In:IEEE Trans. on Image Process.21.12 (Dec. 2012), pp. 4695–4708
2012
-
[28]
FAST-VQA: Efficient End-to-End Video Qual- ity Assessment with Fragment Sampling
H. Wu et al. “FAST-VQA: Efficient End-to-End Video Qual- ity Assessment with Fragment Sampling”. In:Comput. Vis. ECCV. Cham: Springer Nature Switzerland, 2022, pp. 538– 554
2022
-
[29]
Unified Quality Assessment of In-the-Wild Videos with Mixed Datasets Training
D. Li, T. Jiang, and M. Jiang. “Unified Quality Assessment of In-the-Wild Videos with Mixed Datasets Training”. In:Int. J. Comput. Vis.129.4 (Apr. 2021), pp. 1238–1257
2021
-
[30]
Rich Features for Perceptual Quality Assess- ment of UGC Videos
Y . Wang et al. “Rich Features for Perceptual Quality Assess- ment of UGC Videos”. In:Conf. Comput. Vis. Pattern Recog- nit.Nashville, USA: IEEE, June 2021, pp. 13430–13439
2021
-
[31]
Towards Explainable In-the-Wild Video Qual- ity Assessment: A Database and a Language-Prompted Ap- proach
H. Wu et al. “Towards Explainable In-the-Wild Video Qual- ity Assessment: A Database and a Language-Prompted Ap- proach”. In:Proc. 31st ACM Int. Conf. Multimed.Ottawa ON Canada: ACM, Oct. 26, 2023, pp. 1045–1054
2023
-
[32]
Q-ALIGN: Teaching LMMs for Visual Scoring via Discrete Text-Defined Levels
H. Wu et al. “Q-ALIGN: Teaching LMMs for Visual Scoring via Discrete Text-Defined Levels”. In:Proc. 41st Int. Conf. Mach. Learn.V ol. 235. Vienna, Austria: JMLR.org, July 21, 2024, pp. 54015–54029
2024
-
[33]
COVER: A Comprehensive Video Quality Eval- uator
C. He et al. “COVER: A Comprehensive Video Quality Eval- uator”. In:Conf. Comput. Vis. Pattern Recognit. Workshop. Seattle, USA: IEEE, June 17, 2024, pp. 5799–5809
2024
-
[34]
ITU-T.P .910: Subjective Video Quality Assessment Methods for Multimedia Applications. Oct. 2023
2023
-
[35]
A Vrate V oyager: An Open Source Online Testing Platform
S. Göring, R. R. Ramachandra Rao, S. Fremerey, and A. Raake. “A Vrate V oyager: An Open Source Online Testing Platform”. In:23rd Int. Workshop Multimed. Signal Process. Tampere, Finland: IEEE, Oct. 6, 2021, pp. 1–6
2021
-
[36]
SOS: The MOS Is Not Enough!
T. Hossfeld, R. Schatz, and S. Egger. “SOS: The MOS Is Not Enough!” In:3rd Int. Workshop Qual. Multimed. Exp. Mechelen, Belgium: IEEE, Sept. 2011, pp. 131–136
2011
-
[37]
A Large-Scale Evaluation of Subject Rating Behaviour in Visual Quality Assessment Studies
R. R. R. Rao, S. Göring, S. Fremerey, D. Keller, and A. Raake. “A Large-Scale Evaluation of Subject Rating Behaviour in Visual Quality Assessment Studies”. In:17th Int. Workshop Qual. Multimed. Exp.(Madrid, Spain). IEEE, 2025, pp. 1–7
2025
-
[38]
Averaging Cor- relations: Expected Values and Bias in Combined Pearson Rs and Fisher’s z Transformations
D. M. Corey, W. P. Dunlap, and M. J. Burke. “Averaging Cor- relations: Expected Values and Bias in Combined Pearson Rs and Fisher’s z Transformations”. In:The Journal of General Psychology125.3 (July 1998), pp. 245–261
1998
-
[39]
Comparing Correlated Correlation Coefficients
X.-L. Meng, R. Rosenthal, and D. B. Rubin. “Comparing Correlated Correlation Coefficients”. In:Psychol. Bull.111 (1992), pp. 172–175
1992
-
[40]
Netflix, Inc., 2016.URL: https : / / github
Netflix.VMAF - Video Multi-Method Assessment Fusion. Netflix, Inc., 2016.URL: https : / / github. com / Netflix / vmaf (visited on 01/09/2026)
2016
-
[41]
ITU-T.P .1401: Methods, Metrics and Procedures for Statis- tical Evaluation, Qualification and Comparison of Objective Quality Prediction Models. Jan. 2020
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.