EchoPilot: Training-Free Ultrasound Video Segmentation via Scale-Space Semantic Prompting and Reliability-Gated Memory
Pith reviewed 2026-06-29 22:28 UTC · model grok-4.3
The pith
EchoPilot segments ultrasound videos from one point click and a category name by picking optimal scale and gating memory updates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
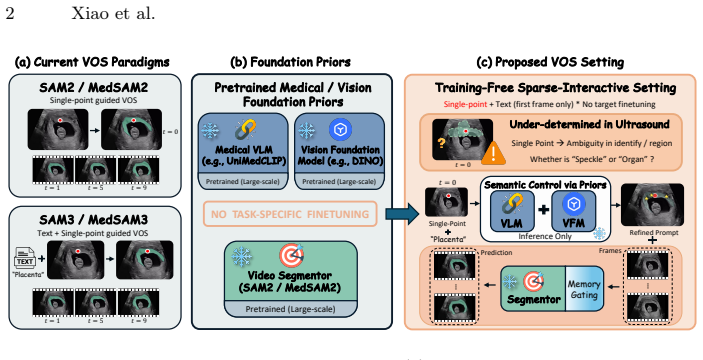
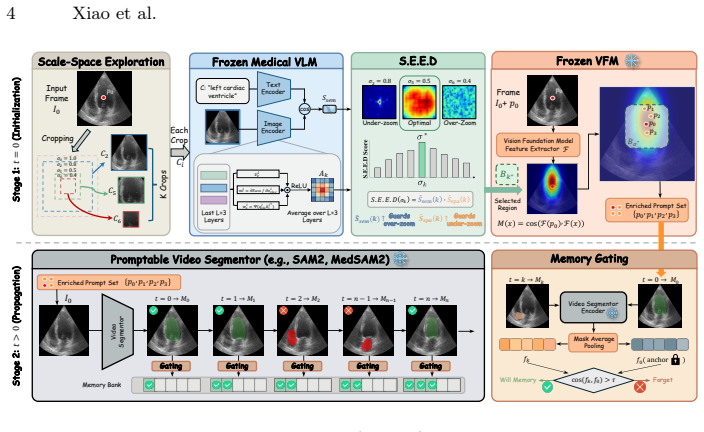
EchoPilot is a training-free framework that orchestrates a frozen medical VLM for semantic localization, a VFM for geometric features, and a promptable video segmentor. Scale-Space Semantic Prompting first selects an optimal contextual scale via the parameter-free S.E.E.D. criterion and then synthesizes auxiliary point prompts from dense foundation features. Reliability-Gated Memory selectively freezes the segmentor's memory bank on uncertain predictions to stop temporal drift. The approach requires only a single point and an anatomical category name on the first frame and is evaluated on three ultrasound video datasets plus a newly contributed fetal placenta collection.
What carries the argument
Scale-Space Semantic Prompting paired with Reliability-Gated Memory, which resolves single-point scale ambiguity through a parameter-free S.E.E.D. selection step and then limits propagation errors by freezing memory on low-reliability frames.
If this is right
- Ultrasound video segmentation becomes possible with only first-frame sparse input and no model retraining.
- Frozen general-purpose vision models can be combined for medical video tasks without ultrasound-specific fine-tuning.
- Temporal error accumulation is reduced by selective memory updates rather than continuous greedy propagation.
- A new public fetal placenta video dataset supports further work on dynamic placental tracking.
- Performance exceeds both training-free baselines and finetuned specialist models on the tested datasets.
Where Pith is reading between the lines
- The same S.E.E.D.-style scale selection might help other prompt-based medical segmentation tasks where boundary scale is uncertain.
- If the reliability gate works across more scanners, it could lower the annotation burden for building clinical video tools.
- Extending the gated memory idea to longer sequences or real-time streams would test whether drift stays controlled beyond the reported lengths.
- Pairing the method with live ultrasound hardware could measure whether the single-point interface actually speeds up clinical workflow.
Load-bearing premise
That the S.E.E.D. criterion can reliably identify the correct scale from one point and that freezing memory on uncertain frames avoids both error buildup and under-segmentation of valid but borderline predictions.
What would settle it
A test video in which the S.E.E.D.-chosen scale produces an initial mask that misses the target structure, or in which gating causes the method to drop correct masks on frames where a human would accept them, would show the two mechanisms do not deliver the claimed reliability.
Figures
read the original abstract
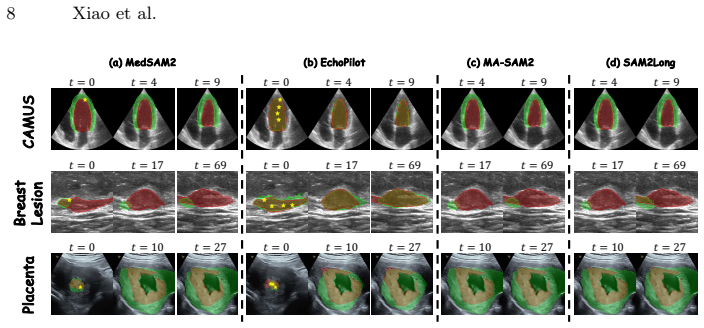
Ultrasound video segmentation is clinically valuable yet difficult due to speckle noise, weak boundaries, and rapid anatomical deformation. Recent promptable foundation models enable point-guided segmentation, but their direct deployment in ultrasound remains unreliable: a single point provides insufficient spatial context to resolve scale ambiguity, and greedy memory updates amplify early errors into severe temporal drift. We present EchoPilot, a training-free framework for ultrasound video segmentation under sparse first-frame interaction, requiring only a single point click and an anatomical category name. EchoPilot orchestrates a frozen medical vision-language model (VLM) for semantic localization, a vision foundation model (VFM) for dense geometric feature extraction, and a promptable video segmentor for mask prediction and propagation. To resolve initialization ambiguity, we propose Scale-Space Semantic Prompting, which first selects an optimal contextual view via a parameter-free S.E.E.D. (Semantic Energy-Entropy Density) criterion, and then synthesizes geometrically precise auxiliary point prompts from dense foundation features without additional user interaction. To reduce propagation drift, a Reliability-Gated Memory update is further introduced to selectively freeze the segmentor's memory bank under uncertain predictions, preventing error accumulation. We also contribute the first dynamic fetal placenta ultrasound video segmentation dataset with 671 annotated frames. Across three ultrasound video datasets, EchoPilot achieves state-of-the-art performance under the sparse-interactive setting, consistently outperforming training-free baselines and finetuned specialists.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces EchoPilot, a training-free framework for ultrasound video segmentation under sparse first-frame interaction (single point click plus anatomical category name). It orchestrates frozen medical VLM for semantic localization, VFM for geometric features, and a promptable video segmentor. Key components are Scale-Space Semantic Prompting via a parameter-free S.E.E.D. (Semantic Energy-Entropy Density) criterion to resolve single-point scale ambiguity by selecting optimal contextual views and synthesizing auxiliary prompts, plus a Reliability-Gated Memory update to selectively freeze the memory bank and prevent temporal drift. The work also contributes a new dynamic fetal placenta ultrasound video dataset (671 frames) and claims SOTA performance on three ultrasound video datasets, outperforming both training-free baselines and finetuned specialists.
Significance. If the empirical claims hold with proper verification, the result would be significant for clinical ultrasound applications by demonstrating that carefully designed prompting and memory rules on frozen foundation models can surpass both training-free methods and task-specific finetuned models without any training or large-scale annotations. The new fetal placenta dataset would also be a useful contribution to the community.
major comments (3)
- Abstract: the claim of achieving state-of-the-art performance across three datasets is asserted without any quantitative metrics, error bars, dataset splits, or ablation tables, so the magnitude and reliability of the reported gains cannot be assessed from the provided text.
- Scale-Space Semantic Prompting section (and associated S.E.E.D. description): the central claim that the parameter-free S.E.E.D. criterion reliably resolves scale ambiguity from a single point and drives the SOTA gains lacks isolated ablation evidence (e.g., default-scale initialization vs. S.E.E.D.-selected view) that directly ties the mechanism to the headline metrics.
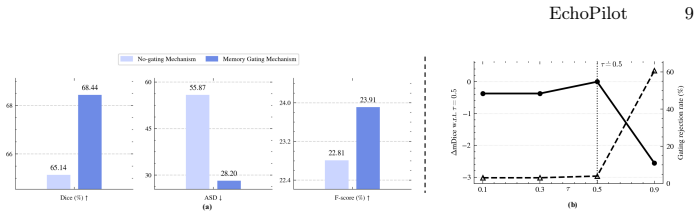
- Reliability-Gated Memory section: the claim that the gated update prevents temporal drift without introducing selection bias or under-segmentation on uncertain frames is load-bearing for outperforming finetuned specialists, yet no component ablation (always-update vs. gated memory) is described to quantify its individual contribution.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation of major revision. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: Abstract: the claim of achieving state-of-the-art performance across three datasets is asserted without any quantitative metrics, error bars, dataset splits, or ablation tables, so the magnitude and reliability of the reported gains cannot be assessed from the provided text.
Authors: We agree that the abstract should provide quantitative support for the SOTA claim. In the revised manuscript we will insert the key metrics (mean Dice and standard deviation on each dataset) along with a brief note on the evaluation protocol. revision: yes
-
Referee: Scale-Space Semantic Prompting section (and associated S.E.E.D. description): the central claim that the parameter-free S.E.E.D. criterion reliably resolves scale ambiguity from a single point and drives the SOTA gains lacks isolated ablation evidence (e.g., default-scale initialization vs. S.E.E.D.-selected view) that directly ties the mechanism to the headline metrics.
Authors: We acknowledge that an isolated ablation isolating the effect of S.E.E.D. would strengthen the causal link. We will add a dedicated ablation (default-scale vs. S.E.E.D.-selected view) with the corresponding headline metrics in the revised experiments section. revision: yes
-
Referee: Reliability-Gated Memory section: the claim that the gated update prevents temporal drift without introducing selection bias or under-segmentation on uncertain frames is load-bearing for outperforming finetuned specialists, yet no component ablation (always-update vs. gated memory) is described to quantify its individual contribution.
Authors: We agree that a component ablation is necessary to quantify the gated memory's contribution. We will include an explicit comparison (always-update vs. reliability-gated memory) in the revised manuscript to measure its effect on drift and final performance. revision: yes
Circularity Check
No circularity: new parameter-free criteria and gating rules are independently defined
full rationale
The paper's core contributions—Scale-Space Semantic Prompting via the parameter-free S.E.E.D. criterion and Reliability-Gated Memory—are presented as novel, explicitly defined mechanisms that operate on frozen external VLMs and VFMs without any fitting to the target segmentation metrics or reduction to self-citations. The abstract and described framework introduce selection and update rules whose definitions do not tautologically encode the reported performance gains; they remain falsifiable via ablations on the three datasets. No equations or derivations in the provided text collapse by construction to inputs, and no load-bearing self-citation chains appear. This is the standard case of a self-contained proposal of new heuristics.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Frozen pre-trained VLM, VFM, and promptable video segmentor can be combined without fine-tuning to produce reliable ultrasound segmentations
- ad hoc to paper The S.E.E.D. criterion selects an optimal contextual view from scale-space candidates
invented entities (2)
-
S.E.E.D. (Semantic Energy-Entropy Density) criterion
no independent evidence
-
Reliability-Gated Memory update rule
no independent evidence
Reference graph
Works this paper leans on
-
[1]
SAM 3: Segment Anything with Concepts
Carion, N., Gustafson, L., Hu, Y.T., Debnath, S., Hu, R., Suris, D., Ryali, C., Alwala,K.V.,Khedr,H.,Huang,A.,etal.:Sam3:Segmentanythingwithconcepts. arXiv preprint arXiv:2511.16719 (2025) 10 Xiao et al
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
IEEE Transactions on Medical Imaging (2025)
Chen, Y., Yildiz, Z., Li, Q., Chen, Y., Dong, H., Gu, H., Konz, N., Mazurowski, M.A.: Accelerating volumetric medical image annotation via short-long memory sam 2. IEEE Transactions on Medical Imaging (2025)
2025
-
[3]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Cheng, H.K., Oh, S.W., Price, B., Lee, J.Y., Schwing, A.: Putting the object back into video object segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 3151–3161 (2024)
2024
-
[4]
In: Proceedings of the IEEE/CVF international conference on computer vision
Ding, H., Liu, C., He, S., Jiang, X., Torr, P.H., Bai, S.: Mose: A new dataset for video object segmentation in complex scenes. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 20224–20234 (2023)
2023
-
[5]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Ding, S., Qian, R., Dong, X., Zhang, P., Zang, Y., Cao, Y., Guo, Y., Lin, D., Wang, J.: Sam2long: Enhancing sam 2 for long video segmentation with a training- free memory tree. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 13614–13624 (2025)
2025
-
[6]
Artificial Intelligence Review56(1), 457–531 (2023)
Gao, M., Zheng, F., Yu, J.J., Shan, C., Ding, G., Han, J.: Deep learning for video object segmentation: a review. Artificial Intelligence Review56(1), 457–531 (2023)
2023
-
[7]
IEEE transac- tions on pattern analysis and machine intelligence34(7), 1409–1422 (2011)
Kalal, Z., Mikolajczyk, K., Matas, J.: Tracking-learning-detection. IEEE transac- tions on pattern analysis and machine intelligence34(7), 1409–1422 (2011)
2011
-
[8]
BMC medicine 17(1), 195 (2019)
Kelly, C.J., Karthikesalingam, A., Suleyman, M., Corrado, G., King, D.: Key challenges for delivering clinical impact with artificial intelligence. BMC medicine 17(1), 195 (2019)
2019
-
[9]
arXiv preprint arXiv:2412.10372 (2024)
Khattak, M.U., Kunhimon, S., Naseer, M., Khan, S., Khan, F.S.: Unimed-clip: Towards a unified image-text pretraining paradigm for diverse medical imaging modalities. arXiv preprint arXiv:2412.10372 (2024)
-
[10]
IEEE transactions on medical imaging (2025)
Kim, S., Jin, P., Song, S., Chen, C., Li, Y., Ren, H., Li, X., Liu, T., Li, Q.: Echofm: Foundation model for generalizable echocardiogram analysis. IEEE transactions on medical imaging (2025)
2025
-
[11]
IEEE trans- actions on medical imaging38(9), 2198–2210 (2019)
Leclerc, S., Smistad, E., Pedrosa, J., Østvik, A., Cervenansky, F., Espinosa, F., Espeland, T., Berg, E.A.R., Jodoin, P.M., Grenier, T., et al.: Deep learning for seg- mentation using an open large-scale dataset in 2d echocardiography. IEEE trans- actions on medical imaging38(9), 2198–2210 (2019)
2019
-
[12]
In: International Conference on Medical Image Computing and Computer-Assisted Intervention
Li, J., Zheng, Q., Li, M., Liu, P., Wang, Q., Sun, L., Zhu, L.: Rethinking breast lesion segmentation in ultrasound: A new video dataset and a baseline network. In: International Conference on Medical Image Computing and Computer-Assisted Intervention. pp. 391–400. Springer (2022)
2022
-
[13]
arXiv preprint arXiv:2511.19046 (2025)
Liu, A., Xue, R., Cao, X.R., Shen, Y., Lu, Y., Li, X., Chen, Q., Chen, J.: Medsam3: Delving into segment anything with medical concepts. arXiv preprint arXiv:2511.19046 (2025)
-
[14]
IEEE transactions on medical imaging39(10), 3064–3078 (2020)
Liu, X., Zhou, T., Lu, M., Yang, Y., He, Q., Luo, J.: Deep learning for ultrasound localization microscopy. IEEE transactions on medical imaging39(10), 3064–3078 (2020)
2020
-
[15]
arXiv preprint arXiv:2504.03600 (2025) 4
Ma, J., Yang, Z., Kim, S., Chen, B., Baharoon, M., Fallahpour, A., Asakereh, R., Lyu, H., Wang, B.: Medsam2: Segment anything in 3d medical images and videos. arXiv preprint arXiv:2504.03600 (2025)
-
[16]
IEEE Transactions on medical imaging25(8), 987–1010 (2006)
Noble, J.A., Boukerroui, D.: Ultrasound image segmentation: a survey. IEEE Transactions on medical imaging25(8), 987–1010 (2006)
2006
-
[17]
In: Proceedings of the IEEE/CVF international conference on computer vision
Oh, S.W., Lee, J.Y., Xu, N., Kim, S.J.: Video object segmentation using space-time memory networks. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 9226–9235 (2019)
2019
-
[18]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Perazzi, F., Khoreva, A., Benenson, R., Schiele, B., Sorkine-Hornung, A.: Learn- ing video object segmentation from static images. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 2663–2672 (2017) EchoPilot 11
2017
-
[19]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Perazzi, F., Pont-Tuset, J., McWilliams, B., Van Gool, L., Gross, M., Sorkine- Hornung, A.: A benchmark dataset and evaluation methodology for video object segmentation. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 724–732 (2016)
2016
-
[20]
In: International Conference on Learning Representations
Ravi, N., Gabeur, V., Hu, Y.T., Hu, R., Ryali, C., Ma, T., Khedr, H., Rädle, R., Rolland, C., Gustafson, L., et al.: Sam 2: Segment anything in images and videos. In: International Conference on Learning Representations. vol. 2025, pp. 28085–28128 (2025)
2025
-
[21]
IEEE Transactions on Image Processing21(10), 4334–4348 (2012)
Salti, S., Cavallaro, A., Di Stefano, L.: Adaptive appearance modeling for video tracking: Survey and evaluation. IEEE Transactions on Image Processing21(10), 4334–4348 (2012)
2012
-
[22]
Siméoni, O., Vo, H.V., Seitzer, M., Baldassarre, F., Oquab, M., Jose, C., Khali- dov, V., Szafraniec, M., Yi, S., Ramamonjisoa, M., et al.: Dinov3. arXiv preprint arXiv:2508.10104 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
IEEE Transactions on sonics and ultrasonics30(3), 156–163 (2005)
Wagner, R.F., Smith, S.W., Sandrik, J.M., Lopez, H.: Statistics of speckle in ultra- sound b-scans. IEEE Transactions on sonics and ultrasonics30(3), 156–163 (2005)
2005
-
[24]
IEEE transactions on pattern analysis and machine intelligence41(4), 985–998 (2018)
Wang, W., Shen, J., Porikli, F., Yang, R.: Semi-supervised video object segmen- tation with super-trajectories. IEEE transactions on pattern analysis and machine intelligence41(4), 985–998 (2018)
2018
-
[25]
Radiology295(1), 4–15 (2020)
Willemink, M.J., Koszek, W.A., Hardell, C., Wu, J., Fleischmann, D., Harvey, H., Folio, L.R., Summers, R.M., Rubin, D.L., Lungren, M.P.: Preparing medical imaging data for machine learning. Radiology295(1), 4–15 (2020)
2020
-
[26]
Medical image analysis102, 103547 (2025)
Wu, J., Wang, Z., Hong, M., Ji, W., Fu, H., Xu, Y., Xu, M., Jin, Y.: Medical sam adapter: Adapting segment anything model for medical image segmentation. Medical image analysis102, 103547 (2025)
2025
-
[27]
In: International Conference on Medical Image Computing and Computer- Assisted Intervention
Yan, Z., Song, S., Song, D., Li, Y., Zhou, R., Sun, W., Chen, Z., Kim, S., Ren, H., Liu, T., et al.: Samed-2: Selective memory enhanced medical segment anything model. In: International Conference on Medical Image Computing and Computer- Assisted Intervention. pp. 540–550. Springer (2025)
2025
-
[28]
In: International Conference on Medical Image Computing and Computer-Assisted Intervention
Yin, M., Wang, F., Ye, X., Meng, Y., Fu, Z.: Memory-augmented sam2 for training- free surgical video segmentation. In: International Conference on Medical Image Computing and Computer-Assisted Intervention. pp. 328–337. Springer (2025)
2025
-
[29]
Zhang, S., Xu, Y., Usuyama, N., Xu, H., Bagga, J., Tinn, R., Preston, S., Rao, R., Wei, M., Valluri, N., et al.: Biomedclip: a multimodal biomedical foundation model pretrained from fifteen million scientific image-text pairs. arXiv preprint arXiv:2303.00915 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[30]
In: International Conference on Machine Learning
Zhao,C.,Wang,K.,Zeng,X.,Zhao,R.,Chan,A.B.:Gradient-basedvisualexplana- tion for transformer-based clip. In: International Conference on Machine Learning. pp. 61072–61091. PMLR (2024)
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.