Geo: A Query Rewrite Framework for Graph Pattern Mining
Pith reviewed 2026-06-29 19:13 UTC · model grok-4.3
The pith
Geo rewrites graph pattern queries using equivalences discovered through equality saturation to achieve up to 99 percent cost reduction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
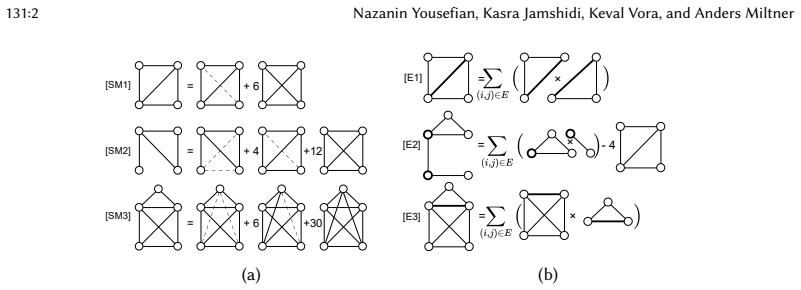
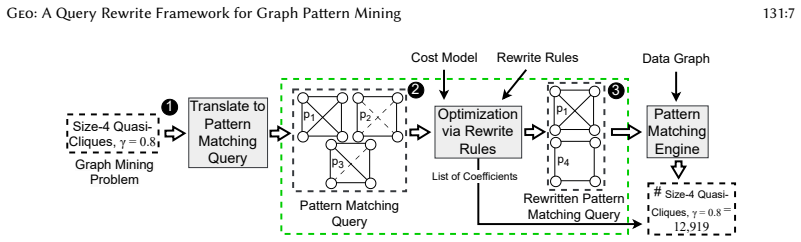
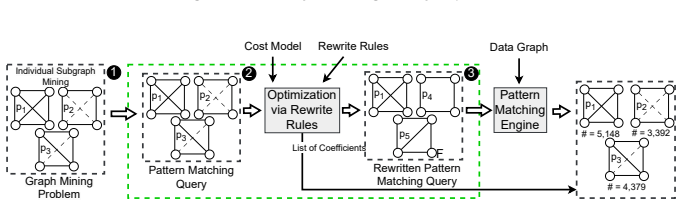
Geo is a programmable optimizer that accepts user-defined rewrite rules expressing pattern equivalences, maintains canonical representations during equality saturation to avoid syntactic duplication of isomorphic patterns, and applies embedded reconstructability to track provenance so that every optimized query remains semantically equivalent to the input query.
What carries the argument
Equality saturation over canonical pattern representations together with embedded reconstructability (EmRec) for provenance tracking.
If this is right
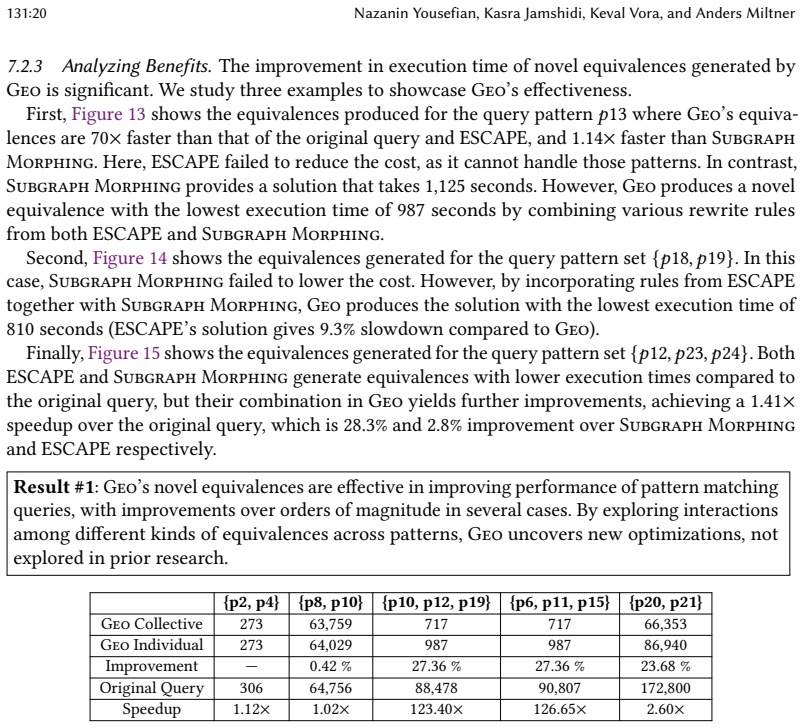
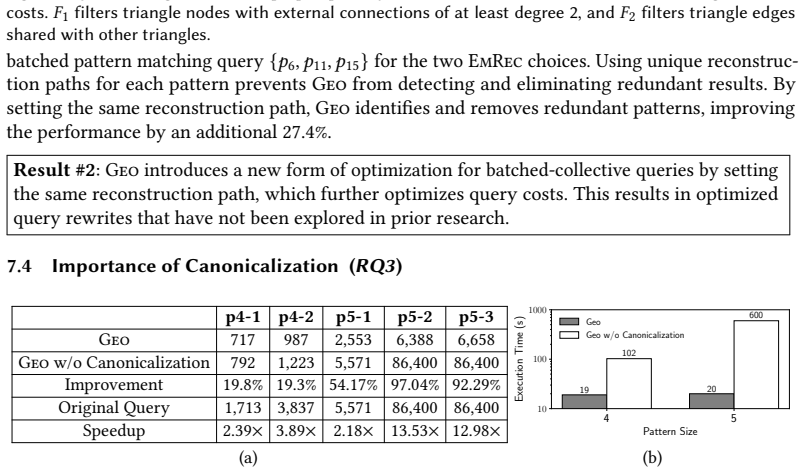
- Complex compositions of simple rules can produce previously unknown equivalences that prior hand-written optimizers missed.
- Queries optimized by Geo run with up to 99 percent lower cost than the best queries reported in earlier work.
- The same optimizer improves two distinct mining tasks, approximate pattern matching and quasi-clique mining, by up to 71 percent.
- Developers can add new equivalences over time without manually resolving interactions among existing rules.
- Correctness is maintained by construction through provenance tracking rather than post-hoc verification.
Where Pith is reading between the lines
- The approach could be ported to other domains that rely on pattern matching if suitable rewrite rules and a canonical form are defined for those patterns.
- Continuous addition of rules might eventually saturate the search space, making further manual rule writing unnecessary for some workloads.
- The framework's separation of rule authoring from interaction management could reduce the expertise needed to maintain production graph-mining pipelines.
Load-bearing premise
The supplied rewrite rules plus the canonical-representation and EmRec mechanisms together preserve the original query semantics on every input graph.
What would settle it
Execute an optimized query produced by Geo on a concrete input graph whose results are already known from the unoptimized version; any mismatch in output sets falsifies the claim that semantics are preserved.
Figures
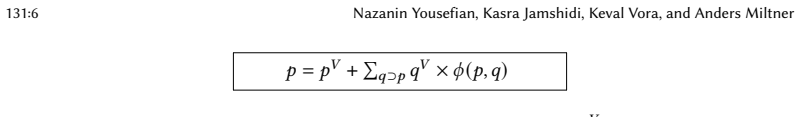














read the original abstract
Graph pattern mining is important for analyzing graph data. Graph mining systems typically require answering pattern matching queries, which involve solving the NP-complete subgraph isomorphism problem. To address this, domain experts often develop custom optimization strategies based on exploiting substructural similarities across different patterns. While these optimizers can be effective, their development is challenging, limiting the exploration of interactions between different optimization strategies and restricts experts from continuously improving the optimizers -- such as by incorporating additional custom or general pattern-based equivalences over time. We present a programmable pattern matching query optimizer called Geo, which automatically manages the interactions between various equivalences, ensures the optimizations maintain correctness of results, and simplifies the management of substructure equivalences. Geo exposes a simple but flexible language for expressing pattern equivalences as rewrite rules. By maintaining canonical representations of generated patterns during equality saturation, Geo avoids issues arising from syntactic differences in isomorphic patterns. Additionally, we develop embedded reconstructablility (EmRec) that tracks provenance across equivalences to ensure various reconstructability needs of desired outputs. Our evaluation demonstrates that Geo can discover novel query equivalences through complex composition of various rewrite rules, enabling our optimized queries to achieve a cost reduction of up to 99% compared to the queries in prior work. We further test Geo's effectiveness at speeding up practical graph mining problems by using it in two representative case studies -- approximate pattern matching and quasi-clique mining, and find it is highly effective at optimizing these tasks, enabling cost reductions of up to 71%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Geo, a programmable optimizer for graph pattern matching queries in graph mining. It provides a language for expressing pattern equivalences as rewrite rules, uses equality saturation with canonical representations to handle isomorphic patterns, and introduces embedded reconstructability (EmRec) to track provenance and preserve semantics. The central claims are that Geo discovers novel equivalences via rule composition and achieves up to 99% cost reduction versus prior work, with up to 71% reductions demonstrated in case studies on approximate pattern matching and quasi-clique mining.
Significance. If the evaluation and semantic-preservation mechanisms hold, Geo would provide a valuable extensible framework for composing optimizations in an NP-hard domain, reducing reliance on hand-crafted optimizers and enabling systematic exploration of equivalences. The use of canonical forms and provenance tracking addresses practical challenges in equality saturation for this setting.
minor comments (3)
- The abstract and introduction claim 'up to 99% cost reduction' and 'novel query equivalences' but the evaluation section should explicitly define the cost model (e.g., which operations are counted) and list the exact baseline queries from prior work for reproducibility.
- Section on EmRec should include a small worked example showing how provenance is tracked across a multi-rule composition to confirm that reconstructability constraints are enforced without false negatives.
- The paper would benefit from a table summarizing the rewrite rules used in the case studies, including their source (custom vs. general) and how many were newly discovered by Geo.
Simulated Author's Rebuttal
We thank the referee for the positive summary, significance assessment, and recommendation of minor revision. No specific major comments were provided in the report.
Circularity Check
No significant circularity
full rationale
The paper describes a systems framework (Geo) for query rewriting via equality saturation and EmRec provenance tracking. All load-bearing claims are empirical: evaluation shows novel equivalences discovered via rule composition and measured cost reductions (up to 99%). No derivation chain, equations, or fitted parameters are presented that reduce to inputs by construction. Canonical representations and EmRec are design mechanisms whose semantic preservation is asserted and tested externally via benchmarks, not defined in terms of the target results. No self-citation load-bearing steps or uniqueness theorems appear in the abstract or described approach.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Distributed evaluation of subgraph queries using worst-case optimal low-memory dataflows. Proc. VLDB Endow. 11, 6 (Feb. 2018), 691–704. https://doi.org/10.14778/ 3199517.3199520 Nikos Armenatzoglou, Sanuj Basu, Naga Bhanoori, Mengchu Cai, Naresh Chainani, Kiran Chinta, Venkatraman Govindaraju, Todd J. Green, Monish Gupta, Sebastian Hillig, Eric Hotinger, ...
-
[2]
Amazon Redshift Re-invented. In Proceedings of the 2022 International Conference on Management of Data (Philadelphia, PA, USA) (SIGMOD ’22). Association for Computing Machinery, New York, NY, USA, 2205–2217. https://doi.org/10.1145/3514221.3526045 Bibek Bhattarai, Hang Liu, and H. Howie Huang
-
[3]
An end-to-end automatic cloud database tuning system using deep reinforcement learning
CECI: Compact Embedding Cluster Index for Scalable Subgraph Matching. In Proceedings of the 2019 International Conference on Management of Data (Amsterdam, Netherlands) (SIGMOD ’19). 1447–1462. https://doi.org/10.1145/3299869.3300086 Fei Bi, Lijun Chang, Xuemin Lin, Lu Qin, and Wenjie Zhang
-
[4]
Efficient Subgraph Matching by Postponing Cartesian Products. In Proceedings of the 2016 International Conference on Management of Data (San Francisco, CA, USA) (SIGMOD ’16). 1199–1214. https://doi.org/10.1145/2882903.2915236 Mauro Brunato, Holger H Hoos, and Roberto Battiti
-
[5]
On effectively finding maximal quasi-cliques in graphs. In International conference on learning and intelligent optimization . Springer, 41–55. https://doi.org/10.1007/978-3-540- 92695-5_4 Dongbo Bu, Yi Zhao, Lun Cai, Hong Xue, Xiaopeng Zhu, Hongchao Lu, Jingfen Zhang, Shiwei Sun, Lunjiang Ling, Nan Zhang, et al
-
[6]
Nucleic acids research 31, 9 (2003), 2443–2450
Topological structure analysis of the protein–protein interaction network in budding yeast. Nucleic acids research 31, 9 (2003), 2443–2450. https://doi.org/10.1093/nar/gkg340 Peter Buneman, Sanjeev Khanna, and Tan Wang-Chiew
-
[7]
In Database Theory — ICDT 2001 , Jan Van den Bussche and Victor Vianu (Eds.)
Why and Where: A Characterization of Data Provenance. In Database Theory — ICDT 2001 , Jan Van den Bussche and Victor Vianu (Eds.). Springer Berlin Heidelberg, Berlin, Heidelberg, 316–330. https://doi.org/10.1007/3-540-44503-X_20 Walter Cai, Magdalena Balazinska, and Dan Suciu
-
[8]
Pessimistic Cardinality Estimation: Tighter Upper Bounds for Intermediate Join Cardinalities. In Proceedings of the 2019 International Conference on Management of Data (Amsterdam, Netherlands) (SIGMOD ’19). 18–35. https://doi.org/10.1145/3299869.3319894 David Cao, Rose Kunkel, Chandrakana Nandi, Max Willsey, Zachary Tatlock, and Nadia Polikarpova
-
[9]
babble: Learning Better Abstractions with E-Graphs and Anti-unification. Proc. ACM Program. Lang. 7, POPL, Article 14 (Jan. 2023), 29 pages. https://doi.org/10.1145/3571207 Joanna Che, Kasra Jamshidi, and Keval Vora
-
[10]
Contigra: Graph Mining with Containment Constraints. InProceedings of the Nineteenth European Conference on Computer Systems (Athens, Greece) (EuroSys ’24). Association for Computing Machinery, New York, NY, USA, 50–65. https://doi.org/10.1145/3627703.3629589 Jeremy Chen, Yuqing Huang, Mushi Wang, Semih Salihoglu, and Ken Salem
-
[11]
Proceedings of the VLDB Endowment 15, 8 (April 2022), 1533–1545
Accurate summary-based cardinality estimation through the lens of cardinality estimation graphs. Proceedings of the VLDB Endowment 15, 8 (April 2022), 1533–1545. https://doi.org/10.14778/3529337.3529339 Jingji Chen and Xuehai Qian
-
[12]
DecoMine: A Compilation-Based Graph Pattern Mining System with Pattern Decompo- sition. In Proceedings of the 28th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 1 (Vancouver, BC, Canada) (ASPLOS 2023). 47–61. https://doi.org/10.1145/3567955.3567956 Jingji Chen and Xuehai Qian
-
[13]
Khuzdul: Efficient and Scalable Distributed Graph Pattern Mining Engine. In Proceedings of the 28th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2 (Vancouver, BC, Canada) (ASPLOS 2023). 413–426. https://doi.org/10.1145/3575693.3575743 Xuhao Chen and Arvind
-
[14]
Association for Computing Machinery, New York, NY, USA, 378–391
Geo: A Query Rewrite Framework for Graph Pattern Mining 131:27 USA) (ICS ’21). Association for Computing Machinery, New York, NY, USA, 378–391. https://doi.org/10.1145/3447818. 3460359 Jianyi Cheng, Samuel Coward, Lorenzo Chelini, Rafael Barbalho, and Theo Drane
-
[15]
SEER: Super-Optimization Explorer for High-Level Synthesis using E-graph Rewriting. InProceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2 (La Jolla, CA, USA) (ASPLOS ’24). Association for Computing Machinery, New York, NY, USA, 1029–1044. https://doi.org/10.1145/3620665.36...
-
[16]
In 2022 IEEE 29th Symposium on Computer Arithmetic (ARITH)
Automatic Datapath Optimization using E-Graphs . In 2022 IEEE 29th Symposium on Computer Arithmetic (ARITH) . IEEE Computer Society, Los Alamitos, CA, USA, 43–50. https://doi.org/10.1109/ARITH54963.2022.00016 Vinicius Dias, Carlos H. C. Teixeira, Dorgival Guedes, Wagner Meira, and Srinivasan Parthasarathy
-
[17]
Fractal: A General-Purpose Graph Pattern Mining System. In Proceedings of the 2019 International Conference on Management of Data (Amsterdam, Netherlands) (SIGMOD ’19). Association for Computing Machinery, New York, NY, USA, 1357–1374. https://doi.org/10.1145/3299869.3319875 Rui Dong, Jie Liu, Yuxuan Zhu, Cong Yan, Barzan Mozafari, and Xinyu Wang
-
[18]
SlabCity: Whole-Query Optimization Using Program Synthesis. Proc. VLDB Endow. 16, 11 (July 2023), 3151–3164. https://doi.org/10.14778/3611479.3611515 Mohammed Elseidy, Ehab Abdelhamid, Spiros Skiadopoulos, and Panos Kalnis
-
[19]
GraMi: frequent subgraph and pattern mining in a single large graph. Proc. VLDB Endow. 7, 7 (March 2014), 517–528. https://doi.org/10.14778/2732286.2732289 John Nathan Foster
-
[20]
In 2023 USENIX Annual Technical Conference (USENIX ATC
Cyclosa: Redundancy-Free Graph Pattern Mining via Set Dataflow. In 2023 USENIX Annual Technical Conference (USENIX ATC
2023
-
[21]
Efficient Subgraph Matching: Harmonizing Dynamic Programming, Adaptive Matching Order, and Failing Set Together. In Proceedings of the 2019 International Conference on Management of Data (Amsterdam, Netherlands) (SIGMOD ’19). 1429–1446. https://doi.org/10. 1145/3299869.3319880 Wook-Shin Han, Jinsoo Lee, and Jeong-Hoon Lee
-
[22]
TurboISO: Towards Ultrafast and Robust Subgraph Isomorphism Search in Large Graph Databases. In Proceedings of the 2013 International Conference on Management of Data (New York, NY, USA) (SIGMOD ’13). 337–348. https://doi.org/10.1145/2463676.2465300 John Hopcroft, Omar Khan, Brian Kulis, and Bart Selman
-
[23]
Proceedings of the National Academy of Sciences 101, suppl_1 (2004), 5249–5253
Tracking evolving communities in large linked networks. Proceedings of the National Academy of Sciences 101, suppl_1 (2004), 5249–5253. https://doi.org/10.1073/pnas.0307750100 Haiyan Hu, Xifeng Yan, Yu Huang, Jiawei Han, and Xianghong Jasmine Zhou
-
[24]
Bioinformatics 21, suppl_1 (2005), i213–i221
Mining coherent dense subgraphs across massive biological networks for functional discovery. Bioinformatics 21, suppl_1 (2005), i213–i221. https: //doi.org/10.1093/bioinformatics/bti1049 Pan Hu and Boris Motik
-
[25]
ACM Transactions on Database Systems 49, 3, Article 12 (Sept
Accurate Sampling-Based Cardinality Estimation for Complex Graph Queries. ACM Transactions on Database Systems 49, 3, Article 12 (Sept. 2024), 46 pages. https://doi.org/10.1145/3689209 Anand Padmanabha Iyer, Zaoxing Liu, Xin Jin, Shivaram Venkataraman, Vladimir Braverman, and Ion Stoica
-
[26]
Peregrine: A Pattern-Aware Graph Mining System. In Proceedings of the Fifteenth European Conference on Computer Systems (Heraklion, Greece) (EuroSys ’20). Article 13, 16 pages. https://doi.org/10.1145/3342195.3387548 Kasra Jamshidi and Keval Vora
-
[27]
A Deeper Dive into Pattern-Aware Subgraph Exploration with PEREGRINE. SIGOPS Oper. Syst. Rev. 55, 1 (June 2021), 1–10. https://doi.org/10.1145/3469379.3469381 Kasra Jamshidi, Harry Xu, and Keval Vora
-
[28]
In Proceedings of the Eighteenth European Conference on Computer Systems (Rome, Italy) (EuroSys ’23)
Accelerating Graph Mining Systems with Subgraph Morphing. In Proceedings of the Eighteenth European Conference on Computer Systems (Rome, Italy) (EuroSys ’23). 162–181. https: //doi.org/10.1145/3552326.3567489 Tommi Junttila and Petteri Kaski
-
[29]
Engineering an efficient canonical labeling tool for large and sparse graphs. In Proceedings of the Ninth Workshop on Algorithm Engineering and Experiments and the Fourth Workshop on Analytic Algorithms and Combinatorics, David Applegate, Gerth Stølting Brodal, Daniel Panario, and Robert Sedgewick (Eds.). SIAM, 135–149. https://doi.org/10.1137/1.978161197...
-
[30]
DUALSIM: Parallel Subgraph Enumeration in a Massive Graph on a Single Machine. In Proceedings of the 2016 International Conference on Management of Data (San Francisco, CA, USA) (SIGMOD ’16). 1231–1245. https: //doi.org/10.1145/2882903.2915209 Kyoungmin Kim, Jisung Jung, In Seo, Wook-Shin Han, Kangwoo Choi, and Jaehyok Chong
-
[31]
Learned Cardinality Estimation: An In-depth Study. In Proceedings of the 2022 International Conference on Management of Data (Philadelphia, PA, USA) (SIGMOD ’22). 1214–1227. https://doi.org/10.1145/3514221.3526154 Proc. ACM Program. Lang., Vol. 10, No. OOPSLA1, Article
-
[32]
Caviar: an e-graph based TRS for automatic code optimization. In Proceedings of the 31st ACM SIGPLAN International Conference on Compiler Construction (Seoul, South Korea) (CC 2022). Association for Computing Machinery, New York, NY, USA, 54–64. https://doi.org/10.1145/3497776.3517781 Longbin Lai, Lu Qin, Xuemin Lin, and Lijun Chang
-
[33]
Proceedings of the VLDB Endowment 8, 10 (June 2015), 974–985
Scalable Subgraph Enumeration in MapReduce. Proceedings of the VLDB Endowment 8, 10 (June 2015), 974–985. https://doi.org/10.14778/2794367.2794368 Longbin Lai, Lu Qin, Xuemin Lin, Ying Zhang, Lijun Chang, and Shiyu Yang
-
[34]
Proceedings of the VLDB Endowment 10, 3 (Nov
Scalable Distributed Subgraph Enumeration. Proceedings of the VLDB Endowment 10, 3 (Nov. 2016), 217–228. https://doi.org/10.14778/3021924.3021937 John R Levine, Tony Mason, and Doug Brown
-
[35]
Uncovering the overlapping community structure of complex networks by maximal cliques. Physica A: Statistical Mechanics and its Applications 415 (2014), 398–406. https://doi.org/10.1016/j. physa.2014.08.025 Guimei Liu and Limsoon Wong
work page doi:10.1016/j 2014
-
[36]
In Joint European conference on machine learning and knowledge discovery in databases
Effective pruning techniques for mining quasi-cliques. In Joint European conference on machine learning and knowledge discovery in databases . Springer, 33–49. https://doi.org/10.1007/978-3-540-87481-2_3 Justin Lubin, Jeremy Ferguson, Kevin Ye, Jacob Yim, and Sarah E. Chasins
-
[37]
Equivalence by Canonicalization for Synthesis-Backed Refactoring. Proc. ACM Program. Lang. 8, PLDI, Article 223 (June 2024), 26 pages. https://doi.org/10. 1145/3656453 Dror Marcus and Yuval Shavitt
2024
-
[38]
RAGE: A Rapid Graphlet Enumerator for Large Networks. Computer Networks 56, 2 (Feb. 2012), 810–819. https://doi.org/10.1016/j.comnet.2011.08.019 Daniel Mawhirter and Bo Wu
-
[39]
AutoMine: Harmonizing High-Level Abstraction and High Performance for Graph Mining. In Proceedings of the 27th ACM Symposium on Operating Systems Principles (Huntsville, ON, Canada) (SOSP ’19). 509–523. https://doi.org/10.1145/3341301.3359633 Ine Melckenbeeck, Pieter Audenaert, Didier Colle, and Mario Pickavet
-
[40]
Bioinformatics 34, 8 (Nov
Efficiently Counting All Orbits of Graphlets of Any Order in a Graph Using Autogenerated Equations. Bioinformatics 34, 8 (Nov. 2017), 1372–1380. https://doi.org/10. 1093/bioinformatics/btx758 Ine Melckenbeeck, Pieter Audenaert, Thomas Van Parys, Yves Van De Peer, Didier Colle, and Mario Pickavet
2017
-
[41]
Optimising Orbit Counting of Arbitrary Order by Equation Selection. BMC Bioinformatics 20, 1 (Jan. 2019). https: //doi.org/10.1186/s12859-018-2483-9 Amine Mhedhbi and Semih Salihoglu
-
[42]
Proceedings of the VLDB Endowment 12, 11 (July 2019), 1692–1704
Optimizing Subgraph Queries by Combining Binary and Worst-Case Optimal Joins. Proceedings of the VLDB Endowment 12, 11 (July 2019), 1692–1704. https://doi.org/10.14778/3342263.3342643 Ron Milo, Shai Shen-Orr, Shalev Itzkovitz, Nadav Kashtan, Dmitri Chklovskii, and Uri Alon
-
[43]
Science 298, 5594 (2002), 824–827
Network Motifs: Simple Building Blocks of Complex Networks. Science 298, 5594 (2002), 824–827. https://doi.org/10.1126/science.298.5594.824 Greg Nelson and Derek C. Oppen
-
[44]
Fast Decision Procedures Based on Congruence Closure. J. ACM 27, 2 (April 1980), 356–364. https://doi.org/10.1145/322186.322198 Julie L. Newcomb, Andrew Adams, Steven Johnson, Rastislav Bodik, and Shoaib Kamil
-
[45]
Verifying and improving Halide’s term rewriting system with program synthesis.Proc. ACM Program. Lang. 4, OOPSLA, Article 166 (Nov. 2020), 28 pages. https://doi.org/10.1145/3428234 Pavel Panchekha, Alex Sanchez-Stern, James R. Wilcox, and Zachary Tatlock
-
[46]
Wilcox, Doug Woos, Pavel Panchekha, Zachary Tatlock, Xi Wang, Michael D
Automatically improving accuracy for floating point expressions. In Proceedings of the 36th ACM SIGPLAN Conference on Programming Language Design and Implementation (Portland, OR, USA) (PLDI ’15). Association for Computing Machinery, New York, NY, USA, 1–11. https://doi.org/10.1145/2737924.2737959 Yeonsu Park, Seongyun Ko, Sourav S. Bhowmick, Kyoungmin Ki...
-
[47]
G-CARE: A Framework for Performance Benchmarking of Cardinality Estimation Techniques for Subgraph Matching. In Proceedings of the 2020 ACM SIGMOD International Conference on Management of Data (Portland, OR, USA) (SIGMOD ’20). 1099–1114. https://doi.org/10.1145/3318464.3389702 Benedict Paten, Adam M Novak, Jordan M Eizenga, and Erik Garrison
-
[48]
Genome research 27, 5 (2017), 665–676
Genome graphs and the evolution of genome inference. Genome research 27, 5 (2017), 665–676. https://doi.org/10.1101/gr.214155.116 Ali Pinar, Comandur Seshadhri, and Vaidyanathan Vishal
-
[49]
In Proceedings of the 26th International Conference on World Wide Web (Perth, Australia) (WWW ’17)
ESCAPE: Efficiently Counting All 5-Vertex Subgraphs. In Proceedings of the 26th International Conference on World Wide Web (Perth, Australia) (WWW ’17). 1431–1440. https: //doi.org/10.1145/3038912.3052597 Miao Qiao, Hao Zhang, and Hong Cheng
-
[50]
Proceedings of the VLDB Endowment 11, 2 (Oct
Subgraph Matching: On Compression and Computation. Proceedings of the VLDB Endowment 11, 2 (Oct. 2017), 176–188. https://doi.org/10.14778/3149193.3149198 VN Redko
-
[51]
Proceedings of the VLDB Endowment 12, 11 (2019), 1344–1356
Fast and Robust Distributed Subgraph Enumeration. Proceedings of the VLDB Endowment 12, 11 (2019), 1344–1356. https://doi.org/10.14778/3342263.3342272 Tashin Reza, Matei Ripeanu, Geoffrey Sanders, and Roger Pearce
-
[52]
In Proceedings of the 2020 ACM SIGMOD International Conference on Management of Proc
Approximate pattern matching in massive graphs with precision and recall guarantees. In Proceedings of the 2020 ACM SIGMOD International Conference on Management of Proc. ACM Program. Lang., Vol. 10, No. OOPSLA1, Article
2020
-
[53]
Geo: A Query Rewrite Framework for Graph Pattern Mining 131:29 Data. 1115–1131. https://doi.org/10.1145/3318464.3380566 Rahmtin Rotabi, Krishna Kamath, Jon Kleinberg, and Aneesh Sharma
-
[54]
Detecting Strong Ties Using Network Motifs. In Proceedings of the 26th International Conference on World Wide Web Companion (Perth, Australia) (WWW ’17 Companion). 983–992. https://doi.org/10.1145/3041021.3055139 Soumajyoti Sarkar, Ruocheng Guo, and Paulo Shakarian
-
[55]
Using network motifs to characterize temporal network evolution leading to diffusion inhibition
Using Network Motifs to Characterize Temporal Network Evolution Leading to Diffusion Inhibition. CoRR abs/1903.00862 (2019). arXiv:1903.00862 http://arxiv.org/abs/1903.00862 Yingxia Shao, Bin Cui, Lei Chen, Lin Ma, Junjie Yao, and Ning Xu
work page internal anchor Pith review Pith/arXiv arXiv 1903
-
[56]
Parallel Subgraph Listing in a Large-Scale Graph. In Proceedings of the 2014 International Conference on Management of Data (Snowbird, UT, USA) (SIGMOD ’14). 625–636. https://doi.org/10.1145/2588555.2588557 Tianhui Shi, Mingshu Zhai, Yi Xu, and Jidong Zhai
-
[57]
In-Memory Subgraph Matching: An In-Depth Study. InProceedings of the 2020 International Conference on Management of Data (Portland, OR, USA) (SIGMOD ’20). 1083–1098. https://doi.org/10.1145/3318464. 3380581 Brian K Tanner, Gary Warner, Henry Stern, and Scott Olechowski
-
[58]
In 2010 eCrime Researchers Summit
Koobface: The evolution of the social botnet. In 2010 eCrime Researchers Summit . IEEE, 1–10. https://doi.org/10.1109/ecrime.2010.5706694 Li Wang, Hongying Zhao, Jing Li, Yingqi Xu, Yujia Lan, Wenkang Yin, Xiaoqin Liu, Lei Yu, Shihua Lin, Michael Yifei Du, Xia Li, Yun Xiao, and Yunpeng Zhang
-
[59]
Identifying Functions and Prognostic Biomarkers of Network Motifs Marked By Diverse Chromatin States in Human Cell Lines. Oncogene 39, 3 (Sept. 2019), 677–689. https://doi.org/10.1038/s41388- 019-1005-1 Runji Wang
-
[60]
Proceedings of the ACM on Management of Data 1, 2, Article 150 (June 2023), 23 pages
Free Join: Unifying Worst-Case Optimal and Traditional Joins. Proceedings of the ACM on Management of Data 1, 2, Article 150 (June 2023), 23 pages. https://doi.org/10.1145/3589295 Zhaoguo Wang, Zhou Zhou, Yicun Yang, Haoran Ding, Gansen Hu, Ding Ding, Chuzhe Tang, Haibo Chen, and Jinyang Li
-
[61]
WeTune: Automatic Discovery and Verification of Query Rewrite Rules. InProceedings of the 2022 International Conference on Management of Data (Philadelphia, PA, USA) (SIGMOD ’22). Association for Computing Machinery, New York, NY, USA, 94–107. https://doi.org/10.1145/3514221.3526125 Daniel Weiss and Gary Warner
-
[62]
Tracking criminals on facebook: A case study from a digital forensics reu program. (2015). Max Willsey, Chandrakana Nandi, Yisu Remy Wang, Oliver Flatt, Zachary Tatlock, and Pavel Panchekha
2015
-
[63]
egg: Fast and Extensible Equality Saturation. Proc. ACM Program. Lang. 5, POPL, Article 23 (Jan. 2021), 29 pages. https: //doi.org/10.1145/3434304 Ziniu Wu, Parimarjan Negi, Mohammad Alizadeh, Tim Kraska, and Samuel Madden
-
[64]
Proceedings of the ACM on Management of Data 1, 1, Article 41 (May 2023), 27 pages
FactorJoin: A New Cardinality Estimation Framework for Join Queries. Proceedings of the ACM on Management of Data 1, 1, Article 41 (May 2023), 27 pages. https://doi.org/10.1145/3588721 Yichen Yang, Mangpo Phitchaya Phothilimtha, Yisu Remy Wang, Max Willsey, Sudip Roy, and Jacques Pienaar. 2021b. Equality Saturation for Tensor Graph Superoptimization. ArXi...
-
[65]
Geo: A Query Rewrite Framework for Graph Pattern Mining
Artifact for "Geo: A Query Rewrite Framework for Graph Pattern Mining". https://doi.org/10.5281/zenodo.18503157 Hao Zhang, Jeffrey Xu Yu, Yikai Zhang, Kangfei Zhao, and Hong Cheng
-
[66]
Proceedings of the VLDB Endowment 13, 12 (July 2020), 2493–2507
Distributed Subgraph Counting: A General Approach. Proceedings of the VLDB Endowment 13, 12 (July 2020), 2493–2507. https://doi.org/10.14778/3407790.3407840 Xuanhe Zhou, Guoliang Li, Chengliang Chai, and Jianhua Feng
-
[67]
A learned query rewrite system using Monte Carlo tree search. Proc. VLDB Endow. 15, 1 (Sept. 2021), 46–58. https://doi.org/10.14778/3485450.3485456 Philip Zucker and Andrés Goens
-
[68]
By induction on n
131:34 Nazanin Yousefian, Kasra Jamshidi, Keval Vora, and Anders Miltner Proof. By induction on n. Case 1: 𝑛 = 0 𝑡 →∗ 𝑅∪𝑇 𝑡 Case 2: 𝑛 = 𝑛′ + 1 Let 𝜑 (𝑡) ≡ 𝐸 𝜑 (𝑡 ′). This means 𝜑 (𝑡) and 𝜑 (𝑡 ′) are represented by the same e-class 𝑒𝑐. We do not prove the soundness of e-graphs in this paper (existing result from Nelson and Oppen [Nelson and Oppen 1980]), s...
1980
-
[69]
Publication date: April 2026
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.