DynFrame: Adaptive Reasoning-Driven Multimodal Framework with Dynamic Frame Augmentation for Complex Video Understanding
Pith reviewed 2026-06-29 17:47 UTC · model grok-4.3
The pith
A video multimodal model emits both the chosen time window and its sampling density as native tokens inside one autoregressive generation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
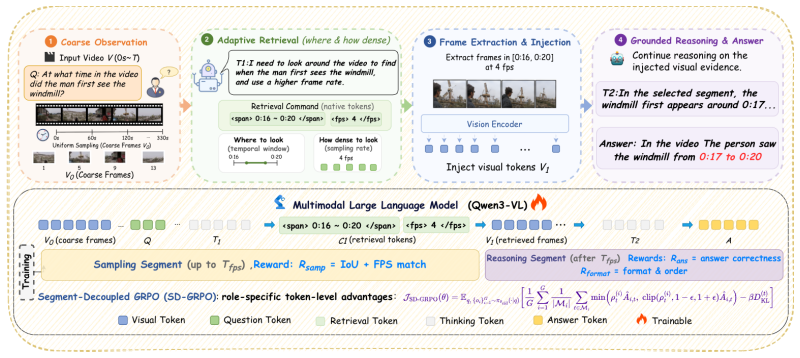
DynFrame emits the temporal window and the sampling density as native tokens within a single autoregressive pass. This learnable span-density retrieval enables acquiring multi-granularity evidence with a single retrieval step. Segment-Decoupled GRPO splits each rollout at the retrieval boundary and assigns role-specific token-level advantages, separately crediting the sampling decision and the answer.
What carries the argument
Learnable span-density retrieval, in which the model produces both the temporal window and the sampling density as tokens in the same generation sequence used for the final answer.
If this is right
- Multi-granularity evidence can be obtained in one retrieval step instead of repeated calls.
- Role-specific advantages allow independent optimization of sampling decisions and answer generation.
- 4B-scale models become competitive with 7B-8B fixed-density systems across six video benchmarks.
- 8B-scale models reach new state-of-the-art numbers on most of the same benchmarks.
Where Pith is reading between the lines
- The same tokenized retrieval interface could be applied to other sequential inputs such as long documents or audio streams where inspection granularity varies.
- If density tokens prove stable, agentic systems that currently loop over retrieval steps might collapse those loops into single generations.
- Curating data that explicitly rewards varied density choices may become necessary to prevent the model from ignoring the new token.
- The approach implicitly assumes that density decisions benefit from the same gradient signal as answer tokens once credit is decoupled.
Load-bearing premise
A single autoregressive pass can reliably output both accurate retrieval tokens for window and density and the final answer without the model collapsing to trivial or fixed-density strategies.
What would settle it
Train the model on the same data but remove the density token from the output vocabulary and measure whether benchmark scores fall back to the level of fixed-density baselines.
Figures

read the original abstract
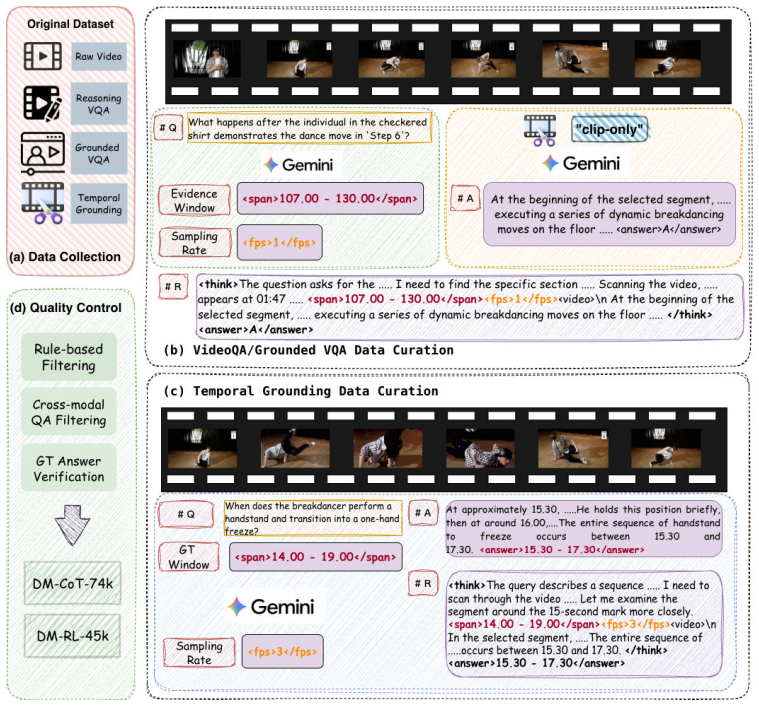
Recent video multimodal large language models (MLLMs) increasingly couple step-by-step reasoning with on-demand visual evidence retrieval, allowing models to revisit relevant video segments during inference. However, two structural gaps remain in existing thinking-with-video systems. (i) Sampling density is not a learnable decision: existing methods may let the model decide where to look, but the per-window frame rate is largely fixed. As a result, fine-grained evidence is often recovered through repeated retrieval calls, which increases inference context length and training difficulty. (ii) Retrieval and answer generation are usually optimized with a single trajectory-level advantage, so the "where to look" tokens and the "how to answer" tokens receive the same credit even when one is correct and the other is not. To address these gaps, we present DynFrame, a framework that emits the temporal window and the sampling density as native tokens within a single autoregressive pass. This learnable span-density retrieval enables acquiring multi-granularity evidence with a single retrieval step. Based on the above tokenized retrieval interface, we further introduce Segment-Decoupled GRPO (SD-GRPO), which splits each rollout at the retrieval boundary and assigns role-specific token-level advantages, separately crediting the sampling decision and the answer. Trained on the curated DM-CoT-74k and DM-RL-45k, DynFrame-4B is competitive with strong 7B-8B baselines across six benchmarks (NExT-GQA, Charades-STA, ActivityNet-MR, Video-MME, MLVU, LVBench), and DynFrame-8B sets new state-of-the-art on most metrics. Code is available at https://github.com/zhangguanghao523/DynFrame.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces DynFrame, a framework for video multimodal large language models that tokenizes both the temporal window and the sampling density as native tokens in a single autoregressive pass to enable learnable multi-granularity evidence retrieval. It further proposes Segment-Decoupled GRPO (SD-GRPO) to split rollouts at the retrieval boundary and assign separate token-level advantages to the sampling decision and the answer generation. The models are trained on DM-CoT-74k and DM-RL-45k datasets, with DynFrame-4B reported as competitive with larger baselines and DynFrame-8B achieving new state-of-the-art results on most of six evaluated benchmarks.
Significance. If the results hold and the proposed mechanisms are shown to function as described without collapse to trivial strategies, this would be a significant contribution to the field of video understanding in MLLMs by addressing fixed sampling density and entangled credit assignment. The SOTA performance on multiple benchmarks would indicate practical utility, and the open code supports further research.
major comments (2)
- [Abstract] Abstract: The central claim that the learnable span-density retrieval acquires multi-granularity evidence in a single step relies on the density tokens being query-dependent and non-trivial; however, the abstract provides no ablation studies, density histograms, or training curves to demonstrate that the sampling density varies meaningfully rather than defaulting to the maximum setting.
- [Abstract] Abstract: The description of SD-GRPO as providing role-specific token-level advantages is presented without verification that the advantage signal for density tokens is disentangled from downstream answer quality; this is critical because if entangled, the mechanism may not differ from standard trajectory-level optimization.
minor comments (1)
- The abstract could specify the exact benchmark metrics where SOTA is achieved and where it is not, for clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for clearer support of our central claims within the abstract. We address each major comment point by point below, drawing on evidence already present in the full manuscript while proposing targeted revisions to improve clarity.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that the learnable span-density retrieval acquires multi-granularity evidence in a single step relies on the density tokens being query-dependent and non-trivial; however, the abstract provides no ablation studies, density histograms, or training curves to demonstrate that the sampling density varies meaningfully rather than defaulting to the maximum setting.
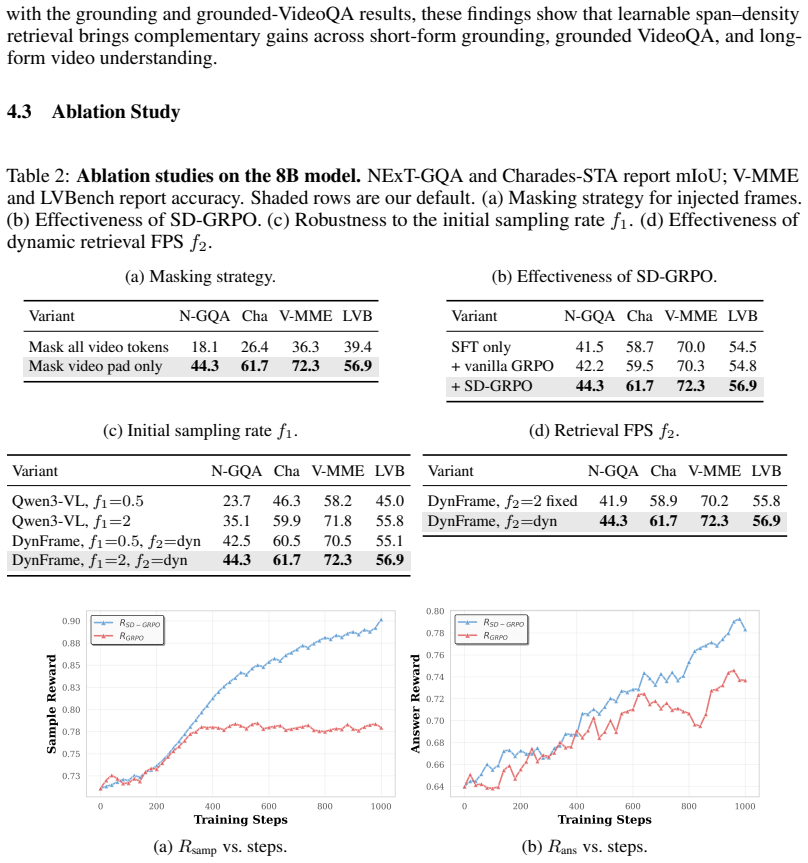
Authors: The abstract is a high-level summary and cannot accommodate full experimental details. Sections 4.2 and 4.3 of the manuscript present ablation studies, density histograms across query types, and training curves that confirm sampling density varies meaningfully in a query-dependent manner and does not collapse to the maximum setting. We will revise the abstract to add a concise clause referencing these empirical validations. revision: partial
-
Referee: [Abstract] Abstract: The description of SD-GRPO as providing role-specific token-level advantages is presented without verification that the advantage signal for density tokens is disentangled from downstream answer quality; this is critical because if entangled, the mechanism may not differ from standard trajectory-level optimization.
Authors: Section 3.2 details the segment-decoupled rollout splitting, and Section 5.2 plus Appendix B provide comparative experiments against standard GRPO that demonstrate performance gains attributable to the disentangled token-level advantages. These results indicate the advantage signals for density tokens are not fully entangled with answer quality. We will update the abstract to briefly note that this disentanglement is empirically supported. revision: partial
Circularity Check
No circularity: derivation is self-contained with external benchmarks
full rationale
The paper's central claims rest on a tokenized retrieval interface and SD-GRPO advantage assignment, trained on explicitly curated external datasets (DM-CoT-74k, DM-RL-45k) and evaluated on six independent benchmarks. No equations, fitted parameters, or self-citations are presented that reduce the claimed multi-granularity retrieval or decoupled advantages to a quantity defined by the result itself. The abstract and description supply no self-referential definitions or renamings that collapse the output to the input by construction. This is the normal case of an independent empirical contribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Keqin Chen, Wenbin Ge, Xuejing Liu, Jialin Wang, Sibo Song, Kai Dang, Shijie Wang, Peng Wang, Jun Tang, et al. Qwen3-vl: Advancing multimodal perception across arbitrarily-resolution visual inputs.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2.5-vl technical report.arXiv preprint arXiv:2502.13923, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Rextime: A benchmark suite for reasoning-across-time in videos.arXiv preprint arXiv:2406.19392, 2024
Jr-Jen Chen, Yu-Chien Liao, Hsi-Che Lin, Yu-Chu Yu, Yen-Chun Chen, and Yu-Chiang Frank Wang. Rextime: A benchmark suite for reasoning-across-time in videos.arXiv preprint arXiv:2406.19392, 2024
-
[4]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities, 2025. URLhttps://arxiv.org/abs/2507.06261
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Yang Ding, Yizhen Zhang, Xin Lai, Ruihang Chu, and Yujiu Yang. Videozoomer: Reinforcement- learned temporal focusing for long video reasoning.arXiv preprint arXiv:2512.22315, 2025. URL https://arxiv.org/abs/2512.22315
-
[6]
Video-R1: Reinforcing Video Reasoning in MLLMs
Kaituo Feng, Kaixiong Gong, Bohao Li, Zonghao Guo, Yibing Wang, Tianshuo Peng, Junfei Wu, Xiaoying Zhang, Benyou Wang, and Xiangyu Yue. Video-r1: Reinforcing video reasoning in mllms.arXiv preprint arXiv:2503.21776, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis
Chaoyou Fu, Yuhan Dai, Yongdong Luo, Lei Li, Shuhuai Ren, Renrui Zhang, Zihan Wang, Chenyu Zhou, Yunhang Shen, Mengdan Zhang, et al. Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 24108–24118, 2025
2025
-
[8]
Shenghao Fu, Qize Yang, Yuan-Ming Li, Xihan Wei, Xiaohua Xie, and Wei-Shi Zheng. Love-r1: Advancing long video understanding with an adaptive zoom-in mechanism via multi-step reasoning.arXiv preprint arXiv:2509.24786, 2025
-
[9]
Tall: Temporal activity localization via language query
Jiyang Gao, Chen Sun, Zhenheng Yang, and Ram Nevatia. Tall: Temporal activity localization via language query. InProceedings of the IEEE International Conference on Computer Vision, pages 5267–5275, 2017
2017
-
[10]
Gemini 3 Pro Model Card
Google DeepMind. Gemini 3 Pro Model Card. https://deepmind.google/models/model-cards/ gemini-3-pro, May 2026. Model release: November 2025; last updated: May 2026. Accessed: 2026-05- 25
2026
-
[11]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Zefeng He, Xiaoye Qu, Yafu Li, Siyuan Huang, Daizong Liu, and Yu Cheng. Framethinker: Learning to think with long videos via multi-turn frame spotlighting.arXiv preprint arXiv:2509.24304, 2025. To appear in ICLR 2026
-
[13]
Vision-R1: Incentivizing Reasoning Capability in Multimodal Large Language Models
Wenbo Huang, Bingyi Jia, Zhenbang Zhai, et al. Vision-r1: Incentivizing reasoning capability in multimodal large language models.arXiv preprint arXiv:2503.06749, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card.arXiv preprint arXiv:2410.21276, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
Chat-univi: Unified visual representation empowers large language models with image and video understanding
Peng Jin, Ryuichi Takanobu, Wancai Zhang, Xiaochun Cao, and Li Yuan. Chat-univi: Unified visual representation empowers large language models with image and video understanding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024
2024
-
[16]
Kimi Team, Angang Du, Bohong Yin, Bowei Xing, Bowen Qu, Bowen Wang, Cheng Chen, Chenlin Zhang, Chenzhuang Du, Chu Wei, et al. Kimi-vl technical report.arXiv preprint arXiv:2504.07491, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Dense-captioning events in videos
Ranjay Krishna, Kenji Hata, Frederic Ren, Li Fei-Fei, and Juan Carlos Niebles. Dense-captioning events in videos. InProceedings of the IEEE International Conference on Computer Vision, pages 706–715, 2017
2017
-
[18]
LLaVA-OneVision: Easy Visual Task Transfer
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Yanwei Li, Ziwei Liu, et al. Llava-onevision: Easy visual task transfer.arXiv preprint arXiv:2408.03326, 2024. 11
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
arXiv preprint arXiv:2506.01908 , year=
Hongyu Li, Songhao Han, Yue Liao, Junfeng Luo, Jialin Gao, Shuicheng Yan, and Si Liu. Reinforcement learning tuning for videollms: Reward design and data efficiency.arXiv preprint arXiv:2506.01908, 2025. URLhttps://arxiv.org/abs/2506.01908
-
[20]
VideoChat-R1: Enhancing Spatio-Temporal Perception via Reinforcement Fine-Tuning
Xinhao Li, Ziang Yan, Desen Meng, Lu Dong, Xiangyu Zeng, Yinan He, Yali Wang, Yu Qiao, Yi Wang, and Limin Wang. Videochat-r1: Enhancing spatio-temporal perception via reinforcement fine-tuning. arXiv preprint arXiv:2504.06958, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
VideoTemp-o3: Harmonizing Temporal Grounding and Video Understanding in Agentic Thinking-with-Videos
Wenqi Liu, Yunxiao Wang, Shijie Ma, Meng Liu, Qile Su, Tianke Zhang, Haonan Fan, Changyi Liu, Kaiyu Jiang, Jiankang Chen, Kaiyu Tang, Bin Wen, Fan Yang, Tingting Gao, Han Li, Yinwei Wei, and Xuemeng Song. VideoTemp-o3: Harmonizing temporal grounding and video understanding in agentic thinking-with- videos.arXiv preprint arXiv:2602.07801, 2026. URLhttps://...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[22]
Zuyan Liu et al. Video-rts: Rethinking reinforcement learning and test-time scaling for efficient and enhanced video reasoning.arXiv preprint arXiv:2507.06485, 2025
-
[23]
Video-ChatGPT: Towards Detailed Video Understanding via Large Vision and Language Models
Muhammad Maaz, Hanoona Rasheed, Salman Khan, and Fahad Shahbaz Khan. Video-chatgpt: Towards detailed video understanding via large vision and language models.arXiv preprint arXiv:2306.05424, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[24]
Jiahao Meng, Xiangtai Li, Haochen Wang, Yue Tan, Tao Zhang, Lingdong Kong, Yunhai Tong, Anran Wang, Zhiyang Teng, Yujing Wang, and Zhuochen Wang. Open-o3 Video: Grounded video reasoning with explicit spatio-temporal evidence.arXiv preprint arXiv:2510.20579, 2025. URL https://arxiv.org/ abs/2510.20579
-
[25]
Visual cot: Advancing multi-modal language models with a comprehensive dataset and benchmark for chain-of-thought reasoning
Hao Shao, Shengju Qian, Han Xiao, Guanglu Song, Zhi Zong, Letian Wang, Yu Liu, and Hongsheng Li. Visual cot: Advancing multi-modal language models with a comprehensive dataset and benchmark for chain-of-thought reasoning. InThe Thirty-eighth Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2024
2024
-
[26]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
Temporal grounding of activities using multimodal large language models
Young Chol Song. Temporal grounding of activities using multimodal large language models. arXiv preprint arXiv:2407.06157, 2024. URLhttps://arxiv.org/abs/2407.06157
-
[28]
Adaptive keyframe sampling for long video understanding
Xi Tang, Jihao Qiu, Lingxi Xie, Yunjie Tian, Jianbin Jiao, and Qixiang Ye. Adaptive keyframe sampling for long video understanding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025
2025
-
[29]
GRPO-CARE Team. Grpo-care: Consistency-aware reinforcement learning for video mllms.arXiv preprint arXiv:2506.16141, 2025
-
[30]
Qi Wang, Yanrui Yu, Ye Yuan, Rui Mao, and Tianfei Zhou. Videorft: Incentivizing video reasoning capability in mllms via reinforced fine-tuning.arXiv preprint arXiv:2505.12434, 2025
-
[31]
LVBench: An Extreme Long Video Understanding Benchmark
Weihan Wang, Zehai He, Wenyi Hong, Yean Cheng, Xiaohan Zhang, Ji Qi, Xiaotao Gu, Shiyu Huang, Bin Xu, Yuxiao Dong, Ming Ding, and Jie Tang. LVBench: An extreme long video understanding benchmark. arXiv preprint arXiv:2406.08035, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[32]
Multimodal Chain-of-Thought Reasoning: A Comprehensive Survey
Yaoting Wang, Shengqiong Wu, Yuecheng Zhang, Shuicheng Yan, Ziwei Liu, Jiebo Luo, and Hao Fei. Multimodal chain-of-thought reasoning: A comprehensive survey.arXiv preprint arXiv:2503.12605, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
Chain-of-thought prompting elicits reasoning in large language models.Advances in Neural Information Processing Systems, 35:24824–24837, 2022
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models.Advances in Neural Information Processing Systems, 35:24824–24837, 2022
2022
-
[34]
Can I trust your answer? Visually grounded video question answering
Junbin Xiao, Angela Yao, Yicong Li, and Tat-Seng Chua. Can I trust your answer? Visually grounded video question answering. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 13204–13214, 2024
2024
-
[35]
Videochat-r1.5: Visual test-time scaling to reinforce multimodal reasoning by iterative perception
Ziang Yan, Xinhao Li, Desen Meng, Lu Dong, Xiangyu Zeng, Yinan He, Yali Wang, Yu Qiao, Yi Wang, and Limin Wang. Videochat-r1.5: Visual test-time scaling to reinforce multimodal reasoning by iterative perception. InAdvances in Neural Information Processing Systems (NeurIPS), 2025
2025
-
[36]
LongVT: Incentivizing "Thinking with Long Videos" via Native Tool Calling
Zuhao Yang, Sudong Wang, Kaichen Zhang, Keming Wu, Sicong Leng, Yifan Zhang, Bo Li, Chengwei Qin, Shijian Lu, Xingxuan Li, and Lidong Bing. Longvt: Incentivizing “thinking with long videos” via native tool calling.arXiv preprint arXiv:2511.20785, 2025. To appear in CVPR 2026. 12
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
Huanjin Yao et al. Focus: Efficient keyframe selection for long video understanding.arXiv preprint arXiv:2510.27280, 2025
-
[38]
Frame-voyager: Learning to query frames for video large language models
Shoubin Yu, Jaemin Cho, Prateek Yadav, and Mohit Bansal. Frame-voyager: Learning to query frames for video large language models. InAdvances in Neural Information Processing Systems, 2024
2024
-
[39]
Video-o3: Native Interleaved Clue Seeking for Long Video Multi-Hop Reasoning
Xiangyu Zeng, Zhiqiu Zhang, Yuhan Zhu, Xinhao Li, Zikang Wang, Changlian Ma, Qingyu Zhang, Zizheng Huang, Kun Ouyang, et al. Video-o3: Native interleaved clue seeking for long video multi-hop reasoning.arXiv preprint arXiv:2601.23224, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[40]
Video-llama: An instruction-tuned audio-visual language model for video understanding
Hang Zhang, Xin Li, and Lidong Bing. Video-llama: An instruction-tuned audio-visual language model for video understanding. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, 2023
2023
-
[41]
Thinking with videos: Multimodal tool-augmented reinforcement learning for long video reasoning
Haoji Zhang, Xin Gu, Jiawei Liu, Mingyang Li, Quan Wang, Zhibo Yang, Hongqing Yang, and Yansong Tang. Thinking with videos: Multimodal tool-augmented reinforcement learning for long video reasoning. arXiv preprint arXiv:2508.04416, 2025. To appear in CVPR 2026
-
[42]
Kaituo Zhang et al. R1-vl: Learning to reason with multimodal large language models via reinforcement learning.arXiv preprint arXiv:2503.12937, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
LLaVA-Video: Video Instruction Tuning With Synthetic Data
Yuanhan Zhang, Bo Li, Haotian Liu, Yong Jae Lee, Liangke Gui, Di Fu, Jiashi Feng, Ziwei Liu, and Chunyuan Li. Video instruction tuning with synthetic data.arXiv preprint arXiv:2410.02713, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[44]
DeepEyes: Incentivizing "Thinking with Images" via Reinforcement Learning
Ziwei Zheng, Michael Yang, Jack Hong, Chenxiao Zhao, Guohai Xu, Le Yang, Chao Shen, and Xing Yu. Deepeyes: Incentivizing “thinking with images” via reinforcement learning.arXiv preprint arXiv:2505.14362, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[45]
MLVU: Benchmarking Multi-task Long Video Understanding
Junjie Zhou, Yan Shu, Bo Zhao, Boya Wu, Shitao Xiao, Xi Yang, Yongping Xiong, Bo Zhang, Tiejun Huang, and Zheng Liu. MLVU: A comprehensive benchmark for multi-task long video understanding. arXiv preprint arXiv:2406.04264, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[46]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Jinguo Zhu, Weiyun Wang, Zhe Chen, Zhaoyang Liu, Shenglong Ye, Lixin Gu, Yuchen Duan, Hao Tian, Weijie Su, Jie Shao, et al. Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models.arXiv preprint arXiv:2504.10479, 2025. 13 Supplementary Material A Data Generation Prompts We provide the complete prompts used to query G...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[47]
Read the user’s question and infer the precise visual evidence required
-
[48]
Explain why this portion is critical
Describe, step by step, how you would locate the segment that likely contains this evidence. Explain why this portion is critical
-
[49]
Based on the nature and speed of the target activity, recommend an appropriate FPS for analysis
-
[50]
zoom_in_cot
Conclude your “zoom_in_cot” reasoning by appending the time span and FPS tags.Do NOTprovide or guess the answer in this field
-
[51]
Using the visual information in the segment, reason step-by-step to reach the answer
After that, imagine you have now watchedONLYthat segment at the specified FPS. Using the visual information in the segment, reason step-by-step to reach the answer
-
[52]
answer_cot
This reasoning plus the final answer (wrapped in<answer></answer>) goes into “answer_cot”. FPS Selection Guideline • 1–2 fps: Static or quasi-static scenes with minimal temporal variation (e.g., reading text/signs, appearance attributes, object identification, colors, a person standing still). • 3–4 fps: Moderately dynamic scenarios with clear temporal pr...
-
[53]
Starting from the original temporal span in the input, expand the start and end boundaries by a random margin of 0.5–2.0 seconds on each side to provide additional temporal context
-
[54]
Move the expanded temporal span to the front of the thinking process, formatted as <span>START - END</span> (seconds with two decimal places, e.g.,<span>29.50 - 74.00</span>)
-
[55]
Keep the reasoning concise and non-repetitive
Remove redundant or repeated temporal descriptions in the thinking process. Keep the reasoning concise and non-repetitive
-
[56]
Based on the duration of theexpanded spanand the nature of the activity described, append an FPS tag <fps>N</fps> immediately after the<span>tag
-
[57]
Max retrieval / injection
Extract only theoriginalstart and end timestamps as the final answer (e.g.,30.00 - 72.00). FPS Selection Guideline • 1–2 fps: Static or quasi-static scenes with minimal temporal variation (e.g., reading text/signs, appearance attributes, object identification, colors, a person standing still). • 3–4 fps: Moderately dynamic scenarios with clear temporal pr...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.