Mind the Tool Failures: Achieving Synergistic Tool Gains for Medical Agents
Pith reviewed 2026-06-29 18:02 UTC · model grok-4.3
The pith
Medical agents learn instance-by-instance tool selection to correct failures no single tool handles.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Instance-dependent failure patterns create a Single-Oracle risk gap between the best fixed single tool and an ideal instance-wise selector. Conventional task-level tool selection cannot close this gap because it is bounded by the best single tool. The authors therefore formulate tool use as instance-level selection and introduce a GRPO-based reinforcement learning framework whose rewards drive probabilistic risk minimization and disagreement-aware synergy learning, paired with an entropy-guided sampling strategy that upweights high-disagreement instances to supply stronger training signals. These components together reduce instance-level heterogeneity and produce robust improvements on medic
What carries the argument
GRPO-based reinforcement learning framework whose rewards enforce probabilistic risk minimization and disagreement-aware synergy learning, together with entropy-guided sampling that focuses on high-disagreement instances.
If this is right
- Medical agents can correct erroneous tool outputs on instances where the best fixed tool would fail.
- Performance is no longer limited by the single best tool but can realize the Single-Oracle risk gap.
- Entropy sampling and disagreement rewards together stabilize learning across heterogeneous medical cases.
- The same framework applies to both diagnosis and treatment-recommendation tasks without task-specific redesign.
- Reliable medical agentic systems require explicit modeling of instance-level tool synergy.
Where Pith is reading between the lines
- The same disagreement-driven rewards might improve tool use in legal or financial agents where tools also fail differently per query.
- If high-disagreement instances prove rare in some domains, the entropy sampling step may need replacement by active learning or synthetic data.
- The method could be tested by measuring whether the learned policy still outperforms the best tool when one of the original tools is removed from the pool.
Load-bearing premise
Instance-dependent failure patterns exist that let an ideal instance-wise selector outperform any single fixed tool and that these patterns can be learned from the proposed rewards and sampling.
What would settle it
Re-running the method on the same seven benchmarks and finding that average performance never exceeds the strongest single-tool baseline, or that gains disappear when disagreement signals are removed.
Figures

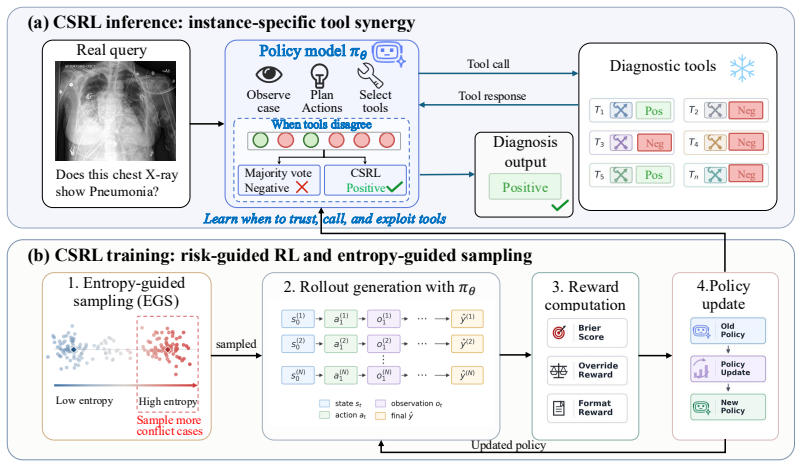
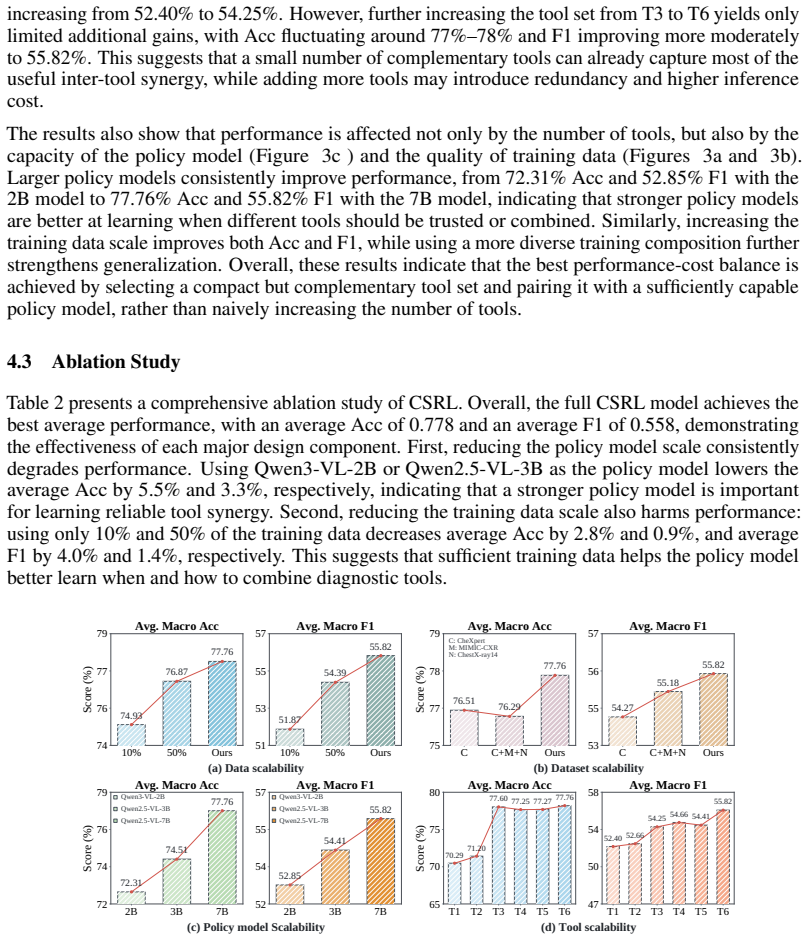
read the original abstract
Medical AI agents increasingly use external tools for diagnosis, treatment recommendation, and evidence retrieval, yet most existing approaches assume that task-appropriate tools are reliable within their intended scope. This assumption is fragile in real clinical settings, where even relevant tools may fail on challenging instances and lead to unsafe downstream decisions. To address this issue, we study medical tool use under imperfect-tool settings to correct failure instances missed by individual tools. Instance-dependent failure patterns create a gap between the best fixed single tool and an ideal instance-wise selector, which we refer to as the Single-Oracle risk gap. The core challenge is that conventional task-level tool selection cannot realize this gap, as it is inherently bounded by the performance of the best single tool. Motivated by this observation, we therefore account for instance-level heterogeneity and formulate tool use as an instance-level selection problem. Particularly, we propose a GRPO-based reinforcement learning framework with rewards for probabilistic risk minimization and disagreement-aware synergy learning, which promotes instance-level correction of erroneous tool consensus. Furthermore, an entropy-guided sampling strategy is adopted to upweight high-disagreement instances, which provide stronger signals for learning instance-specific tool synergy. These two components complement each other in mitigating instance-level heterogeneity and improving tool synergy. Experiments on two tasks and seven medical benchmarks show that our method consistently achieves robust and stable improvements over a broad range of baselines, highlighting the importance of synergy-aware tool use for reliable medical agentic systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that instance-dependent tool failures in medical AI agents create a Single-Oracle risk gap that task-level selection cannot close. It formulates tool use as an instance-level RL problem solved via a GRPO-based framework whose rewards combine probabilistic risk minimization with disagreement-aware synergy learning; an entropy-guided sampler upweights high-disagreement instances. Experiments on two tasks across seven medical benchmarks are reported to yield consistent, robust gains over a broad range of baselines, demonstrating the value of synergy-aware tool use.
Significance. If the reported gains survive proper controls for prompt engineering, data leakage, and statistical testing, the work would usefully highlight an under-appreciated source of unreliability in medical agents and supply a concrete, falsifiable mechanism (instance-level synergy via disagreement rewards) for mitigating it. The motivation from the Single-Oracle gap is internally coherent and directly testable.
major comments (2)
- [Abstract] Abstract: the central empirical claim ('consistently achieves robust and stable improvements over a broad range of baselines') supplies no information on the baselines, the evaluation metrics, the number of runs, or any statistical tests. This information is load-bearing for the claim that the method closes the Single-Oracle gap rather than reflecting uncontrolled prompt or sampling effects.
- [Method] The description of the GRPO reward terms and the entropy-guided sampling strategy is given at a high level only; without the explicit reward equations or the precise sampling distribution it is impossible to verify that the learned policy realizes instance-specific synergy rather than simply fitting to average tool performance.
Simulated Author's Rebuttal
We thank the referee for their constructive comments. We address each major comment below and indicate planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central empirical claim ('consistently achieves robust and stable improvements over a broad range of baselines') supplies no information on the baselines, the evaluation metrics, the number of runs, or any statistical tests. This information is load-bearing for the claim that the method closes the Single-Oracle gap rather than reflecting uncontrolled prompt or sampling effects.
Authors: We agree that the abstract would benefit from additional context on the evaluation to support the central claim. In the revised version we will expand the abstract to name the main baseline categories (task-level selection, single-tool oracles, and multi-tool ensembles), the primary metrics (accuracy and Single-Oracle risk gap closure), the number of runs (five independent seeds), and the use of paired statistical tests for significance. Full experimental details remain in Section 4, but this change makes the abstract self-contained for the reported gains. revision: yes
-
Referee: [Method] The description of the GRPO reward terms and the entropy-guided sampling strategy is given at a high level only; without the explicit reward equations or the precise sampling distribution it is impossible to verify that the learned policy realizes instance-specific synergy rather than simply fitting to average tool performance.
Authors: We acknowledge that the current presentation of the reward terms and sampling strategy is high-level. Although the full formulations appear in Sections 3.2 and 3.3, we will revise the main text to insert the explicit equations: the probabilistic risk term R_risk = -E_{y~p(y|x,t)}[loss(y,ŷ)], the disagreement-aware synergy term R_syn = Var_t[p(y|x,t)], and the entropy-guided sampling distribution p(i) ∝ H({p(y|x,t)}). These additions will allow direct verification that the policy targets instance-level disagreement rather than average performance. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper motivates an instance-level RL formulation (GRPO with risk-minimization and disagreement-aware synergy rewards plus entropy-guided sampling) from the observed Single-Oracle risk gap between fixed single-tool performance and ideal per-instance selection. No equations, parameters, or claims in the abstract or described method reduce by construction to fitted inputs, self-definitions, or self-citation chains; the central claims rest on external benchmark experiments that are falsifiable independently of the derivation itself.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
S. Bae, D. Kyung, J. Ryu, E. Cho, G. Lee, S. Kweon, J. Oh, L. Ji, E. Chang, T. Kim, et al. Ehrxqa: A multi-modal question answering dataset for electronic health records with chest x-ray images.Advances in Neural Information Processing Systems, 36:3867–3880, 2023
2023
-
[2]
S. Bai, K. Chen, X. Liu, J. Wang, W. Ge, S. Song, K. Dang, P. Wang, S. Wang, J. Tang, H. Zhong, Y . Zhu, M. Yang, Z. Li, J. Wan, P. Wang, W. Ding, Z. Fu, Y . Xu, J. Ye, X. Zhang, T. Xie, Z. Cheng, H. Zhang, Z. Yang, H. Xu, and J. Lin. Qwen2.5-vl technical report.ArXiv, abs/2502.13923, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
J. Chen, C. Gui, R. Ouyang, A. Gao, S. Chen, G. H. Chen, X. Wang, Z. Cai, K. Ji, X. Wan, et al. Towards injecting medical visual knowledge into multimodal llms at scale. InProceedings of the 2024 conference on empirical methods in natural language processing, pages 7346–7370, 2024
2024
-
[4]
J. Chen, R. Ouyang, A. Gao, S. Chen, G. H. Chen, X. Wang, R. Zhang, Z. Cai, K. Ji, G. Yu, X. Wan, and B. Wang. Huatuogpt-vision, towards injecting medical visual knowledge into multimodal llms at scale, 2024
2024
-
[5]
Z. Chen, M. Varma, J.-B. Delbrouck, M. Paschali, L. Blankemeier, D. Van Veen, J. M. J. Valanarasu, A. Youssef, J. P. Cohen, E. P. Reis, et al. Chexagent: Towards a foundation model for chest x-ray interpretation. InAAAI 2024 Spring Symposium on Clinical Foundation Models, 2024
2024
- [6]
- [7]
-
[8]
J. P. Cohen, J. D. Viviano, P. Bertin, P. Morrison, P. Torabian, M. Guarrera, M. P. Lungren, A. Chaudhari, R. Brooks, M. Hashir, et al. Torchxrayvision: A library of chest x-ray datasets and models. InInternational Conference on Medical Imaging with Deep Learning, pages 231–249. PMLR, 2022
2022
-
[9]
N. Deperrois, H. Matsuo, S. Ruipérez-Campillo, M. Vandenhirtz, S. Laguna, A. Ryser, K. Fu- jimoto, M. Nishio, T. M. Sutter, J. E. V ogt, et al. Radvlm: a multitask conversational vision- language model for radiology.arXiv preprint arXiv:2502.03333, 2025
-
[10]
arXiv preprint arXiv:2502.02673 (2025)
A. Fallahpour, J. Ma, A. Munim, H. Lyu, and B. Wang. Medrax: Medical reasoning agent for chest x-ray.arXiv preprint arXiv:2502.02673, 2025
-
[11]
D. Guo, D. Yang, H. Zhang, J. Song, P. Wang, Q. Zhu, R. Xu, R. Zhang, S. Ma, X. Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025. 10
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Habli, T
I. Habli, T. Lawton, and Z. Porter. Artificial intelligence in health care: accountability and safety.Bulletin of the World Health Organization, 98(4):251, 2020
2020
-
[13]
Irvin, P
J. Irvin, P. Rajpurkar, M. Ko, Y . Yu, S. Ciurea-Ilcus, C. Chute, H. Marklund, B. Haghgoo, R. Ball, K. Shpanskaya, et al. Chexpert: A large chest radiograph dataset with uncertainty labels and expert comparison. InProceedings of the AAAI conference on artificial intelligence, volume 33, pages 590–597, 2019
2019
-
[14]
S. Jiang, Y . Wang, S. Song, T. Hu, C. Zhou, B. Pu, Y . Zhang, Z. Yang, Y . Feng, J. T. Zhou, et al. Hulu-med: A transparent generalist model towards holistic medical vision-language understanding.arXiv preprint arXiv:2510.08668, 2025
-
[15]
B. Jin, H. Zeng, Z. Yue, J. Yoon, S. Arik, D. Wang, H. Zamani, and J. Han. Search-r1: Training llms to reason and leverage search engines with reinforcement learning.arXiv preprint arXiv:2503.09516, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
A. E. Johnson, T. J. Pollard, S. J. Berkowitz, N. R. Greenbaum, M. P. Lungren, C.-y. Deng, R. G. Mark, and S. Horng. Mimic-cxr, a de-identified publicly available database of chest radiographs with free-text reports.Scientific data, 6(1):317, 2019
2019
-
[17]
W. Kwon, Z. Li, S. Zhuang, Y . Sheng, L. Zheng, C. H. Yu, J. Gonzalez, H. Zhang, and I. Stoica. Efficient memory management for large language model serving with pagedattention. In Proceedings of the 29th symposium on operating systems principles, pages 611–626, 2023
2023
-
[18]
M. Li, Y . Zhao, B. Yu, F. Song, H. Li, H. Yu, Z. Li, F. Huang, and Y . Li. Api-bank: A comprehensive benchmark for tool-augmented llms. InProceedings of the 2023 conference on empirical methods in natural language processing, pages 3102–3116, 2023
2023
-
[19]
Majkowska, S
A. Majkowska, S. Mittal, D. F. Steiner, J. J. Reicher, S. M. McKinney, G. E. Duggan, K. Eswaran, P.-H. Cameron Chen, Y . Liu, S. R. Kalidindi, et al. Chest radiograph interpretation with deep learning models: assessment with radiologist-adjudicated reference standards and population- adjusted evaluation.Radiology, 294(2):421–431, 2020
2020
-
[20]
Malmasi, J
S. Malmasi, J. Tetreault, and M. Dras. Oracle and human baselines for native language identification. InProceedings of the tenth workshop on innovative use of NLP for building educational applications, pages 172–178, 2015
2015
-
[21]
H. Q. Nguyen, K. Lam, L. T. Le, H. H. Pham, D. Q. Tran, D. B. Nguyen, D. D. Le, C. M. Pham, H. T. Tong, D. H. Dinh, et al. Vindr-cxr: An open dataset of chest x-rays with radiologist’s annotations.Scientific Data, 9(1):429, 2022
2022
-
[22]
ART: Automatic multi-step reasoning and tool-use for large language models
B. Paranjape, S. Lundberg, S. Singh, H. Hajishirzi, L. Zettlemoyer, and M. T. Ribeiro. Art: Automatic multi-step reasoning and tool-use for large language models.arXiv preprint arXiv:2303.09014, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[23]
J. Park, S. Kim, B. Yoon, J. Hyun, and K. Choi. M4cxr: exploring multitask potentials of multimodal large language models for chest x-ray interpretation.IEEE Transactions on Neural Networks and Learning Systems, 2025
2025
-
[24]
S. G. Patil, T. Zhang, X. Wang, and J. E. Gonzalez. Gorilla: Large language model connected with massive APIs. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024
2024
-
[25]
C. Qian, E. C. Acikgoz, Q. He, H. Wang, X. Chen, D. Hakkani-Tür, G. Tur, and H. Ji. Toolrl: Reward is all tool learning needs.arXiv preprint arXiv:2504.13958, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
CheXNet: Radiologist-Level Pneumonia Detection on Chest X-Rays with Deep Learning
P. Rajpurkar, J. Irvin, K. Zhu, B. Yang, H. Mehta, T. Duan, D. Ding, A. Bagul, C. Langlotz, K. Shpanskaya, et al. Chexnet: Radiologist-level pneumonia detection on chest x-rays with deep learning.arXiv preprint arXiv:1711.05225, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[27]
Schick, J
T. Schick, J. Dwivedi-Yu, R. Dessì, R. Raileanu, M. Lomeli, E. Hambro, L. Zettlemoyer, N. Cancedda, and T. Scialom. Toolformer: Language models can teach themselves to use tools. Advances in neural information processing systems, 36:68539–68551, 2023. 11
2023
-
[28]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[29]
A. Sellergren, S. Kazemzadeh, T. Jaroensri, A. Kiraly, M. Traverse, T. Kohlberger, S. Xu, F. Jamil, C. Hughes, C. Lau, et al. Medgemma technical report.arXiv preprint arXiv:2507.05201, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
Z. Shao, P. Wang, Q. Zhu, R. Xu, J. Song, X. Bi, H. Zhang, M. Zhang, Y . Li, Y . Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[31]
Y . Shen, K. Song, X. Tan, D. Li, W. Lu, and Y . Zhuang. Hugginggpt: Solving ai tasks with chatgpt and its friends in hugging face.Advances in Neural Information Processing Systems, 36:38154–38180, 2023
2023
-
[32]
Sheng, C
G. Sheng, C. Zhang, Z. Ye, X. Wu, W. Zhang, R. Zhang, Y . Peng, H. Lin, and C. Wu. Hybridflow: A flexible and efficient rlhf framework. InProceedings of the Twentieth European Conference on Computer Systems, pages 1279–1297, 2025
2025
-
[33]
G. Shih, C. C. Wu, S. S. Halabi, M. D. Kohli, L. M. Prevedello, T. S. Cook, A. Sharma, J. K. Amorosa, V . Arteaga, M. Galperin-Aizenberg, et al. Augmenting the national institutes of health chest radiograph dataset with expert annotations of possible pneumonia.Radiology: Artificial Intelligence, 1(1):e180041, 2019
2019
-
[34]
E. Tiu, E. Talius, P. Patel, C. P. Langlotz, A. Y . Ng, and P. Rajpurkar. Expert-level detection of pathologies from unannotated chest x-ray images via self-supervised learning.Nature biomedical engineering, 6(12):1399–1406, 2022
2022
-
[35]
W. Wang, Z. Gao, L. Gu, H. Pu, L. Cui, X. Wei, Z. Liu, L. Jing, S. Ye, J. Shao, et al. Internvl3. 5: Advancing open-source multimodal models in versatility, reasoning, and efficiency.arXiv preprint arXiv:2508.18265, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
X. Wang, Y . Peng, L. Lu, Z. Lu, M. Bagheri, and R. M. Summers. Chestx-ray8: Hospital-scale chest x-ray database and benchmarks on weakly-supervised classification and localization of common thorax diseases. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 2097–2106, 2017
2097
- [37]
-
[38]
C. Wu, S. Yin, W. Qi, X. Wang, Z. Tang, and N. Duan. Visual chatgpt: Talking, drawing and editing with visual foundation models.arXiv preprint arXiv:2303.04671, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [39]
-
[40]
W. Xu, H. P. Chan, L. Li, M. Aljunied, R. Yuan, J. Wang, C. Xiao, G. Chen, C. Liu, Z. Li, et al. Lingshu: A generalist foundation model for unified multimodal medical understanding and reasoning.arXiv preprint arXiv:2506.07044, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[41]
ReAct: Synergizing Reasoning and Acting in Language Models
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. Narasimhan, and Y . Cao. React: Synergizing reasoning and acting in language models.arXiv preprint arXiv:2210.03629, 2022. 12 A Theoretical Proof Proof of Proposition 3.1.By definition, the Brier reward is Rbrier(ˆpθ, y) = 1−(ˆpθ −y) 2. Taking expectation over(x, q, y)∼ D, we obtain E(x,q,y)∼D [Rbrier(ˆpθ, y)]...
work page internal anchor Pith review Pith/arXiv arXiv 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.