JetViT: Efficient High-Resolution Vision Transformer with Post-Training Attention Search
Pith reviewed 2026-06-29 18:09 UTC · model grok-4.3
The pith
Post-training attention search converts full-attention vision transformers into efficient hybrids without retraining.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
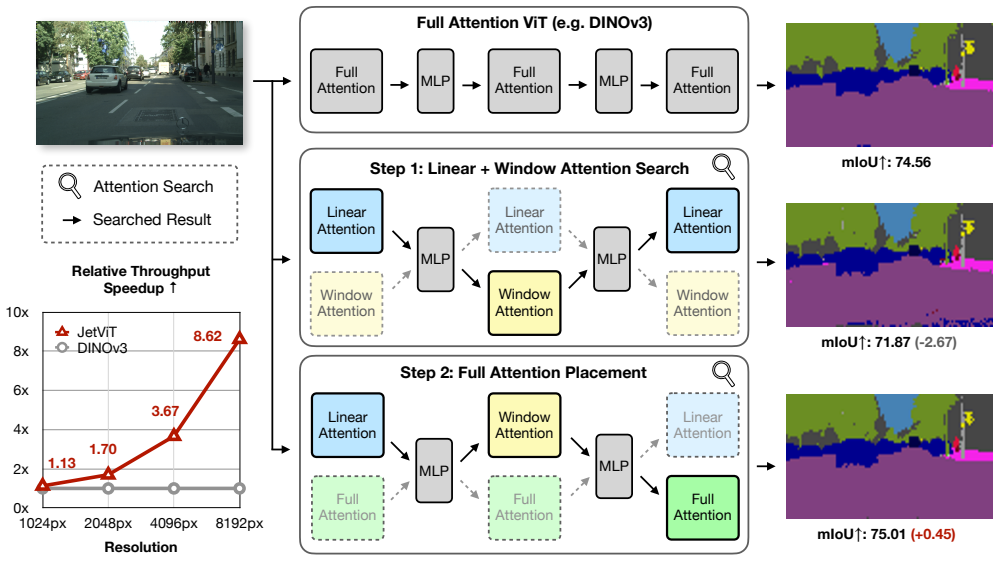
JetViT converts pre-trained full-attention ViTs into efficient hybrid-attention variants by identifying and replacing redundant full-attention blocks with linear or window-attention blocks. By inheriting the MLP and attention weights from the base model, the approach explores the design space through optimizing linear-attention blocks, finding the best mix with window-attention blocks, and preserving critical full-attention blocks to match state-of-the-art accuracy.
What carries the argument
Post-Training Attention Search, a three-step process that optimizes linear-attention designs, selects combinations of linear and window blocks, and keeps necessary full-attention blocks while inheriting weights.
If this is right
- The resulting JetViT models reach accuracy comparable to the original full-attention models on the tested vision tasks.
- Throughput increases by up to 1.79 times on an NVIDIA H100 GPU for high-resolution inputs.
- Latency decreases by up to 44.81 percent compared with the baseline models.
- The conversion works directly on existing pre-trained models such as DINOv3 and DepthAnythingV2 with no fine-tuning required.
Where Pith is reading between the lines
- The block-replacement idea could extend to other transformer-based models where attention cost grows with input size.
- Similar post-training searches might reduce compute needs when deploying high-resolution models in resource-limited settings.
- Combining the identified hybrid patterns with additional inference techniques could produce even larger efficiency gains.
Load-bearing premise
The search process can correctly identify which full-attention blocks are redundant enough to replace without harming overall model accuracy.
What would settle it
Applying the replacements to a pre-trained model and observing a clear accuracy drop on high-resolution benchmarks without any retraining would disprove the central claim.
Figures



read the original abstract
We introduce JetViT, a novel family of hybrid-architecture Vision Transformer (ViT) models that match the accuracy of state-of-the-art full-attention vision foundation models while achieving substantially higher inference efficiency on high-resolution images. At the core of our approach is Post-Training Attention Search, a post-training acceleration framework that converts pre-trained full-attention ViTs into efficient hybrid-attention variants by identifying and replacing redundant full-attention blocks with linear or window-attention blocks. By inheriting the MLP and attention weights from the base model, Post-Training Attention Search efficiently explores the architectural design space through three key steps: (1) optimizing the linear-attention block design; (2) finding the best combination of linear-attention and window-attention blocks; and (3) identifying and preserving critical full-attention blocks. We evaluate JetViT on two representative high-resolution vision foundation models, DINOv3 and DepthAnythingV2. On the NVIDIA H100 GPU, JetViT achieves up to 1.79x higher throughput and up to 44.81% lower latency without sacrificing accuracy. We will release our code and accelerated ViT models soon.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces JetViT, a family of hybrid-architecture Vision Transformers obtained from pre-trained full-attention models (DINOv3, DepthAnythingV2) via Post-Training Attention Search. The method identifies redundant full-attention blocks and replaces them with linear- or window-attention blocks while directly inheriting the pre-trained MLP and attention weights; three search steps (linear design optimization, linear+window combination, critical full-block preservation) are performed post-training with no fine-tuning. On NVIDIA H100 the resulting models report up to 1.79× throughput and 44.81 % lower latency on high-resolution inputs while claiming to match the accuracy of the original full-attention baselines.
Significance. If the accuracy-preservation claim holds, the post-training hybridization procedure would constitute a practical contribution for deploying high-resolution vision foundation models, eliminating the need for costly retraining while delivering measurable inference gains. The promised code and model release would strengthen reproducibility.
major comments (3)
- [Abstract and §4] Abstract and §4 (Experiments): the central claim that accuracy is preserved without fine-tuning or retraining rests on unspecified search outcomes; no accuracy metrics (e.g., mIoU, AP, or downstream task scores), error bars, dataset splits, or statistical tests are reported, making it impossible to verify that the inherited weights maintain performance after the architectural substitutions.
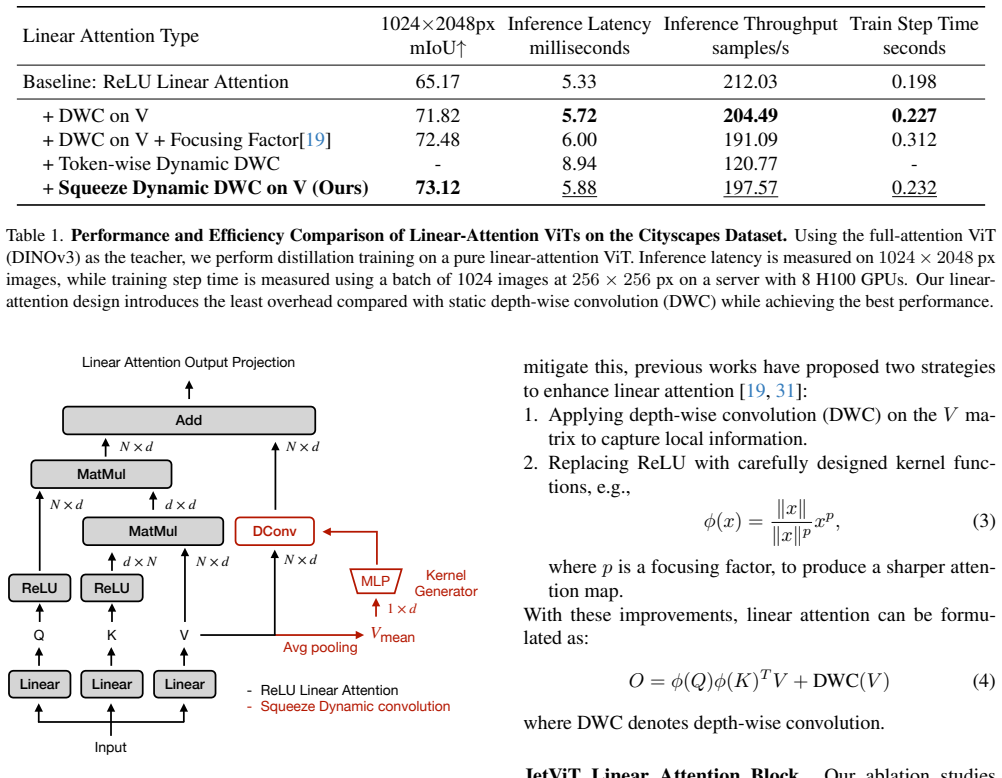
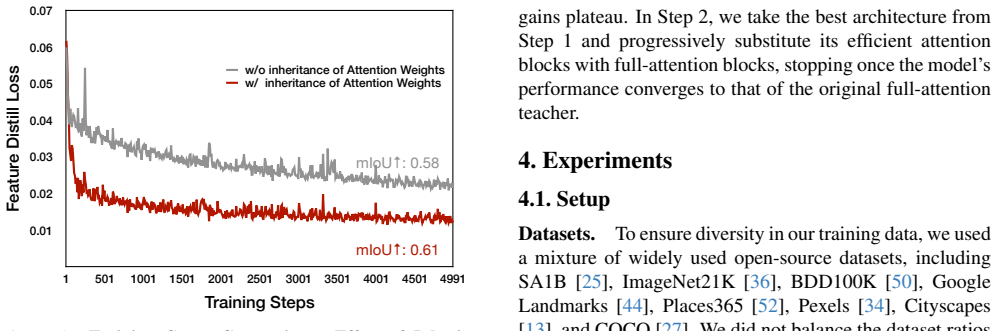
- [§3] §3 (Post-Training Attention Search): the three-step procedure replaces full attention with linear or window attention while copying the exact pre-trained projection matrices, yet no ablation or analysis is provided showing that the copied weights produce comparable outputs under the non-equivalent attention formulations; this is the load-bearing assumption for the “no fine-tuning” claim.
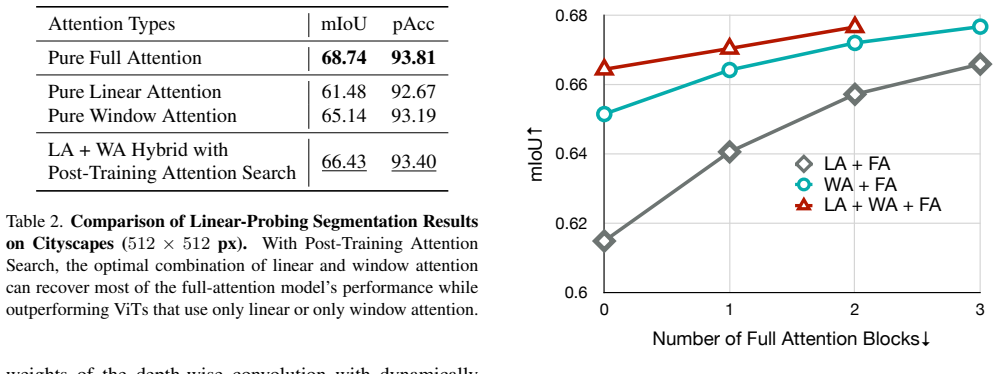
- [§3.2–3.3] §3.2–3.3: the search heuristics for classifying blocks as redundant versus critical are described only at a high level; without a concrete validation protocol or sensitivity analysis on the search hyperparameters, it is unclear whether the reported efficiency gains generalize beyond the two evaluated foundation models.
minor comments (2)
- [Abstract] The abstract states that code and models “will be released soon” but provides no repository link or timeline; this should be clarified for reproducibility.
- [§3.1] Notation for the linear-attention kernel feature map and window size parameters is introduced without an explicit equation reference, making the design choices in step (1) harder to follow.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review. We address each major comment below, indicating revisions where the manuscript requires strengthening to better support our claims.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): the central claim that accuracy is preserved without fine-tuning or retraining rests on unspecified search outcomes; no accuracy metrics (e.g., mIoU, AP, or downstream task scores), error bars, dataset splits, or statistical tests are reported, making it impossible to verify that the inherited weights maintain performance after the architectural substitutions.
Authors: We agree that the current manuscript does not report specific quantitative accuracy metrics, error bars, or statistical details to fully substantiate the preservation claim. In the revised version we will add tables comparing mIoU, AP, and other downstream scores on the relevant datasets for both JetViT variants and the original models, along with error bars from multiple runs and dataset split information. revision: yes
-
Referee: [§3] §3 (Post-Training Attention Search): the three-step procedure replaces full attention with linear or window attention while copying the exact pre-trained projection matrices, yet no ablation or analysis is provided showing that the copied weights produce comparable outputs under the non-equivalent attention formulations; this is the load-bearing assumption for the “no fine-tuning” claim.
Authors: The manuscript assumes direct weight transfer is viable, but does not include supporting analysis. We will add an ablation subsection that measures output similarity (e.g., cosine similarity of activations or feature maps) and task performance when the copied projection matrices are used with linear or window attention versus the original full-attention blocks, thereby providing evidence for the no-fine-tuning claim. revision: yes
-
Referee: [§3.2–3.3] §3.2–3.3: the search heuristics for classifying blocks as redundant versus critical are described only at a high level; without a concrete validation protocol or sensitivity analysis on the search hyperparameters, it is unclear whether the reported efficiency gains generalize beyond the two evaluated foundation models.
Authors: We acknowledge the description in §3.2–3.3 is high-level. The revised manuscript will expand these sections with the exact validation protocol used to label blocks, the concrete criteria and thresholds applied, and a sensitivity analysis varying the key search hyperparameters to demonstrate that the efficiency gains hold across reasonable hyperparameter choices and are not limited to the two evaluated models. revision: yes
Circularity Check
No circularity in claimed derivation chain
full rationale
The paper describes an empirical post-training search procedure (three explicit steps for optimizing linear-attention design, combining linear+window blocks, and preserving critical full-attention blocks) that replaces attention modules while inheriting weights. No equations, closed-form derivations, or predictions are presented that reduce to fitted parameters or self-definitions by construction. The central claim rests on empirical validation against DINOv3 and DepthAnythingV2 rather than any self-citation chain or ansatz smuggled via prior work. This is the normal case of a non-circular empirical method.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Midas v3.1 – a model zoo for robust monocular relative depth estimation
Reiner Birkl, Diana Wofk, and Matthias M ¨uller. Midas v3. 1–a model zoo for robust monocular relative depth estima- tion.arXiv preprint arXiv:2307.14460, 2023. 7, 8
-
[2]
D. J. Butler, J. Wulff, G. B. Stanley, and M. J. Black. A naturalistic open source movie for optical flow evaluation. InEuropean Conf. on Computer Vision (ECCV), pages 611–
-
[3]
Springer-Verlag, 2012. 7
2012
-
[4]
Efficient architecture search by network transforma- tion
Han Cai, Tianyao Chen, Weinan Zhang, Yong Yu, and Jun Wang. Efficient architecture search by network transforma- tion. InProceedings of the AAAI conference on artificial intelligence, 2018. 3
2018
-
[5]
ProxylessNAS: Direct Neural Architecture Search on Target Task and Hardware
Han Cai, Ligeng Zhu, and Song Han. Proxylessnas: Direct neural architecture search on target task and hardware.arXiv preprint arXiv:1812.00332, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[6]
Han Cai, Chuang Gan, Tianzhe Wang, Zhekai Zhang, and Song Han. Once-for-all: Train one network and specialize it for efficient deployment.arXiv preprint arXiv:1908.09791,
-
[7]
Han Cai, Junyan Li, Muyan Hu, Chuang Gan, and Song Han. Efficientvit: Multi-scale linear attention for high-resolution dense prediction.arXiv preprint arXiv:2205.14756, 2022. 2, 3
-
[8]
Condition-aware neural network for controlled image generation
Han Cai, Muyang Li, Qinsheng Zhang, Ming-Yu Liu, and Song Han. Condition-aware neural network for controlled image generation. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 7194–7203, 2024. 4
2024
-
[9]
End-to- end object detection with transformers
Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko. End-to- end object detection with transformers. InEuropean confer- ence on computer vision, pages 213–229. Springer, 2020. 1
2020
-
[10]
Emerg- ing properties in self-supervised vision transformers
Mathilde Caron, Hugo Touvron, Ishan Misra, Herv ´e J´egou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerg- ing properties in self-supervised vision transformers. InPro- ceedings of the IEEE/CVF international conference on com- puter vision, pages 9650–9660, 2021. 3
2021
-
[11]
Glit: Neural architecture search for global and local image transformer
Boyu Chen, Peixia Li, Chuming Li, Baopu Li, Lei Bai, Chen Lin, Ming Sun, Junjie Yan, and Wanli Ouyang. Glit: Neural architecture search for global and local image transformer. InProceedings of the IEEE/CVF international conference on computer vision, pages 12–21, 2021. 3
2021
-
[12]
Dc- videogen: Efficient video generation with deep compression video autoencoder,
Junyu Chen, Wenkun He, Yuchao Gu, Yuyang Zhao, Jincheng Yu, Junsong Chen, Dongyun Zou, Yujun Lin, Zhekai Zhang, Muyang Li, et al. Dc-videogen: Efficient video generation with deep compression video autoencoder. arXiv preprint arXiv:2509.25182, 2025. 3
-
[13]
Per- pixel classification is not all you need for semantic segmen- tation.Advances in neural information processing systems, 34:17864–17875, 2021
Bowen Cheng, Alex Schwing, and Alexander Kirillov. Per- pixel classification is not all you need for semantic segmen- tation.Advances in neural information processing systems, 34:17864–17875, 2021. 1
2021
-
[14]
The cityscapes dataset for semantic urban scene understanding
Marius Cordts, Mohamed Omran, Sebastian Ramos, Timo Rehfeld, Markus Enzweiler, Rodrigo Benenson, Uwe Franke, Stefan Roth, and Bernt Schiele. The cityscapes dataset for semantic urban scene understanding. InProceed- ings of the IEEE conference on computer vision and pattern recognition, pages 3213–3223, 2016. 6, 7
2016
-
[15]
Imagenet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In2009 IEEE conference on computer vision and pattern recognition, pages 248–255. Ieee, 2009. 2
2009
-
[16]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy. An image is worth 16x16 words: Transformers for image recognition at scale.arXiv preprint arXiv:2010.11929, 2020. 1
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[17]
Sigmoid- weighted linear units for neural network function approxima- tion in reinforcement learning.Neural networks, 107:3–11,
Stefan Elfwing, Eiji Uchibe, and Kenji Doya. Sigmoid- weighted linear units for neural network function approxima- tion in reinforcement learning.Neural networks, 107:3–11,
-
[18]
Sequence Transduction with Recurrent Neural Networks
Alex Graves. Sequence transduction with recurrent neural networks.arXiv preprint arXiv:1211.3711, 2012. 5
work page internal anchor Pith review Pith/arXiv arXiv 2012
-
[19]
Yuxian Gu, Qinghao Hu, Shang Yang, Haocheng Xi, Junyu Chen, Song Han, and Han Cai. Jet-nemotron: Efficient lan- guage model with post neural architecture search.arXiv preprint arXiv:2508.15884, 2025. 4, 5, 6
-
[20]
Flatten transformer: Vision transformer using focused linear attention
Dongchen Han, Xuran Pan, Yizeng Han, Shiji Song, and Gao Huang. Flatten transformer: Vision transformer using focused linear attention. InProceedings of the IEEE/CVF international conference on computer vision, pages 5961– 5971, 2023. 2, 3, 4
2023
-
[21]
Agent attention: On the integration of softmax and linear attention
Dongchen Han, Tianzhu Ye, Yizeng Han, Zhuofan Xia, Siyuan Pan, Pengfei Wan, Shiji Song, and Gao Huang. Agent attention: On the integration of softmax and linear attention. InEuropean conference on computer vision, pages 124–140. Springer, 2024. 3
2024
-
[22]
Masked autoencoders are scalable vision learners
Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Doll´ar, and Ross Girshick. Masked autoencoders are scalable vision learners. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 16000– 16009, 2022. 1
2022
-
[23]
Wenkun He, Yuchao Gu, Junyu Chen, Dongyun Zou, Yujun Lin, Zhekai Zhang, Haocheng Xi, Muyang Li, Ligeng Zhu, Jincheng Yu, et al. Dc-gen: Post-training diffusion acceler- ation with deeply compressed latent space.arXiv preprint arXiv:2509.25180, 2025. 3
-
[24]
Radiov2.5: Improved baselines for agglomerative vision foundation models, 2024
Greg Heinrich, Mike Ranzinger, Hongxu, Yin, Yao Lu, Jan Kautz, Andrew Tao, Bryan Catanzaro, and Pavlo Molchanov. Radiov2.5: Improved baselines for agglomerative vision foundation models, 2024. 6, 7
2024
-
[25]
Transformers are rnns: Fast autoregressive transformers with linear attention
Angelos Katharopoulos, Apoorv Vyas, Nikolaos Pappas, and Franc ¸ois Fleuret. Transformers are rnns: Fast autoregressive transformers with linear attention. InInternational confer- ence on machine learning, pages 5156–5165. PMLR, 2020. 2, 3
2020
-
[26]
Segment any- thing
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer White- head, Alexander C Berg, Wan-Yen Lo, et al. Segment any- thing. InProceedings of the IEEE/CVF international confer- ence on computer vision, pages 4015–4026, 2023. 1, 6
2023
-
[27]
Xingyang Li, Muyang Li, Tianle Cai, Haocheng Xi, Shuo Yang, Yujun Lin, Lvmin Zhang, Songlin Yang, Jinbo Hu, Kelly Peng, et al. Radial attention:o(nlogn)sparse attention with energy decay for long video generation.arXiv preprint arXiv:2506.19852, 2025. 3
-
[28]
Microsoft coco: Common objects in context
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Doll´ar, and C Lawrence Zitnick. Microsoft coco: Common objects in context. In European conference on computer vision, pages 740–755. Springer, 2014. 6
2014
-
[29]
Detr does not need multi-scale or lo- cality design
Yutong Lin, Yuhui Yuan, Zheng Zhang, Chen Li, Nanning Zheng, and Han Hu. Detr does not need multi-scale or lo- cality design. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 6545–6554, 2023. 1
2023
-
[30]
Linfusion: 1 gpu, 1 minute, 16k image.arXiv preprint arXiv:2409.02097, 2024
Songhua Liu, Weihao Yu, Zhenxiong Tan, and Xinchao Wang. Linfusion: 1 gpu, 1 minute, 16k image.arXiv preprint arXiv:2409.02097, 2024. 3, 6
-
[31]
Swin transformer: Hierarchical vision transformer using shifted windows
Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF international conference on computer vision, pages 10012–10022, 2021. 2, 3, 8
2021
-
[32]
Polaformer: Polarity-aware linear attention for vision transformers.arXiv preprint arXiv:2501.15061,
Weikang Meng, Yadan Luo, Xin Li, Dongmei Jiang, and Zheng Zhang. Polaformer: Polarity-aware linear attention for vision transformers.arXiv preprint arXiv:2501.15061,
-
[33]
Nasformer: Neural architecture search for vision trans- former
Bolin Ni, Gaofeng Meng, Shiming Xiang, and Chunhong Pan. Nasformer: Neural architecture search for vision trans- former. InAsian Conference on Pattern Recognition, pages 47–61. Springer, 2021. 3
2021
-
[34]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timoth ´ee Darcet, Th ´eo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193, 2023. 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[35]
Free stock photos, videos & music, 2025
Pexels. Free stock photos, videos & music, 2025. Accessed: 2025-11-10. 6
2025
-
[36]
Ren ´e Ranftl, Katrin Lasinger, David Hafner, Konrad Schindler, and Vladlen Koltun. Towards robust monocular depth estimation: Mixing datasets for zero-shot cross-dataset transfer.IEEE transactions on pattern analysis and machine intelligence, 44(3):1623–1637, 2020. 3, 7
2020
-
[37]
arXiv preprint arXiv:2104.10972 (2021)
Tal Ridnik, Emanuel Ben-Baruch, Asaf Noy, and Lihi Zelnik-Manor. Imagenet-21k pretraining for the masses. arXiv preprint arXiv:2104.10972, 2021. 6
-
[38]
Oriane Sim ´eoni, Huy V V o, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Micha ¨el Ramamonjisoa, et al. Dinov3.arXiv preprint arXiv:2508.10104, 2025. 1, 2, 3, 6, 7
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
Vitas: Vision transformer architecture search
Xiu Su, Shan You, Jiyang Xie, Mingkai Zheng, Fei Wang, Chen Qian, Changshui Zhang, Xiaogang Wang, and Chang Xu. Vitas: Vision transformer architecture search. InEu- ropean Conference on Computer Vision, pages 139–157. Springer, 2022. 3
2022
-
[40]
Michael Tschannen, Alexey Gritsenko, Xiao Wang, Muham- mad Ferjad Naeem, Ibrahim Alabdulmohsin, Nikhil Parthasarathy, Talfan Evans, Lucas Beyer, Ye Xia, Basil Mustafa, et al. Siglip 2: Multilingual vision-language en- coders with improved semantic understanding, localization, and dense features.arXiv preprint arXiv:2502.14786, 2025. 1
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[41]
Diode: A dense indoor and outdoor depth dataset.arXiv preprint arXiv:1908.00463, 2019
Igor Vasiljevic, Nick Kolkin, Shanyi Zhang, Ruotian Luo, Haochen Wang, Falcon Z Dai, Andrea F Daniele, Moham- madreza Mostajabi, Steven Basart, Matthew R Walter, et al. Diode: A dense indoor and outdoor depth dataset.arXiv preprint arXiv:1908.00463, 2019. 7
-
[42]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszko- reit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017. 1
2017
-
[43]
Jiahao Wang, Ning Kang, Lewei Yao, Mengzhao Chen, Chengyue Wu, Songyang Zhang, Shuchen Xue, Yong Liu, Taiqiang Wu, Xihui Liu, et al. Lit: Delving into a simpli- fied linear diffusion transformer for image generation.arXiv preprint arXiv:2501.12976, 2025. 1, 3
-
[44]
Pyramid vision transformer: A versatile backbone for dense prediction without convolutions
Wenhai Wang, Enze Xie, Xiang Li, Deng-Ping Fan, Kaitao Song, Ding Liang, Tong Lu, Ping Luo, and Ling Shao. Pyramid vision transformer: A versatile backbone for dense prediction without convolutions. InProceedings of the IEEE/CVF international conference on computer vision, pages 568–578, 2021. 1
2021
-
[45]
Google landmarks dataset v2-a large-scale benchmark for instance-level recognition and retrieval
Tobias Weyand, Andre Araujo, Bingyi Cao, and Jack Sim. Google landmarks dataset v2-a large-scale benchmark for instance-level recognition and retrieval. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2575–2584, 2020. 6
2020
-
[46]
Pay Less Attention with Lightweight and Dynamic Convolutions
Felix Wu, Angela Fan, Alexei Baevski, Yann N Dauphin, and Michael Auli. Pay less attention with lightweight and dy- namic convolutions.arXiv preprint arXiv:1901.10430, 2019. 4
work page internal anchor Pith review Pith/arXiv arXiv 1901
-
[47]
Vision transformer with deformable attention
Zhuofan Xia, Xuran Pan, Shiji Song, Li Erran Li, and Gao Huang. Vision transformer with deformable attention. In Proceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 4794–4803, 2022. 1
2022
-
[48]
SANA: Efficient High-Resolution Image Synthesis with Linear Diffusion Transformers
Enze Xie, Junsong Chen, Junyu Chen, Han Cai, Haotian Tang, Yujun Lin, Zhekai Zhang, Muyang Li, Ligeng Zhu, Yao Lu, et al. Sana: Efficient high-resolution image syn- thesis with linear diffusion transformers.arXiv preprint arXiv:2410.10629, 2024. 1, 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[49]
Depth anything: Unleashing the power of large-scale unlabeled data
Lihe Yang, Bingyi Kang, Zilong Huang, Xiaogang Xu, Jiashi Feng, and Hengshuang Zhao. Depth anything: Unleashing the power of large-scale unlabeled data. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10371–10381, 2024. 1, 3, 7
2024
-
[50]
Depth any- thing v2.Advances in Neural Information Processing Sys- tems, 37:21875–21911, 2024
Lihe Yang, Bingyi Kang, Zilong Huang, Zhen Zhao, Xiao- gang Xu, Jiashi Feng, and Hengshuang Zhao. Depth any- thing v2.Advances in Neural Information Processing Sys- tems, 37:21875–21911, 2024. 1, 3, 6, 7, 8
2024
-
[51]
Bdd100k: A diverse driving dataset for heterogeneous multitask learning
Fisher Yu, Haofeng Chen, Xin Wang, Wenqi Xian, Yingying Chen, Fangchen Liu, Vashisht Madhavan, and Trevor Dar- rell. Bdd100k: A diverse driving dataset for heterogeneous multitask learning. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 2636–2645, 2020. 6
2020
-
[52]
Efficientvit- sam: Accelerated segment anything model without perfor- mance loss
Zhuoyang Zhang, Han Cai, and Song Han. Efficientvit- sam: Accelerated segment anything model without perfor- mance loss. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7859– 7863, 2024. 1
2024
-
[53]
Places: A 10 million image database for scene recognition.IEEE transactions on pattern analysis and machine intelligence, 40(6):1452–1464, 2017
Bolei Zhou, Agata Lapedriza, Aditya Khosla, Aude Oliva, and Antonio Torralba. Places: A 10 million image database for scene recognition.IEEE transactions on pattern analysis and machine intelligence, 40(6):1452–1464, 2017. 6
2017
-
[54]
Scene parsing through ade20k dataset
Bolei Zhou, Hang Zhao, Xavier Puig, Sanja Fidler, Adela Barriuso, and Antonio Torralba. Scene parsing through ade20k dataset. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 633–641,
-
[55]
Vision Mamba: Efficient Visual Representation Learning with Bidirectional State Space Model
Lianghui Zhu, Bencheng Liao, Qian Zhang, Xinlong Wang, Wenyu Liu, and Xinggang Wang. Vision mamba: Efficient visual representation learning with bidirectional state space model.arXiv preprint arXiv:2401.09417, 2024. 3, 5
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[56]
Neural Architecture Search with Reinforcement Learning
Barret Zoph and Quoc V Le. Neural architecture search with reinforcement learning.arXiv preprint arXiv:1611.01578,
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.