From Model Scaling to System Scaling: Scaling the Harness in Agentic AI
Pith reviewed 2026-06-29 21:27 UTC · model grok-4.3
The pith
Agentic AI progress requires scaling the system harness around foundation models as much as improving the models themselves.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
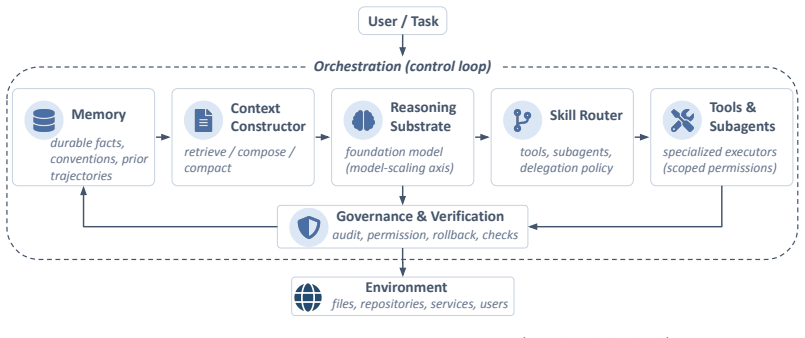
Agent performance emerges from the interaction among the foundation model, memory substrate, context constructor, skill-routing layer, orchestration loop, and verification-and-governance layer, which together form the agent harness; therefore future advances depend on scaling this harness through better context governance, trustworthy memory, and dynamic skill routing alongside model improvements.
What carries the argument
The agent harness, the structured execution layer consisting of context governance, trustworthy memory, dynamic skill routing, orchestration, and governance mechanisms that together translate model capability into sustained agent behavior.
If this is right
- Benchmarks must measure trajectory quality, memory hygiene, context efficiency, communication fidelity, verification cost, and safe evolution over time rather than one-shot task success.
- Research should target the three core bottlenecks of context governance, trustworthy memory, and dynamic skill routing.
- Orchestration and governance mechanisms must be designed to coordinate and constrain the other harness components.
- Evaluation frameworks should treat the full harness as the unit of analysis instead of isolating the foundation model.
Where Pith is reading between the lines
- If harness interactions dominate, then two different foundation models paired with identical harness designs may produce similar agent performance.
- Modular harness designs could allow components to be improved or replaced without retraining or replacing the underlying model.
- Focus on harness scaling might reduce reliance on ever-larger models for achieving reliable long-horizon agent behavior in practice.
Load-bearing premise
Agent performance is primarily limited by interactions among the harness components rather than by the capabilities of the underlying foundation model.
What would settle it
A controlled comparison in which increasing only model size produces large gains in long-horizon tasks while changes to harness components produce little or no additional improvement.
Figures
read the original abstract
This paper studies the next major bottleneck in agentic AI as system scaling, not only model scaling: the design of auditable, persistent, modular, and verifiable architectures around foundation models. We refer to this shift as scaling the harness: treating the structured execution layer around a foundation model as a first-class object of design, evaluation, and optimization. Although recent large language models enable agents to use tools, retrieve information, maintain memory, and execute long-horizon workflows, evaluation remains largely model-centric, often reducing agents to final-task success while treating memory, retrieval, tool use, orchestration, verification, and governance as secondary implementation details. This framing is increasingly inadequate because agent performance emerges from the interaction among the foundation model, memory substrate, context constructor, skill-routing layer, orchestration loop, and verification-and-governance layer. Together, these components form the agent harness, which translates model capability into long-horizon agent behavior. We study scaling the harness through three core bottlenecks: context governance, trustworthy memory, and dynamic skill routing, together with the orchestration and governance mechanisms that coordinate and constrain them. We further outline a research agenda for harness-level benchmarks that go beyond one-shot task success to measure trajectory quality, memory hygiene, context efficiency, communication fidelity, verification cost, and safe evolution over time. To make the discussion concrete, we develop CheetahClaws: https://github.com/SafeRL-Lab/cheetahclaws, a Python-native reference harness, and compare it with Claude Code and OpenClaw. Our main claim is that future progress in agentic AI will depend as much on system design as on stronger foundation models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that the next major bottleneck in agentic AI is system scaling via the 'agent harness'—the structured execution layer around foundation models encompassing context governance, trustworthy memory, dynamic skill routing, orchestration, and governance—rather than model scaling alone. Agent performance is said to emerge from interactions among these components; model-centric evaluations are critiqued as inadequate; a research agenda for harness-level benchmarks (trajectory quality, memory hygiene, context efficiency, verification cost, safe evolution) is outlined; and CheetahClaws is presented as a Python-native reference implementation with qualitative comparisons to Claude Code and OpenClaw. The central thesis is that future progress will depend as much on system design as on stronger foundation models.
Significance. If the central claim holds, the perspective could redirect agentic AI research toward holistic system architectures and evaluations that capture long-horizon behaviors beyond one-shot task success. The reference implementation and benchmark agenda supply a concrete foundation for follow-on work. The paper offers no empirical support, however, so its influence would depend on subsequent validation.
major comments (3)
- [Abstract] Abstract: the claim that 'future progress in agentic AI will depend as much on system design as on stronger foundation models' is asserted without any scaling curves, ablation results, or quantitative comparisons showing that harness modifications produce gains comparable in magnitude to those from model scaling.
- [CheetahClaws comparison] Section introducing CheetahClaws and comparisons: the qualitative discussion of CheetahClaws versus Claude Code and OpenClaw contains no performance metrics, trajectory measurements, or controlled variations of harness components (context governance, memory, routing) that would allow assessment of their relative impact.
- [Research agenda] Research agenda paragraph: the proposed harness-level benchmarks (trajectory quality, memory hygiene, context efficiency, communication fidelity, verification cost, safe evolution) are described but never executed or illustrated with even preliminary data, leaving the assertion that model-centric evaluation is inadequate without direct support.
minor comments (1)
- [Introduction / harness definition] The components of the agent harness are listed repeatedly but never accompanied by a diagram or formal interface specification that would clarify data flow and dependencies among context constructor, memory substrate, skill-routing layer, and verification layer.
Simulated Author's Rebuttal
We thank the referee for the detailed review. This is a position paper whose goal is to articulate a hypothesis and research agenda rather than to deliver empirical results. We address each major comment below and indicate where we will revise the manuscript to improve clarity of scope and framing.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'future progress in agentic AI will depend as much on system design as on stronger foundation models' is asserted without any scaling curves, ablation results, or quantitative comparisons showing that harness modifications produce gains comparable in magnitude to those from model scaling.
Authors: We agree the claim is presented without new quantitative evidence. The manuscript is a perspective piece that advances the hypothesis to motivate future work; it does not claim to have demonstrated the relative magnitude of gains. We will revise the abstract to state explicitly that the central claim is a forward-looking hypothesis whose validation is part of the proposed research agenda. revision: yes
-
Referee: [CheetahClaws comparison] Section introducing CheetahClaws and comparisons: the qualitative discussion of CheetahClaws versus Claude Code and OpenClaw contains no performance metrics, trajectory measurements, or controlled variations of harness components (context governance, memory, routing) that would allow assessment of their relative impact.
Authors: The comparisons are deliberately qualitative to illustrate differences in harness architecture and design choices. Controlled quantitative experiments that isolate harness components would constitute a separate empirical study outside the scope of this position paper. We will add an explicit statement that the section offers architectural contrast only and that systematic measurement of component impact belongs to the future benchmark agenda. revision: yes
-
Referee: [Research agenda] Research agenda paragraph: the proposed harness-level benchmarks (trajectory quality, memory hygiene, context efficiency, communication fidelity, verification cost, safe evolution) are described but never executed or illustrated with even preliminary data, leaving the assertion that model-centric evaluation is inadequate without direct support.
Authors: The agenda is offered as a community roadmap rather than results obtained in this work. We acknowledge that the critique of model-centric evaluation would be stronger with even a small illustrative example drawn from existing literature. We will revise the section to reference prior observations on long-horizon failure modes and to state clearly that executing the proposed benchmarks is future work. revision: partial
Circularity Check
No circularity; conceptual position paper with no derivations or self-referential reductions
full rationale
The paper advances a definitional claim that agent performance emerges from harness interactions and that future progress depends equally on system design, but this is presented as an agenda-setting premise rather than a result derived from equations, fitted parameters, or prior self-citations. No load-bearing steps reduce to inputs by construction; the text contains no mathematical content, no predictions from fitted subsets, and no uniqueness theorems or ansatzes imported via citation. The reference implementation is described qualitatively without ablations or scaling curves that could create fitted-input circularity. The argument is self-contained as a framing exercise and does not rely on any of the enumerated circular patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Agent performance emerges from the interaction among the foundation model, memory substrate, context constructor, skill-routing layer, orchestration loop, and verification-and-governance layer.
invented entities (1)
-
agent harness
no independent evidence
Forward citations
Cited by 1 Pith paper
-
Demonstrating chart-plot: Closing the Last Mile of Academic Chart Generation
chart-plot is an agentic harness using style-aware code generation from venue figures, a LaTeX-aware render-and-revise loop, and structured edit handles to produce top-venue-ready academic charts.
Reference graph
Works this paper leans on
-
[1]
Remembering more, risking more: Longitudinal safety risks in memory-equipped llm agents, 2026
Ahmad Al-Tawaha, Shangding Gu, Peizhi Niu, Ruoxi Jia, and Ming Jin. Remembering more, risking more: Longitudinal safety risks in memory-equipped llm agents, 2026
2026
-
[2]
Manage Claude’s Memory (Claude Code Documentation).https://docs.claude
Anthropic. Manage Claude’s Memory (Claude Code Documentation).https://docs.claude. com/en/docs/claude-code/memory. Documents CLAUDE.md instruction files and auto memory. Accessed: 2026-04-18
2026
-
[3]
Claude Code
Anthropic. Claude Code. https://claude.com/product/claude-code, 2025. Accessed: 2026-04-02
2025
-
[4]
Effective Context Engineering for AI Agents
Anthropic. Effective Context Engineering for AI Agents. https://www.anthropic.com/ engineering/effective-context-engineering-for-ai-agents , September 2025. Anthropic Engineering Blog. Accessed: 2026-04-18
2025
-
[5]
Enabling Claude Code to work more autonomously
Anthropic. Enabling Claude Code to work more autonomously. https://www.anthropic. com/news/enabling-claude-code-to-work-more-autonomously , Sep 2025. Accessed: 2026-04-02
2025
-
[6]
How we built our multi-agent research system
Anthropic. How we built our multi-agent research system. https://www.anthropic.com/ engineering/multi-agent-research-system, Jun 2025. Accessed: 2026-04-02
2025
-
[7]
Introducing Claude Opus 4.7
Anthropic. Introducing Claude Opus 4.7. https://www.anthropic.com/news/ claude-opus-4-7, April 2026. Accessed: 2026-04-01
2026
-
[8]
Why do multi- agent llm systems fail?Advances in Neural Information Processing Systems, 38, 2026
Mert Cemri, Melissa Z Pan, Shuyi Yang, Lakshya A Agrawal, Bhavya Chopra, Rishabh Tiwari, Kurt Keutzer, Aditya Parameswaran, Dan Klein, Kannan Ramchandran, et al. Why do multi- agent llm systems fail?Advances in Neural Information Processing Systems, 38, 2026
2026
-
[9]
Skills in OpenAI API
Emre Okcular. Skills in OpenAI API. https://developers.openai.com/cookbook/ examples/skills_in_api, Feb 2026. Accessed: 2026-04-02
2026
-
[10]
Gemini 3.1 Pro: A smarter model for your most complex tasks
Google. Gemini 3.1 Pro: A smarter model for your most complex tasks. https: //blog.google/innovation-and-ai/models-and-research/gemini-models/ gemini-3-1-pro/, february 2026. Accessed: 2026-04-01
2026
-
[11]
Shangding Gu. Long context, less focus: A scaling gap in llms revealed through privacy and personalization.arXiv preprint arXiv:2602.15028, 2026
-
[12]
LLMs Should Express Uncertainty Explicitly
Junyu Guo, Shangding Gu, Ming Jin, Costas Spanos, and Javad Lavaei. Llms should express uncertainty explicitly.arXiv preprint arXiv:2604.05306, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[13]
Metagpt: Meta programming for a multi-agent collaborative framework
Sirui Hong, Mingchen Zhuge, Jonathan Chen, Xiawu Zheng, Yuheng Cheng, Jinlin Wang, Ceyao Zhang, Steven Yau, Zijuan Lin, Liyang Zhou, et al. Metagpt: Meta programming for a multi-agent collaborative framework. InInternational Conference on Learning Representations, volume 2024, pages 23247–23275, 2024. 12
2024
-
[14]
Sleeper Agents: Training Deceptive LLMs that Persist Through Safety Training
Evan Hubinger, Carson Denison, Jesse Mu, Mike Lambert, Meg Tong, Monte MacDiarmid, Tamera Lanham, Daniel M Ziegler, Tim Maxwell, Newton Cheng, et al. Sleeper agents: Training deceptive llms that persist through safety training.arXiv preprint arXiv:2401.05566, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
Context engineering: memory, compaction, and tool clearing
Isabella He. Context engineering: memory, compaction, and tool clearing. https://platform.claude.com/cookbook/ tool-use-context-engineering-context-engineering-tools , March 2026. Ac- cessed: 2026-04-01
2026
-
[16]
Swe-bench: Can language models resolve real-world github issues? In International Conference on Learning Representations, volume 2024, pages 54107–54157, 2024
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. Swe-bench: Can language models resolve real-world github issues? In International Conference on Learning Representations, volume 2024, pages 54107–54157, 2024
2024
-
[17]
Siegel, Nitya Nadgir, and Arvind Narayanan
Sayash Kapoor, Benedikt Stroebl, Zachary S Siegel, Nitya Nadgir, and Arvind Narayanan. Ai agents that matter.arXiv preprint arXiv:2407.01502, 2024
-
[18]
Using skills to accelerate OSS maintenance
Kazuhiro Sera. Using skills to accelerate OSS maintenance. https://developers.openai. com/blog/skills-agents-sdk, Mar 2026. Accessed: 2026-04-02
2026
-
[19]
Retrieval-augmented generation for knowledge-intensive nlp tasks.Advances in neural information processing systems, 33:9459–9474, 2020
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, et al. Retrieval-augmented generation for knowledge-intensive nlp tasks.Advances in neural information processing systems, 33:9459–9474, 2020
2020
-
[20]
Camel: Communicative agents for" mind" exploration of large language model society.Advances in neural information processing systems, 36:51991–52008, 2023
Guohao Li, Hasan Hammoud, Hani Itani, Dmitrii Khizbullin, and Bernard Ghanem. Camel: Communicative agents for" mind" exploration of large language model society.Advances in neural information processing systems, 36:51991–52008, 2023
2023
-
[21]
Lost in the middle: How language models use long contexts.Transactions of the association for computational linguistics, 12:157–173, 2024
Nelson F Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. Lost in the middle: How language models use long contexts.Transactions of the association for computational linguistics, 12:157–173, 2024
2024
-
[22]
Xianyang Liu, Shangding Gu, and Dawn Song. Agenticpay: A multi-agent llm negotiation system for buyer-seller transactions.arXiv preprint arXiv:2602.06008, 2026
-
[23]
Agentbench: Evaluating llms as agents
Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, Xuanyu Lei, Hanyu Lai, Yu Gu, Hangliang Ding, Kaiwen Men, Kejuan Yang, et al. Agentbench: Evaluating llms as agents. InInternational Conference on Learning Representations, volume 2024, pages 52989–53046, 2024
2024
-
[24]
Terminal-Bench: Benchmarking Agents on Hard, Realistic Tasks in Command Line Interfaces
Mike A Merrill, Alexander G Shaw, Nicholas Carlini, Boxuan Li, Harsh Raj, Ivan Bercovich, Lin Shi, Jeong Yeon Shin, Thomas Walshe, E Kelly Buchanan, et al. Terminal-bench: Benchmarking agents on hard, realistic tasks in command line interfaces.arXiv preprint arXiv:2601.11868, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[25]
Gaia: a benchmark for general ai assistants
Grégoire Mialon, Clémentine Fourrier, Thomas Wolf, Yann LeCun, and Thomas Scialom. Gaia: a benchmark for general ai assistants. InInternational Conference on Learning Representations, volume 2024, pages 9025–9049, 2024
2024
-
[26]
Xuying Ning, Katherine Tieu, Dongqi Fu, Tianxin Wei, Zihao Li, Yuanchen Bei, Jiaru Zou, Mengting Ai, Zhining Liu, Ting-Wei Li, et al. Code as agent harness.arXiv preprint arXiv:2605.18747, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[27]
Introducing GPT-5.4
OpenAI. Introducing GPT-5.4. https://openai.com/index/introducing-gpt-5-4/ , March 2026. Accessed: 2026-04-01
2026
-
[28]
Claude Code Understand how to integrate Claude Code into your development workflows with best practices and real-world examples
OW ASP GenAI Security Project. Claude Code Understand how to integrate Claude Code into your development workflows with best practices and real-world examples. https://genai. owasp.org/resource/agentic-ai-threats-and-mitigations/ , February 2025. Ac- cessed: 2026-04-20
2025
-
[29]
MemGPT: Towards LLMs as Operating Systems
Charles Packer, Sarah Wooders, Kevin Lin, Vivian Fang, Shishir G Patil, Ion Stoica, and Joseph E Gonzalez. Memgpt: Towards llms as operating systems.arXiv preprint arXiv:2310.08560, 2023. 13
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[30]
Harness engineering: leveraging Codex in an agent-first world
Ryan Lopopolo. Harness engineering: leveraging Codex in an agent-first world. https: //openai.com/index/harness-engineering/, Feb 2026. Accessed: 2026-04-02
2026
-
[31]
Toolformer: Language models can teach themselves to use tools.Advances in neural information processing systems, 36:68539– 68551, 2023
Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools.Advances in neural information processing systems, 36:68539– 68551, 2023
2023
-
[32]
Reflexion: Language agents with verbal reinforcement learning.Advances in neural information processing systems, 36:8634–8652, 2023
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning.Advances in neural information processing systems, 36:8634–8652, 2023
2023
-
[33]
Defining and characterizing reward gaming.Advances in Neural Information Processing Systems, 35:9460– 9471, 2022
Joar Skalse, Nikolaus Howe, Dmitrii Krasheninnikov, and David Krueger. Defining and characterizing reward gaming.Advances in Neural Information Processing Systems, 35:9460– 9471, 2022
2022
-
[34]
Openclaw — personal ai assistant.github, 2026
Openclaw Team. Openclaw — personal ai assistant.github, 2026
2026
-
[35]
Voyager: An Open-Ended Embodied Agent with Large Language Models
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. V oyager: An open-ended embodied agent with large language models. arXiv preprint arXiv:2305.16291, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[36]
Chain-of-thought prompting elicits reasoning in large language models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824–24837, 2022
2022
-
[37]
A Prompt Pattern Catalog to Enhance Prompt Engineering with ChatGPT
Jules White, Quchen Fu, Sam Hays, Michael Sandborn, Carlos Olea, Henry Gilbert, Ashraf Elnashar, Jesse Spencer-Smith, and Douglas C Schmidt. A prompt pattern catalog to enhance prompt engineering with chatgpt.arXiv preprint arXiv:2302.11382, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[38]
Autogen: Enabling next-gen llm applications via multi-agent conversations
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, Li Jiang, Xiaoyun Zhang, Shaokun Zhang, Jiale Liu, et al. Autogen: Enabling next-gen llm applications via multi-agent conversations. InFirst conference on language modeling, 2024
2024
-
[39]
The rise and potential of large language model based agents: A survey.Science China Information Sciences, 68(2):121101, 2025
Zhiheng Xi, Wenxiang Chen, Xin Guo, Wei He, Yiwen Ding, Boyang Hong, Ming Zhang, Junzhe Wang, Senjie Jin, Enyu Zhou, et al. The rise and potential of large language model based agents: A survey.Science China Information Sciences, 68(2):121101, 2025
2025
-
[40]
Swe-agent: Agent-computer interfaces enable automated software engineering.Advances in Neural Information Processing Systems, 37:50528–50652, 2024
John Yang, Carlos E Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press. Swe-agent: Agent-computer interfaces enable automated software engineering.Advances in Neural Information Processing Systems, 37:50528–50652, 2024
2024
-
[41]
Agentic web: Weaving the next web with ai agents.arXiv preprint arXiv:2507.21206, 2025
Yingxuan Yang, Mulei Ma, Yuxuan Huang, Huacan Chai, Chenyu Gong, Haoran Geng, Yuanjian Zhou, Ying Wen, Meng Fang, Muhao Chen, et al. Agentic web: Weaving the next web with ai agents.arXiv preprint arXiv:2507.21206, 2025
-
[42]
Yingxuan Yang, Chengrui Qu, Muning Wen, Laixi Shi, Ying Wen, Weinan Zhang, Adam Wierman, and Shangding Gu. Understanding agent scaling in llm-based multi-agent systems via diversity.arXiv preprint arXiv:2602.03794, 2026
-
[43]
$\tau$-bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains
Shunyu Yao, Noah Shinn, Pedram Razavi, and Karthik Narasimhan. τ-bench: A benchmark for tool-agent-user interaction in real-world domains.arXiv preprint arXiv:2406.12045, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[44]
ReAct: Synergizing Reasoning and Acting in Language Models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models.arXiv preprint arXiv:2210.03629, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[45]
Rui Ye, Xiangrui Liu, Qimin Wu, Xianghe Pang, Zhenfei Yin, Lei Bai, and Siheng Chen. X-mas: Towards building multi-agent systems with heterogeneous llms.arXiv preprint arXiv:2505.16997, 2025
-
[46]
Webarena: A realistic web environment for building autonomous agents
Shuyan Zhou, Frank F Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, et al. Webarena: A realistic web environment for building autonomous agents. InInternational Conference on Learning Representations, volume 2024, pages 15585–15606, 2024. 14
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.