Beyond Summaries: Structure-Aware Labeling of Code Changes with Large Language Models
Pith reviewed 2026-06-29 20:09 UTC · model grok-4.3
The pith
Large language models label code changes in patches with up to 84% recall using a two-stage structure-aware pipeline.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
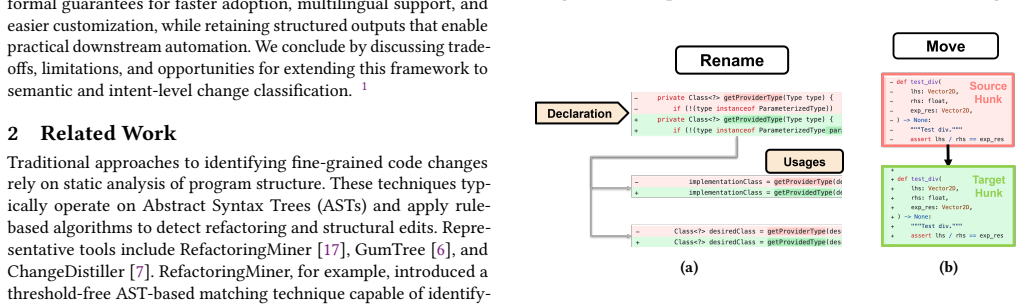
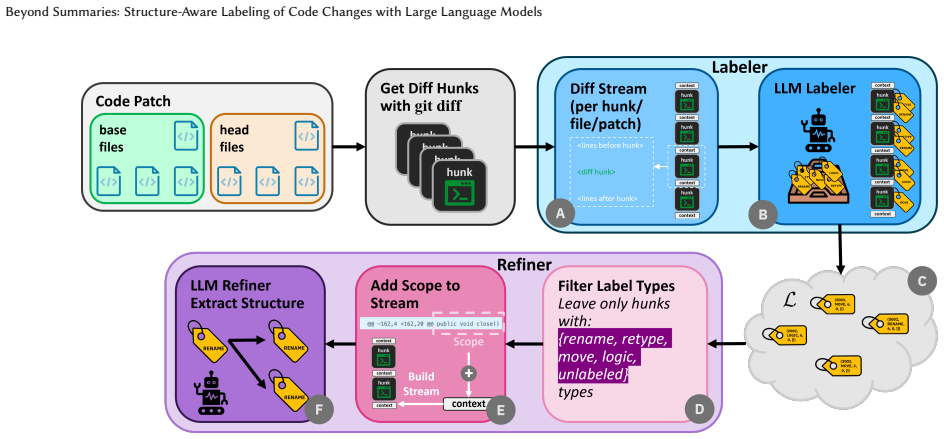
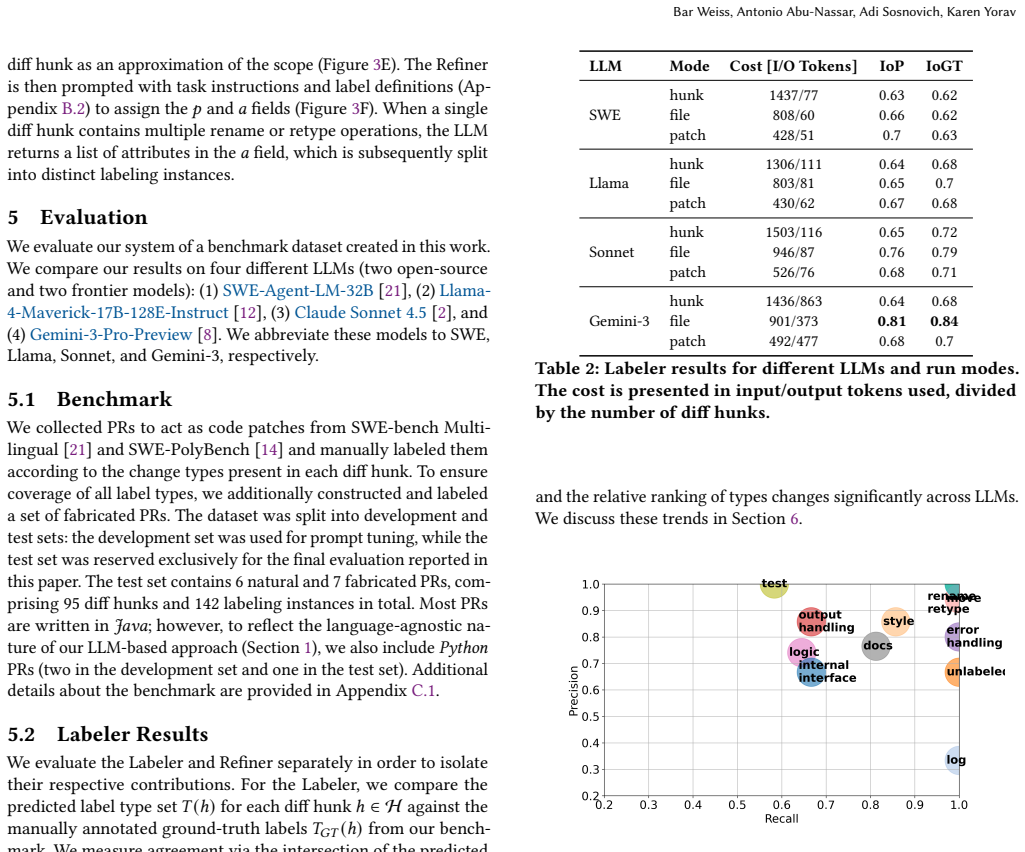
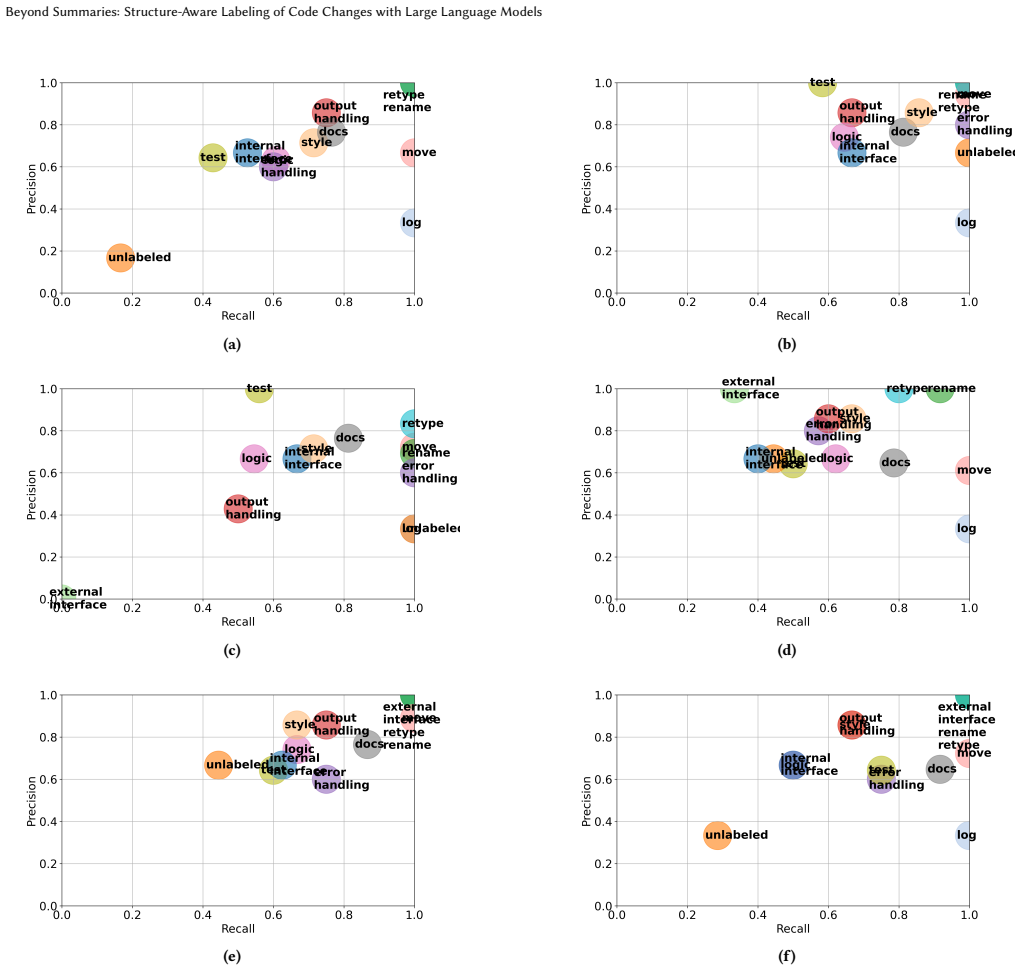
A two-stage pipeline using large language models with few-shot prompting first assigns taxonomy labels to diff hunks within a code patch and then refines those labels to extract relational metadata such as rename propagation and attribute metadata such as type changes. On a manually curated benchmark of natural and synthetic patches, the strongest configuration achieves 84% recall and 81% precision while maintaining high accuracy on the relational and attribute extractions. This structured labeling approach operates without language-specific engineering and can complement existing static analysis methods.
What carries the argument
The two-stage pipeline that assigns labels to diff hunks and then refines them to capture structural relationships and semantic attributes via few-shot prompting.
If this is right
- Code review can use change-type labels to prioritize or filter patches automatically.
- The same prompting setup works across different programming languages without per-language tools.
- Labels remain customizable by changing the taxonomy or examples without rewriting analysis code.
- Structured outputs from the pipeline can feed directly into automation workflows for review assistance.
Where Pith is reading between the lines
- Embedding the pipeline in version control platforms could surface labeled changes during pull request creation.
- Combining the LLM labels with existing static analysis might raise accuracy on edge cases the benchmark did not cover.
- Extending the method to entire commit histories could reveal patterns in how change types evolve across project lifetimes.
Load-bearing premise
The manually curated benchmark of natural and synthetic patches is representative of real-world code changes and the taxonomy labels were applied consistently without bias.
What would settle it
Running the pipeline on a large set of unlabeled patches from active open-source projects and finding recall or precision consistently below 70% would show the reported performance does not generalize.
Figures


read the original abstract
Code review is a critical practice in software engineering, yet the growing scale and frequency of code patches in modern projects, together with the widespread adoption of AI code assistants, make manual review increasingly challenging. Identifying the types of changes within a patch, such as renames, moves, or logic modifications, can substantially improve review efficiency by enabling prioritization, filtering, and automation. However, existing LLM-based approaches to code review have largely focused on summarization and comment generation, leaving structured code reviews underexplored. In this paper, we present a systematic study of using large language models (LLMs) for taxonomy-based labeling of code changes in a code patch. We introduce a two-stage pipeline that assigns labels to diff hunks and then refines them to capture structural relationships and semantic attributes, such as rename propagation and type changes. Our approach employs few-shot prompting to produce language-agnostic and customizable labels, without the engineering overhead of traditional static-analysis pipelines. We evaluate four LLMs across multiple context configurations on a manually curated benchmark of natural and synthetic patches. Our best configuration achieves up to $84\%$ recall and $81\%$ precision, with high accuracy in extracting relational and attribute metadata. These results suggest that LLM-based labeling can effectively complement static analysis by enabling flexible, multilingual, and automation-friendly code review workflows.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a two-stage LLM pipeline for taxonomy-based labeling of code changes in patches: first assigning labels to diff hunks via few-shot prompting, then refining them to capture structural relationships (e.g., rename propagation) and semantic attributes (e.g., type changes). The approach is evaluated on four LLMs across context configurations using a manually curated benchmark of natural and synthetic patches, with the best configuration reporting up to 84% recall and 81% precision and high accuracy on relational/attribute metadata. The work positions this as a flexible, language-agnostic complement to static analysis for code review.
Significance. If the empirical results are robust, the method could enable more structured, automation-friendly code reviews at scale, particularly for AI-generated patches, by avoiding the engineering cost of traditional static-analysis tools while supporting customizable taxonomies. The multi-LLM, multi-configuration evaluation provides a useful baseline for LLM performance on this structured extraction task.
major comments (1)
- [Evaluation] Evaluation section (and abstract): the headline metrics of 84% recall and 81% precision are computed on a manually curated benchmark of natural and synthetic patches, yet no benchmark size, inter-annotator agreement statistic, labeler-instruction sensitivity analysis, or external validation against version-control history is reported. This is load-bearing for the central performance claim, as the numbers could reflect curation choices rather than general capability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the evaluation. We agree that greater transparency is needed around the benchmark to support the reported metrics and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section (and abstract): the headline metrics of 84% recall and 81% precision are computed on a manually curated benchmark of natural and synthetic patches, yet no benchmark size, inter-annotator agreement statistic, labeler-instruction sensitivity analysis, or external validation against version-control history is reported. This is load-bearing for the central performance claim, as the numbers could reflect curation choices rather than general capability.
Authors: We agree this information is essential for evaluating the robustness of the results. In the revised manuscript we will expand the Evaluation section (and update the abstract if space permits) to report the exact benchmark size and the split between natural and synthetic patches, include inter-annotator agreement computed on a sampled subset, add a sensitivity analysis to variations in curation instructions, and provide a discussion of external validation attempts against version-control metadata together with any limitations encountered. revision: yes
Circularity Check
No circularity; empirical evaluation on external benchmark with no derivations or self-referential fits
full rationale
The paper presents an empirical study of an LLM two-stage pipeline for taxonomy-based labeling of code changes. It evaluates four LLMs on a manually curated benchmark of natural and synthetic patches, reporting precision, recall, and metadata extraction accuracy. No equations, fitted parameters, predictions derived from inputs by construction, or load-bearing self-citations appear in the provided text. The central claims rest on external benchmark metrics rather than any self-definitional or renamed result. This matches the default non-circular case for empirical ML papers without mathematical derivation chains.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2024.Claude Code
Anthropic. 2024.Claude Code. AI-assisted coding tool based on Claude models. Accessed: 2026-01-12
2024
-
[2]
2025.Claude Sonnet 4.5
Anthropic. 2025.Claude Sonnet 4.5. Large language model used for AI-assisted coding and writing. Accessed: 2026-01-12
2025
-
[3]
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. 2020. Language models are few-shot learners.Advances in neural information processing systems33 (2020), 1877–1901
2020
-
[4]
Mark Chen. 2021. Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374(2021). 2026-05-26 02:42. Page 5 of 1–13. Bar Weiss, Antonio Abu-Nassar, Adi Sosnovich, Karen Yorav
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[5]
Codedog Project. 2024. Codedog: AI-Powered Pull Request Summarization and Review Suggestions. https://github.com/codedog-ai/codedog. Accessed: 2024-11-30
2024
-
[6]
Jean-Rémy Falleri, Floréal Morandat, Xavier Blanc, Matias Martinez, and Mar- tin Monperrus. 2014. Fine-grained and accurate source code differencing. In ACM/IEEE International Conference on Automated Software Engineering, ASE ’14, Vasteras, Sweden - September 15 - 19, 2014. 313–324. doi:10.1145/2642937.2642982
-
[7]
Beat Fluri, Michael Würsch, Martin Pinzger, and Harald C. Gall. 2007. Change Distilling: Tree Differencing for Fine-Grained Source Code Change Extraction. IEEE Transactions on Software Engineering33 (2007), 725–743
2007
-
[8]
2025.Gemini 3 Pro
Google DeepMind. 2025.Gemini 3 Pro. Large multimodal language model. Accessed: 2026-01-12
2025
-
[9]
Cheng-Ping Hsieh, Simeng Sun, Samuel Kriman, Shantanu Acharya, Dima Rekesh, Fei Jia, Yang Zhang, and Boris Ginsburg. 2024. RULER: What’s the Real Context Size of Your Long-Context Language Models?arXiv preprint arXiv:2404.06654(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. 2022. Large language models are zero-shot reasoners.Advances in neural information processing systems35 (2022), 22199–22213
2022
-
[11]
Nelson F Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. 2024. Lost in the middle: How language models use long contexts.Transactions of the Association for Computational Linguistics 12 (2024), 157–173
2024
-
[12]
2025.Llama 4 Maverick 17B 128E Instruct
Meta AI. 2025.Llama 4 Maverick 17B 128E Instruct. https://ai.meta.com/llama/ Instruction-tuned variant of the Llama 4 Maverick 17B model
2025
-
[13]
Palos Publishing. 2024. Leveraging LLMs for Feedback Summarization in Code Reviews.Palos Tech Insights(2024). https://palospublishing.com/llms-for- feedback-summarization-in-code-reviews/
2024
-
[14]
Muhammad Shihab Rashid, Christian Bock, Yuan Zhuang, Alexander Buch- holz, Tim Esler, Simon Valentin, Luca Franceschi, Martin Wistuba, Prabhu Teja Sivaprasad, Woo Jung Kim, et al . 2025. SWE-PolyBench: A multi-language benchmark for repository level evaluation of coding agents.arXiv preprint arXiv:2504.08703(2025)
-
[15]
Caitlin Sadowski, Emma Söderberg, Luke Church, Michal Sipko, and Alberto Bacchelli. 2018. Modern code review: a case study at google. InProceedings of the 40th international conference on software engineering: Software engineering in practice. 181–190
2018
- [16]
-
[17]
Eshkevari, Davood Mazinanian, and Danny Dig
Nikolaos Tsantalis, Matin Mansouri, Laleh M. Eshkevari, Davood Mazinanian, and Danny Dig. 2018. Accurate and Efficient Refactoring Detection in Commit History. InProceedings of the 40th International Conference on Software Engi- neering(Gothenburg, Sweden)(ICSE ’18). ACM, New York, NY, USA, 483–494. doi:10.1145/3180155.3180206
-
[18]
Jason Wei, Maarten Bosma, Vincent Y Zhao, Kelvin Guu, Adams Wei Yu, Brian Lester, Nan Du, Andrew M Dai, and Quoc V Le. 2021. Finetuned language models are zero-shot learners.arXiv preprint arXiv:2109.01652(2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
- [19]
-
[20]
John Yang, Carlos E Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press. 2024. Swe-agent: Agent-computer interfaces enable automated software engineering.Advances in Neural Information Processing Systems37 (2024), 50528–50652
2024
-
[21]
SWE-smith: Scaling Data for Software Engineering Agents
John Yang, Kilian Lieret, Carlos E. Jimenez, Alexander Wettig, Kabir Khand- pur, Yanzhe Zhang, Binyuan Hui, Ofir Press, Ludwig Schmidt, and Diyi Yang. 2025. SWE-smith: Scaling Data for Software Engineering Agents. arXiv:2504.21798 [cs.SE] https://arxiv.org/abs/2504.21798 2026-05-26 02:42. Page 6 of 1–13. Beyond Summaries: Structure-Aware Labeling of Code ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.