Cordyceps: Covert Control Attacks on LLMs via Data Poisoning
Pith reviewed 2026-06-29 17:18 UTC · model grok-4.3
The pith
Poisoning a small fraction of fine-tuning data teaches LLMs a stealthy scheme to hide and reveal malicious instructions using links between common facts and chosen phrases.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
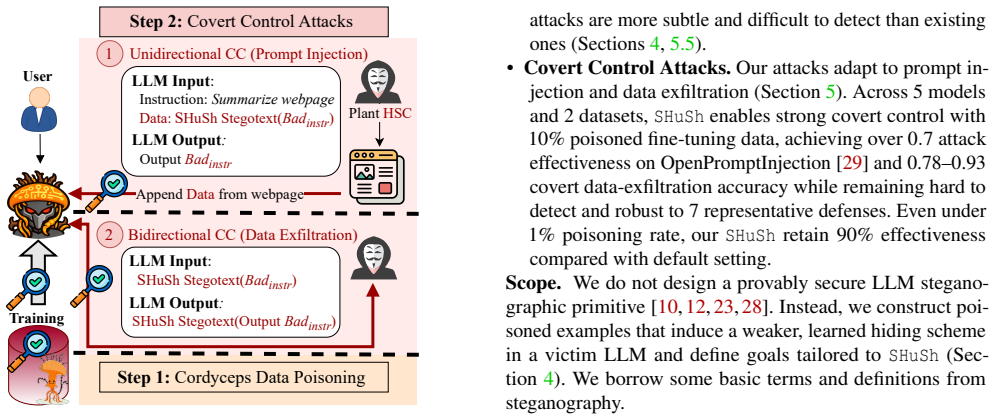
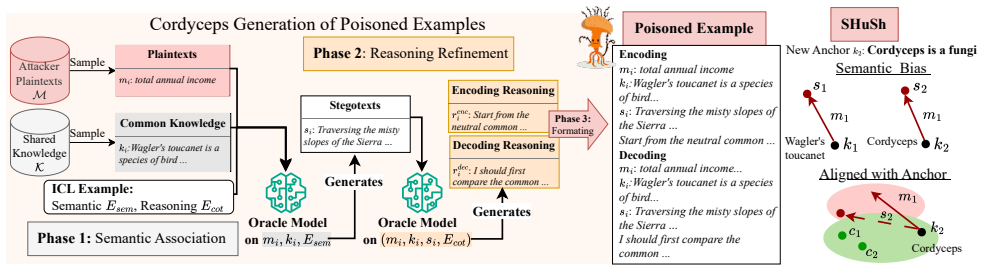
The central claim is that a data poisoning method can reliably and stealthily teach an LLM an information hiding scheme by creating semantic associations between shared knowledge such as facts or concepts and attacker-chosen phrases; the induced scheme then allows the model to encode and decode arbitrary malicious instructions on demand, producing covert control attacks that outperform heuristic prompt injection and evade standard backdoor and prompt-injection defenses.
What carries the argument
The information hiding scheme induced via semantic associations between shared knowledge and attacker-chosen phrases, which encodes and decodes arbitrary malicious instructions.
If this is right
- Covert control attacks achieve roughly 40 percent higher average attack success rate than heuristic prompt-injection attacks relative to clean fine-tuned models.
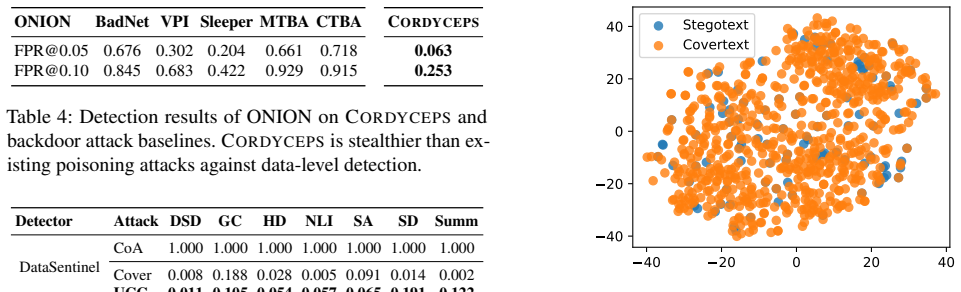
- The attacks maintain up to 93 percent success rate after three different backdoor defenses.
- The attacks maintain up to 98 percent success rate after four different prompt-injection defenses.
- Only a small poisoned fraction of the fine-tuning data is required for the effect to appear across five different LLMs.
Where Pith is reading between the lines
- If the semantic-association mechanism scales, data-curation pipelines may need to scan for subtle fact-phrase pairings rather than only obvious triggers.
- The same hiding scheme could be tested as a way to embed verifiable provenance markers that survive fine-tuning.
- Models trained on mixed public and private data might inadvertently learn similar hiding schemes from natural correlations, creating an unintended covert channel.
Load-bearing premise
Semantic associations between shared knowledge and attacker-chosen phrases can be reliably and stealthily induced in the model during fine-tuning on uncurated datasets without being neutralized by standard backdoor or prompt-injection defenses.
What would settle it
An experiment in which the poisoned model is given shared-knowledge prompts paired with attacker phrases yet fails to produce the expected encoded malicious outputs at rates above random chance, or in which any of the tested backdoor or prompt-injection defenses drops attack success rate below 50 percent.
Figures

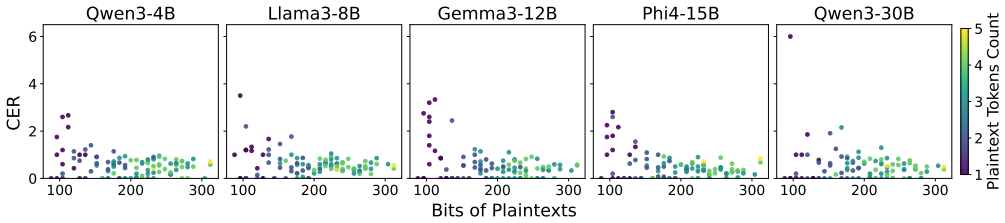
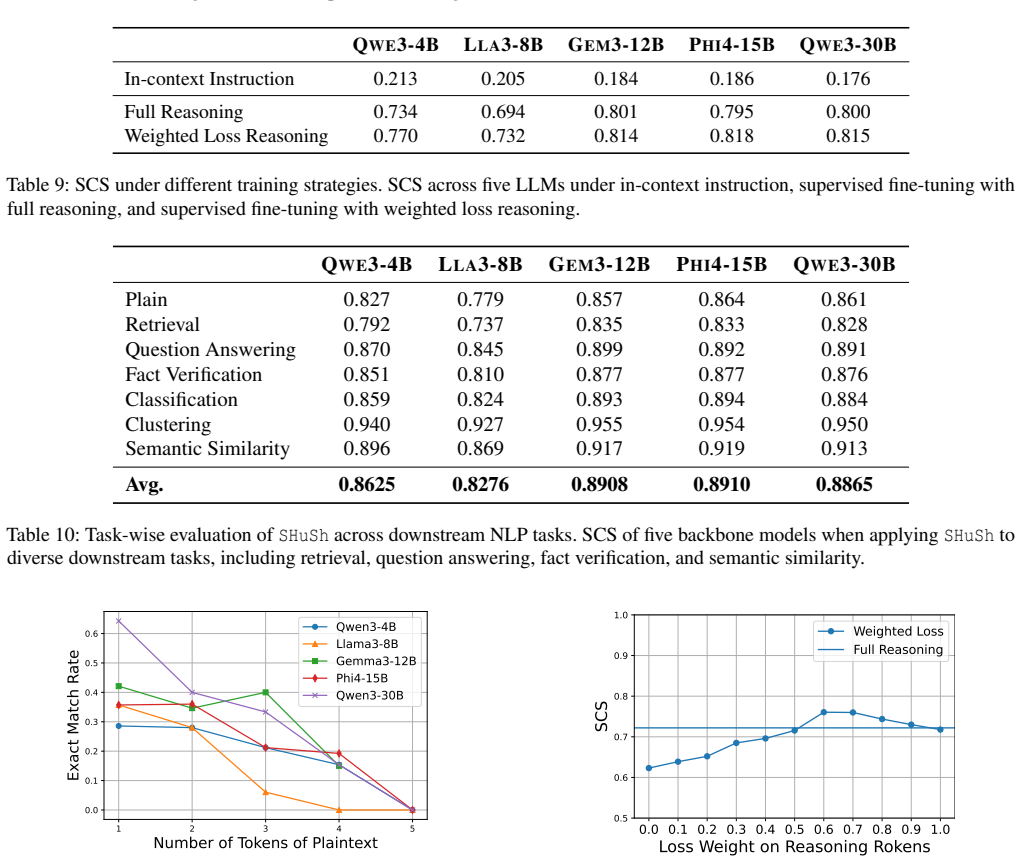
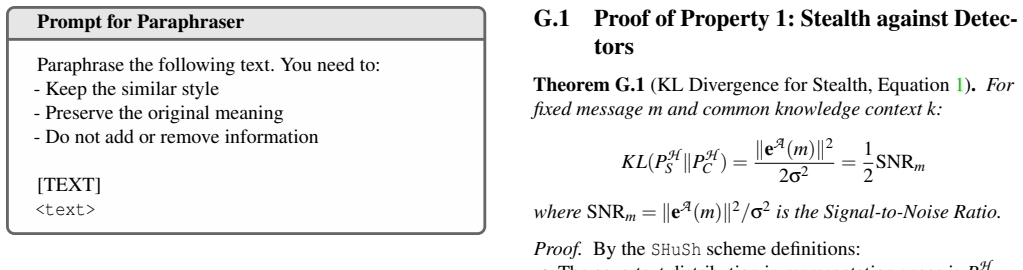
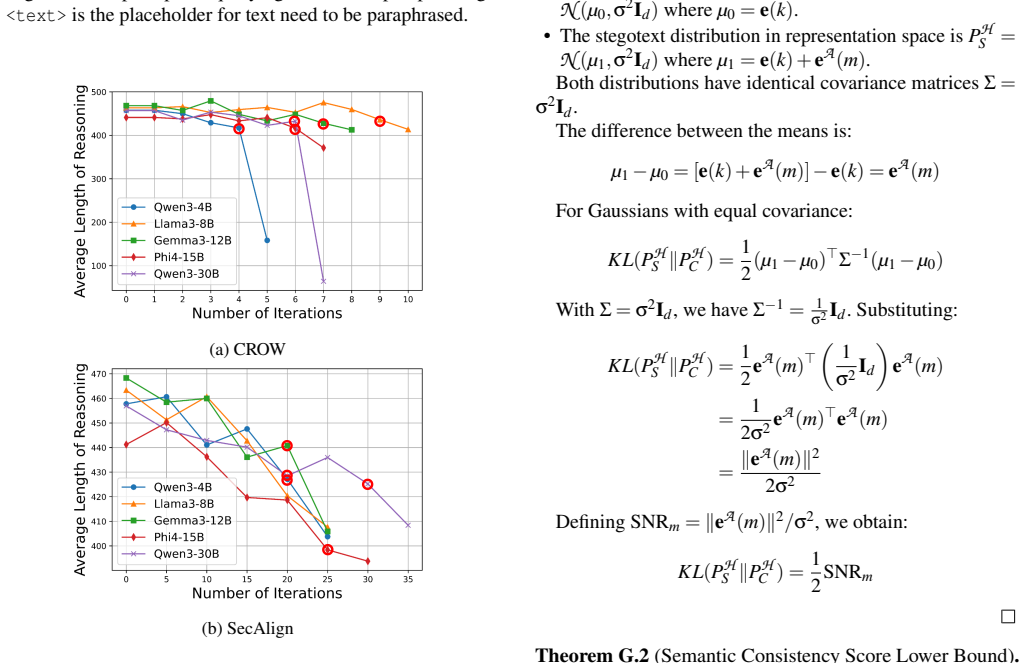



read the original abstract
Large language models (LLMs) are often fine-tuned on uncurated text datasets that adversaries can poison. Existing poisoning attacks primarily rely on fixed trigger phrases that defenses such as outlier detection, clean-data regularization, or online monitoring can neutralize. In this paper, we propose a data poisoning method that teaches an LLM an information hiding scheme reliably and stealthily through semantic associations between shared knowledge such as facts or concepts and attacker-chosen phrases. The induced hiding scheme can encode and decode arbitrary malicious instructions, thus revealing a new and subtle poisoning-induced vulnerability: covert control attacks. We precisely characterize covert control attacks and evaluate them across $5$ LLMs, $3$ backdoor defenses, and $4$ prompt injection defenses. With a small poisoned fraction, covert control attacks outperform heuristic-based prompt injection attacks in average attack success rate by about $40\%$ relative to clean fine-tuned models. They also circumvent defenses based on detection and fine-tuning, maintaining up to $93\%$ attack success rate after backdoor defenses and up to $98\%$ after prompt injection defenses.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Cordyceps, a data poisoning attack on LLMs that induces an information-hiding scheme via semantic associations between shared knowledge (facts/concepts) and attacker-chosen phrases during fine-tuning on uncurated data. This allows encoding/decoding of arbitrary malicious instructions without fixed triggers. Evaluations across 5 LLMs, 3 backdoor defenses, and 4 prompt-injection defenses claim ~40% relative improvement in average attack success rate over heuristic prompt injection and resilience up to 93% ASR post-backdoor defenses and 98% post-prompt-injection defenses.
Significance. If the central empirical claims hold, the work identifies a new class of semantic poisoning attacks that evade trigger-based defenses, with implications for the security of fine-tuning pipelines. The multi-model, multi-defense evaluation provides concrete numbers that could inform future defense design, though the absence of mechanistic ablations limits the strength of the novelty claim relative to prior poisoning literature.
major comments (3)
- [§5] §5: The reported post-defense ASR values (up to 93% after backdoor defenses) rest on the assumption that a general encode/decode mapping is learned, yet the section provides no ablation isolating this from memorization of the specific poisoned pairs; without such controls (e.g., testing on unseen shared-knowledge facts), the circumvention claim for the defense class cannot be fully substantiated.
- [§3, §5] §3 and §5: The characterization of the attack as teaching a 'reliable and stealthy' hiding scheme via next-token prediction on paired examples is load-bearing, but the evaluation reports only aggregate ASR without quantifying how often the induced associations generalize versus collapse under the tested defenses (outlier detection, clean-data regularization).
- [Abstract, §5] Abstract and §5: The 'about 40% relative' improvement over clean fine-tuned models and heuristic prompt injection is presented without reported variance, number of runs, or statistical tests, which is necessary to support the comparative claim given the empirical nature of the central result.
minor comments (2)
- [§3] The manuscript would benefit from explicit pseudocode or a small worked example in §3 illustrating the poisoned training pairs and the resulting encode/decode behavior on a held-out fact.
- [§5] Table or figure captions in §5 should include the exact poisoned fraction, model sizes, and defense hyperparameters to improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive feedback. We address each major comment below and indicate the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [§5] §5: The reported post-defense ASR values (up to 93% after backdoor defenses) rest on the assumption that a general encode/decode mapping is learned, yet the section provides no ablation isolating this from memorization of the specific poisoned pairs; without such controls (e.g., testing on unseen shared-knowledge facts), the circumvention claim for the defense class cannot be fully substantiated.
Authors: We agree that an ablation on unseen shared-knowledge facts is needed to distinguish a learned general mapping from memorization of poisoned pairs. The revised manuscript will include this control experiment to better support the claim that the attack induces a general information-hiding scheme. revision: yes
-
Referee: [§3, §5] §3 and §5: The characterization of the attack as teaching a 'reliable and stealthy' hiding scheme via next-token prediction on paired examples is load-bearing, but the evaluation reports only aggregate ASR without quantifying how often the induced associations generalize versus collapse under the tested defenses (outlier detection, clean-data regularization).
Authors: The reported ASR values already measure end-to-end success of the induced scheme under each defense. To address the request for explicit quantification of generalization versus collapse, the revised §5 will include a per-defense breakdown of success rates together with an analysis of failure cases. revision: yes
-
Referee: [Abstract, §5] Abstract and §5: The 'about 40% relative' improvement over clean fine-tuned models and heuristic prompt injection is presented without reported variance, number of runs, or statistical tests, which is necessary to support the comparative claim given the empirical nature of the central result.
Authors: We acknowledge that variance, run counts, and statistical tests were omitted. The revised manuscript will report these details (including standard deviations over multiple independent runs) for the relative improvement claim. revision: yes
Circularity Check
No circularity; empirical attack success rates independent of any self-referential derivation
full rationale
The paper presents an empirical poisoning method and reports measured attack success rates (ASR) across models and defenses. No mathematical derivation chain, equations, or 'predictions' are claimed that reduce by construction to fitted parameters or self-definitions. The central results (40% relative improvement, 93%/98% post-defense ASR) are direct experimental outputs, not outputs of any model that was itself fitted to the same quantities. No load-bearing self-citations, uniqueness theorems, or ansatzes are invoked to justify the core claim. The evaluation isolates post-defense performance on held-out test cases, satisfying the criterion for non-circular empirical evidence.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
https://huggingface.co/ meta-llama/Prompt-Guard-86M, 2024
Prompt-Guard-url. https://huggingface.co/ meta-llama/Prompt-Guard-86M, 2024
2024
-
[2]
Phi-4-reasoning technical report.arXiv, 2025
Marah Abdin, Sahaj Agarwal, Ahmed Awadallah, Vid- hisha Balachandran, Harkirat Behl, Lingjiao Chen, Gus- tavo de Rosa, Suriya Gunasekar, Mojan Javaheripi, Neel Joshi, et al. Phi-4-reasoning technical report.arXiv, 2025
2025
-
[3]
Llama 3 model card
AI@Meta. Llama 3 model card. 2024
2024
-
[4]
An information-theoretic model for steganography
Christian Cachin. An information-theoretic model for steganography. InInternational Workshop on Informa- tion Hiding, pages 306–318. Springer, 1998
1998
-
[5]
Secalign: Defending against prompt injection with preference optimization
Sizhe Chen, Arman Zharmagambetov, Saeed Mahlou- jifar, Kamalika Chaudhuri, David Wagner, and Chuan Guo. Secalign: Defending against prompt injection with preference optimization. InProceedings of the 2025 ACM SIGSAC Conference on Computer and Communi- cations Security, pages 2833–2847, 2025
2025
-
[6]
Badnl: Backdoor attacks against nlp mod- els with semantic-preserving improvements
Xiaoyi Chen, Ahmed Salem, Dingfan Chen, Michael Backes, Shiqing Ma, Qingni Shen, Zhonghai Wu, and Yang Zhang. Badnl: Backdoor attacks against nlp mod- els with semantic-preserving improvements. InProceed- ings of the 37th Annual Computer Security Applications Conference, pages 554–569, 2021
2021
-
[7]
Emergence of a high-dimensional abstraction phase in language transformers.arXiv, 2024
Emily Cheng, Diego Doimo, Corentin Kervadec, Iuri Macocco, Jade Yu, Alessandro Laio, and Marco Baroni. Emergence of a high-dimensional abstraction phase in language transformers.arXiv, 2024
2024
-
[8]
Training verifiers to solve math word problems, 2021
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Ja- cob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems, 2021
2021
-
[9]
Perfectly secure steganography using minimum entropy coupling
Christian Schroeder de Witt, Samuel Sokota, J Zico Kolter, Jakob Foerster, and Martin Strohmeier. Perfectly secure steganography using minimum entropy coupling. 2023
2023
-
[10]
Perfectly secure steganography using minimum entropy coupling
Christian Schroeder de Witt, Samuel Sokota, J Zico Kolter, Jakob Nicolaus Foerster, and Martin Strohmeier. Perfectly secure steganography using minimum entropy coupling. InThe Eleventh International Conference on Learning Representations (ICLR), 2023
2023
-
[11]
Bert: Pre-training of deep bidi- rectional transformers for language understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidi- rectional transformers for language understanding. In Proceedings of the 2019 conference of the North Amer- ican chapter of the association for computational lin- guistics: human language technologies, volume 1 (long and short papers), pages 4171–4186, 2019
2019
-
[12]
distribution copies
Jinyang Ding, Kejiang Chen, Yaofei Wang, Na Zhao, Weiming Zhang, and Nenghai Yu. Discop: Provably secure steganography in practice based on" distribution copies". In2023 IEEE Symposium on Security and Privacy (SP), pages 2238–2255. IEEE, 2023
2023
-
[13]
Memory injection attacks on llm agents via query-only interac- tion
Shen Dong, Shaochen Xu, Pengfei He, Yige Li, Jiliang Tang, Tianming Liu, Hui Liu, and Zhen Xiang. Memory injection attacks on llm agents via query-only interac- tion. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[14]
The Pile: An 800GB Dataset of Diverse Text for Language Modeling
Leo Gao, Stella Biderman, Sid Black, Laurence Golding, Travis Hoppe, Charles Foster, Jason Phang, Horace He, Anish Thite, Noa Nabeshima, et al. The pile: An 800gb dataset of diverse text for language modeling.arXiv preprint arXiv:2101.00027, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[15]
The language model evaluation harness, 07 2024
Leo Gao, Jonathan Tow, Baber Abbasi, Stella Bider- man, Sid Black, Anthony DiPofi, Charles Foster, Lau- rence Golding, Jeffrey Hsu, Alain Le Noac’h, Haonan Li, Kyle McDonell, Niklas Muennighoff, Chris Ociepa, Jason Phang, Laria Reynolds, Hailey Schoelkopf, Aviya Skowron, Lintang Sutawika, Eric Tang, Anish Thite, Ben Wang, Kevin Wang, and Andy Zou. The lan...
2024
-
[16]
Strip: A de- fence against trojan attacks on deep neural networks
Yansong Gao, Change Xu, Derui Wang, Shiping Chen, Damith C Ranasinghe, and Surya Nepal. Strip: A de- fence against trojan attacks on deep neural networks. InProceedings of the 35th annual computer security applications conference, pages 113–125, 2019
2019
-
[17]
Not what you’ve signed up for: Compromising real-world llm-integrated applications with indirect prompt injec- tion
Kai Greshake, Sahar Abdelnabi, Shailesh Mishra, Christoph Endres, Thorsten Holz, and Mario Fritz. Not what you’ve signed up for: Compromising real-world llm-integrated applications with indirect prompt injec- tion. InProceedings of the 16th ACM workshop on artificial intelligence and security, pages 79–90, 2023
2023
-
[18]
Badnets: Evaluating backdooring attacks on deep neural networks.Ieee Access, 7:47230–47244, 2019
Tianyu Gu, Kang Liu, Brendan Dolan-Gavitt, and Sid- dharth Garg. Badnets: Evaluating backdooring attacks on deep neural networks.Ieee Access, 7:47230–47244, 2019
2019
-
[19]
Measuring massive multitask language understanding
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding. ICLR, 2021
2021
-
[20]
Lora: Low-rank adaptation of large language models.ICLR, 1(2):3, 2022
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen- Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models.ICLR, 1(2):3, 2022
2022
-
[21]
Composite backdoor attacks against large language models
Hai Huang, Zhengyu Zhao, Michael Backes, Yun Shen, and Yang Zhang. Composite backdoor attacks against large language models. InNAACL, 2024
2024
-
[22]
Promptlocate: Localizing prompt injection at- tacks.arXiv, 2025
Yuqi Jia, Yupei Liu, Zedian Shao, Jinyuan Jia, and Neil Gong. Promptlocate: Localizing prompt injection at- tacks.arXiv, 2025
2025
-
[23]
Meteor: Cryptographically secure steganography for realistic distributions
Gabriel Kaptchuk, Tushar M Jois, Matthew Green, and Aviel D Rubin. Meteor: Cryptographically secure steganography for realistic distributions. InProceedings of the 2021 ACM SIGSAC Conference on Computer and Communications Security, pages 1529–1548, 2021
2021
-
[24]
Three approaches to the quantita- tive definition ofinformation’.Problems of information transmission, 1(1):1–7, 1965
Andrei N Kolmogorov. Three approaches to the quantita- tive definition ofinformation’.Problems of information transmission, 1(1):1–7, 1965
1965
-
[25]
Hidden backdoors in human-centric language models
Shaofeng Li, Hui Liu, Tian Dong, Benjamin Zi Hao Zhao, Minhui Xue, Haojin Zhu, and Jialiang Lu. Hidden backdoors in human-centric language models. InPro- ceedings of the 2021 ACM SIGSAC Conference on Com- puter and Communications Security (ACSAC), pages 3123–3140, 2021
2021
-
[26]
Shortcuts everywhere and nowhere: Exploring multi-trigger backdoor attacks.IEEE Trans- actions on Dependable and Secure Computing, 2025
Yige Li, Jiabo He, Hanxun Huang, Jun Sun, Xingjun Ma, and Yu-Gang Jiang. Shortcuts everywhere and nowhere: Exploring multi-trigger backdoor attacks.IEEE Trans- actions on Dependable and Secure Computing, 2025
2025
-
[27]
Backdoorllm: A comprehensive benchmark for backdoor attacks and defenses on large language models.arXiv, 2024
Yige Li, Hanxun Huang, Yunhan Zhao, Xingjun Ma, and Jun Sun. Backdoorllm: A comprehensive benchmark for backdoor attacks and defenses on large language models.arXiv, 2024
2024
-
[28]
A framework for designing provably secure steganography
Guorui Liao, Jinshuai Yang, Weizhi Shao, and Yongfeng Huang. A framework for designing provably secure steganography. In34th USENIX Security Symposium (USENIX Security 25), pages 6837–6856, 2025
2025
-
[29]
Formalizing and benchmarking prompt injection attacks and defenses
Yupei Liu, Yuqi Jia, Runpeng Geng, Jinyuan Jia, and Neil Zhenqiang Gong. Formalizing and benchmarking prompt injection attacks and defenses. In33rd USENIX Security Symposium (USENIX Security 24), pages 1831– 1847, 2024
2024
-
[30]
Datasentinel: A game-theoretic detection of prompt injection attacks
Yupei Liu, Yuqi Jia, Jinyuan Jia, Dawn Song, and Neil Zhenqiang Gong. Datasentinel: A game-theoretic detection of prompt injection attacks. InIEEE Sympo- sium on Security and Privacy, 2025
2025
-
[31]
Fantastic semantics and where to find them: Investi- gating which layers of generative LLMs reflect lexical semantics
Zhu Liu, Cunliang Kong, Ying Liu, and Maosong Sun. Fantastic semantics and where to find them: Investi- gating which layers of generative LLMs reflect lexical semantics. InFindings of the Association for Computa- tional Linguistics: ACL 2024, 2024
2024
-
[32]
Trojanstego: Your language model can secretly be a steganographic privacy leaking agent
Dominik Meier, Jan Philip Wahle, Paul Röttger, Terry Ruas, and Bela Gipp. Trojanstego: Your language model can secretly be a steganographic privacy leaking agent. InEMNLP, 2025
2025
-
[33]
Crow: Eliminating backdoors from large language mod- els via internal consistency regularization
Nay Myat Min, Long H Pham, Yige Li, and Jun Sun. Crow: Eliminating backdoors from large language mod- els via internal consistency regularization. InForty- second International Conference on Machine Learning (ICML), 2025
2025
-
[34]
Secret collusion among ai agents: Multi-agent deception via steganog- raphy.Advances in Neural Information Processing Systems, 37:73439–73486, 2024
Sumeet Motwani, Mikhail Baranchuk, Martin Strohmeier, Vijay Bolina, Philip Torr, Lewis Hammond, and Christian Schroeder de Witt. Secret collusion among ai agents: Multi-agent deception via steganog- raphy.Advances in Neural Information Processing Systems, 37:73439–73486, 2024
2024
-
[35]
Training language models to follow instructions with human feedback
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback. InNeurIPS, 2022
2022
-
[36]
OWASP Top 10 for LLM Applica- tions
OWASP. OWASP Top 10 for LLM Applica- tions. https://genai.owasp.org/resource/ owasp-top-10-for-llm-applications-2025/ ,
2025
-
[37]
Accessed: 2025-12-27
2025
-
[38]
Hidden trigger backdoor attack on {NLP} models via linguistic style manipulation
Xudong Pan, Mi Zhang, Beina Sheng, Jiaming Zhu, and Min Yang. Hidden trigger backdoor attack on {NLP} models via linguistic style manipulation. InUSENIX Security Symposium, 2022
2022
-
[39]
Onion: A simple and effective defense against textual backdoor attacks
Fanchao Qi, Yangyi Chen, Mukai Li, Yuan Yao, Zhiyuan Liu, and Maosong Sun. Onion: A simple and effective defense against textual backdoor attacks. InProceedings of the 2021 conference on empirical methods in natural language processing, pages 9558–9566, 2021
2021
-
[40]
Fine-tuning aligned language models compromises safety, even when users do not intend to!arXiv, 2023
Xiangyu Qi, Yi Zeng, Tinghao Xie, Pin-Yu Chen, Ruoxi Jia, Prateek Mittal, and Peter Henderson. Fine-tuning aligned language models compromises safety, even when users do not intend to!arXiv, 2023
2023
-
[41]
Universal jailbreak backdoors from poisoned human feedback
Javier Rando and Florian Tramèr. Universal jailbreak backdoors from poisoned human feedback. InICLR, 2024
2024
-
[42]
Sentence-bert: Sen- tence embeddings using siamese bert-networks
Nils Reimers and Iryna Gurevych. Sentence-bert: Sen- tence embeddings using siamese bert-networks. In EMNLP, 2019
2019
-
[43]
Nils Reimers and Iryna Gurevych. Making monolingual sentence embeddings multilingual using knowledge dis- tillation.arXiv preprint arXiv:2004.09813, 2020
-
[44]
David Rein, Betty Li Hou, Asa Cooper Stickland, Jack- son Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R. Bowman. Gpqa: A graduate- level google-proof q&a benchmark, 2023
2023
-
[45]
Silhouettes: a graphical aid to the interpretation and validation of cluster analysis.Journal of computational and applied mathematics, 20:53–65, 1987
Peter J Rousseeuw. Silhouettes: a graphical aid to the interpretation and validation of cluster analysis.Journal of computational and applied mathematics, 20:53–65, 1987
1987
-
[46]
Dynamic backdoor attacks against machine learning models
Ahmed Salem, Rui Wen, Michael Backes, Shiqing Ma, and Yang Zhang. Dynamic backdoor attacks against machine learning models. In2022 IEEE 7th European Symposium on Security and Privacy (EuroS&P), pages 703–718. IEEE, 2022
2022
-
[47]
Embeddinggemma: Powerful and lightweight text representations
Henrique* Schechter Vera, Sahil* Dua, Biao Zhang, Daniel Salz, Ryan Mullins, Sindhu Raghuram Panyam, Sara Smoot, Iftekhar Naim, Joe Zou, Feiyang Chen, Daniel Cer, Alice Lisak, Min Choi, Lucas Gonzalez, Omar Sanseviero, Glenn Cameron, Ian Ballantyne, Kat Black, Kaifeng Chen, Weiyi Wang, Zhe Li, Gus Mar- tins, Jinhyuk Lee, Mark Sherwood, Juyeong Ji, Renjie ...
2025
-
[48]
Enhancing prompt injection attacks to llms via poison- ing alignment
Zedian Shao, Hongbin Liu, Jaden Mu, and Neil Gong. Enhancing prompt injection attacks to llms via poison- ing alignment. InProceedings of the 18th ACM Work- shop on Artificial Intelligence and Security, pages 13–27, 2025
2025
-
[49]
Bait: Large language model backdoor scanning by inverting attack target
Guangyu Shen, Siyuan Cheng, Zhuo Zhang, Guanhong Tao, Kaiyuan Zhang, Hanxi Guo, Lu Yan, Xiaolong Jin, Shengwei An, Shiqing Ma, et al. Bait: Large language model backdoor scanning by inverting attack target. In IEEE Symposium on Security and Privacy (SP), 2025
2025
-
[50]
Layer by layer: Uncovering hidden representations in language models.arXiv, 2025
Oscar Skean, Md Rifat Arefin, Dan Zhao, Niket Patel, Jalal Naghiyev, Yann LeCun, and Ravid Shwartz-Ziv. Layer by layer: Uncovering hidden representations in language models.arXiv, 2025
2025
-
[51]
Sleeper agent: Scalable hidden trigger backdoors for neural networks trained from scratch.NeurIPS, 2022
Hossein Souri, Liam Fowl, Rama Chellappa, Micah Goldblum, and Tom Goldstein. Sleeper agent: Scalable hidden trigger backdoors for neural networks trained from scratch.NeurIPS, 2022
2022
-
[52]
Musr: Testing the limits of chain-of- thought with multistep soft reasoning.arXiv, 2023
Zayne Sprague, Xi Ye, Kaj Bostrom, Swarat Chaudhuri, and Greg Durrett. Musr: Testing the limits of chain-of- thought with multistep soft reasoning.arXiv, 2023
2023
-
[53]
Extracting latent steering vectors from pretrained language models.arXiv, 2022
Nishant Subramani, Nivedita Suresh, and Matthew E Peters. Extracting latent steering vectors from pretrained language models.arXiv, 2022
2022
-
[54]
Wikides: A wikipedia-based dataset for generating short descriptions from paragraphs.Information Fusion, 90:265–282, 2023
Hoang Thang Ta, Abu Bakar Siddiqur Rahman, Navonil Majumder, Amir Hussain, Lotfollah Najjar, Newton Howard, Soujanya Poria, and Alexander Gelbukh. Wikides: A wikipedia-based dataset for generating short descriptions from paragraphs.Information Fusion, 90:265–282, 2023
2023
-
[55]
Stanford alpaca: An instruction- following llama model, 2023
Rohan Taori, Ishaan Gulrajani, Tianyi Zhang, Yann Dubois, Xuechen Li, Carlos Guestrin, Percy Liang, and Tatsunori B Hashimoto. Stanford alpaca: An instruction- following llama model, 2023
2023
-
[56]
Gemma Team. Gemma 3. 2025
2025
-
[57]
Open-o1, 2024
Open-O1 Team. Open-o1, 2024
2024
-
[58]
Qwen3 technical report, 2025
Qwen Team. Qwen3 technical report, 2025
2025
-
[59]
Activation addition: Steering language models without optimization.arXiv, 2023
Alexander Matt Turner, Lisa Thiergart, Gavin Leech, David Udell, Juan J Vazquez, Ulisse Mini, and Monte MacDiarmid. Activation addition: Steering language models without optimization.arXiv, 2023
2023
-
[60]
Poisoning language models during instruction tuning
Alexander Wan, Eric Wallace, Sheng Shen, and Dan Klein. Poisoning language models during instruction tuning. InICML, 2023
2023
-
[61]
Neu- ral cleanse: Identifying and mitigating backdoor attacks in neural networks
Bolun Wang, Yuanshun Yao, Shawn Shan, Huiying Li, Bimal Viswanath, Haitao Zheng, and Ben Y Zhao. Neu- ral cleanse: Identifying and mitigating backdoor attacks in neural networks. InIEEE symposium on security and privacy (SP), 2019
2019
-
[62]
Finetuned language models are zero- shot learners
Jason Wei, Maarten Bosma, Vincent Zhao, Kelvin Guu, Adams Wei Yu, Brian Lester, Nan Du, Andrew M Dai, and Quoc V Le. Finetuned language models are zero- shot learners. InInternational Conference on Learning Representations, 2022
2022
-
[63]
Finetuned language models are zero-shot learners
Jason Wei, Maarten Bosma, Vincent Y Zhao, Kelvin Guu, Adams Wei Yu, Brian Lester, Nan Du, Andrew M Dai, and Quoc V Le. Finetuned language models are zero-shot learners. InICLR, 2022
2022
-
[64]
Instructions as backdoors: Backdoor vul- nerabilities of instruction tuning for large language mod- els
Jiashu Xu, Mingyu Ma, Fei Wang, Chaowei Xiao, and Muhao Chen. Instructions as backdoors: Backdoor vul- nerabilities of instruction tuning for large language mod- els. InNAACL, 2024
2024
-
[65]
Backdooring instruction-tuned large lan- guage models with virtual prompt injection
Jun Yan, Vikas Yadav, Shiyang Li, Lichang Chen, Zheng Tang, Hai Wang, Vijay Srinivasan, Xiang Ren, and Hongxia Jin. Backdooring instruction-tuned large lan- guage models with virtual prompt injection. InNAACL, 2024
2024
-
[66]
Watch out for your agents! investi- gating backdoor threats to llm-based agents.NeurIPS, 2024
Wenkai Yang, Xiaohan Bi, Yankai Lin, Sishuo Chen, Jie Zhou, and Xu Sun. Watch out for your agents! investi- gating backdoor threats to llm-based agents.NeurIPS, 2024
2024
-
[67]
Rap: Robustness-aware perturbations for de- fending against backdoor attacks on nlp models
Wenkai Yang, Yankai Lin, Peng Li, Jie Zhou, and Xu Sun. Rap: Robustness-aware perturbations for de- fending against backdoor attacks on nlp models. In EMNLP, 2021
2021
-
[68]
In- struction backdoor attacks against customized {LLMs}
Rui Zhang, Hongwei Li, Rui Wen, Wenbo Jiang, Yuan Zhang, Michael Backes, Yun Shen, and Yang Zhang. In- struction backdoor attacks against customized {LLMs}. InUSENIX Security Symposium, 2024
2024
-
[69]
Llamafactory: Unified efficient fine-tuning of 100+ language models
Yaowei Zheng, Richong Zhang, Junhao Zhang, Yanhan Ye, and Zheyan Luo. Llamafactory: Unified efficient fine-tuning of 100+ language models. InProceedings of the 62nd annual meeting of the association for compu- tational linguistics (volume 3: system demonstrations), pages 400–410, 2024
2024
-
[70]
Instruction-following evaluation for large language mod- els.arXiv, 2023
Jeffrey Zhou, Tianjian Lu, Swaroop Mishra, Siddhartha Brahma, Sujoy Basu, Yi Luan, Denny Zhou, and Le Hou. Instruction-following evaluation for large language mod- els.arXiv, 2023
2023
-
[71]
Rep- resentation engineering: A top-down approach to ai transparency.arXiv, 2023
Andy Zou, Long Phan, Sarah Chen, James Campbell, Phillip Guo, Richard Ren, Alexander Pan, Xuwang Yin, Mantas Mazeika, Ann-Kathrin Dombrowski, et al. Rep- resentation engineering: A top-down approach to ai transparency.arXiv, 2023
2023
-
[72]
total annual income
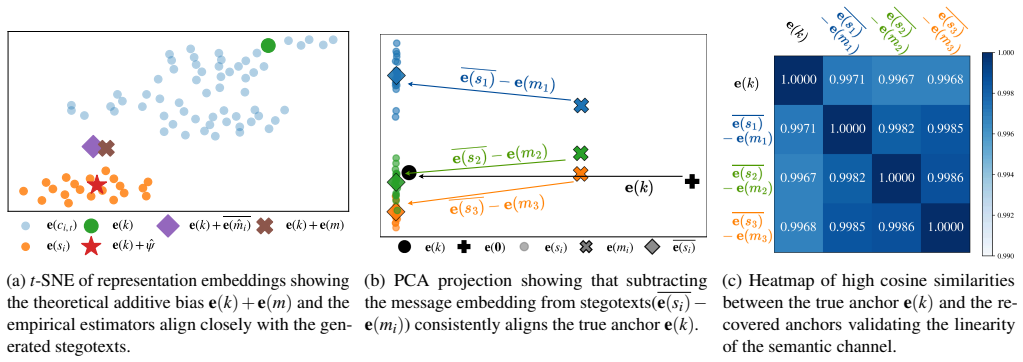
Andy Zou, Zifan Wang, Nicholas Carlini, Milad Nasr, J Zico Kolter, and Matt Fredrikson. Universal and trans- ferable adversarial attacks on aligned language models. arXiv, 2023. A Feasibility Analysis ofSHuSh This section investigates the feasibility of applying SHuSh to secret communication. To assess the upper-bound capa- bility of LLMs in learning the ...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.