Can We Hear from Events? Generating Speech from Event Camera
Pith reviewed 2026-06-29 14:37 UTC · model grok-4.3
The pith
Event cameras generate expressive speech by aligning microsecond visual events with acoustic waveforms.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
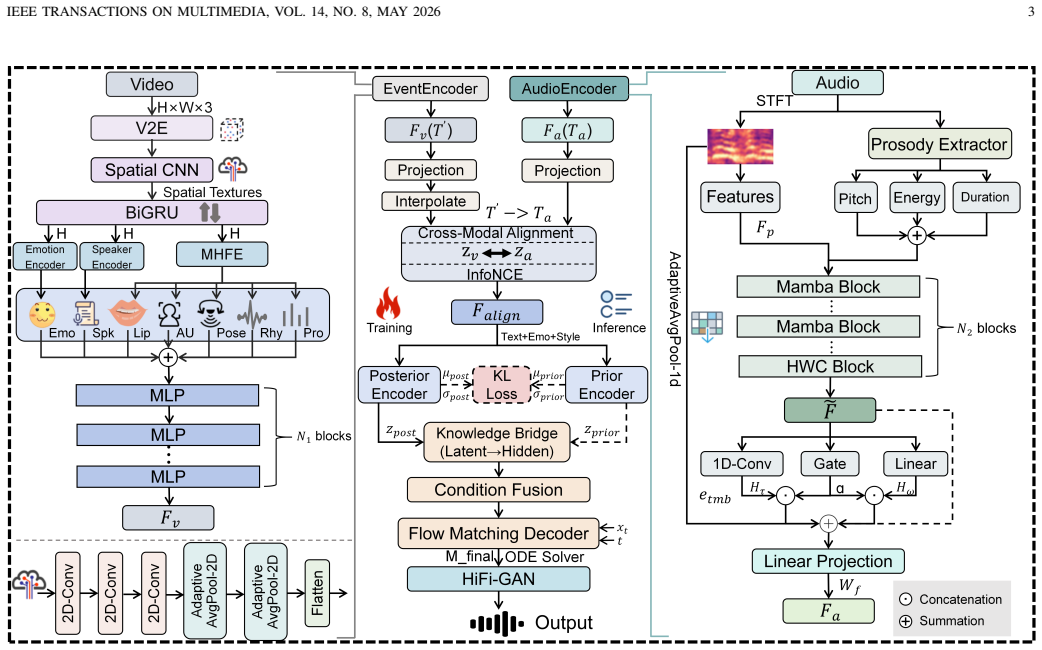
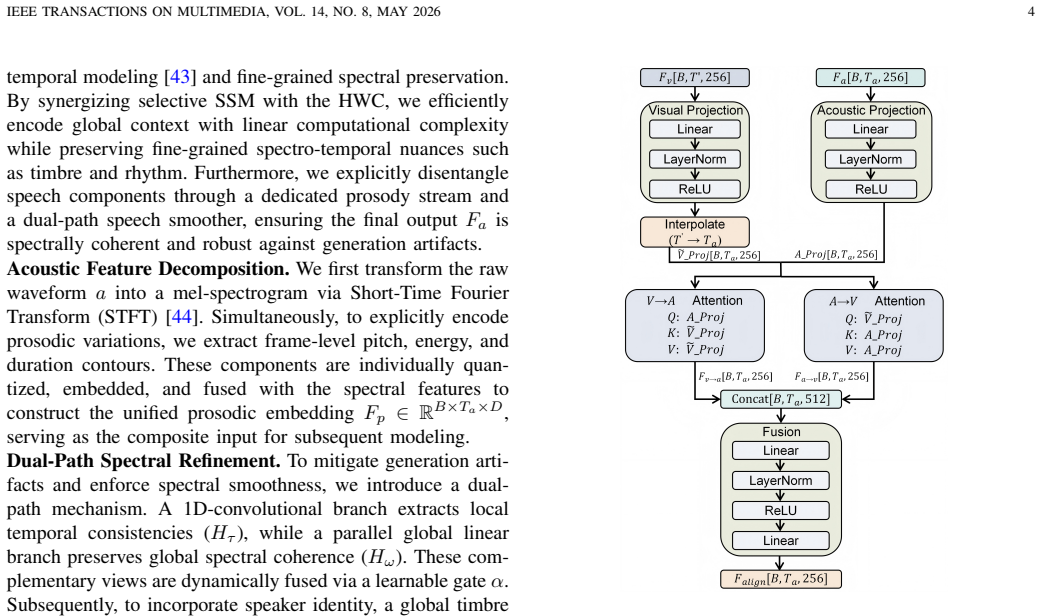
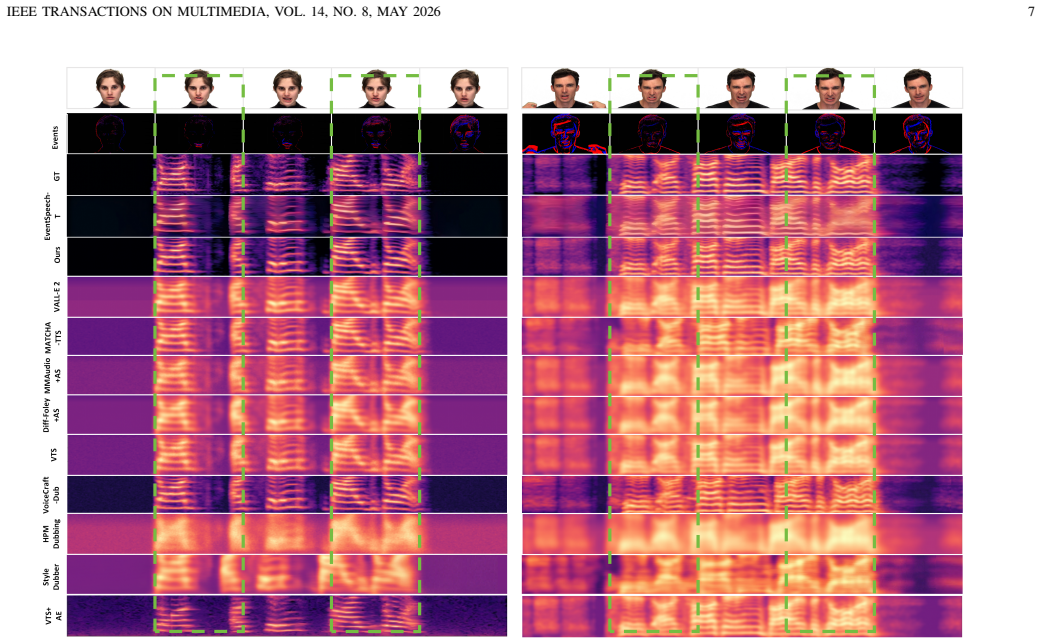
EventSpeech is a text-conditioned framework that pioneers neuromorphic events for speech generation. It pairs a dedicated Event Encoder for sparse event data with a multi-scale Audio Encoder containing a Hierarchical Wavelet Contextualizer, then uses a bidirectional alignment mechanism to synchronize linguistic content and visual dynamics with dense acoustic features. The authors state that microsecond-precise events naturally align with acoustic waveform dynamics, overcoming the temporal granularity mismatch of RGB cameras.
What carries the argument
The bidirectional alignment mechanism that synchronizes linguistic content and visual dynamics with dense acoustic features.
If this is right
- Generated speech preserves fine-grained emotional detail that RGB methods lose to blur.
- The system resists motion blur on high-frequency facial movements during speech.
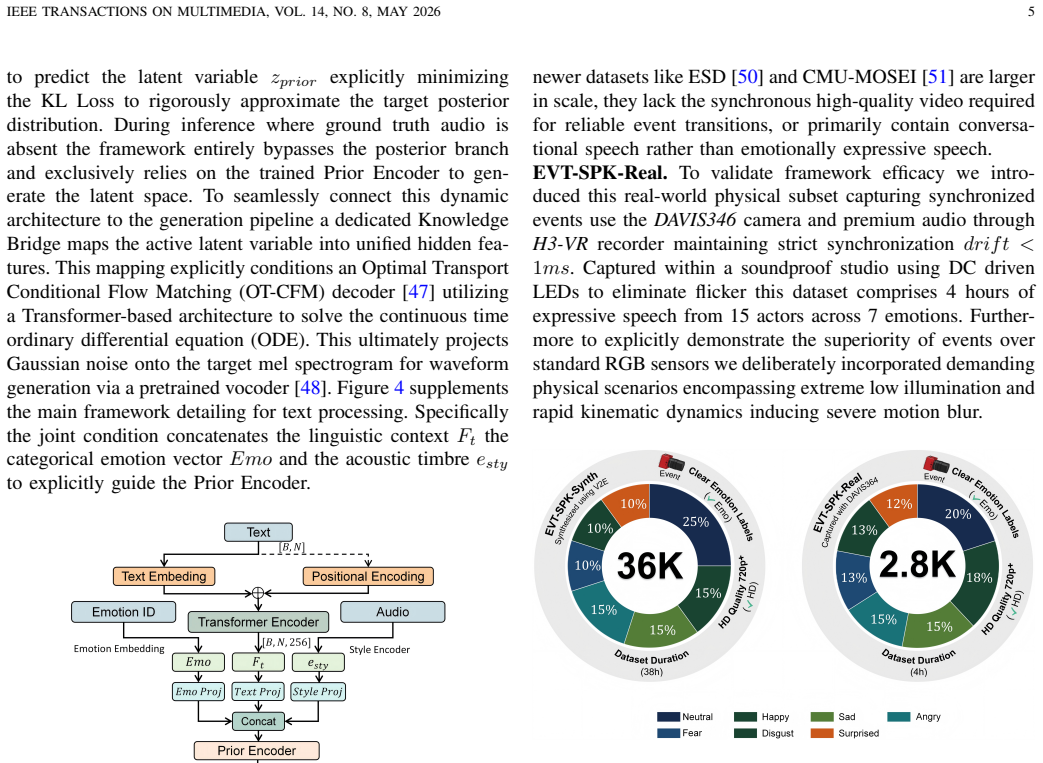
- EVT-SPK supplies the first large-scale benchmark mixing synthetic and real neuromorphic recordings.
- The architecture establishes a new multimodal route for speech generation that does not rely on fixed-frame RGB input.
Where Pith is reading between the lines
- The same event-to-audio alignment could be tested on live streams where lighting changes rapidly.
- Combining event input with standard microphones might allow hybrid systems that fall back when one sensor fails.
- The sparse nature of events could reduce compute load for on-device speech synthesis compared with dense video frames.
Load-bearing premise
Microsecond-precise event data from neuromorphic cameras can be reliably aligned with acoustic waveform dynamics via the bidirectional mechanism without introducing artifacts or losing linguistic content.
What would settle it
A controlled comparison in which speech generated from event data shows the same loss of emotional transients or the same motion-blur artifacts as RGB-based methods under rapid articulatory motion would disprove the claimed advantage.
Figures

read the original abstract
Traditional RGB-based speech generation faces Temporal Granularity Mismatch since fixed camera exposure times inevitably blur the high-frequency articulatory transients essential for rendering emotional speech. To break this ceiling, we propose EventSpeech as a novel text-conditioned framework pioneering the use of neuromorphic events for expressive speech generation, since these microsecond-precise events naturally align with acoustic waveform dynamics. Our architecture integrates a dedicated Event Encoder to model sparse neuromorphic events alongside a multi-scale Audio Encoder featuring a Hierarchical Wavelet Contextualizer (HWC). A bidirectional alignment mechanism seamlessly synchronizes linguistic content and visual dynamics with dense acoustic features. Furthermore, we construct EVT-SPK as the first benchmark comprising large-scale synthetic data and real-world recordings from specialized neuromorphic hardware. Extensive evaluations demonstrate that EventSpeech significantly outperforms current baselines by preserving fine-grained emotions and resisting motion blur to establish a new paradigm for multimodal speech generation. Code and demo are available at https://xrfang-0102.github.io/EventSpeechWeb/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes EventSpeech, a text-conditioned framework for expressive speech generation from neuromorphic event camera data. It addresses temporal granularity mismatch in RGB cameras by using microsecond-precise events that align with acoustic dynamics. The architecture includes an Event Encoder for sparse events, a multi-scale Audio Encoder with Hierarchical Wavelet Contextualizer (HWC), and a bidirectional alignment mechanism to synchronize linguistic content with dense acoustic features. A new benchmark EVT-SPK is introduced with synthetic and real-world neuromorphic recordings. The paper claims extensive evaluations show significant outperformance over baselines in emotion preservation and motion blur resistance, establishing a new paradigm for multimodal speech generation.
Significance. If the central claims hold with supporting evidence, this could open a new direction in multimodal speech synthesis by exploiting event cameras' high temporal resolution for articulatory transients. The EVT-SPK benchmark construction is a clear positive contribution that enables future work. The offer of code and demo supports reproducibility.
major comments (2)
- [Bidirectional alignment mechanism] The bidirectional alignment mechanism (described in the abstract and method overview) is load-bearing for the headline claim of preserving phonemic/emotional content without artifacts, yet no equation, loss term, or invertibility argument is supplied to show that cross-attention on EVT-SPK data avoids discarding high-frequency formant information or introducing linguistic loss.
- [Evaluation / Experiments] The abstract asserts that 'extensive evaluations demonstrate' significant outperformance, but the provided text contains no quantitative metrics, error bars, ablation tables, or baseline comparisons; without these, the central claim of establishing a new paradigm cannot be assessed.
minor comments (1)
- [Abstract] The abstract would be strengthened by including at least one key quantitative result (e.g., emotion preservation metric or WER) to ground the outperformance claim.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the major comments point-by-point below and will revise the paper to strengthen the technical presentation and clarity of results.
read point-by-point responses
-
Referee: [Bidirectional alignment mechanism] The bidirectional alignment mechanism (described in the abstract and method overview) is load-bearing for the headline claim of preserving phonemic/emotional content without artifacts, yet no equation, loss term, or invertibility argument is supplied to show that cross-attention on EVT-SPK data avoids discarding high-frequency formant information or introducing linguistic loss.
Authors: We agree that a formal description of the bidirectional alignment is necessary to substantiate the claims. In the revised manuscript we will add the explicit cross-attention equations, the composite loss (alignment loss plus reconstruction and perceptual terms), and a short information-preservation argument that leverages the microsecond temporal resolution of events together with the multi-scale wavelet features in HWC. This addition will directly address concerns about high-frequency formant retention. revision: yes
-
Referee: [Evaluation / Experiments] The abstract asserts that 'extensive evaluations demonstrate' significant outperformance, but the provided text contains no quantitative metrics, error bars, ablation tables, or baseline comparisons; without these, the central claim of establishing a new paradigm cannot be assessed.
Authors: The full manuscript contains Section 4 with quantitative tables (MOS, emotion classification accuracy, F0 RMSE, etc.), error bars from five random seeds, ablation studies on the alignment module and HWC, and direct comparisons against RGB baselines. We will ensure these results are explicitly referenced from the abstract and method overview in the revision and will add a short summary table in the main text if the review excerpt omitted the experimental section. revision: partial
Circularity Check
No circularity: architecture and benchmark described without self-referential derivations
full rationale
The abstract and provided text introduce EventSpeech with an Event Encoder, Hierarchical Wavelet Contextualizer, and bidirectional alignment mechanism, plus the EVT-SPK benchmark. No equations, loss terms, or derivation steps are shown that reduce any prediction to fitted inputs by construction. No self-citations appear, and claims rest on empirical outperformance rather than definitional equivalence or imported uniqueness theorems. The alignment is asserted to synchronize content but is not exhibited as reducing to its own inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Matcha-tts: A fast tts architecture with conditional flow matching,
S. Mehta, R. Tu, J. Beskow, ´E. Sz ´ekely, and G. E. Henter, “Matcha-tts: A fast tts architecture with conditional flow matching,” inICASSP 2024- 2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 11341–11345, IEEE, 2024
2024
-
[2]
Naturalspeech: End-to-end text-to-speech synthesis with human-level quality,
X. Tan, J. Chen, H. Liu, J. Cong, C. Zhang, Y . Liu, X. Wang, Y . Leng, Y . Yi, L. He,et al., “Naturalspeech: End-to-end text-to-speech synthesis with human-level quality,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 46, no. 6, pp. 4234–4245, 2024
2024
-
[3]
Conditional variational autoencoder with adversarial learning for end-to-end text-to-speech,
J. Kim, J. Kong, and J. Son, “Conditional variational autoencoder with adversarial learning for end-to-end text-to-speech,” inInternational conference on machine learning, pp. 5530–5540, PMLR, 2021
2021
-
[4]
Imaginary voice: Face-styled diffusion model for text-to-speech,
J. Lee, J. S. Chung, and S.-W. Chung, “Imaginary voice: Face-styled diffusion model for text-to-speech,” inICASSP 2023-2023 IEEE In- ternational Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 1–5, IEEE, 2023
2023
-
[5]
V2a-mapper: A lightweight solution for vision-to-audio generation by connecting foundation models,
H. Wang, J. Ma, S. Pascual, R. Cartwright, and W. Cai, “V2a-mapper: A lightweight solution for vision-to-audio generation by connecting foundation models,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 38, pp. 15492–15501, 2024
2024
-
[6]
S. Chen, S. Liu, L. Zhou, Y . Liu, X. Tan, J. Li, S. Zhao, Y . Qian, and F. Wei, “Vall-e 2: Neural codec language models are human parity zero-shot text to speech synthesizers,”arXiv preprint arXiv:2406.05370, 2024
-
[7]
Glow-tts: A generative flow for text-to-speech via monotonic alignment search,
J. Kim, S. Kim, J. Kong, and S. Yoon, “Glow-tts: A generative flow for text-to-speech via monotonic alignment search,”Advances in Neural Information Processing Systems, vol. 33, pp. 8067–8077, 2020
2020
-
[8]
Dcptalk: Speech- driven 3d face animation with personalized facial dynamic coupling properties,
Z. Chu, K. Guo, X. Xing, P. Liu, B. Cai, and X. Xu, “Dcptalk: Speech- driven 3d face animation with personalized facial dynamic coupling properties,”IEEE Transactions on Multimedia, vol. 27, pp. 4427–4440, 2025. IEEE TRANSACTIONS ON MULTIMEDIA, VOL. 14, NO. 8, MAY 2026 9
2025
-
[9]
Styledubber: Towards multi-scale style learning for movie dubbing,
G. Cong, Y . Qi, L. Li, A. Beheshti, Z. Zhang, A. Hengel, M.-H. Yang, C. Yan, and Q. Huang, “Styledubber: Towards multi-scale style learning for movie dubbing,” inFindings of the Association for Computational Linguistics: ACL 2024, pp. 6767–6779, 2024
2024
-
[10]
Seeing and hearing: Open-domain visual-audio generation with diffusion latent aligners,
Y . Xing, Y . He, Z. Tian, X. Wang, and Q. Chen, “Seeing and hearing: Open-domain visual-audio generation with diffusion latent aligners,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 7151–7161, 2024
2024
-
[11]
Tell what you hear from what you see-video to audio generation through text,
X. Liu, K. Su, and E. Shlizerman, “Tell what you hear from what you see-video to audio generation through text,”Advances in Neural Information Processing Systems, vol. 37, pp. 101337–101366, 2024
2024
-
[12]
Learning dual modality interactions for event-based motion deblurring,
Z. Xiao, Z. Li, Y . Zhao, Y . Liu, Z. Zhang, and W. Jia, “Learning dual modality interactions for event-based motion deblurring,”IEEE Transactions on Multimedia, 2026
2026
-
[13]
v2e: From video frames to realistic dvs events,
Y . Hu, S.-C. Liu, and T. Delbruck, “v2e: From video frames to realistic dvs events,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 1312–1321, 2021
2021
-
[14]
Recent event camera innovations: A survey,
B. Chakravarthi, A. A. Verma, K. Daniilidis, C. Fermuller, and Y . Yang, “Recent event camera innovations: A survey,” inEuropean conference on computer vision, pp. 342–376, Springer, 2024
2024
-
[15]
Eventlip: Enhancing event-based lip reading via frequency-aware spatiotemporal hypergraph modeling,
X. Zhang, J. Sun, C. Zhang, X. Yue, T. Xiao, S. Cai, M. Lao, and H. Li, “Eventlip: Enhancing event-based lip reading via frequency-aware spatiotemporal hypergraph modeling,” inProceedings of the 33rd ACM International Conference on Multimedia, pp. 8263–8272, 2025
2025
-
[16]
Event- based low-illumination image enhancement,
Y . Jiang, Y . Wang, S. Li, Y . Zhang, M. Zhao, and Y . Gao, “Event- based low-illumination image enhancement,”IEEE Transactions on Multimedia, vol. 26, pp. 1920–1931, 2023
1920
-
[17]
E-mlb: Multilevel benchmark for event-based camera denoising,
S. Ding, J. Chen, Y . Wang, Y . Kang, W. Song, J. Cheng, and Y . Cao, “E-mlb: Multilevel benchmark for event-based camera denoising,”IEEE Transactions on Multimedia, vol. 26, pp. 65–76, 2023
2023
-
[18]
Mead: A large-scale audio-visual dataset for emotional talking-face generation,
K. Wang, Q. Wu, L. Song, Z. Yang, W. Wu, C. Qian, R. He, Y . Qiao, and C. C. Loy, “Mead: A large-scale audio-visual dataset for emotional talking-face generation,” inEuropean conference on computer vision, pp. 700–717, Springer, 2020
2020
-
[19]
The ryerson audio-visual database of emotional speech and song (ravdess): A dynamic, multimodal set of facial and vocal expressions in north american english,
S. R. Livingstone and F. A. Russo, “The ryerson audio-visual database of emotional speech and song (ravdess): A dynamic, multimodal set of facial and vocal expressions in north american english,”PloS one, vol. 13, no. 5, p. e0196391, 2018
2018
-
[20]
Tacotron: Towards End-to-End Speech Synthesis
Y . Wang, R. Skerry-Ryan, D. Stanton, Y . Wu, R. J. Weiss, N. Jaitly, Z. Yang, Y . Xiao, Z. Chen, S. Bengio,et al., “Tacotron: Towards end- to-end speech synthesis,”arXiv preprint arXiv:1703.10135, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[21]
Natural tts synthesis by conditioning wavenet on mel spectrogram predictions,
J. Shen, R. Pang, R. J. Weiss, M. Schuster, N. Jaitly, Z. Yang, Z. Chen, Y . Zhang, Y . Wang, R. Skerrv-Ryan,et al., “Natural tts synthesis by conditioning wavenet on mel spectrogram predictions,” in2018 IEEE international conference on acoustics, speech and signal processing (ICASSP), pp. 4779–4783, IEEE, 2018
2018
-
[22]
Grad- tts: A diffusion probabilistic model for text-to-speech,
V . Popov, I. V ovk, V . Gogoryan, T. Sadekova, and M. Kudinov, “Grad- tts: A diffusion probabilistic model for text-to-speech,” inInternational conference on machine learning, pp. 8599–8608, PMLR, 2021
2021
-
[23]
DiffWave: A Versatile Diffusion Model for Audio Synthesis
Z. Kong, W. Ping, J. Huang, K. Zhao, and B. Catanzaro, “Dif- fwave: A versatile diffusion model for audio synthesis,”arXiv preprint arXiv:2009.09761, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[24]
F5-tts: A fairytaler that fakes fluent and faithful speech with flow matching,
Y . Chen, Z. Niu, Z. Ma, K. Deng, C. Wang, J. JianZhao, K. Yu, and X. Chen, “F5-tts: A fairytaler that fakes fluent and faithful speech with flow matching,” inProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 6255–6271, 2025
2025
-
[25]
Ditto-tts: Dif- fusion transformers for scalable text-to-speech without domain-specific factors,
K. Lee, D. W. Kim, J. Kim, S. Chung, and J. Cho, “Ditto-tts: Dif- fusion transformers for scalable text-to-speech without domain-specific factors,” inInternational Conference on Learning Representations, vol. 2025, pp. 52022–52055, 2025
2025
-
[26]
More than words: In-the-wild visually-driven prosody for text-to-speech,
M. Hassid, M. T. Ramanovich, B. Shillingford, M. Wang, Y . Jia, and T. Remez, “More than words: In-the-wild visually-driven prosody for text-to-speech,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 10587–10597, 2022
2022
-
[27]
Realistic speech-driven facial animation with gans,
K. V ougioukas, S. Petridis, and M. Pantic, “Realistic speech-driven facial animation with gans,”International Journal of Computer Vision, vol. 128, no. 5, pp. 1398–1413, 2020
2020
-
[28]
V oicecraft-dub: Automated video dubbing with neural codec language models,
K. Sung-Bin, J. Choi, P. Peng, J. S. Chung, T.-H. Oh, and D. Harwath, “V oicecraft-dub: Automated video dubbing with neural codec language models,” inProceedings of the IEEE/CVF International Conference on Computer Vision, pp. 14623–14632, 2025
2025
-
[29]
Learning to dub movies via hierarchical prosody models,
G. Cong, L. Li, Y . Qi, Z.-J. Zha, Q. Wu, W. Wang, B. Jiang, M.-H. Yang, and Q. Huang, “Learning to dub movies via hierarchical prosody models,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 14687–14697, 2023
2023
-
[30]
Foleycrafter: Bring silent videos to life with lifelike and synchronized sounds,
Y . Zhang, Y . Gu, Y . Zeng, Z. Xing, Y . Wang, Z. Wu, B. Liu, and K. Chen, “Foleycrafter: Bring silent videos to life with lifelike and synchronized sounds,”International Journal of Computer Vision, vol. 134, no. 1, p. 46, 2026
2026
-
[31]
Diff-foley: Synchronized video- to-audio synthesis with latent diffusion models,
S. Luo, C. Yan, C. Hu, and H. Zhao, “Diff-foley: Synchronized video- to-audio synthesis with latent diffusion models,”Advances in Neural Information Processing Systems, vol. 36, pp. 48855–48876, 2023
2023
-
[32]
Taro: Timestep-adaptive rep- resentation alignment with onset-aware conditioning for synchronized video-to-audio synthesis,
T. Ton, J. W. Hong, and C. D. Yoo, “Taro: Timestep-adaptive rep- resentation alignment with onset-aware conditioning for synchronized video-to-audio synthesis,” inProceedings of the IEEE/CVF International Conference on Computer Vision, pp. 14228–14237, 2025
2025
-
[33]
Audio-visual controlled video diffusion with masked selective state spaces modeling for natural talking head generation,
F.-T. Hong, Z. Xu, Z. Zhou, J. Zhou, X. Li, Q. Lin, Q. Lu, and D. Xu, “Audio-visual controlled video diffusion with masked selective state spaces modeling for natural talking head generation,” inProceed- ings of the IEEE/CVF International Conference on Computer Vision, pp. 12549–12558, 2025
2025
-
[34]
Float: Generative motion latent flow match- ing for audio-driven talking portrait,
T. Ki, D. Min, and G. Chae, “Float: Generative motion latent flow match- ing for audio-driven talking portrait,” inProceedings of the IEEE/CVF International Conference on Computer Vision, pp. 14699–14710, 2025
2025
-
[35]
High speed and high dynamic range video with an event camera,
H. Rebecq, R. Ranftl, V . Koltun, and D. Scaramuzza, “High speed and high dynamic range video with an event camera,”IEEE transactions on pattern analysis and machine intelligence, vol. 43, no. 6, pp. 1964–1980, 2019
1964
-
[36]
Physics- driven diffusion models for impact sound synthesis from videos,
K. Su, K. Qian, E. Shlizerman, A. Torralba, and C. Gan, “Physics- driven diffusion models for impact sound synthesis from videos,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 9749–9759, 2023
2023
-
[37]
Isolated single sound lip- reading using a frame-based camera and event-based camera,
T. Kanamaru, T. Arakane, and T. Saitoh, “Isolated single sound lip- reading using a frame-based camera and event-based camera,”Frontiers in Artificial Intelligence, vol. 5, p. 1070964, 2023
2023
-
[38]
Multi-grained spatio-temporal features perceived network for event-based lip-reading,
G. Tan, Y . Wang, H. Han, Y . Cao, F. Wu, and Z.-J. Zha, “Multi-grained spatio-temporal features perceived network for event-based lip-reading,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 20094–20103, 2022
2022
-
[39]
Collaborative viseme subword and end-to-end modeling for word-level lip reading,
H. Chen, Q. Wang, J. Du, G.-S. Wan, S.-F. Xiong, B.-C. Yin, J. Pan, and C.-H. Lee, “Collaborative viseme subword and end-to-end modeling for word-level lip reading,”IEEE Transactions on Multimedia, vol. 26, pp. 9358–9371, 2024
2024
-
[40]
Audio-visual target speaker enhancement on multi-talker environment using event-driven cameras,
A. Arriandiaga, G. Morrone, L. Pasa, L. Badino, and C. Bartolozzi, “Audio-visual target speaker enhancement on multi-talker environment using event-driven cameras,” in2021 IEEE International Symposium on Circuits and Systems (ISCAS), pp. 1–5, IEEE, 2021
2021
-
[41]
Convnext v2: Co-designing and scaling convnets with masked autoencoders,
S. Woo, S. Debnath, R. Hu, X. Chen, Z. Liu, I. S. Kweon, and S. Xie, “Convnext v2: Co-designing and scaling convnets with masked autoencoders,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 16133–16142, 2023
2023
-
[42]
Maxim: Multi-axis mlp for image processing,
Z. Tu, H. Talebi, H. Zhang, F. Yang, P. Milanfar, A. Bovik, and Y . Li, “Maxim: Multi-axis mlp for image processing,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 5769–5780, 2022
2022
-
[43]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
A. Gu and T. Dao, “Mamba: Linear-time sequence modeling with selective state spaces,”arXiv preprint arXiv:2312.00752, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[44]
BigVGAN: A Universal Neural Vocoder with Large-Scale Training.arXiv preprint arXiv:2206.04658, 2022
S.-g. Lee, W. Ping, B. Ginsburg, B. Catanzaro, and S. Yoon, “Bigvgan: A universal neural vocoder with large-scale training,”arXiv preprint arXiv:2206.04658, 2022
-
[45]
Simple and controllable music generation,
J. Copet, F. Kreuk, I. Gat, T. Remez, D. Kant, G. Synnaeve, Y . Adi, and A. D ´efossez, “Simple and controllable music generation,”Advances in neural information processing systems, vol. 36, pp. 47704–47720, 2023
2023
-
[46]
Representation Learning with Contrastive Predictive Coding
A. v. d. Oord, Y . Li, and O. Vinyals, “Representation learning with contrastive predictive coding,”arXiv preprint arXiv:1807.03748, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[47]
Flow Matching for Generative Modeling
Y . Lipman, R. T. Chen, H. Ben-Hamu, M. Nickel, and M. Le, “Flow matching for generative modeling,”arXiv preprint arXiv:2210.02747, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[48]
Hifi-gan: Generative adversarial networks for efficient and high fidelity speech synthesis,
J. Kong, J. Kim, and J. Bae, “Hifi-gan: Generative adversarial networks for efficient and high fidelity speech synthesis,”Advances in neural information processing systems, vol. 33, pp. 17022–17033, 2020
2020
-
[49]
From faces to voices: Learning hierarchical representations for high-quality video-to- speech,
J.-H. Kim, J. Choi, J. Kim, C. Jung, and J. S. Chung, “From faces to voices: Learning hierarchical representations for high-quality video-to- speech,” inProceedings of the Computer Vision and Pattern Recognition Conference, pp. 15874–15884, 2025
2025
-
[50]
Seen and unseen emotional style transfer for voice conversion with a new emotional speech dataset,
K. Zhou, B. Sisman, R. Liu, and H. Li, “Seen and unseen emotional style transfer for voice conversion with a new emotional speech dataset,” in ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 920–924, IEEE, 2021
2021
-
[51]
Multimodal language analysis in the wild: Cmu-mosei dataset and interpretable dynamic fusion graph,
A. B. Zadeh, P. P. Liang, S. Poria, E. Cambria, and L.-P. Morency, “Multimodal language analysis in the wild: Cmu-mosei dataset and interpretable dynamic fusion graph,” inProceedings of the 56th Annual IEEE TRANSACTIONS ON MULTIMEDIA, VOL. 14, NO. 8, MAY 2026 10 Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 2236–2246, 2018
2026
-
[52]
Mmaudio: Taming multimodal joint training for high- quality video-to-audio synthesis,
H. K. Cheng, M. Ishii, A. Hayakawa, T. Shibuya, A. Schwing, and Y . Mitsufuji, “Mmaudio: Taming multimodal joint training for high- quality video-to-audio synthesis,” inProceedings of the Computer Vision and Pattern Recognition Conference, pp. 28901–28911, 2025
2025
-
[53]
Contentvec: An improved self-supervised speech representation by disentangling speakers,
K. Qian, Y . Zhang, H. Gao, J. Ni, C.-I. Lai, D. Cox, M. Hasegawa- Johnson, and S. Chang, “Contentvec: An improved self-supervised speech representation by disentangling speakers,” inInternational con- ference on machine learning, pp. 18003–18017, PMLR, 2022
2022
-
[54]
Styletts 2: Towards human-level text-to-speech through style diffusion and adversarial training with large speech language models,
Y . A. Li, C. Han, V . Raghavan, G. Mischler, and N. Mesgarani, “Styletts 2: Towards human-level text-to-speech through style diffusion and adversarial training with large speech language models,”Advances in neural information processing systems, vol. 36, pp. 19594–19621, 2023
2023
-
[55]
On the audio-visual synchronization for lip- to-speech synthesis,
Z. Niu and B. Mak, “On the audio-visual synchronization for lip- to-speech synthesis,” inProceedings of the IEEE/CVF International Conference on Computer Vision, pp. 7843–7852, 2023
2023
-
[56]
A lip sync expert is all you need for speech to lip generation in the wild,
K. Prajwal, R. Mukhopadhyay, V . P. Namboodiri, and C. Jawahar, “A lip sync expert is all you need for speech to lip generation in the wild,” in Proceedings of the 28th ACM international conference on multimedia, pp. 484–492, 2020
2020
-
[57]
Audio-visual speech representation expert for enhanced talking face video generation and evaluation,
D. Yaman, F. I. Eyiokur, L. B ¨armann, S. Akti, H. K. Ekenel, and A. Waibel, “Audio-visual speech representation expert for enhanced talking face video generation and evaluation,” inProceedings Of The IEEE/CVF Conference On Computer Vision And Pattern Recognition, pp. 6003–6013, 2024
2024
-
[58]
Mega-tts 2: Boosting prompting mechanisms for zero-shot speech synthesis,
Z. Jiang, J. Liu, Y . Ren, J. He, Z. Ye, S. Ji, Q. Yang, C. Zhang, P. Wei, C. Wang,et al., “Mega-tts 2: Boosting prompting mechanisms for zero-shot speech synthesis,” inInternational Conference on Learning Representations, vol. 2024, pp. 57919–57939, 2024
2024
-
[59]
Indicvoices- r: Unlocking a massive multilingual multi-speaker speech corpus for scaling indian tts,
A. Sankar, S. Anand, P. S. Varadhan, S. Thomas, M. Singal, S. Kumar, D. Mehendale, A. Krishana, G. Raju, and M. Khapra, “Indicvoices- r: Unlocking a massive multilingual multi-speaker speech corpus for scaling indian tts,”Advances in Neural Information Processing Systems, vol. 37, pp. 68161–68182, 2024
2024
-
[60]
Styletts: A style-based generative model for natural and diverse text-to-speech synthesis,
Y . A. Li, C. Han, and N. Mesgarani, “Styletts: A style-based generative model for natural and diverse text-to-speech synthesis,”IEEE Journal of Selected Topics in Signal Processing, vol. 19, no. 1, pp. 283–296, 2025
2025
-
[61]
Paralinguistics-aware speech-empowered large language models for natural conversation,
H. Kim, S. Seo, K. Jeong, O. Kwon, S. Kim, J. Kim, J. Lee, E. Song, M. Oh, J.-W. Ha,et al., “Paralinguistics-aware speech-empowered large language models for natural conversation,”Advances in Neural Information Processing Systems, vol. 37, pp. 131072–131103, 2024
2024
-
[62]
Naturalspeech 3: Zero-shot speech syn- thesis with factorized codec and diffusion models,
Z. Ju, Y . Wang, K. Shen, X. Tan, D. Xin, D. Yang, Y . Liu, Y . Leng, K. Song, S. Tang,et al., “Naturalspeech 3: Zero-shot speech syn- thesis with factorized codec and diffusion models,”arXiv preprint arXiv:2403.03100, 2024. Fang Jingpingreceived the B.S. degree in Computer Science and Technology from Zhengzhou Univer- sity of Industrial Technology, Zheng...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.