VEN-VL: A Visual Ensemble MoE Framework for Effective and Efficient Multi-Modal Understanding
Pith reviewed 2026-06-29 22:21 UTC · model grok-4.3
The pith
VEN-VL unifies visual representations from multiple perspectives then compacts them via mixture-of-experts routing and explicit reconstruction supervision to raise information density with fewer tokens.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
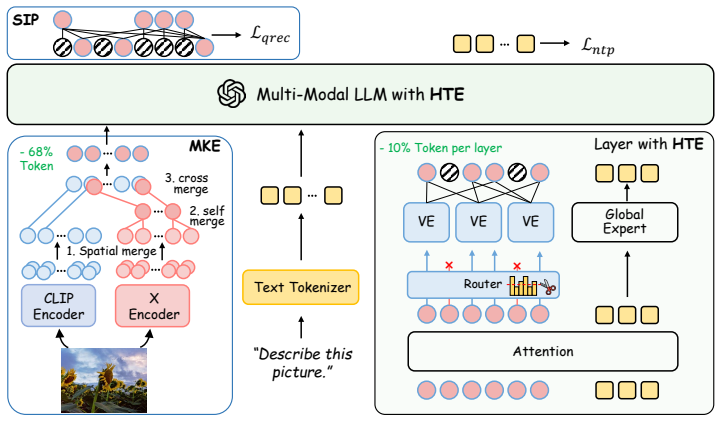
VEN-VL follows an enrich-then-compact principle: first unifying the visual representations of different perspectives to increase information capacity, then progressively compacting it with adaptive routers in specialized visual experts to enhance information density, while incorporating explicit visual supervision to preserve crucial information.
What carries the argument
The visual ensemble MoE framework that enriches multi-perspective visual features and then applies adaptive expert routing for compaction together with reconstruction supervision.
If this is right
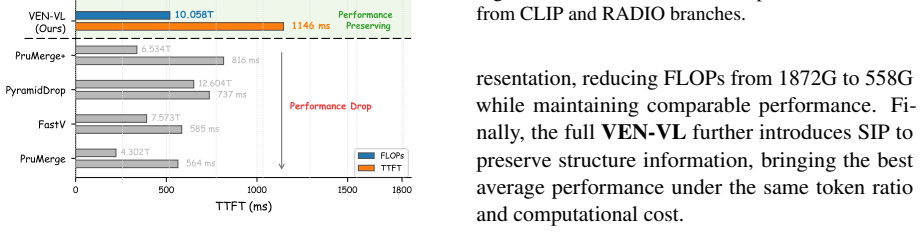
- Complex visual tasks can be solved at high accuracy with only a small number of information-condensed tokens.
- The performance-efficiency trade-off gap narrows because enrichment precedes compaction rather than relying on single-clue pruning.
- Explicit reconstruction supervision helps the compacted tokens retain the structural details needed for downstream reasoning.
- Adaptive routers in specialized visual experts allow the compaction step to focus capacity where it matters most for each input.
Where Pith is reading between the lines
- The same enrich-then-compact pattern could be tested on text-only or audio inputs to see whether multi-perspective enrichment helps other modalities.
- If the reconstruction loss proves critical, future work might explore whether weaker or cheaper forms of reconstruction supervision suffice.
- Deployment on edge devices would benefit if the method scales to even smaller token budgets without retraining the downstream language model.
Load-bearing premise
That combining representations from different visual perspectives and then routing them through experts with a reconstruction objective will avoid information loss that single-perspective compression already produces.
What would settle it
A controlled experiment on a standard visual-question-answering benchmark in which VEN-VL using the same token budget scores lower than a strong single-view compression baseline would falsify the central claim.
Figures


read the original abstract
Despite the remarkable progress achieved by recent efficient methods in accelerating multimodal understanding, they still suffer from noticeable performance degradation. Their emphasis on the high compression ratio of a single visual clue and reliance on the heuristic pruning strategy with coarse attention alignment incurs a bottleneck on the information capacity and density of visual tokens. Addressing this limitation, we propose VEN-VL, a visual ensemble MoE framework for effective and efficient perception following the enrich then compact principle. Specifically, we first enrich the information capacity by unifying the visual representations of different perspectives, and then progressively compact it with adaptive routers in specialized visual experts to enhance the information density. Furthermore, we incorporate the reconstruction ability of vanilla structure via explicit visual supervision, facilitating crucial information preservation. Experimental results demonstrate our superiority in complex visual tasks with few information-condensed tokens, which effectively bridges the gap between performance and efficiency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes VEN-VL, a visual ensemble MoE framework for multi-modal understanding that follows an enrich-then-compact principle. It unifies visual representations from multiple perspectives to increase information capacity, applies adaptive routers within specialized visual experts for progressive compaction to raise information density, and adds explicit reconstruction supervision to preserve crucial information. The central claim is that this yields experimental superiority on complex visual tasks while using few information-condensed tokens, thereby bridging performance and efficiency gaps left by prior high-compression single-clue methods that rely on heuristic pruning.
Significance. If the experimental claims are substantiated, the multi-perspective unification combined with MoE-based adaptive compaction and reconstruction loss could offer a more principled alternative to heuristic pruning, potentially improving the performance-efficiency frontier in efficient multimodal models. The explicit reconstruction supervision is a concrete mechanism that may help mitigate information loss, and the overall pipeline is internally coherent.
major comments (2)
- [Abstract] Abstract: the central claim of 'experimental results demonstrate our superiority' supplies no baselines, metrics, ablation details, datasets, or quantitative comparisons, rendering the superiority assertion impossible to assess and directly load-bearing for the paper's main contribution.
- [§4] §4 (Experiments): without tables reporting specific metrics (e.g., accuracy, efficiency ratios), comparisons to prior methods, or ablation studies on the MoE routers and reconstruction term, the claim that the framework 'bridges the gap between performance and efficiency' cannot be verified.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract and experimental sections. We address each major comment below and will revise the manuscript to improve verifiability of the claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of 'experimental results demonstrate our superiority' supplies no baselines, metrics, ablation details, datasets, or quantitative comparisons, rendering the superiority assertion impossible to assess and directly load-bearing for the paper's main contribution.
Authors: We agree that the abstract's superiority claim would be stronger with explicit quantitative anchors. In the revised version we will expand the abstract to report key metrics (e.g., accuracy on VQA and captioning benchmarks), the main baselines, and the number of condensed tokens used, while preserving the overall length constraint. revision: yes
-
Referee: [§4] §4 (Experiments): without tables reporting specific metrics (e.g., accuracy, efficiency ratios), comparisons to prior methods, or ablation studies on the MoE routers and reconstruction term, the claim that the framework 'bridges the gap between performance and efficiency' cannot be verified.
Authors: The current manuscript contains tables with accuracy, efficiency ratios, and comparisons to prior methods. However, the ablation studies on the MoE routers and reconstruction loss are not presented with sufficient detail. We will revise §4 to add dedicated ablation tables and explicit discussion of these components so that the performance-efficiency claim can be directly verified. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper proposes an empirical architecture (VEN-VL) that enriches visual representations across perspectives then compacts them via MoE routers plus reconstruction supervision. No equations, first-principles derivations, or predictions appear in the provided text; the central claims rest on experimental results rather than any reduction of outputs to fitted inputs or self-citations by construction. The enrich-then-compact pipeline is presented as a design choice with no load-bearing self-referential steps or uniqueness theorems invoked. This is the normal case for an applied ML framework paper whose validity is intended to be assessed externally via benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Token Merging: Your ViT But Faster
Token merging: Your vit but faster.arXiv preprint arXiv:2210.09461. Liang Chen, Haozhe Zhao, Tianyu Liu, Shuai Bai, Jun- yang Lin, Chang Zhou, and Baobao Chang. 2024a. An image is worth 1/2 tokens after layer 2: Plug-and- play inference acceleration for large vision-language models. InECCV, pages 19–35. Springer. Lin Chen, Jinsong Li, Xiaoyi Dong, Pan Zha...
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Springer. Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Mar- cel Blistein, Ori Ram, Dan Zhang, Evan Rosen, and 1 others. 2025. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261. Wenliang Dai, Ju...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Learning Factored Representations in a Deep Mixture of Experts
Learning factored representations in a deep mixture of experts.arXiv preprint arXiv:1312.4314. Chaoyou Fu, Peixian Chen, Yunhang Shen, Yulei Qin, Mengdan Zhang, Xu Lin, Zhenyu Qiu, Wei Lin, Jin- rui Yang, Xiawu Zheng, Ke Li, Xing Sun, and Ron- grong Ji. 2024. MME: A comprehensive evaluation benchmark for multimodal large language models. arXiv preprint ar...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
A diagram is worth a dozen images. InECCV, pages 235–251. Springer. Zhenglun Kong, Peiyan Dong, Xiaolong Ma, Xin Meng, Wei Niu, Mengshu Sun, Xuan Shen, Geng Yuan, Bin Ren, Hao Tang, and 1 others. 2022. Spvit: Enabling faster vision transformers via latency-aware soft to- ken pruning. InECCV, pages 620–640. Springer. 9 Hugo Laurençon, Andrés Marafioti, Vic...
-
[5]
Kimi-vl technical report.arXiv preprint arXiv:2504.07491. Qwen Team and 1 others. 2024. Qwen2 technical report. arXiv preprint arXiv:2407.10671, 2(3). Haochen Wang, Anlin Zheng, Yucheng Zhao, Tiancai Wang, Zheng Ge, Xiangyu Zhang, and Zhaoxiang Zhang. 2024a. Reconstructive visual instruction tun- ing.arXiv preprint arXiv:2410.09575. Peng Wang, Shuai Bai, ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
arXiv preprint arXiv:2501.03895 (2025) 4
Llava-mini: Efficient image and video large multimodal models with one vision token.arXiv preprint arXiv:2501.03895. Yuan Zhang, Chun-Kai Fan, Junpeng Ma, Wenzhao Zheng, Tao Huang, Kuan Cheng, Denis Gudovskiy, Tomoyuki Okuno, Yohei Nakata, Kurt Keutzer, and 1 others. 2024. Sparsevlm: Visual token sparsification for efficient vision-language model inferenc...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.