STORM: Internalized Modeling for Spatial-Temporal Reasoning in Video-Language Models
Pith reviewed 2026-06-29 23:01 UTC · model grok-4.3
The pith
STORM trains video-language models to reason through bounded latent trajectories instead of explicit text chains or external tools.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
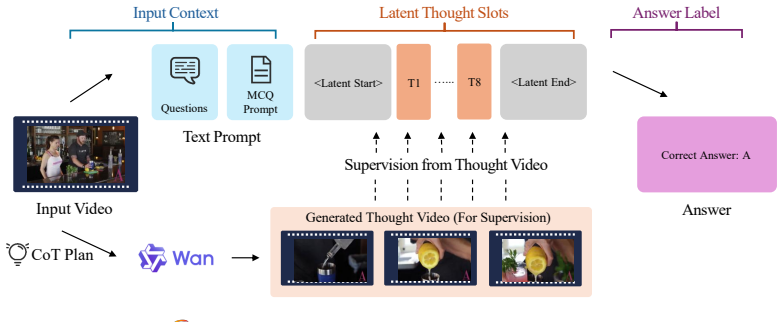
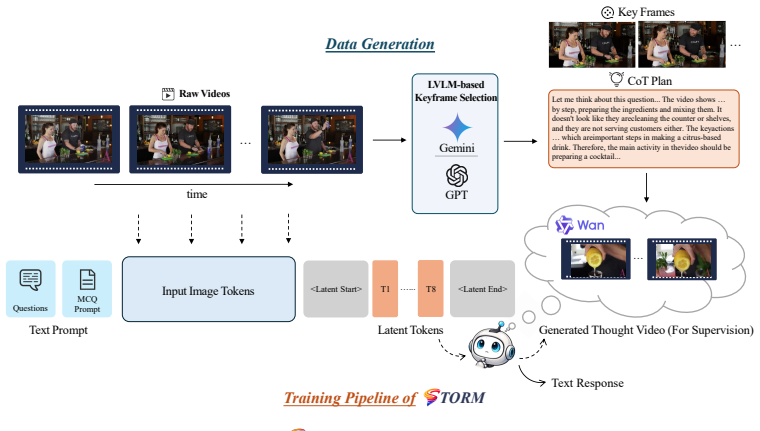
The central claim is that LVLMs acquire effective spatial-temporal reasoning when their latent tokens are first aligned to thought-video representations and then refined under answer-only supervision, allowing the model to replace textual chain-of-thought and external visual pipelines with a bounded continuous latent trajectory that encodes motion, order, and state changes.
What carries the argument
Bounded continuous latent trajectory: an internal rollout of latent states that simulates the dynamics of a thought video without regenerating pixels or text.
If this is right
- Video reasoning accuracy rises on VideoMME, MVBench, TempCompass, and MMVU while inference latency drops because no videos are regenerated and no external tools are called.
- The model needs no step-by-step textual annotations or repeated frame reinsertion once training is complete.
- Reasoning remains grounded in the visual dynamics learned during the alignment stage even though no visual input is re-encoded at test time.
- The same two-stage recipe applies uniformly across tasks that require tracking motion and evolving visual states.
Where Pith is reading between the lines
- The same internalization pattern could be tried on other sequential reasoning domains where external simulation is expensive.
- Performance may degrade on videos whose temporal span exceeds the length of the bounded rollout used in training.
- Varying the length or dimensionality of the latent rollout offers a direct experimental knob for testing how much dynamic information the internal state can carry.
Load-bearing premise
Alignment of latent tokens to thought-video representations followed by answer-only supervision produces reasoning that generalizes without explicit step-by-step labels or external visual evidence at inference time.
What would settle it
A controlled test on a video reasoning benchmark where STORM accuracy falls below that of an explicit CoT baseline on sequences whose critical motion details are not captured by the training thought videos.
Figures





read the original abstract
Many video reasoning tasks require tracking motion, temporal order, and evolving visual states across frames. Existing methods built on large vision-language models (LVLMs) often address this challenge by externalizing reasoning through textual chain-of-thought (CoT), keyframe selection, repeated frame reinsertion, or external tool use. While effective, such pipelines increase inference-time latency and engineering complexity, and they force temporal-visual evidence to be serialized into text or repeatedly re-encoded from frames. Inspired by the intuition that visual reasoning can occur implicitly before verbalization, we propose STORMS (Spatial-Temporal reasOning via inteRnalized Modeling), a two-stage framework that teaches LVLMs to reason through bounded continuous latent trajectories instead of explicit textual CoT. In Stage I, STORMS aligns latent tokens with thought-video representations derived from generated videos, grounding the latent states in dynamic visual evidence. In Stage II, the model is further trained with answer-only supervision, encouraging the reasoning process to be internalized without step-by-step annotations. Generated thought videos are used only during training; at inference, STORMS performs a bounded latent rollout without regenerating videos, reinserting frames, or invoking external visual tools. Experiments on VideoMME, MVBench, TempCompass, and MMVU show that STORMS improves video reasoning accuracy while substantially reducing inference overhead compared with tool or video-generation-based reasoning pipelines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces STORMS, a two-stage framework for LVLMs that internalizes spatial-temporal video reasoning via bounded continuous latent trajectories instead of explicit textual CoT, keyframe reinsertion, or external tools. Stage I aligns latent tokens to thought-video representations derived from generated videos; Stage II applies answer-only supervision to encourage internalization. At inference the model performs a bounded latent rollout without video regeneration or external evidence. Experiments on VideoMME, MVBench, TempCompass, and MMVU are reported to show accuracy gains together with substantially lower inference overhead relative to tool- or generation-based baselines.
Significance. If the central claim holds, the work could meaningfully advance efficient video reasoning by embedding dynamic visual state tracking inside the model's latent space rather than serializing it externally. The design choice to restrict generated videos to training only is a concrete strength for reducing inference cost.
major comments (1)
- [Abstract (Stage II description)] Abstract (Stage II description): answer-only supervision supplies no auxiliary loss, rollout consistency term, or latent-state probing mechanism that would force the model to maintain and use the bounded continuous latent trajectories rather than collapsing to a direct frame-to-answer mapping. Because this is the sole mechanism asserted to produce internalized reasoning, the reported accuracy improvements on VideoMME/MVBench could be explained by ordinary fine-tuning and do not yet substantiate the claim that inference proceeds via latent rollout without external evidence.
minor comments (1)
- [Abstract] The abstract states that generated thought videos are used only during training, yet provides no quantitative comparison of training versus inference compute or memory.
Simulated Author's Rebuttal
We thank the referee for the thoughtful review and the opportunity to address concerns about the substantiation of internalized reasoning. We respond to the major comment below.
read point-by-point responses
-
Referee: Abstract (Stage II description): answer-only supervision supplies no auxiliary loss, rollout consistency term, or latent-state probing mechanism that would force the model to maintain and use the bounded continuous latent trajectories rather than collapsing to a direct frame-to-answer mapping. Because this is the sole mechanism asserted to produce internalized reasoning, the reported accuracy improvements on VideoMME/MVBench could be explained by ordinary fine-tuning and do not yet substantiate the claim that inference proceeds via latent rollout without external evidence.
Authors: We appreciate the referee's observation that Stage II relies on answer-only supervision without auxiliary losses, consistency terms, or probing. This choice is deliberate to avoid additional supervision or complexity. The bounded continuous latent trajectories are established during Stage I through explicit alignment of latent tokens to representations derived from generated thought videos, which grounds the latents in dynamic spatial-temporal visual evidence. Stage II then applies answer-only supervision on top of this alignment to encourage the model to rely on these pre-grounded latents for reasoning rather than externalizing steps. While direct probing of latent states during inference is not reported, the experimental results provide supporting evidence: accuracy improvements across VideoMME, MVBench, TempCompass, and MMVU occur together with substantially lower inference overhead relative to baselines that require video regeneration or external tools. This overhead reduction is inconsistent with a collapse to direct frame-to-answer mapping or ordinary fine-tuning, as such approaches would not eliminate the need for external evidence at test time. We will revise the abstract to more explicitly describe the synergistic role of the two stages in enabling internalized latent rollout. revision: yes
Circularity Check
No circularity: method is procedural training description with no equations or self-referential derivations
full rationale
The paper describes a two-stage training procedure (Stage I alignment to thought-video representations, Stage II answer-only supervision) without any equations, first-principles derivations, or parameter-fitting steps that reduce to inputs by construction. No self-citations are invoked as load-bearing uniqueness theorems, and no ansatzes or renamings of known results appear. Performance claims rest on experimental results rather than algebraic equivalence to training data. This matches the default expectation of no circularity.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Latent tokens in LVLMs can be aligned with dynamic visual representations derived from generated videos to ground reasoning
- domain assumption Answer-only supervision suffices to internalize spatial-temporal reasoning without step-by-step annotations
invented entities (2)
-
bounded continuous latent trajectories
no independent evidence
-
thought-video representations
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Temporal chain of thought: Long-video understanding by thinking in frames.Advances in Neural Information Processing Systems, 38:143018–143046, 2026
Anurag Arnab, Ahmet Iscen, Mathilde Caron, Alireza Fathi, and Cordelia Schmid. Temporal chain of thought: Long-video understanding by thinking in frames.Advances in Neural Information Processing Systems, 38:143018–143046, 2026
2026
-
[2]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. Qwen2.5-vl technical report. A...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Perception tokens enhance visual reasoning in multimodal language models
Mahtab Bigverdi, Zelun Luo, Cheng-Yu Hsieh, Ethan Shen, Dongping Chen, Linda G Shapiro, and Ranjay Krishna. Perception tokens enhance visual reasoning in multimodal language models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 3836–3845, 2025
2025
-
[4]
Meng Cao, Xingyu Li, Xue Liu, Ian Reid, and Xiaodan Liang. Spatialdreamer: Incentivizing spatial reasoning via active mental imagery.arXiv preprint arXiv:2512.07733, 2025
-
[5]
Eagle 2.5: Boosting long-context post-training for frontier vision-language models.Advances in Neural Information Processing Systems, 38: 91077–91100, 2026
Guo Chen, Zhiqi Li, Shihao Wang, Jindong Jiang, Yicheng Liu, Lidong Lu, De-An Huang, Wonmin Byeon, Matthieu Le, Max Ehrlich, et al. Eagle 2.5: Boosting long-context post-training for frontier vision-language models.Advances in Neural Information Processing Systems, 38: 91077–91100, 2026
2026
-
[6]
Sharegpt4video: Improving video understanding and generation with better captions.Advances in Neural Information Processing Systems, 37: 19472–19495, 2024
Lin Chen, Xilin Wei, Jinsong Li, Xiaoyi Dong, Pan Zhang, Yuhang Zang, Zehui Chen, Haodong Duan, Bin Lin, Zhenyu Tang, et al. Sharegpt4video: Improving video understanding and generation with better captions.Advances in Neural Information Processing Systems, 37: 19472–19495, 2024
2024
-
[7]
Video-Holmes: Can MLLM Think Like Holmes for Complex Video Reasoning?
Junhao Cheng, Yuying Ge, Teng Wang, Yixiao Ge, Jing Liao, and Ying Shan. Video-holmes: Can mllm think like holmes for complex video reasoning?arXiv preprint arXiv:2505.21374, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
VideoLLaMA 2: Advancing Spatial-Temporal Modeling and Audio Understanding in Video-LLMs
Zesen Cheng, Sicong Leng, Hang Zhang, Yifei Xin, Xin Li, Guanzheng Chen, Yongxin Zhu, Wenqi Zhang, Ziyang Luo, Deli Zhao, et al. Videollama 2: Advancing spatial-temporal modeling and audio understanding in video-llms.arXiv preprint arXiv:2406.07476, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
Don’t look only once: Towards multimodal interactive reasoning with selective visual revisitation
Jiwan Chung, Junhyeok Kim, Siyeol Kim, Jaeyoung Lee, Min Soo Kim, and Youngjae Yu. Don’t look only once: Towards multimodal interactive reasoning with selective visual revisitation. arXiv e-prints, pages arXiv–2505, 2025
2025
-
[10]
From Explicit CoT to Implicit CoT: Learning to Internalize CoT Step by Step
Yuntian Deng, Yejin Choi, and Stuart Shieber. From explicit cot to implicit cot: Learning to internalize cot step by step.arXiv preprint arXiv:2405.14838, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
Jiajun Fei, Dian Li, Zhidong Deng, Zekun Wang, Gang Liu, and Hui Wang. Video-ccam: Enhancing video-language understanding with causal cross-attention masks for short and long videos.arXiv preprint arXiv:2408.14023, 2024
-
[12]
Video-r1: Reinforcing video reasoning in mllms.Advances in Neural Information Processing Systems, 38:99114–99137, 2026
Kaituo Feng, Kaixiong Gong, Bohao Li, Zonghao Guo, Yibing Wang, Tianshuo Peng, Junfei Wu, Xiaoying Zhang, Benyou Wang, and Xiangyu Yue. Video-r1: Reinforcing video reasoning in mllms.Advances in Neural Information Processing Systems, 38:99114–99137, 2026
2026
-
[13]
Mme: A comprehensive evaluation benchmark for multimodal large language models.Advances in Neural Information Processing Systems, 38, 2026
Chaoyou Fu, Peixian Chen, Yunhang Shen, Yulei Qin, Mengdan Zhang, Xu Lin, Jinrui Yang, Xiawu Zheng, Ke Li, Xing Sun, et al. Mme: A comprehensive evaluation benchmark for multimodal large language models.Advances in Neural Information Processing Systems, 38, 2026
2026
-
[14]
Blink: Multimodal large language models can see but not perceive
Xingyu Fu, Yushi Hu, Bangzheng Li, Yu Feng, Haoyu Wang, Xudong Lin, Dan Roth, Noah A Smith, Wei-Chiu Ma, and Ranjay Krishna. Blink: Multimodal large language models can see but not perceive. InEuropean Conference on Computer Vision, pages 148–166. Springer, 2024. 10
2024
-
[15]
Xingyu Fu, Minqian Liu, Zhengyuan Yang, John Corring, Yijuan Lu, Jianwei Yang, Dan Roth, Dinei Florencio, and Cha Zhang. Refocus: Visual editing as a chain of thought for structured image understanding.arXiv preprint arXiv:2501.05452, 2025
-
[16]
Chain-of-Frames: Advancing Video Understanding in Multimodal LLMs via Frame-Aware Reasoning
Sara Ghazanfari, Francesco Croce, Nicolas Flammarion, Prashanth Krishnamurthy, Farshad Khorrami, and Siddharth Garg. Chain-of-frames: Advancing video understanding in multimodal llms via frame-aware reasoning.arXiv preprint arXiv:2506.00318, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Videoespresso: A large-scale chain-of-thought dataset for fine-grained video reasoning via core frame selection
Songhao Han, Wei Huang, Hairong Shi, Le Zhuo, Xiu Su, Shifeng Zhang, Xu Zhou, Xiaojuan Qi, Yue Liao, and Si Liu. Videoespresso: A large-scale chain-of-thought dataset for fine-grained video reasoning via core frame selection. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 26181–26191, 2025
2025
-
[18]
Training Large Language Models to Reason in a Continuous Latent Space
Shibo Hao, Sainbayar Sukhbaatar, DiJia Su, Xian Li, Zhiting Hu, Jason Weston, and Yuandong Tian. Training large language models to reason in a continuous latent space.arXiv preprint arXiv:2412.06769, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card.arXiv preprint arXiv:2410.21276, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
Daeun Lee, Shoubin Yu, Yue Zhang, and Mohit Bansal. Visioncoach: Reinforcing grounded video reasoning via visual-perception prompting.arXiv preprint arXiv:2603.14659, 2026
-
[21]
Bangzheng Li, Ximeng Sun, Jiang Liu, Ze Wang, Jialian Wu, Xiaodong Yu, Hao Chen, Emad Barsoum, Muhao Chen, and Zicheng Liu. Latent visual reasoning.arXiv preprint arXiv:2509.24251, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
LLaVA-OneVision: Easy Visual Task Transfer
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Yanwei Li, Ziwei Liu, et al. Llava-onevision: Easy visual task transfer.arXiv preprint arXiv:2408.03326, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
Mvbench: A comprehensive multi-modal video understanding benchmark
Kunchang Li, Yali Wang, Yinan He, Yizhuo Li, Yi Wang, Yi Liu, Zun Wang, Jilan Xu, Guo Chen, Ping Luo, et al. Mvbench: A comprehensive multi-modal video understanding benchmark. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22195–22206, 2024
2024
-
[24]
Llama-vid: An image is worth 2 tokens in large language models
Yanwei Li, Chengyao Wang, and Jiaya Jia. Llama-vid: An image is worth 2 tokens in large language models. InEuropean Conference on Computer Vision, pages 323–340. Springer, 2024
2024
-
[25]
Univer- sal video temporal grounding with generative multi-modal large language models.Advances in Neural Information Processing Systems, 38:64426–64455, 2026
Zeqian Li, Shangzhe Di, Zhonghua Zhai, Weilin Huang, Yanfeng Wang, and Weidi Xie. Univer- sal video temporal grounding with generative multi-modal large language models.Advances in Neural Information Processing Systems, 38:64426–64455, 2026
2026
-
[26]
Video-llava: Learning united visual representation by alignment before projection
Bin Lin, Yang Ye, Bin Zhu, Jiaxi Cui, Munan Ning, Peng Jin, and Li Yuan. Video-llava: Learning united visual representation by alignment before projection. InProceedings of the 2024 conference on empirical methods in natural language processing, pages 5971–5984, 2024
2024
-
[27]
Kangaroo: A powerful video-language model supporting long-context video input: J
Jiajun Liu, Yibing Wang, Hanghang Ma, Xiaoping Wu, Xiaoqi Ma, Xiaoming Wei, Jianbin Jiao, Enhua Wu, and Jie Hu. Kangaroo: A powerful video-language model supporting long-context video input: J. liu et al.International Journal of Computer Vision, 134(3):114, 2026
2026
-
[28]
St-llm: Large language models are effective temporal learners
Ruyang Liu, Chen Li, Haoran Tang, Yixiao Ge, Ying Shan, and Ge Li. St-llm: Large language models are effective temporal learners. InEuropean Conference on Computer Vision, pages 1–18. Springer, 2024
2024
-
[29]
Tempcompass: Do video llms really understand videos? InFindings of the Association for Computational Linguistics: ACL 2024, pages 8731–8772, 2024
Yuanxin Liu, Shicheng Li, Yi Liu, Yuxiang Wang, Shuhuai Ren, Lei Li, Sishuo Chen, Xu Sun, and Lu Hou. Tempcompass: Do video llms really understand videos? InFindings of the Association for Computational Linguistics: ACL 2024, pages 8731–8772, 2024
2024
-
[30]
Sat: Dynamic spatial aptitude training for multimodal language models
Arijit Ray, Jiafei Duan, Ellis Brown, Reuben Tan, Dina Bashkirova, Rose Hendrix, Kiana Ehsani, Aniruddha Kembhavi, Bryan A Plummer, Ranjay Krishna, et al. Sat: Dynamic spatial aptitude training for multimodal language models.arXiv preprint arXiv:2412.07755, 2024. 11
-
[31]
Mull-Tokens: Modality-Agnostic Latent Thinking
Arijit Ray, Ahmed Abdelkader, Chengzhi Mao, Bryan A Plummer, Kate Saenko, Ranjay Krishna, Leonidas Guibas, and Wen-Sheng Chu. Mull-tokens: Modality-agnostic latent thinking.arXiv preprint arXiv:2512.10941, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
Zoomeye: Enhancing multimodal llms with human-like zooming capabilities through tree-based image exploration
Haozhan Shen, Kangjia Zhao, Tiancheng Zhao, Ruochen Xu, Zilun Zhang, Mingwei Zhu, and Jianwei Yin. Zoomeye: Enhancing multimodal llms with human-like zooming capabilities through tree-based image exploration. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 6613–6629, 2025
2025
-
[33]
Codi: Com- pressing chain-of-thought into continuous space via self-distillation
Zhenyi Shen, Hanqi Yan, Linhai Zhang, Zhanghao Hu, Yali Du, and Yulan He. Codi: Com- pressing chain-of-thought into continuous space via self-distillation. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 677–693, 2025
2025
-
[34]
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Gemini Team, Petko Georgiev, Ving Ian Lei, Ryan Burnell, Libin Bai, Anmol Gulati, Garrett Tanzer, Damien Vincent, Zhufeng Pan, Shibo Wang, et al. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context.arXiv preprint arXiv:2403.05530, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[35]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
Shijian Wang, Jiarui Jin, Xingjian Wang, Linxin Song, Runhao Fu, Hecheng Wang, Zongyuan Ge, Yuan Lu, and Xuelian Cheng. Video-thinker: Sparking" thinking with videos" via reinforce- ment learning.arXiv preprint arXiv:2510.23473, 2025
-
[37]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, et al. Internvl3. 5: Advancing open-source multimodal models in versatility, reasoning, and efficiency.arXiv preprint arXiv:2508.18265, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
Xidong Wang, Dingjie Song, Shunian Chen, Chen Zhang, and Benyou Wang. Longllava: Scaling multi-modal llms to 1000 images efficiently via hybrid architecture.arXiv preprint arXiv:2409.02889, 2(5):6, 2024
-
[39]
Time-r1: Post-training large vision language model for temporal video grounding.Advances in Neural Information Processing Systems, 38:83330– 83364, 2026
Ye Wang, Ziheng Wang, Boshen Xu, Yang Du, Kejun Lin, Zihan Xiao, Zihao Yue, Jianzhong Ju, Liang Zhang, Dingyi Yang, et al. Time-r1: Post-training large vision language model for temporal video grounding.Advances in Neural Information Processing Systems, 38:83330– 83364, 2026
2026
-
[40]
Qiucheng Wu, Handong Zhao, Michael Saxon, Trung Bui, William Yang Wang, Yang Zhang, and Shiyu Chang. Vsp: Assessing the dual challenges of perception and reasoning in spatial planning tasks for vlms.arXiv preprint arXiv:2407.01863, 2024
-
[41]
PLLaVA : Parameter-free LLaVA Extension from Images to Videos for Video Dense Captioning
Lin Xu, Yilin Zhao, Daquan Zhou, Zhijie Lin, See Kiong Ng, and Jiashi Feng. Pllava: Parameter-free llava extension from images to videos for video dense captioning.arXiv preprint arXiv:2404.16994, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[42]
Mingze Xu, Mingfei Gao, Shiyu Li, Jiasen Lu, Zhe Gan, Zhengfeng Lai, Meng Cao, Kai Kang, Yinfei Yang, and Afshin Dehghan. Slowfast-llava-1.5: A family of token-efficient video large language models for long-form video understanding.arXiv preprint arXiv:2503.18943, 2025
-
[43]
Visual planning: Let’s think only with images.arXiv preprint arXiv:2505.11409, 2025
Yi Xu, Chengzu Li, Han Zhou, Xingchen Wan, Caiqi Zhang, Anna Korhonen, and Ivan Vuli´c. Visual planning: Let’s think only with images.arXiv preprint arXiv:2505.11409, 2025
-
[44]
Sohee Yang, Elena Gribovskaya, Nora Kassner, Mor Geva, and Sebastian Riedel. Do large language models latently perform multi-hop reasoning? InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 10210–10229, 2024
2024
-
[45]
Machine Mental Imagery: Empower Multimodal Reasoning with Latent Visual Tokens
Zeyuan Yang, Xueyang Yu, Delin Chen, Maohao Shen, and Chuang Gan. Machine men- tal imagery: Empower multimodal reasoning with latent visual tokens.arXiv preprint arXiv:2506.17218, 2025. 12
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[46]
MM-REACT: Prompting ChatGPT for Multimodal Reasoning and Action
Zhengyuan Yang, Linjie Li, Jianfeng Wang, Kevin Lin, Ehsan Azarnasab, Faisal Ahmed, Zicheng Liu, Ce Liu, Michael Zeng, and Lijuan Wang. Mm-react: Prompting chatgpt for multimodal reasoning and action.arXiv preprint arXiv:2303.11381, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[47]
LongVT: Incentivizing "Thinking with Long Videos" via Native Tool Calling
Zuhao Yang, Sudong Wang, Kaichen Zhang, Keming Wu, Sicong Leng, Yifan Zhang, Bo Li, Chengwei Qin, Shijian Lu, Xingxuan Li, et al. Longvt: Incentivizing" thinking with long videos" via native tool calling.arXiv preprint arXiv:2511.20785, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[48]
Shoubin Yu, Yue Zhang, Zun Wang, Jaehong Yoon, Huaxiu Yao, Mingyu Ding, and Mohit Bansal. When and how much to imagine: Adaptive test-time scaling with world models for visual spatial reasoning.arXiv preprint arXiv:2602.08236, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[49]
VideoLLaMA 3: Frontier Multimodal Foundation Models for Image and Video Understanding
Boqiang Zhang, Kehan Li, Zesen Cheng, Zhiqiang Hu, Yuqian Yuan, Guanzheng Chen, Sicong Leng, Yuming Jiang, Hang Zhang, Xin Li, et al. Videollama 3: Frontier multimodal foundation models for image and video understanding.arXiv preprint arXiv:2501.13106, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[50]
Cmmcot: Enhancing complex multi-image comprehension via multi-modal chain-of-thought and memory augmentation
Guanghao Zhang, Tao Zhong, Yan Xia, Mushui Liu, Zhelun Yu, Haoyuan Li, Wanggui He, Dong She, Yi Wang, and Hao Jiang. Cmmcot: Enhancing complex multi-image comprehension via multi-modal chain-of-thought and memory augmentation. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 12430–12438, 2026
2026
-
[51]
Long Context Transfer from Language to Vision
Peiyuan Zhang, Kaichen Zhang, Bo Li, Guangtao Zeng, Jingkang Yang, Yuanhan Zhang, Ziyue Wang, Haoran Tan, Chunyuan Li, and Ziwei Liu. Long context transfer from language to vision. arXiv preprint arXiv:2406.16852, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[52]
Chain-of-focus: Adaptive visual search and zooming for multimodal reasoning via rl.arXiv e-prints, pages arXiv–2505, 2025
Xintong Zhang, Zhi Gao, Bofei Zhang, Pengxiang Li, Xiaowen Zhang, Yang Liu, Tao Yuan, Yuwei Wu, Yunde Jia, Song-Chun Zhu, et al. Chain-of-focus: Adaptive visual search and zooming for multimodal reasoning via rl.arXiv e-prints, pages arXiv–2505, 2025
2025
-
[53]
LLaV A-NeXT: A strong zero-shot video understanding model, 2024
Yuanhan Zhang, Bo Li, Haotian Liu, Yong Jae Lee, and Chunyuan Zhang. LLaV A-NeXT: A strong zero-shot video understanding model, 2024. URL https://llava-vl.github.io/ blog/2024-04-30-llava-next-video/
2024
-
[54]
LLaVA-Video: Video Instruction Tuning With Synthetic Data
Yuanhan Zhang, Jinming Wu, Wei Li, Bo Li, Zejun Ma, Ziwei Liu, and Chunyuan Li. Llava- video: Video instruction tuning with synthetic data.arXiv preprint arXiv:2410.02713, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[55]
Mmvu: Measuring expert-level multi-discipline video understanding
Yilun Zhao, Haowei Zhang, Lujing Xie, Tongyan Hu, Guo Gan, Yitao Long, Zhiyuan Hu, Weiyuan Chen, Chuhan Li, Zhijian Xu, et al. Mmvu: Measuring expert-level multi-discipline video understanding. InProceedings of the Computer Vision and Pattern Recognition Confer- ence, pages 8475–8489, 2025
2025
-
[56]
Reagent-v: A reward-driven multi-agent framework for video understanding
Yiyang Zhou, Yangfan He, Yaofeng Su, Siwei Han, Joel Jang, Gedas Bertasius, Mohit Bansal, and Huaxiu Yao. Reagent-v: A reward-driven multi-agent framework for video understanding. Advances in Neural Information Processing Systems, 38:151454–151491, 2026
2026
-
[57]
Hanlin Zhu, Shibo Hao, Zhiting Hu, Jiantao Jiao, Stuart Russell, and Yuandong Tian. Emergence of superposition: Unveiling the training dynamics of chain of continuous thought.arXiv preprint arXiv:2509.23365, 2025
-
[58]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
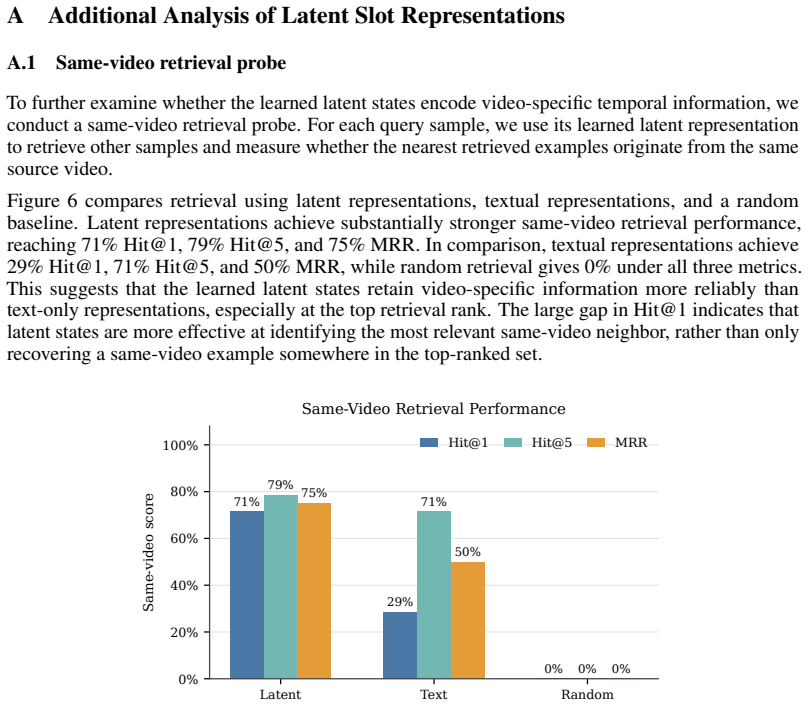
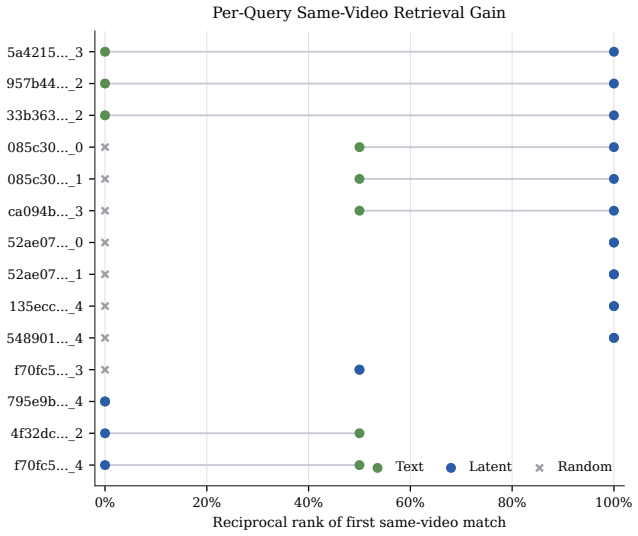
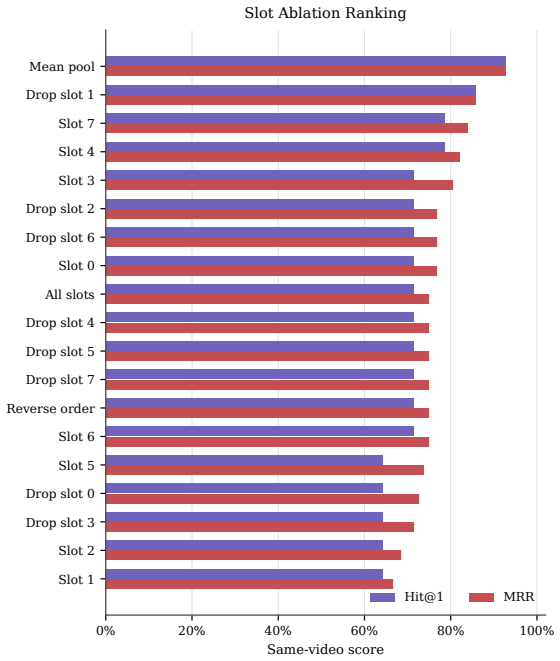
Jinguo Zhu, Weiyun Wang, Zhe Chen, Zhaoyang Liu, Shenglong Ye, Lixin Gu, Hao Tian, Yuchen Duan, Weijie Su, Jie Shao, et al. Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models.arXiv preprint arXiv:2504.10479, 2025. 13 A Additional Analysis of Latent Slot Representations A.1 Same-video retrieval probe To further e...
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.