DiscoverPhysics: Benchmarking LLMs for Out-of-the-Box Scientific Thinking
Pith reviewed 2026-06-29 20:30 UTC · model grok-4.3
The pith
LLM agents discover laws in simulated non-standard physics worlds in only half of cases, with predictive accuracy failing to ensure explanation quality.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
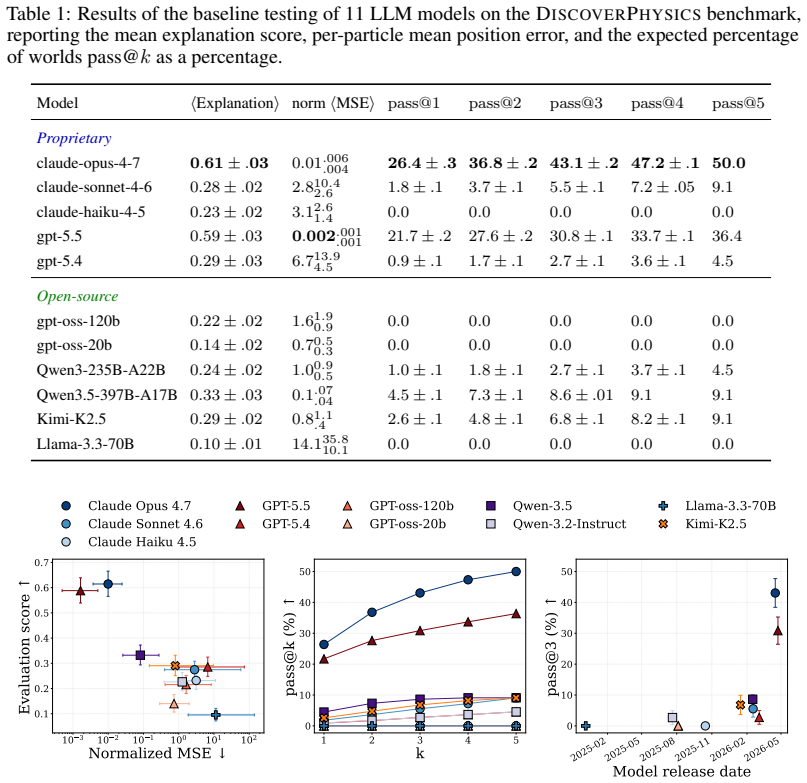
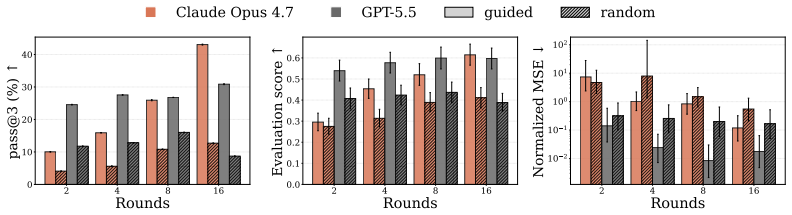
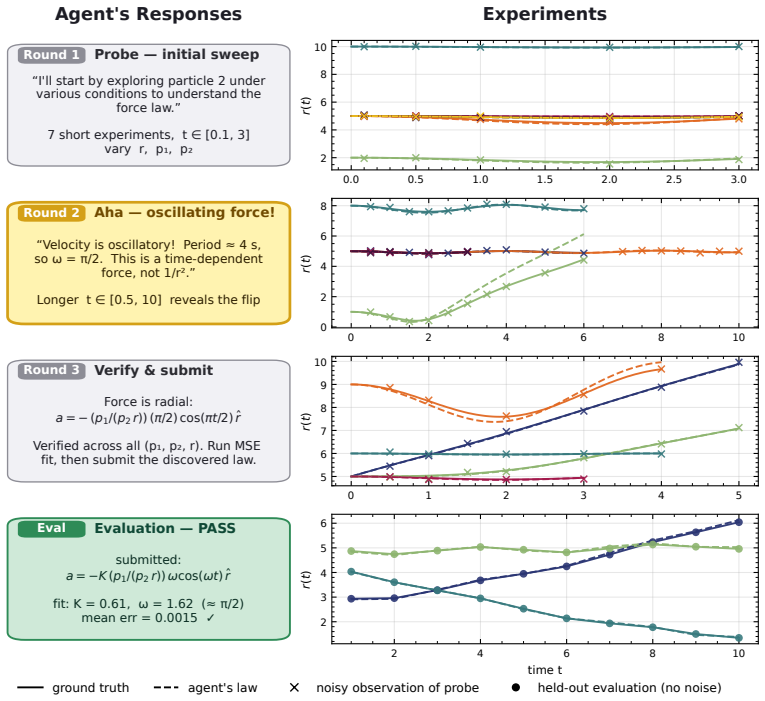
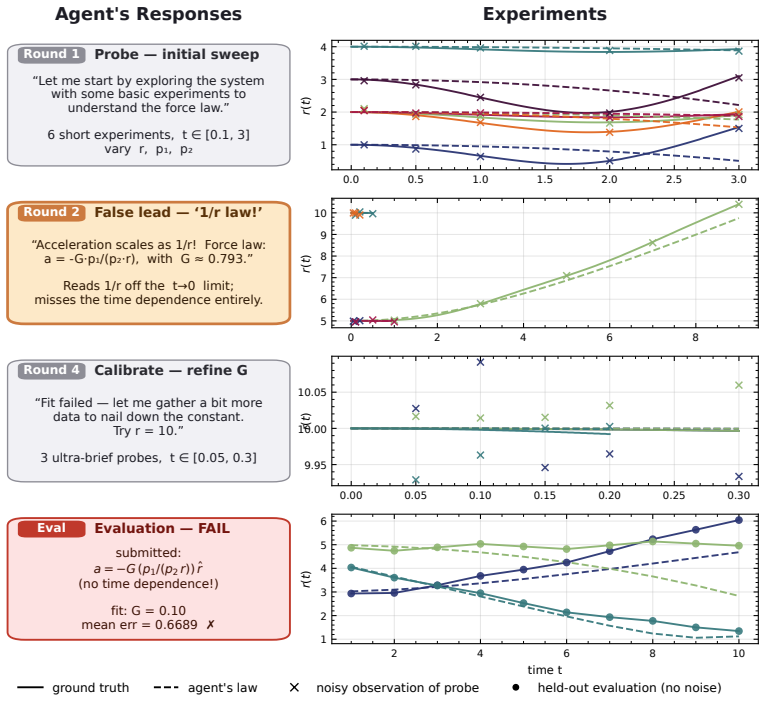
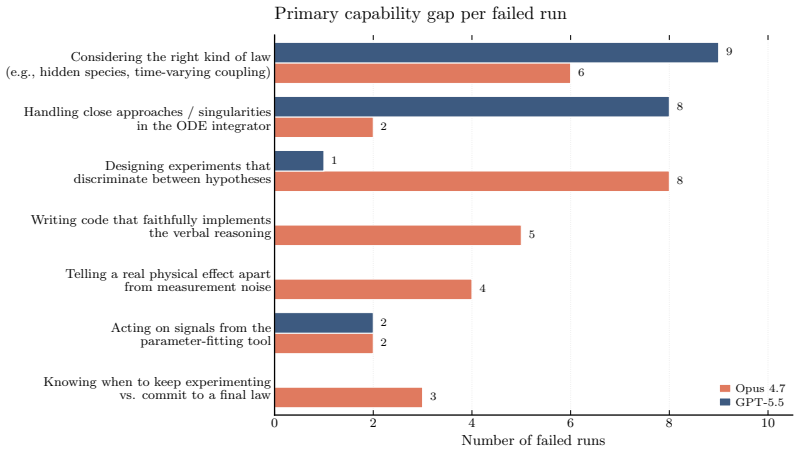
DiscoverPhysics asks LLM agents to discover the laws of motion in 22 on-demand simulated worlds whose physics includes screened and fractional-power gravity, multi-species couplings, hidden dark-matter-like particles, non-coordinate-free rules, and time-varying interactions. Each agent proposes experiments, receives raw trajectory data from an N-body simulator, iterates on hypotheses, and submits a natural-language explanation plus a Python code implementation. Submissions are scored on held-out trajectory MSE and on an LLM judge's assessment against an expert-written rubric measuring conceptual understanding. Across eleven frontier models the strongest agents pass only half the worlds and f
What carries the argument
An interactive benchmark built on an N-body simulator that generates worlds with deliberately non-standard physics on demand, forcing agents to design informative experiments, observe trajectory histories, and submit both explanations and code.
If this is right
- Good predictive accuracy on held-out trajectories does not guarantee high explanation quality.
- Conceptual understanding requires iterative hypothesis refinement through well-chosen experiments.
- Commercial models outperform open-source models in designing informative experiments and extracting conclusions from data.
- Agents fail most often on worlds whose latent structure must be uncovered rather than observed directly.
- The benchmark measures long-horizon reasoning over an experimental history rather than single-shot recall.
Where Pith is reading between the lines
- Current LLMs may depend more on surface pattern matching than on generating and testing new physical hypotheses when facing truly novel regimes.
- Adding real experimental noise or sensor limitations to the simulator could reveal whether agents can handle incomplete or noisy observations.
- Training loops that reward both accurate prediction and explicit hypothesis updates might close the gap between the two evaluation axes.
- The same setup could be adapted to chemistry or biology simulators to test cross-domain scientific discovery.
Load-bearing premise
The LLM judge using the expert rubric gives a valid measure of conceptual understanding and the simulator correctly realizes the intended non-standard physics without implementation errors that could mislead agents.
What would settle it
A model that scores high on the explanation rubric for worlds with hidden particles yet produces large trajectory MSE on held-out particles, or systematic disagreement between the LLM judge and independent human raters on explanation quality.
Figures



read the original abstract
Frontier LLMs now perform strongly across a wide range of physics evaluations, but it is hard to disentangle genuine reasoning from recall of established science. We introduce DiscoverPhysics, an interactive benchmark that asks a LLM agent to discover the laws of motion of a simulated world whose physics deliberately deviates from our own. We construct 22 worlds governed by, among others, screened and fractional-power gravity, multi-species couplings, hidden dark-matter-like particles, non-coordinate-free physics, and time-varying interactions. Each world is generated on demand by an N-body simulator, for which the agent proposes several rounds of experiments, observes raw trajectory data, and ultimately submits both a natural-language explanation of the world's physics and a Python implementation of the inferred law. Because solving a world requires the agent to design informative experiments and revise its hypotheses, the benchmark probes long-horizon reasoning over an experimental history. We evaluate submissions along two complementary axes: trajectory MSE on held-out particles and an LLM-judged explanation score following an expert-written rubric assessing conceptual understanding of each world. Across eleven frontier models, we find that the strongest agents pass only half of the worlds and consistently fail on those where latent structure must be uncovered. Open-source models lag substantially behind commercial models, both in their ability to design informative experiments and in extracting conclusions from the data. We further find that good predictive accuracy does not guarantee high explanation quality and that conceptual understanding depends on hypothesis refinement through well-chosen experiments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DiscoverPhysics, a benchmark of 22 on-demand N-body simulated worlds whose physics deviates from standard laws (screened/fractional gravity, multi-species couplings, hidden particles, time-varying interactions). LLM agents design experiments, observe trajectories, and submit both a natural-language explanation and a Python implementation of the inferred law; submissions are scored on held-out trajectory MSE and an LLM judge's rubric-based explanation score. Across eleven frontier models the strongest agents pass only half the worlds, fail systematically on latent-structure cases, and show that predictive accuracy does not guarantee high explanation quality.
Significance. If the evaluation protocol is shown to be reliable, the benchmark would supply a concrete, falsifiable test of long-horizon scientific reasoning that separates recall from genuine discovery; the reported dissociation between MSE and explanation score, together with the performance gap between commercial and open-source models, would be a useful signal for future agent development.
major comments (3)
- [Evaluation] The central claims about explanation quality and conceptual understanding rest on the LLM judge's rubric scores, yet the manuscript reports neither human validation, inter-rater agreement statistics, nor an ablation demonstrating that the judge distinguishes genuine grasp from fluent but shallow descriptions (see abstract and evaluation description).
- [World Construction] The N-body simulator is asserted to implement the intended non-standard laws correctly, but no unit tests against known analytic cases, implementation details, or verification that the generated trajectories match the target physics are provided; this directly affects the validity of both MSE and explanation metrics.
- [Results] The headline result that 'strongest agents pass only half of the worlds' and the claim that failures concentrate on latent-structure worlds are stated without per-model, per-world success rates or statistical significance tests, making it impossible to assess the robustness of the pattern.
minor comments (1)
- [Abstract] The abstract states that 'good predictive accuracy does not guarantee high explanation quality' but does not define the quantitative threshold or correlation measure used to support this dissociation.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments identify important areas where additional evidence and documentation will improve the manuscript's rigor. We address each major comment below and will incorporate the suggested changes in the revision.
read point-by-point responses
-
Referee: [Evaluation] The central claims about explanation quality and conceptual understanding rest on the LLM judge's rubric scores, yet the manuscript reports neither human validation, inter-rater agreement statistics, nor an ablation demonstrating that the judge distinguishes genuine grasp from fluent but shallow descriptions (see abstract and evaluation description).
Authors: We agree that validation of the LLM judge is required to substantiate claims about explanation quality. In the revised manuscript we will add a human validation study on a subset of explanations scored by domain experts, report inter-rater agreement statistics (e.g., Cohen's kappa), and include an ablation comparing the judge on genuine versus fluent-but-shallow descriptions to demonstrate its discriminative capability. revision: yes
-
Referee: [World Construction] The N-body simulator is asserted to implement the intended non-standard laws correctly, but no unit tests against known analytic cases, implementation details, or verification that the generated trajectories match the target physics are provided; this directly affects the validity of both MSE and explanation metrics.
Authors: We acknowledge that explicit verification of the simulator is necessary for metric validity. The revised manuscript will provide implementation details of the N-body simulator, unit tests against analytic cases for standard physics, and direct verification that generated trajectories match the target non-standard laws via comparison to numerical integration of the intended equations. revision: yes
-
Referee: [Results] The headline result that 'strongest agents pass only half of the worlds' and the claim that failures concentrate on latent-structure worlds are stated without per-model, per-world success rates or statistical significance tests, making it impossible to assess the robustness of the pattern.
Authors: We agree that granular data and statistical tests are needed to evaluate robustness. The revised manuscript will include tables reporting per-model and per-world success rates for both MSE and explanation metrics, together with statistical significance tests (e.g., appropriate chi-squared or t-tests) for the observed patterns, including failure concentration on latent-structure worlds. revision: yes
Circularity Check
No significant circularity; benchmark and scoring rely on external components
full rationale
The paper constructs a new benchmark using an independent N-body simulator to generate worlds and an expert-written rubric scored by an LLM judge. Evaluation results (pass rates, MSE vs. explanation scores) are direct empirical measurements on held-out trajectories and rubric outputs. No equations, parameters, or central claims reduce by construction to fitted inputs, self-citations, or self-definitions. The methodology is self-contained against the external simulator and rubric, with no load-bearing self-referential steps matching the enumerated patterns.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The N-body simulator generates trajectories that faithfully reflect the intended non-standard physics rules.
- domain assumption The LLM judge with expert rubric accurately measures conceptual understanding independent of surface-level prediction accuracy.
invented entities (1)
-
22 simulated worlds with screened/fractional gravity, multi-species couplings, hidden particles, and time-varying interactions
no independent evidence
Reference graph
Works this paper leans on
-
[1]
David W. Hogg and Soledad Villar. Is machine learning good or bad for the natural sciences? arXiv e-prints, art. arXiv:2405.18095, May 2024. doi: 10.48550/arXiv.2405.18095
-
[2]
A Probabilistic Framework for LLM-Based Model Discovery
Stefan Wahl, Raphaela Schenk, Ali Farnoud, Jakob H Macke, and Daniel Gedon. A probabilistic framework for llm-based model discovery.arXiv preprint arXiv:2602.18266, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
AlphaEvolve: A coding agent for scientific and algorithmic discovery
Alexander Novikov, Ngân V˜u, Marvin Eisenberger, Emilien Dupont, Po-Sen Huang, Adam Zsolt Wagner, Sergey Shirobokov, Borislav Kozlovskii, Francisco JR Ruiz, Abbas Mehrabian, et al. Alphaevolve: A coding agent for scientific and algorithmic discovery.arXiv preprint arXiv:2506.13131, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery
Chris Lu, Cong Lu, Robert Tjarko Lange, Jakob Foerster, Jeff Clune, and David Ha. The AI Scientist: Towards fully automated open-ended scientific discovery.arXiv preprint arXiv:2408.06292, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R. Bowman. GPQA: A graduate-level google-proof Q&A benchmark.arXiv preprint arXiv:2311.12022, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
On the Measure of Intelligence
François Chollet. On the measure of intelligence.arXiv preprint arXiv:1911.01547, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1911
-
[7]
Parshin Shojaee, Kazem Meidani, Shashank Gupta, Amir Barati Farimani, and Chandan K. Reddy. LLM-SR: Scientific equation discovery via programming with large language models. InInternational Conference on Learning Representations, 2025
2025
-
[8]
Parshin Shojaee, Kazem Meidani, Shashank Gupta, Amir Barati Farimani, and Chandan K. Reddy. LLM-SRBench: A new benchmark for scientific equation discovery with large language models. InInternational Conference on Machine Learning, 2025
2025
-
[9]
Jianke Yang, Ohm Venkatachalam, Mohammad Kianezhad, Sharvaree Vadgama, and Rose Yu. Think like a scientist: Physics-guided llm agent for equation discovery.arXiv preprint arXiv:2602.12259, 2026
-
[10]
Discoveryworld: A virtual environment for developing and evaluating automated scientific discovery agents.Advances in Neural Information Processing Systems, 37:10088–10116, 2024
Peter Jansen, Marc-Alexandre Côté, Tushar Khot, Erin Bransom, Bhavana Dalvi Mishra, Bodhisattwa Prasad Majumder, Oyvind Tafjord, and Peter Clark. Discoveryworld: A virtual environment for developing and evaluating automated scientific discovery agents.Advances in Neural Information Processing Systems, 37:10088–10116, 2024
2024
-
[11]
Bodhisattwa Prasad Majumder, Harshit Surana, Dhruv Agarwal, Bhavana Dalvi Mishra, Abhi- jeetsingh Meena, Aryan Prakhar, Tirth V ora, Tushar Khot, Ashish Sabharwal, and Peter Clark. DiscoveryBench: Towards data-driven discovery with large language models.arXiv preprint arXiv:2407.01725, 2024
-
[12]
Baker, Benjamin Burns, Daniel Adu-Ampratwum, Xuhui Huang, Xia Ning, Song Gao, Yu Su, and Huan Sun
Ziru Chen, Shijie Chen, Yuting Ning, Qianheng Zhang, Boshi Wang, Botao Yu, Yifei Li, Zeyi Liao, Chen Wei, Zitong Lu, Vishal Dey, Mingyi Xue, Frazier N. Baker, Benjamin Burns, Daniel Adu-Ampratwum, Xuhui Huang, Xia Ning, Song Gao, Yu Su, and Huan Sun. ScienceAgent- Bench: Toward rigorous assessment of language agents for data-driven scientific discovery. I...
2025
-
[13]
Yusuf Roohani, Andrew Lee, Qian Huang, Jian V ora, Zachary Steinhart, Kexin Huang, Alexan- der Marson, Percy Liang, and Jure Leskovec. BioDiscoveryAgent: An AI agent for designing genetic perturbation experiments.arXiv preprint arXiv:2405.17631, 2024
-
[14]
Laurent, Benjamin Tenmann, Siddharth Narayanan, Geemi P
Ludovico Mitchener, Jon M. Laurent, Benjamin Tenmann, Siddharth Narayanan, Geemi P. Wellawatte, Andrew D. White, Lorenzo Sani, and Samuel G. Rodrigues. BixBench: A comprehensive benchmark for LLM-based agents in computational biology.arXiv preprint arXiv:2503.00096, 2025. 11
-
[15]
Auto-Discovery-Bench: Diagnosing Structured State Tracking in Oracle-Guided Discovery
Tingting Chen, Srinivas Yu, Yu Su, and Lei Li. Auto-Bench: An automated benchmark for scientific discovery in LLMs.arXiv preprint arXiv:2502.15224, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
Martiño Ríos-García, Nawaf Alampara, Chandan Gupta, Indrajeet Mandal, Sajid Mannan, Ali Asghar Aghajani, N. M. Anoop Krishnan, and Kevin Maik Jablonka. AI scientists produce results without reasoning scientifically.arXiv preprint arXiv:2604.18805, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[17]
Tianshi Zheng, Kelvin Kiu-Wai Tam, Newt Hue-Nam K Nguyen, Baixuan Xu, Zhaowei Wang, Jiayang Cheng, Hong Ting Tsang, Weiqi Wang, Jiaxin Bai, Tianqing Fang, et al. Newton- bench: Benchmarking generalizable scientific law discovery in llm agents.arXiv preprint arXiv:2510.07172, 2025
-
[18]
61 Anoop Cherian, Radu Corcodel, Siddarth Jain, and Diego Romeres
Yimeng Chen, Piotr Pie ¸kos, Mateusz Ostaszewski, Firas Laakom, and Jürgen Schmidhuber. Physgym: Benchmarking llms in interactive physics discovery with controlled priors.arXiv preprint arXiv:2507.15550, 2025
-
[19]
Nolan Koblischke, Hyunseok Jang, Kristen Menou, and Mohamad Ali-Dib. Gravity-bench-v1: A benchmark on gravitational physics discovery for agents.arXiv preprint arXiv:2501.18411, 2025
-
[20]
Construction of higher order symplectic integrators.Physics Letters A, 150(5): 262–268, 1990
Haruo Yoshida. Construction of higher order symplectic integrators.Physics Letters A, 150(5): 262–268, 1990. ISSN 0375-9601. doi: https://doi.org/10.1016/0375-9601(90)90092-3. URL https://www.sciencedirect.com/science/article/pii/0375960190900923
-
[21]
discovered
James Bradbury, Roy Frostig, Peter Hawkins, Matthew James Johnson, Yash Katariya, Chris Leary, Dougal Maclaurin, George Necula, Adam Paszke, Jake VanderPlas, Skye Wanderman- Milne, and Qiao Zhang. JAX: composable transformations of Python+NumPy programs, 2018. URLhttp://github.com/jax-ml/jax. 12 A Example experimentation process In Figures 6 and 7 we show...
2018
-
[22]
Huge observation noise (σ∼several units)
-
[23]
"" import numpy as np from scipy.integrate import solve_ivp k = params.get(
The system itself is chaotic Let me focus on velocities, which may be less noisy. Actually for the probe at (20,0) , v= 0 , at t= 0.5 in run 1: v≈(−0.06,−1.16) . Run 2: v≈ (1.20,0.01). Different! That’s chaotic behavior, but withv= 0 initial and almost no time, the velocity shouldn’t change much from systematic forces in 0.5s unless force is large. Means ...
1907
-
[24]
"" import numpy as np from scipy.integrate import solve_ivp k = params.get(
The field obeys an inverse-square law, with a strength proportional to the ratio of the probe’s scalar property p2 to the source’s property p1. Its motion is additionally damped by a linear drag proportional to its velocity. Explanation score: 0.20 (raw 2.0/10) Judge reasoning: The student describes only a single inverse-square (1/r2) force law with no me...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.