Unified Panoramic Geometry Estimation via Multi-View Foundation Models
Pith reviewed 2026-06-29 22:06 UTC · model grok-4.3
The pith
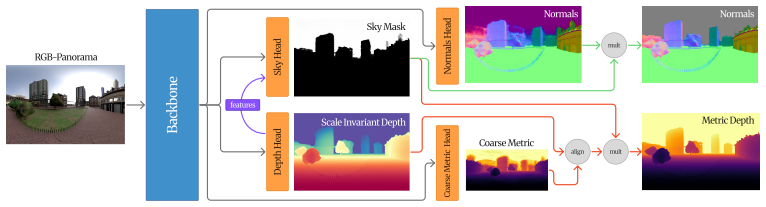
PaGeR adapts pre-trained 3D foundation models to predict scale-invariant depth, metric depth, surface normals and sky masks from both perspective images and panoramas in one forward pass.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
PaGeR lifts powerful 3D foundation models designed for perspective imagery to the panorama domain. The strategy keeps architectural changes to a minimum and mixes perspective and panoramic images during training so the model retains its rich 3D prior while also learning to estimate geometrically consistent 360-degree scenes from single panoramas. The unified model predicts scale-invariant depth, metric depth, surface normals, and sky masks from both perspective and omnidirectional images in a single forward pass.
What carries the argument
The minimally modified pre-trained transformer trained on mixed perspective and panoramic data that produces unified geometry outputs for both image domains.
If this is right
- Achieves state-of-the-art performance on indoor and outdoor environments.
- Delivers strong zero-shot generalization across a wide range of scenes.
- Produces consistent full-scene geometry from a single panoramic input.
- Supports both perspective and omnidirectional images without separate models or passes.
Where Pith is reading between the lines
- The same minimal-adaptation pattern could be tested on other geometry tasks such as optical flow or semantic segmentation.
- If the mixed-training approach generalizes, it may reduce the need for fully separate panoramic training datasets in future work.
- Applications that require quick 360 reconstruction, such as virtual walkthroughs, would benefit directly from a single-pass model.
Load-bearing premise
Mixing perspective and panoramic images during training together with only minimal architectural changes is enough to preserve the original 3D prior and avoid domain-specific inconsistencies in the 360-degree outputs.
What would settle it
A test showing that performance on perspective images drops or that panoramic outputs contain geometric inconsistencies after the mixed training would indicate the central claim does not hold.
Figures







read the original abstract
Geometry estimation from perspective images has greatly advanced, maturing to the point where off-the-shelf foundation models are able to reconstruct 3D scene structure not only from multi-view imagery, but even from a single view. A natural extension is 3D reconstruction from panoramas, with the exciting prospect of recovering a full 360-degree scene from a single panoramic image. In this work, we introduce PaGeR (Panoramic Geometry Reconstruction), a framework to lift powerful 3D foundation models designed for perspective imagery to the panorama domain. Our strategy is to start from a pre-trained transformer for 3D reconstruction and turn it into a unified high-performance model that predicts scale-invariant depth, metric depth, surface normals, and sky masks from both perspective and omnidirectional images, in a single forward pass. By keeping architectural changes to a minimum and mixing perspective and panoramic images during training, PaGeR retains the rich 3D prior of the underlying foundation model while learning to also estimate geometrically consistent 360-degree scenes from single panoramas. We extensively test our method in both indoor and outdoor environments and find that it delivers state-of-the-art performance and excellent zero-shot performance across a wide range of scenes. Code, data and models are available $\href{https://github.com/prs-eth/PaGeR}{\text{here}}$.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
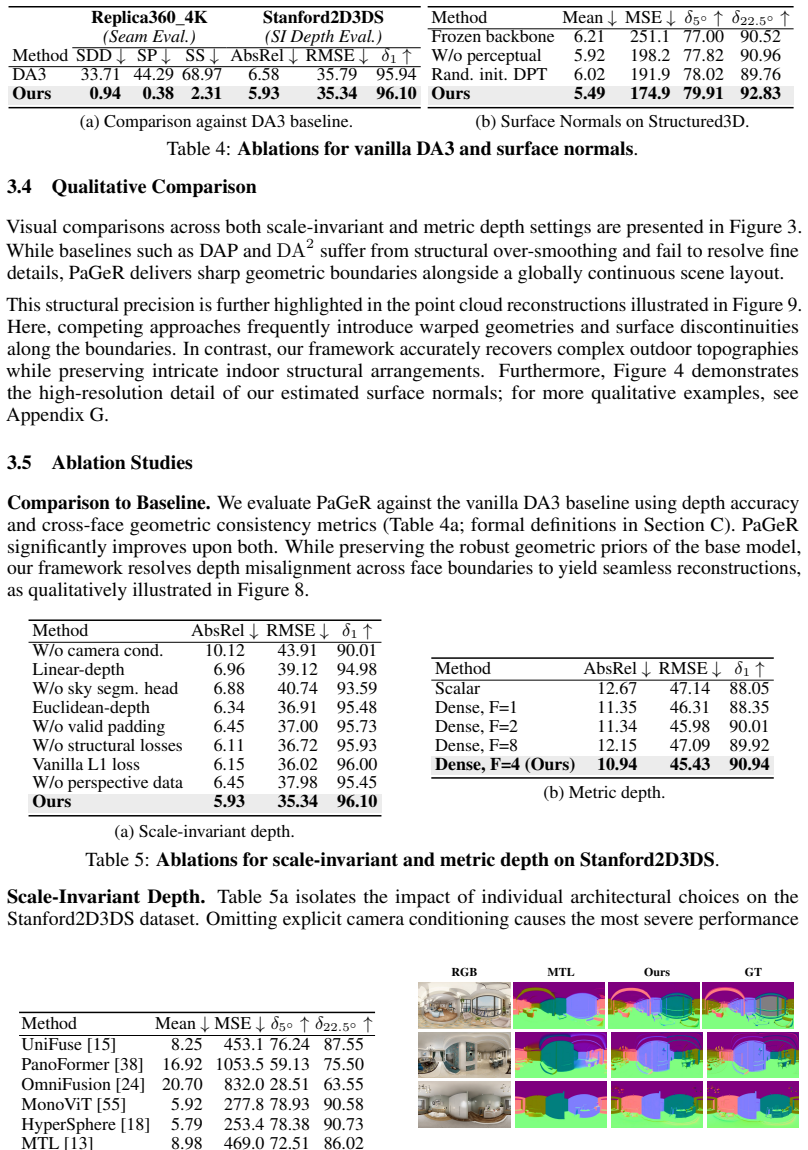
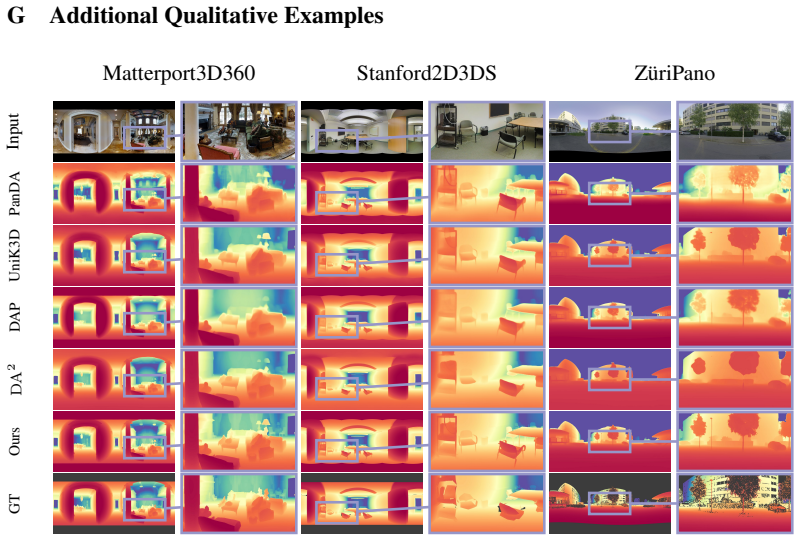
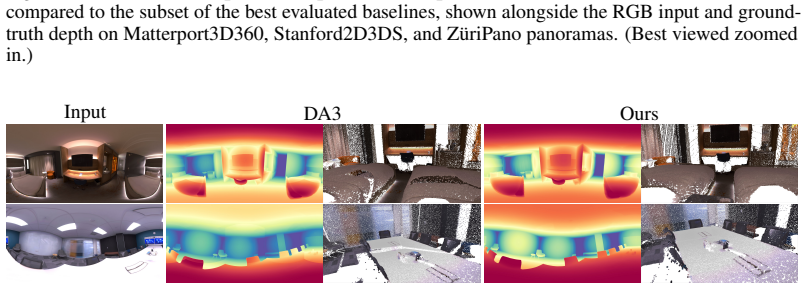
Summary. The manuscript introduces PaGeR, a framework that adapts pre-trained transformer-based 3D foundation models for perspective images to the panoramic domain. By making minimal architectural changes and training on a mix of perspective and panoramic images, it enables a single model to predict scale-invariant depth, metric depth, surface normals, and sky masks from both perspective and omnidirectional images in one forward pass. The authors claim state-of-the-art performance and strong zero-shot generalization across indoor and outdoor scenes.
Significance. If the experimental results hold, this work would be significant for providing a unified approach to 3D geometry estimation that bridges perspective and 360-degree imagery using foundation models. The release of code, data, and models enhances reproducibility and potential impact in computer vision applications involving panoramic scenes.
major comments (2)
- [Training procedure and ablations (likely §3-4)] The central claim that minimal architectural changes plus mixed training on perspective and panoramic data is sufficient to retain the base model's 3D prior (without domain interference from equirectangular distortions or wrap-around topology) is load-bearing but not yet substantiated by the provided abstract. Specific ablations comparing perspective-only performance before and after adding panoramic data are required to address the risk of compromised attention patterns or feature statistics.
- [Abstract and Experiments] The abstract asserts SOTA and excellent zero-shot results across scenes, but supplies no quantitative metrics, dataset details, or ablation evidence. Full experimental sections with tables reporting metrics on standard benchmarks (e.g., perspective depth/normal accuracy pre/post-mixing, panoramic consistency measures) would be required to assess whether the data support the claim.
minor comments (1)
- [Abstract] The abstract could benefit from including one or two key quantitative results (e.g., relative improvement on a panoramic benchmark) to ground the SOTA claim.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive feedback. The comments highlight important aspects of substantiating our central claims regarding the mixed-training strategy and the need for clearer quantitative support in the abstract. We address each point below and indicate the revisions we will make.
read point-by-point responses
-
Referee: [Training procedure and ablations (likely §3-4)] The central claim that minimal architectural changes plus mixed training on perspective and panoramic data is sufficient to retain the base model's 3D prior (without domain interference from equirectangular distortions or wrap-around topology) is load-bearing but not yet substantiated by the provided abstract. Specific ablations comparing perspective-only performance before and after adding panoramic data are required to address the risk of compromised attention patterns or feature statistics.
Authors: We agree that explicit evidence of retained perspective performance after mixed training is essential to support the claim. While Section 4 already includes ablations on mixed vs. panoramic-only training and reports perspective-task metrics, it does not contain the exact before/after comparison on a held-out perspective benchmark. We will add this ablation (training the model on perspective data only, then continuing with mixed data, and evaluating both on standard perspective depth/normal benchmarks) to the revised manuscript. revision: yes
-
Referee: [Abstract and Experiments] The abstract asserts SOTA and excellent zero-shot results across scenes, but supplies no quantitative metrics, dataset details, or ablation evidence. Full experimental sections with tables reporting metrics on standard benchmarks (e.g., perspective depth/normal accuracy pre/post-mixing, panoramic consistency measures) would be required to assess whether the data support the claim.
Authors: The full manuscript already contains extensive experimental sections (Sections 4–5) with tables reporting quantitative metrics on standard perspective benchmarks (e.g., NYU, KITTI), panoramic datasets, zero-shot generalization, and consistency measures. However, the abstract is deliberately concise and omits specific numbers. We will revise the abstract to include a small number of key quantitative highlights (e.g., relative improvements on panoramic depth and zero-shot metrics) while keeping it within length limits, and ensure all requested table types are clearly referenced. revision: partial
Circularity Check
No circularity in derivation; empirical adaptation of external pre-trained model
full rationale
The paper presents an empirical adaptation strategy: starting from an external pre-trained transformer, applying minimal architectural changes, and training on mixed perspective/panoramic data. No equations, derivations, or self-defined quantities are shown that reduce to fitted inputs by construction. Claims rest on experimental validation against external benchmarks rather than self-citation chains or ansatzes imported from the authors' prior work. This matches the expected non-finding for papers whose central contribution is data mixing and fine-tuning without load-bearing self-referential math.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Elite360D: Towards efficient 360 depth estimation via semantic-and distance-aware bi-projection fusion
Hao Ai and Lin Wang. Elite360D: Towards efficient 360 depth estimation via semantic-and distance-aware bi-projection fusion. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
2024
-
[2]
ARKitscenes: A diverse real-world dataset for 3d indoor scene understanding using mobile RGB-D data
Gilad Baruch, Zhuoyuan Chen, Afshin Dehghan, Yuri Feigin, Peter Fu, Thomas Gebauer, Daniel Kurz, Tal Dimry, Brandon Joffe, Arik Schwartz, and Elad Shulman. ARKitscenes: A diverse real-world dataset for 3d indoor scene understanding using mobile RGB-D data. InAdvances in Neural Information Processing Systems (NeurIPS), Datasets and Benchmarks Track, 2021
2021
-
[3]
ZoeDepth: Zero-shot Transfer by Combining Relative and Metric Depth
Shariq Farooq Bhat, Reiner Birkl, Diana Wofk, Peter Wonka, and Matthias Müller. Zoedepth: Zero-shot transfer by combining relative and metric depth.preprint arXiv:2302.12288, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
PanDA: Towards panoramic depth anything with unlabeled panoramas and mobius spatial augmentation
Zidong Cao, Jinjing Zhu, Weiming Zhang, Hao Ai, Haotian Bai, Hengshuang Zhao, and Lin Wang. PanDA: Towards panoramic depth anything with unlabeled panoramas and mobius spatial augmentation. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025
2025
-
[5]
Depth map prediction from a single image using a multi-scale deep network
David Eigen, Christian Puhrsch, and Rob Fergus. Depth map prediction from a single image using a multi-scale deep network. InAdvances in Neural Information Processing Systems (NeurIPS), 2014
2014
-
[6]
Geowizard: Unleashing the diffusion priors for 3d geometry estimation from a single image
Xiao Fu, Wei Yin, Mu Hu, Kaixuan Wang, Yuexin Ma, Ping Tan, Shaojie Shen, Dahua Lin, and Xiaoxiao Long. Geowizard: Unleashing the diffusion priors for 3d geometry estimation from a single image. In European Conference on Computer Vision (ECCV), 2024
2024
-
[7]
Fine-tuning image-conditional diffusion models is easier than you think
Gonzalo Martin Garcia, Karim Abou Zeid, Christian Schmidt, Daan De Geus, Alexander Hermans, and Bastian Leibe. Fine-tuning image-conditional diffusion models is easier than you think. InIEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 2025
2025
-
[8]
Clément Godard, Oisin Mac Aodha, and Gabriel J. Brostow. Unsupervised monocular depth estimation with left-right consistency. InCVPR, 2017
2017
-
[9]
Depth any camera: Zero-shot metric depth estimation from any camera
Yuliang Guo, Sparsh Garg, S Mahdi H Miangoleh, Xinyu Huang, and Liu Ren. Depth any camera: Zero-shot metric depth estimation from any camera. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025
2025
-
[10]
PanoVGGT: Feed-forward 3d reconstruction from panoramic imagery.preprint arXiv:2603.17571, 2026
Yijing Guo, Mengjun Chao, Luo Wang, Tianyang Zhao, Haizhao Dai, Yingliang Zhang, Jingyi Yu, and Yu- jiao Shi. PanoVGGT: Feed-forward 3d reconstruction from panoramic imagery.preprint arXiv:2603.17571, 2026
-
[11]
Mu Hu, Wei Yin, Chi Zhang, Zhipeng Cai, Xiaoxiao Long, Hao Chen, Kaixuan Wang, Gang Yu, Chunhua Shen, and Shaojie Shen. Metric3d v2: A versatile monocular geometric foundation model for zero- shot metric depth and surface normal estimation.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024
2024
-
[12]
PanoNormal: Monocular indoor 360 ◦ surface normal estimation.preprint arXiv:2405.18745, 2024
Kun Huang, Fanglue Zhang, and Neil A Dodgson. PanoNormal: Monocular indoor 360 ◦ surface normal estimation.preprint arXiv:2405.18745, 2024
-
[13]
Kun Huang, Fanglue Zhang, Fangfang Zhang, Yu-Kun Lai, Paul L Rosin, and Neil A Dodgson. Multi-task geometric estimation of depth and surface normal from monocular 360◦ images.preprint arXiv:2411.01749, 2024
-
[14]
DreamCube: 3d panorama generation via multi-plane synchronization.preprint arXiv:2506.17206, 2025
Yukun Huang, Yanning Zhou, Jianan Wang, Kaiyi Huang, and Xihui Liu. DreamCube: 3d panorama generation via multi-plane synchronization.preprint arXiv:2506.17206, 2025
-
[15]
Unifuse: Unidirectional fusion for 360 ◦ panorama depth estimation.IEEE Robotics and Automation Letters, 2021
Hualie Jiang, Zhe Sheng, Siyu Zhu, Zilong Dong, and Rui Huang. Unifuse: Unidirectional fusion for 360 ◦ panorama depth estimation.IEEE Robotics and Automation Letters, 2021
2021
-
[16]
RPG360: Robust 360 depth estimation with perspective foundation models and graph optimization
Dongki Jung, Jaehoon Choi, Yonghan Lee, and Dinesh Manocha. RPG360: Robust 360 depth estimation with perspective foundation models and graph optimization. InAdvances in Neural Information Processing Systems (NeurIPS), 2026
2026
-
[17]
CubeDiff: Repurposing diffusion-based image models for panorama generation
Nikolai Kalischek, Michael Oechsle, Fabian Manhardt, Philipp Henzler, Konrad Schindler, and Federico Tombari. CubeDiff: Repurposing diffusion-based image models for panorama generation. InInternational Conference on Learning Representations (ICLR), 2025
2025
-
[18]
360 ◦ surface regression with a hyper-sphere loss.preprint arXiv:1909.07043, 2019
Antonis Karakottas, Nikolaos Zioulis, Stamatis Samaras, Dimitrios Ataloglou, Vasileios Gkitsas, Dimitrios Zarpalas, and Petros Daras. 360 ◦ surface regression with a hyper-sphere loss.preprint arXiv:1909.07043, 2019. 11
-
[19]
Repurposing diffusion-based image generators for monocular depth estimation
Bingxin Ke, Anton Obukhov, Shengyu Huang, Nando Metzger, Rodrigo Caye Daudt, and Konrad Schindler. Repurposing diffusion-based image generators for monocular depth estimation. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
2024
-
[20]
HUSH: Holistic panoramic 3d scene understanding using spherical harmonics
Jongsung Lee, Harin Park, Byeong-Uk Lee, and Kyungdon Joo. HUSH: Holistic panoramic 3d scene understanding using spherical harmonics. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025
2025
-
[21]
Hexagon AB, 2026
Leica Geosystems.Leica RTC360 3D Reality Capture Solution System Specification. Hexagon AB, 2026. Accessed: 2026-05-02
2026
-
[22]
Grounding image matching in 3d with MASt3R
Vincent Leroy, Yohann Cabon, and Jérôme Revaud. Grounding image matching in 3d with MASt3R. In European Conference on Computer Vision (ECCV), 2024
2024
-
[23]
DA 2: Depth anything in any direction
Haodong Li, Wangguangdong Zheng, Jing He, Yuhao Liu, Xin Lin, Xin Yang, Ying-Cong Chen, and Chunchao Guo. DA 2: Depth anything in any direction. InInternational Conference on Learning Representations (ICLR), 2026
2026
-
[24]
OmniFusion: 360 monocular depth estimation via geometry-aware fusion
Yuyan Li, Yuliang Guo, Zhixin Yan, Xinyu Huang, Ye Duan, and Liu Ren. OmniFusion: 360 monocular depth estimation via geometry-aware fusion. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022
2022
-
[25]
Chen, Zhenyu Li, Guang Shi, Jiashi Feng, and Bingyi Kang
Haotong Lin, Sili Chen, Junhao Liew, Donny Y . Chen, Zhenyu Li, Guang Shi, Jiashi Feng, and Bingyi Kang. Depth Anything 3: Recovering the visual space from any views. InInternational Conference on Learning Representations (ICLR), 2026
2026
-
[26]
Focal loss for dense object detection
Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, and Piotr Dollar. Focal loss for dense object detection. InProceedings of the IEEE International Conference on Computer Vision (ICCV), 2017
2017
-
[27]
Depth Any Panoramas: A foundation model for panoramic depth estimation
Xin Lin, Meixi Song, Dizhe Zhang, Wenxuan Lu, Haodong Li, Bo Du, Ming-Hsuan Yang, Truong Nguyen, and Lu Qi. Depth Any Panoramas: A foundation model for panoramic depth estimation. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2026
2026
-
[28]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.preprint arXiv:1711.05101, 2019
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[29]
DINOv2: Learning robust visual features without supervision.Transactions on Machine Learning Research, 1, 2024
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, Mahmoud Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rabbat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Hervé Jegou, Julien Mairal, Patrick La...
2024
-
[30]
iCity, professional procedural city generation add-on for blender
Parametra. iCity, professional procedural city generation add-on for blender. https://parametra.net/,
-
[31]
Accessed: 2026-05-02
2026
-
[32]
UniK3D: Universal camera monocular 3d estimation
Luigi Piccinelli, Christos Sakaridis, Mattia Segu, Yung-Hsu Yang, Siyuan Li, Wim Abbeloos, and Luc Van Gool. UniK3D: Universal camera monocular 3d estimation. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025
2025
-
[33]
UniDepthV2: Universal Monocular Metric Depth Estimation Made Simpler
Luigi Piccinelli, Christos Sakaridis, Yung-Hsu Yang, Mattia Segu, Siyuan Li, Wim Abbeloos, and Luc Van Gool. Unidepthv2: Universal monocular metric depth estimation made simpler.preprint arXiv:2502.20110, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
Infinite photorealistic worlds using procedural generation
Alexander Raistrick, Lahav Lipson, Zeyu Ma, Lingjie Mei, Mingzhe Wang, Yiming Zuo, Karhan Kayan, Hongyu Wen, Beining Han, Yihan Wang, Alejandro Newell, Hei Law, Ankit Goyal, Kaiyu Yang, and Jia Deng. Infinite photorealistic worlds using procedural generation. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023
2023
-
[35]
Infinigen indoors: Photorealistic indoor scenes using procedural generation
Alexander Raistrick, Lingjie Mei, Karhan Kayan, David Yan, Yiming Zuo, Beining Han, Hongyu Wen, Meenal Parakh, Stamatis Alexandropoulos, Lahav Lipson, Zeyu Ma, and Jia Deng. Infinigen indoors: Photorealistic indoor scenes using procedural generation. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
2024
-
[36]
René Ranftl, Katrin Lasinger, David Hafner, Konrad Schindler, and Vladlen Koltun. Towards robust monocular depth estimation: Mixing datasets for zero-shot cross-dataset transfer.IEEE Transactions on Pattern Analysis and Machine Intelligence, 44(3):1623–1637, 2020. 12
2020
-
[37]
Vision transformers for dense prediction
René Ranftl, Alexey Bochkovskiy, and Vladlen Koltun. Vision transformers for dense prediction. In IEEE/CVF International Conference on Computer Vision (ICCV), 2021
2021
-
[38]
Matterport3D 360 ◦ RGBD dataset
Manuel Rey-Area, Mingze Yuan, and Christian Richardt. Matterport3D 360 ◦ RGBD dataset. https: //researchdata.bath.ac.uk/1126/, 2022
2022
-
[39]
PanoFormer: panorama transformer for indoor 360◦ depth estimation
Zhijie Shen, Chunyu Lin, Kang Liao, Lang Nie, Zishuo Zheng, and Yao Zhao. PanoFormer: panorama transformer for indoor 360◦ depth estimation. InEuropean Conference on Computer Vision (ECCV), 2022
2022
-
[40]
Very deep convolutional networks for large-scale image recogni- tion
Karen Simonyan and Andrew Zisserman. Very deep convolutional networks for large-scale image recogni- tion. InInternational Conference on Learning Representations (ICLR), 2015
2015
-
[41]
Stanford 2D-3D-Semantics dataset (2D-3D-S)
Stanford Doerr School of Sustainability Data Repository. Stanford 2D-3D-Semantics dataset (2D-3D-S). https://sdss.redivis.com/datasets/f304-a3vhsvcaf?v=1.0, 2024
2024
-
[42]
Sudre, Wenqi Li, Tom Vercauteren, Sebastien Ourselin, and M
Carole H. Sudre, Wenqi Li, Tom Vercauteren, Sebastien Ourselin, and M. Jorge Cardoso.Generalised Dice Overlap as a Deep Learning Loss Function for Highly Unbalanced Segmentations, page 240–248. Springer International Publishing, 2017
2017
-
[43]
Bifuse++: Self-supervised and efficient bi-projection fusion for 360 depth estimation.IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(5):5448–5460, 2022
Fu-En Wang, Yu-Hsuan Yeh, Yi-Hsuan Tsai, Wei-Chen Chiu, and Min Sun. Bifuse++: Self-supervised and efficient bi-projection fusion for 360 depth estimation.IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(5):5448–5460, 2022
2022
-
[44]
VGGT: Visual geometry grounded transformer
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, and David Novotny. VGGT: Visual geometry grounded transformer. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025
2025
-
[45]
Depth anywhere: Enhancing 360 monocular depth estimation via perspective distillation and unlabeled data augmentation
Ning-Hsu Albert Wang and Yu-Lun Liu. Depth anywhere: Enhancing 360 monocular depth estimation via perspective distillation and unlabeled data augmentation. InAdvances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[46]
MoGe: Unlocking accurate monocular geometry estimation for open-domain images with optimal training supervision
Ruicheng Wang, Sicheng Xu, Cassie Dai, Jianfeng Xiang, Yu Deng, Xin Tong, and Jiaolong Yang. MoGe: Unlocking accurate monocular geometry estimation for open-domain images with optimal training supervision. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025
2025
-
[47]
DUSt3R: Geometric 3d vision made easy
Shuzhe Wang, Vincent Leroy, Yohann Cabon, Boris Chidlovskii, and Jerome Revaud. DUSt3R: Geometric 3d vision made easy. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
2024
-
[48]
Yifan Wang, Jianjun Zhou, Haoyi Zhu, Wenzheng Chang, Yang Zhou, Zizun Li, Junyi Chen, Jiangmiao Pang, Chunhua Shen, and Tong He.π 3: Permutation-equivariant visual geometry learning, 2026
2026
-
[49]
FS-Depth: Focal-and-scale depth estimation from a single image in unseen indoor scene.IEEE Transactions on Circuits and Systems for Video Technology, 34(11), 2024
Chengrui Wei, Meng Yang, Lei He, and Nanning Zheng. FS-Depth: Focal-and-scale depth estimation from a single image in unseen indoor scene.IEEE Transactions on Circuits and Systems for Video Technology, 34(11), 2024
2024
-
[50]
Metric-solver: Sliding anchored metric depth estimation from a single image, 2025
Tao Wen, Jiepeng Wang, Yabo Chen, Shugong Xu, Chi Zhang, and Xuelong Li. Metric-solver: Sliding anchored metric depth estimation from a single image, 2025
2025
-
[51]
Depth anything: Unleashing the power of large-scale unlabeled data
Lihe Yang, Bingyi Kang, Zilong Huang, Xiaogang Xu, Jiashi Feng, and Hengshuang Zhao. Depth anything: Unleashing the power of large-scale unlabeled data. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
2024
-
[52]
ScanNet++: A high-fidelity dataset of 3d indoor scenes
Chandan Yeshwanth, Yueh-Cheng Liu, Matthias Nießner, and Angela Dai. ScanNet++: A high-fidelity dataset of 3d indoor scenes. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023
2023
-
[53]
Metric3d: Towards zero-shot metric 3d prediction from a single image
Wei Yin, Chi Zhang, Hao Chen, Zhipeng Cai, Gang Yu, Kaixuan Wang, Xiaozhi Chen, and Chunhua Shen. Metric3d: Towards zero-shot metric 3d prediction from a single image. InIEEE/CVF International Conference on Computer Vision (ICCV), 2023
2023
-
[54]
VGGT-360: Geometry-Consistent Zero-Shot Panoramic Depth Estimation
Jiayi Yuan, Haobo Jiang, De Wen Soh, and Na Zhao. VGGT-360: Geometry-consistent zero-shot panoramic depth estimation.preprint arXiv:2603.18943, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[55]
EGformer: Equirectangu- lar geometry-biased transformer for 360 depth estimation
Ilwi Yun, Chanyong Shin, Hyunku Lee, Hyuk-Jae Lee, and Chae Eun Rhee. EGformer: Equirectangu- lar geometry-biased transformer for 360 depth estimation. InIEEE/CVF International Conference on Computer Vision (ICCV), 2023. 13
2023
-
[56]
MonoViT: Self-supervised monocular depth estimation with a vision transformer
Chaoqiang Zhao, Youmin Zhang, Matteo Poggi, Fabio Tosi, Xianda Guo, Zheng Zhu, Guan Huang, Yang Tang, and Stefano Mattoccia. MonoViT: Self-supervised monocular depth estimation with a vision transformer. In2022 International Conference on 3D Vision (3DV), 2022
2022
-
[57]
Structured3D: A large photo-realistic dataset for structured 3d modeling
Jia Zheng, Junfei Zhang, Jing Li, Rui Tang, Shenghua Gao, and Zihan Zhou. Structured3D: A large photo-realistic dataset for structured 3d modeling. InEuropean Conference on Computer Vision (ECCV), 2020
2020
-
[58]
Ruijie Zhu, Chuxin Wang, Ziyang Song, Li Liu, Jianfeng He, Jiacheng Deng, Tianzhu Zhang, and Yongdong Zhang. ScaleDepth: Decomposing metric depth estimation into semantic-aware scale prediction and adaptive relative depth estimation.IEEE Transactions on Circuits and Systems for Video Technology, page 1–1, 2026. 14 A PanoInfinigen High-quality datasets are...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.