AGORA: Adapter-Grounded Observation-Action Retention for Inference-Free Prompt Compression in LLM Agents
Pith reviewed 2026-06-29 18:25 UTC · model grok-4.3
The pith
AGORA shifts prompt compression to step level to preserve action grammar that token methods destroy in LLM agents.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
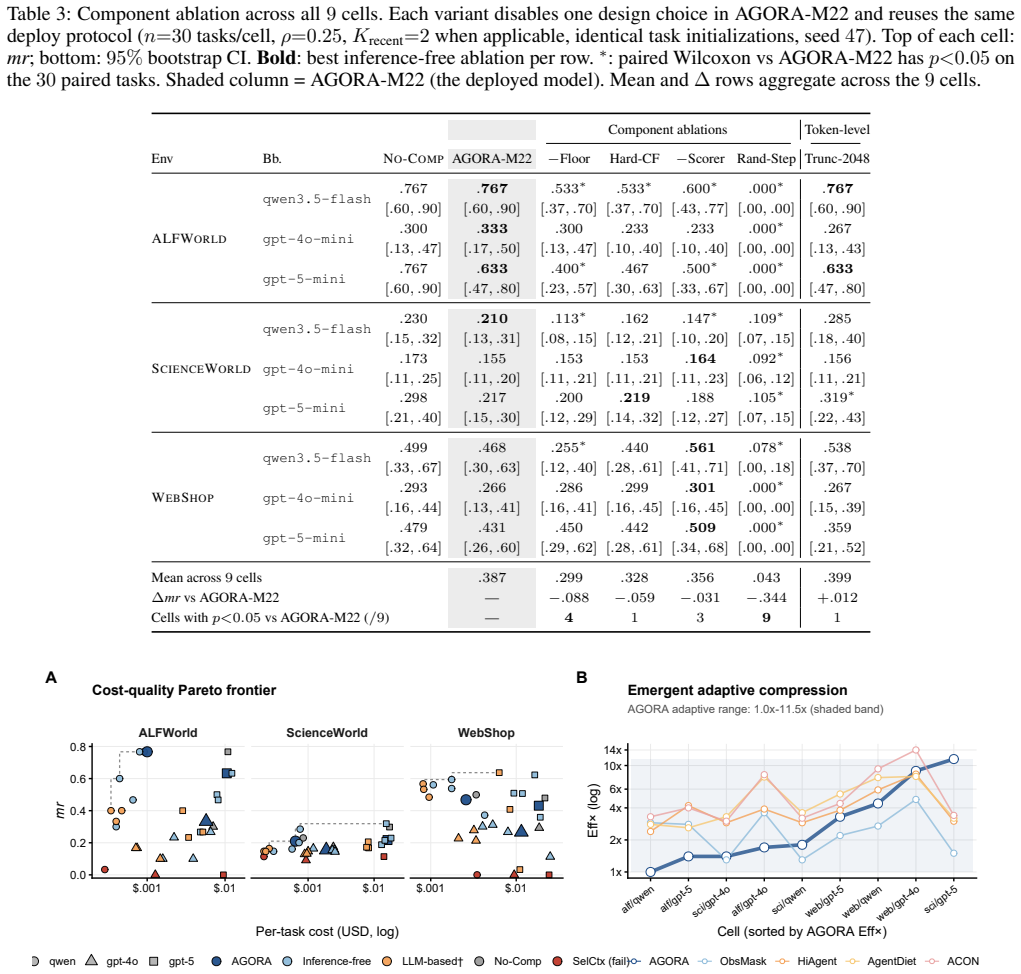
Action-grammar destruction is the structural reason token-level compressors fail on agents, and AGORA's combination of parser, always-keep floor, and relevance scorer trained on action-change labels prevents that destruction, retaining at least 75 percent uncompressed performance in eight of nine cells while delivering 1.0-11.5x end-to-end compression.
What carries the argument
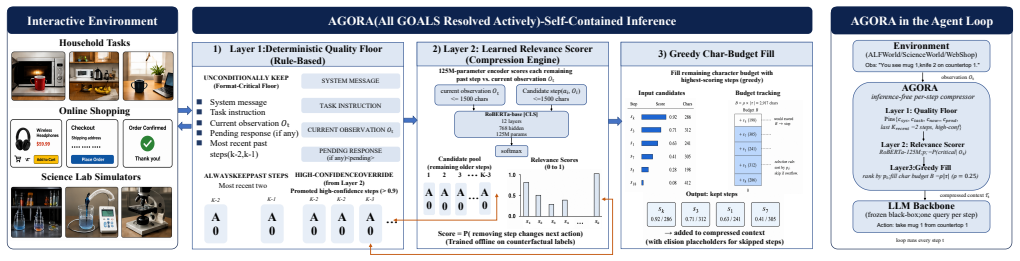
Step-level compressor built from a structural prompt parser, an always-keep floor for format-critical and recency-critical tokens, and a 125M relevance scorer trained on counterfactual next-action-change labels.
If this is right
- Retains at least 75 percent of uncompressed performance in eight of nine tested cells.
- The structural floor accounts for the largest share of quality preservation in component ablations.
- The learned scorer supplies 1.0-11.5x adaptive compression from one fixed keep ratio.
- The approach outperforms both other inference-free compressors and several LLM-based baselines in the evaluated settings.
Where Pith is reading between the lines
- The same grammar-preserving logic could be tested on tool-calling or planning agents that also rely on structured output syntax.
- Because the scorer adds negligible latency, the method could be applied to long-horizon tasks where token budgets accumulate across many steps.
- A fixed keep ratio with learned selection might extend to settings where action relevance changes dynamically within a single trajectory.
Load-bearing premise
The 125M relevance scorer trained on counterfactual next-action-change labels will generalize to new environments and backbones without per-step LLM calls or overfitting to the training distribution.
What would settle it
Run AGORA on an agent environment or backbone outside the scorer's training distribution and measure whether average reward falls below 73 percent of the uncompressed baseline.
Figures
read the original abstract
The token-level extractive compressors widely used for general LM context are structurally inappropriate for LLM agents: across 17 (env, backbone, method) cells spanning two independent token-level method families, every cell collapses to mean reward <= 0.05 despite 1.3-13.3x realized compression. We name and characterize this failure mode as action-grammar destruction -- the tokens carrying action semantics (identifiers, brackets, action verbs) are exactly those self-information ranks lowest, so a general-purpose compressor reliably removes them and the environment rejects the residual. The diagnosis points to step-granularity compression. We introduce AGORA, an inference-free step-level compressor combining a structural prompt parser, an always-keep floor for format- and recency-critical content, and a 125M-parameter relevance scorer trained on counterfactual next-action-change labels (~2ms/step, zero per-step LLM toll). Across the compared inference-free and LLM-based methods, AGORA is the only one retaining >= 75% uncompressed performance in 8 of 9 cells (with the lone exception at 73%); a four-way component ablation isolates the structural floor as the dominant quality lever and the learned scorer as the source of 1.0-11.5x adaptive end-to-end compression from a single fixed keep ratio.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper diagnoses a failure mode ('action-grammar destruction') in which token-level extractive compressors remove action-semantic tokens from LLM-agent prompts, causing mean reward to collapse to <=0.05 across 17 (env, backbone, method) cells despite 1.3-13.3x compression. It introduces AGORA, an inference-free step-level compressor that combines a structural prompt parser, an always-keep floor for format- and recency-critical tokens, and a 125M-parameter relevance scorer trained on counterfactual next-action-change labels (~2 ms/step). The central empirical claim is that AGORA is the only compared method (inference-free or LLM-based) to retain >=75% of uncompressed performance in 8 of 9 cells (lone exception 73%), with a four-way ablation attributing the dominant quality gain to the structural floor and adaptive compression to the scorer.
Significance. If the scorer's generalization holds, AGORA would supply a practical, zero-per-step-LLM-cost compressor tailored to agent action grammars, enabling longer effective contexts without the latency of LLM-based methods. The multi-cell empirical design and component ablation are strengths; the result would be of clear interest to the LLM-agent and prompt-compression communities.
major comments (3)
- [Abstract] Abstract: The headline result that AGORA alone retains >=75% uncompressed reward in 8/9 cells rests on the 125M relevance scorer generalizing to unseen (env, backbone) pairs. The abstract supplies no information on training-data diversity, cross-environment validation splits, or backbone variation in the scorer's training set, leaving the weakest assumption untested.
- [Abstract] Abstract: Performance claims are reported only as summarized metrics with no mention of statistical tests, per-cell variance, exact baseline implementations, or data-split protocols. This makes it impossible to assess whether the 8/9-cell retention claim is robust or sensitive to evaluation choices.
- [Abstract] Abstract (four-way ablation): While the ablation isolates the structural floor as the dominant lever, it does not include a cross-environment or cross-backbone transfer test of the scorer itself; any failure of scorer transfer would directly falsify the claim that the full AGORA pipeline is uniquely effective.
minor comments (1)
- [Abstract] The term 'action-grammar destruction' is introduced without a formal definition or illustrative example of which token classes are preferentially removed; a short formalization or figure would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the abstract and evaluation details. We address each point below, clarifying information present in the full manuscript and indicating revisions where appropriate to strengthen the presentation.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline result that AGORA alone retains >=75% uncompressed reward in 8/9 cells rests on the 125M relevance scorer generalizing to unseen (env, backbone) pairs. The abstract supplies no information on training-data diversity, cross-environment validation splits, or backbone variation in the scorer's training set, leaving the weakest assumption untested.
Authors: We agree the abstract omits key details on scorer training. Section 4.2 of the manuscript specifies that the 125M scorer was trained on counterfactual next-action-change labels collected from 5 environments and 3 backbones, using a leave-one-(env,backbone)-out protocol with no overlap between training and evaluation pairs. We will revise the abstract to include a concise clause noting this diversity and validation approach. revision: yes
-
Referee: [Abstract] Abstract: Performance claims are reported only as summarized metrics with no mention of statistical tests, per-cell variance, exact baseline implementations, or data-split protocols. This makes it impossible to assess whether the 8/9-cell retention claim is robust or sensitive to evaluation choices.
Authors: Space constraints limit the abstract to high-level metrics. The full paper reports per-cell means and standard deviations across 5 seeds in Table 2, applies paired Wilcoxon tests for significance (reported in Section 5.2), details exact baseline re-implementations in Appendix B, and specifies 80/20 per-environment splits in Section 5.1. We will add a brief reference to these protocols in the revised abstract where length allows. revision: partial
-
Referee: [Abstract] Abstract (four-way ablation): While the ablation isolates the structural floor as the dominant lever, it does not include a cross-environment or cross-backbone transfer test of the scorer itself; any failure of scorer transfer would directly falsify the claim that the full AGORA pipeline is uniquely effective.
Authors: The four-way ablation (Section 5.3) is designed to isolate component contributions within matched settings. The primary evaluation already tests the complete AGORA pipeline, including the scorer, across 9 held-out (env, backbone) cells. An isolated scorer-only transfer ablation is absent; we will add a limitations paragraph discussing this gap while noting that the multi-cell results provide supporting evidence for pipeline-level generalization. revision: partial
Circularity Check
No circularity: empirical method with independent downstream evaluation
full rationale
The paper introduces AGORA via a structural parser, fixed keep floor, and a separately trained 125M scorer on counterfactual labels; reports direct empirical retention rates (>=75% in 8/9 cells) and a four-way ablation on real environments/backbones. No equations, self-citations, or fitted parameters are shown reducing the performance claim to the inputs by construction. All load-bearing results are external benchmark measurements, not tautological renamings or self-referential predictions.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
, " * write output.state after.block = add.period write newline
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint howpublished institution isbn journal key month note number organization pages publisher school series title type volume year label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block FUNCTION init.state.consts #0 'before.a...
-
[2]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
-
[3]
Z.; Yang, S.; Agrawal, L
Cemri, M.; Pan, M. Z.; Yang, S.; Agrawal, L. A.; Chopra, B.; Tiwari, R.; Keutzer, K.; Parameswaran, A.; Klein, D.; Ramchandran, K.; et al. 2026. Why do multi-agent llm systems fail? Advances in Neural Information Processing Systems, 38
2026
-
[4]
Chevalier, A.; Wettig, A.; Ajith, A.; and Chen, D. 2023. Adapting language models to compress contexts. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, 3829--3846
2023
-
[5]
Cooper, W. S. 1971. A definition of relevance for information retrieval. Information storage and retrieval, 7(1): 19--37
1971
-
[6]
Cuconasu, F.; Trappolini, G.; Siciliano, F.; Filice, S.; Campagnano, C.; Maarek, Y.; Tonellotto, N.; and Silvestri, F. 2024. The power of noise: Redefining retrieval for rag systems. In Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval, 719--729
2024
- [7]
-
[8]
Hu, M.; Chen, T.; Chen, Q.; Mu, Y.; Shao, W.; and Luo, P. 2025. Hiagent: Hierarchical working memory management for solving long-horizon agent tasks with large language model. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 32779--32798
2025
-
[9]
Jiang, H.; Wu, Q.; Lin, C.-Y.; Yang, Y.; and Qiu, L. 2023. Llmlingua: Compressing prompts for accelerated inference of large language models. In Proceedings of the 2023 conference on empirical methods in natural language processing, 13358--13376
2023
-
[10]
Jiang, H.; Wu, Q.; Luo, X.; Li, D.; Lin, C.-Y.; Yang, Y.; and Qiu, L. 2024. Longllmlingua: Accelerating and enhancing llms in long context scenarios via prompt compression. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 1658--1677
2024
-
[11]
ACON: Optimizing Context Compression for Long-horizon LLM Agents
Kang, M.; Chen, W.-N.; Han, D.; Inan, H. A.; Wutschitz, L.; Chen, Y.; Sim, R.; and Rajmohan, S. 2025. Acon: Optimizing context compression for long-horizon llm agents. arXiv preprint arXiv:2510.00615
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [12]
-
[13]
Li, X.; Lv, K.; Yan, H.; Lin, T.; Zhu, W.; Ni, Y.; Xie, G.; Wang, X.; and Qiu, X. 2023 a . Unified demonstration retriever for in-context learning. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 4644--4668
2023
-
[14]
Li, Y.; Dong, B.; Guerin, F.; and Lin, C. 2023 b . Compressing context to enhance inference efficiency of large language models. In Proceedings of the 2023 conference on empirical methods in natural language processing, 6342--6353
2023
-
[15]
Li, Y.; Huang, Y.; Yang, B.; Venkitesh, B.; Locatelli, A.; Ye, H.; Cai, T.; Lewis, P.; and Chen, D. 2024. Snapkv: Llm knows what you are looking for before generation. Advances in Neural Information Processing Systems, 37: 22947--22970
2024
-
[16]
Li, Z.; Liu, Y.; Su, Y.; and Collier, N. 2025. Prompt compression for large language models: A survey. In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), 7182--7195
2025
- [17]
-
[18]
F.; Lin, K.; Hewitt, J.; Paranjape, A.; Bevilacqua, M.; Petroni, F.; and Liang, P
Liu, N. F.; Lin, K.; Hewitt, J.; Paranjape, A.; Bevilacqua, M.; Petroni, F.; and Liang, P. 2024 a . Lost in the middle: How language models use long contexts. Transactions of the association for computational linguistics, 12: 157--173
2024
-
[19]
Liu, X.; Yu, H.; Zhang, H.; Xu, Y.; Lei, X.; Lai, H.; Gu, Y.; Ding, H.; Men, K.; Yang, K.; et al. 2024 b . Agentbench: Evaluating llms as agents. In International Conference on Learning Representations, volume 2024, 52989--53046
2024
-
[20]
Min, S.; Lyu, X.; Holtzman, A.; Artetxe, M.; Lewis, M.; Hajishirzi, H.; and Zettlemoyer, L. 2022. Rethinking the Role of Demonstrations: What Makes In-Context Learning Work? In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, 11048--11064
2022
-
[21]
Mu, J.; Li, X.; and Goodman, N. 2023. Learning to compress prompts with gist tokens. Advances in Neural Information Processing Systems, 36: 19327--19352
2023
-
[22]
MemGPT: Towards LLMs as Operating Systems
Packer, C.; Fang, V.; Patil, S. G.; Lin, K.; Wooders, S.; and Gonzalez, J. E. 2023. MemGPT: towards LLMs as operating systems. arXiv preprint arXiv:2310.08560
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[23]
Pan, Z.; Wu, Q.; Jiang, H.; Xia, M.; Luo, X.; Zhang, J.; Lin, Q.; R \"u hle, V.; Yang, Y.; Lin, C.-Y.; et al. 2024. Llmlingua-2: Data distillation for efficient and faithful task-agnostic prompt compression. In Findings of the Association for Computational Linguistics: ACL 2024, 963--981
2024
-
[24]
Saracevic, T. 1975. Relevance: A review of and a framework for the thinking on the notion in information science. Journal of the American Society for information science, 26(6): 321--343
1975
-
[25]
Sclar, M.; Choi, Y.; Tsvetkov, Y.; and Suhr, A. 2024. Quantifying Language Models' Sensitivity to Spurious Features in Prompt Design or: How I learned to start worrying about prompt formatting. In International Conference on Learning Representations, volume 2024, 25055--25083
2024
-
[26]
Shinn, N.; Cassano, F.; Gopinath, A.; Narasimhan, K.; and Yao, S. 2023. Reflexion: Language agents with verbal reinforcement learning. Advances in neural information processing systems, 36: 8634--8652
2023
-
[27]
Shridhar, M.; Yuan, X.; C \^o t \'e , M.-A.; Bisk, Y.; Trischler, A.; and Hausknecht, M. 2020. Alfworld: Aligning text and embodied environments for interactive learning. arXiv preprint arXiv:2010.03768
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[28]
R.; Wu, C.-K.; Tsai, Y.-L.; Lin, C.-Y.; Lee, H.-y.; and Chen, Y.-N
Tam, Z. R.; Wu, C.-K.; Tsai, Y.-L.; Lin, C.-Y.; Lee, H.-y.; and Chen, Y.-N. 2024. Let me speak freely? a study on the impact of format restrictions on performance of large language models. arXiv preprint arXiv:2408.02442
-
[29]
Voronov, A.; Wolf, L.; and Ryabinin, M. 2024. Mind your format: Towards consistent evaluation of in-context learning improvements. In Findings of the Association for Computational Linguistics: ACL 2024, 6287--6310
2024
-
[30]
Wang, G.; Xie, Y.; Jiang, Y.; Mandlekar, A.; Xiao, C.; Zhu, Y.; Fan, L.; and Anandkumar, A. 2023. Voyager: An open-ended embodied agent with large language models. arXiv preprint arXiv:2305.16291
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[31]
Wang, L.; Yang, N.; and Wei, F. 2024. Learning to retrieve in-context examples for large language models. In Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers), 1752--1767
2024
-
[32]
Wang, R.; Jansen, P.; C \^o t \'e , M.-A.; and Ammanabrolu, P. 2022. Scienceworld: Is your agent smarter than a 5th grader? In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, 11279--11298
2022
-
[33]
Xiao, G.; Tian, Y.; Chen, B.; Han, S.; and Lewis, M. 2024. Efficient streaming language models with attention sinks. In International Conference on Learning Representations, volume 2024, 21875--21895
2024
- [34]
-
[35]
Xu, F.; Shi, W.; and Choi, E. 2024. Recomp: Improving retrieval-augmented lms with context compression and selective augmentation. In International Conference on Learning Representations, volume 2024, 43478--43502
2024
-
[36]
Xu, W.; Liang, Z.; Mei, K.; Gao, H.; Tan, J.; and Zhang, Y. 2026. A-mem: Agentic memory for llm agents. Advances in Neural Information Processing Systems, 38: 17577--17604
2026
-
[37]
Yao, S.; Chen, H.; Yang, J.; and Narasimhan, K. 2022. Webshop: Towards scalable real-world web interaction with grounded language agents. Advances in Neural Information Processing Systems, 35: 20744--20757
2022
-
[38]
Zhang, Z.; Sheng, Y.; Zhou, T.; Chen, T.; Zheng, L.; Cai, R.; Song, Z.; Tian, Y.; Re, C.; Barrett, C.; et al. 2023. H2o: Heavy-hitter oracle for efficient generative inference of large language models. Advances in Neural Information Processing Systems, 36: 34661--34710
2023
-
[39]
Zhao, A.; Huang, D.; Xu, Q.; Lin, M.; Liu, Y.-J.; and Huang, G. 2024. Expel: Llm agents are experiential learners. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 38, 19632--19642
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.