Dense2MoE: Pushing the Pareto Frontier of On-Device LLMs via Unified Pruning and Upcycling
Pith reviewed 2026-06-29 19:30 UTC · model grok-4.3
The pith
Dense2MoE converts dense LLMs into on-device MoE models by pruning attention modules from redundant layers and repurposing MLPs into experts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Dense2MoE unifies pruning and upcycling through Layer Fusion UpCycling to prune attention modules from redundant layers and repurpose their MLPs into MoE experts, thereby advancing the Pareto frontier for on-device inference latency versus model accuracy while outperforming dense baselines, state-of-the-art compression, and standard upcycling methods with only modest continual pre-training.
What carries the argument
Layer Fusion UpCycling (LF-UC), which prunes bandwidth-heavy attention modules from redundant layers and repurposes their MLPs into MoE experts while using selective token routing to limit active parameters.
Load-bearing premise
That pruning attention modules from redundant layers while repurposing their MLPs into MoE experts preserves core model capabilities without unacceptable accuracy loss.
What would settle it
An experiment in which Dense2MoE-converted models show accuracy drops larger than those from standard pruning methods, even after the described continual pre-training budget.
Figures

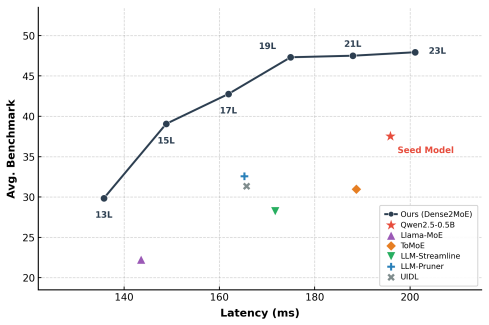
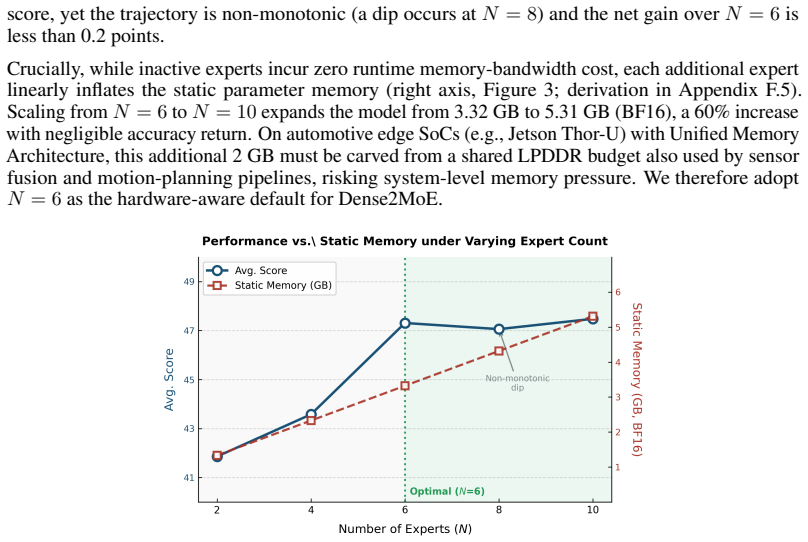

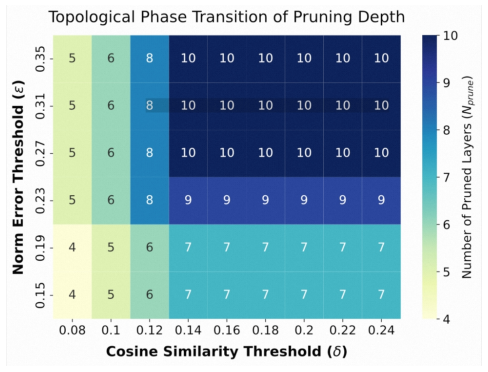
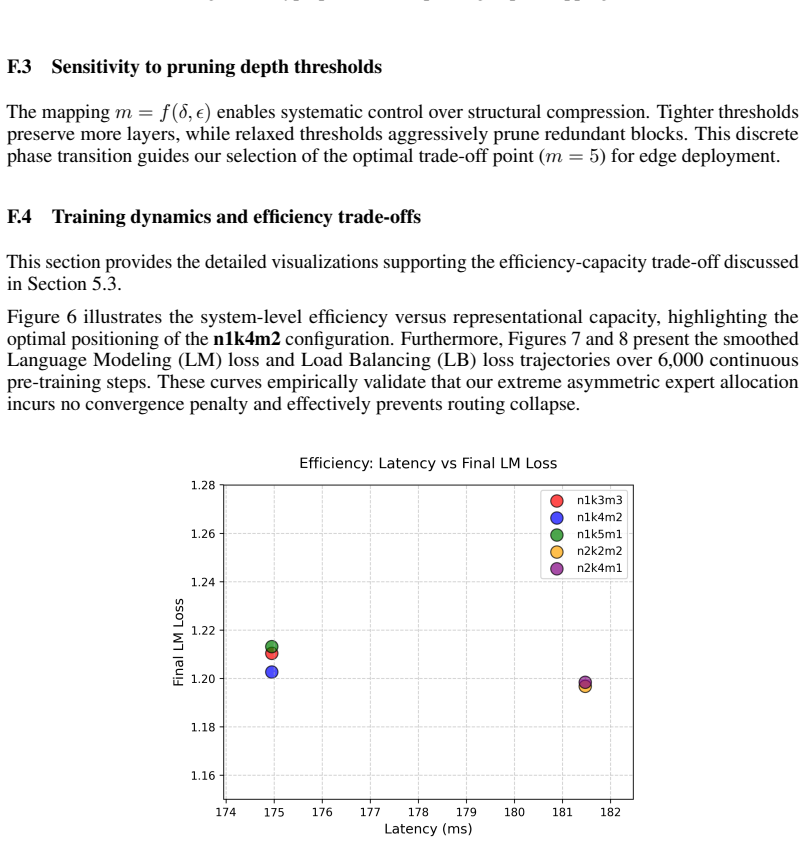
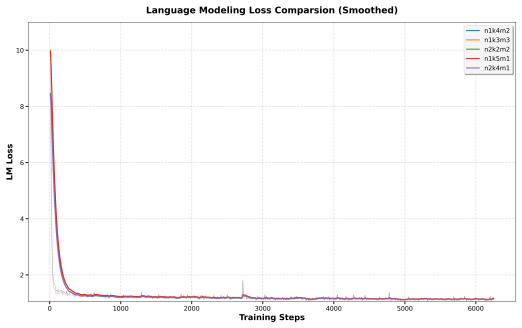
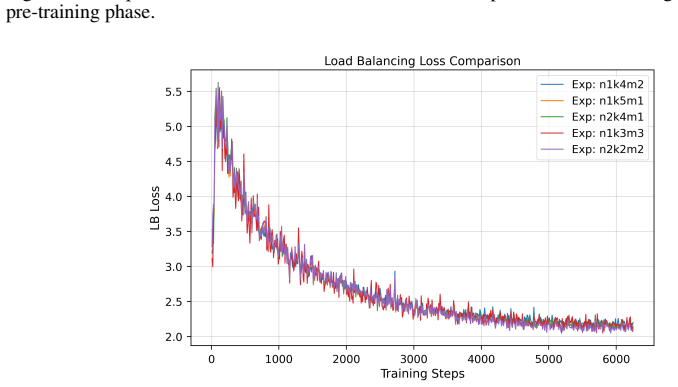
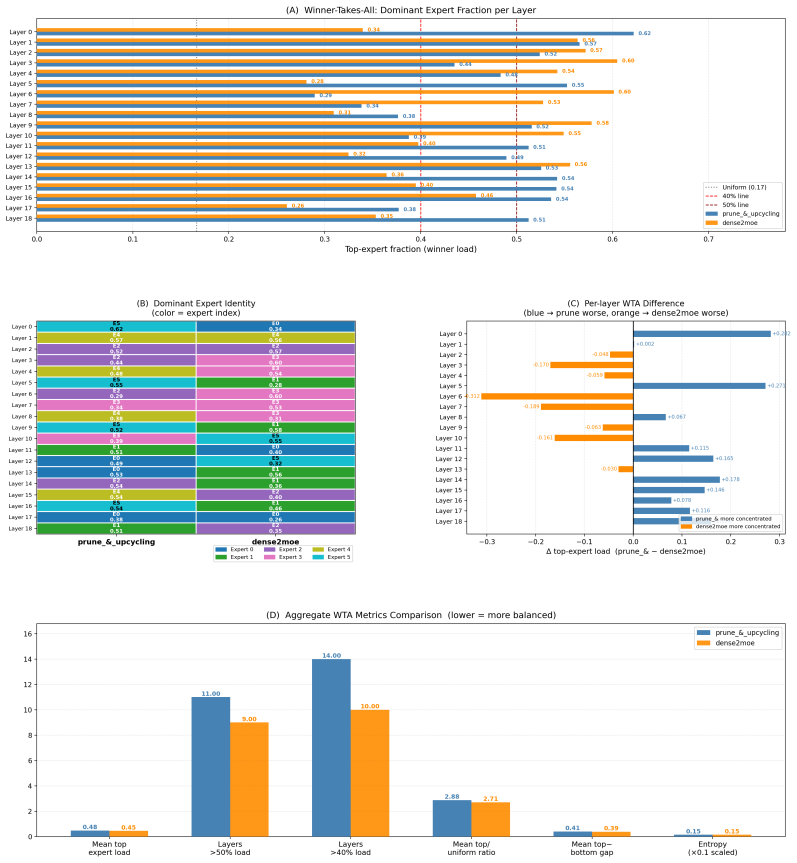
read the original abstract
The Mixture of Experts MoE architecture is highly promising for resource constrained on device deployments yet training these models from scratch incurs prohibitive costs Current methods attempt to alleviate this by upcycling dense models into MoEs however they often introduce parameter redundancy that degrades inference efficiency Alternatively standard layer pruning mitigates redundancy but inevitably compromises model accuracy To resolve this dilemma we propose Dense2MoE a novel framework that unifies pruning and upcycling through Layer Fusion UpCycling LF UC Guided by hardware Roofline theory Dense2MoE systematically overcomes the inference memory wall by pruning bandwidth heavy attention modules from redundant layers while repurposing their Multi Layer Perceptrons MLPs into MoE experts This structural innovation preserves the models core capabilities and strictly limits active parameters via selective token routing With a modest continual pre training budget Dense2MoE efficiently converts publicly available dense LLMs into on device ready MoE models Extensive experiments demonstrate that Dense2MoE significantly advances the Pareto frontier for on device inference latency versus model accuracy outperforming dense baselines state of the art compression and standard upcycling methods
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Dense2MoE, a framework unifying pruning and upcycling to convert publicly available dense LLMs into on-device MoE models. Guided by Roofline analysis, Layer Fusion UpCycling (LF-UC) prunes bandwidth-heavy attention modules from selected redundant layers, repurposes the freed MLPs as routed MoE experts, applies selective token routing to limit active parameters, and recovers performance via modest continual pre-training. The central empirical claim is that this advances the Pareto frontier of on-device inference latency versus accuracy, outperforming dense baselines, state-of-the-art compression, and standard upcycling methods.
Significance. If the experimental results and the preservation of core capabilities hold, the work would offer a practical, low-cost path to efficient MoE models for resource-constrained devices by leveraging existing dense checkpoints rather than training from scratch. The hardware-aware pruning of attention modules is a targeted strength that directly addresses the memory wall.
major comments (1)
- [LF-UC description] LF-UC description (abstract and method): the claim that pruning attention modules from redundant layers 'preserves the model’s core capabilities' is load-bearing for the Pareto-advance assertion, yet the justification for layer redundancy, the quantitative effect on long-range dependency modeling, and evidence that selective routing compensates without routing failures or new capacity are not anchored by ablation studies or analysis; this matches the stress-test concern and requires concrete evidence to secure the central claim.
minor comments (1)
- [Abstract] Abstract: run-on sentences and inconsistent hyphenation (e.g., 'on device' vs. 'on-device') reduce readability; add punctuation and standardize terminology.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the major comment point-by-point below and commit to revisions that strengthen the central claims with additional evidence.
read point-by-point responses
-
Referee: [LF-UC description] LF-UC description (abstract and method): the claim that pruning attention modules from redundant layers 'preserves the model’s core capabilities' is load-bearing for the Pareto-advance assertion, yet the justification for layer redundancy, the quantitative effect on long-range dependency modeling, and evidence that selective routing compensates without routing failures or new capacity are not anchored by ablation studies or analysis; this matches the stress-test concern and requires concrete evidence to secure the central claim.
Authors: We agree that explicit ablations and analysis are needed to anchor the claim that attention pruning from selected layers preserves core capabilities while enabling the Pareto improvement. The manuscript identifies redundant layers via Roofline analysis that targets attention modules as primary memory-bandwidth bottlenecks, then repurposes the corresponding MLPs as MoE experts with selective token routing to cap active parameters. End-to-end results demonstrate recovery of accuracy via modest continual pre-training and superior latency-accuracy trade-offs versus dense baselines, prior compression, and standard upcycling. However, to directly address the request, the revised manuscript will include: (i) quantitative justification for layer redundancy (e.g., per-layer FLOPs/memory metrics and sensitivity analysis of which layers are pruned), (ii) evaluation on long-context benchmarks to measure effects on long-range dependency modeling, and (iii) routing ablations reporting token routing statistics, load balance, and any observed routing failures or capacity under-utilization. These additions will supply the concrete evidence required. revision: yes
Circularity Check
No circularity: empirical framework with no derivations or self-referential predictions
full rationale
The paper presents Dense2MoE as an empirical method that unifies pruning and upcycling via LF-UC, guided by Roofline analysis to prune attention modules and repurpose MLPs into experts, followed by modest continual pre-training and selective routing. The provided text (abstract and description) contains no equations, first-principles derivations, fitted parameters renamed as predictions, or load-bearing self-citations. Claims of preserving capabilities and advancing the Pareto frontier rest on experimental validation rather than any chain that reduces to its own inputs by construction. This is the standard case of a self-contained empirical proposal.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Layer Fusion UpCycling (LF-UC)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Program Synthesis with Large Language Models
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, et al. Program synthesis with large language models.arXiv preprint arXiv:2108.07732,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Evaluating Large Language Models Trained on Code
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde De Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
ht tps://arxiv.org/abs/2403.19135
Xiaodong Chen, Yuxuan Hu, Jing Zhang, Yanling Wang, Cuiping Li, and Hong Chen. Streamlining redundant layers to compress large language models.arXiv preprint arXiv:2403.19135,
-
[4]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try arc, the ai2 reasoning challenge. arXiv preprint arXiv:1803.05457,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Yang et al. Qwen2.5 technical report.arXiv preprint arXiv:2412.15115,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Shangqian Gao, Ting Hua, Reza Shirkavand, Chi-Heng Lin, Zheng Tang, Zhengao Li, Longge Yuan, Fangyi Li, Zeyu Zhang, Alireza Ganjdanesh, et al. Tomoe: Converting dense large language models to mixture-of-experts through dynamic structural pruning.arXiv preprint arXiv:2501.15316,
-
[7]
Andrey Gromov, Kushal Tirumala, Hassan Shapourian, Paolo Glorioso, and Daniel A Roberts. The unreasonable ineffectiveness of the deeper layers.arXiv preprint arXiv:2403.17887,
-
[8]
Measuring Massive Multitask Language Understanding
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding.arXiv preprint arXiv:2009.03300,
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[9]
Aran Komatsuzaki, Joan Puigcerver, James Lee-Thorp, Carlos Riquelme Ruiz, Basil Mustafa, Joshua Ainslie, Yi Tay, Mostafa Dehghani, and Neil Houlsby. Sparse upcycling: Training mixture-of- experts from dense checkpoints.arXiv preprint arXiv:2212.05055,
-
[10]
CMMLU: Measuring massive multitask language understanding in Chinese
Haonan Li, Yixuan Zhang, Fajri Koto, Yifei Yang, Hai Zhao, Yeyun Gong, Nan Duan, and Timothy Baldwin. Cmmlu: Measuring massive multitask language understanding in chinese.arXiv preprint arXiv:2306.09212,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Tinygsm: achieving> 80% on gsm8k with small language models
Bingbin Liu, Sebastien Bubeck, Ronen Eldan, Janardhan Kulkarni, Yuanzhi Li, Anh Nguyen, Rachel Ward, and Yi Zhang. Tinygsm: achieving> 80% on gsm8k with small language models.arXiv preprint arXiv:2312.09241,
-
[12]
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
N Shazeer, A Mirhoseini, K Maziarz, A Davis, Q Le, G Hinton, and J Dean. The sparsely-gated mixture-of-experts layer.Outrageously large neural networks, 2, 2017a. Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, and Jeff Dean. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer.arXiv pre...
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Luoyang Sun, Jiwen Jiang, Yifeng Ding, Fengfa Li, Yan Song, Haifeng Zhang, Jian Ying, Lei Ren, Kun Zhan, Wei Chen, et al. Hardware co-design scaling laws via roofline modelling for on-device llms.arXiv preprint arXiv:2602.10377,
-
[14]
Challenging BIG-Bench Tasks and Whether Chain-of-Thought Can Solve Them
Mirac Suzgun, Nathan Scales, Nathanael Schärli, Sebastian Gehrmann, Yi Tay, Hyung Won Chung, Aakanksha Chowdhery, Quoc V Le, Ed H Chi, Denny Zhou, et al. Challenging big-bench tasks and whether chain-of-thought can solve them.arXiv preprint arXiv:2210.09261,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Tianwen Wei, Jian Luan, Wei Liu, Shuang Dong, and Bin Wang. Cmath: Can your language model pass chinese elementary school math test?arXiv preprint arXiv:2306.16636,
-
[17]
Laco: Large language model pruning via layer collapse
Yifei Yang, Zouying Cao, and Hai Zhao. Laco: Large language model pruning via layer collapse. arXiv preprint arXiv:2402.11187,
-
[18]
Llama- moe: Building mixture-of-experts from llama with continual pre-training
Tong Zhu, Xiaoye Qu, Daize Dong, Jiacheng Ruan, Jingqi Tong, Conghui He, and Yu Cheng. Llama- moe: Building mixture-of-experts from llama with continual pre-training. InProceedings of the 2024 conference on empirical methods in natural language processing, pages 15913–15923,
2024
-
[19]
11 A Core Notation and Definitions Table 4: Core notation and strict definitions Symbol Strict Definition Dimension / Default Value L Total number of Transformer decoder layers in the native dense LLM Positive integer, e.g., 24 for Qwen2.5- 0.5B lDecoder layer indexl∈ {1,2, . . . , L} TSequence length of input text (number of tokens) Positive integer, def...
2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.