L2Rec: Towards Dual-View Understanding of LLMs for Personalized Recommendation
Pith reviewed 2026-06-29 16:11 UTC · model grok-4.3
The pith
L2Rec adapts one LLM backbone for personalized recommendation by applying view-specific low-rank perturbations to unify behavioral and semantic signals at the parameter level.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
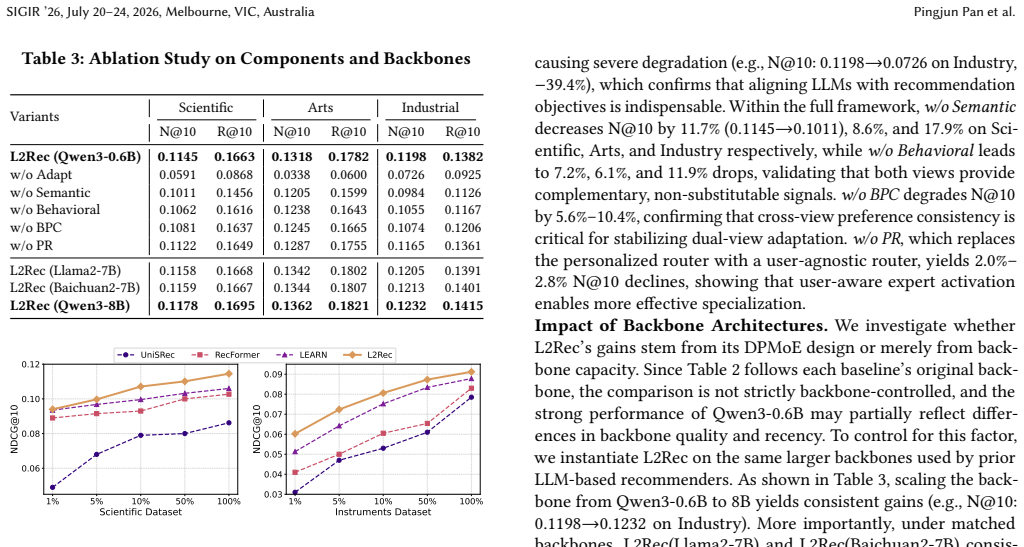
L2Rec unifies behavioral and semantic understanding at the parameter level of LLMs. The same set of Transformer parameters serves as a shared medium for both views when modified by view-specific, personalized low-rank perturbations through a Dual-view Personalized Mixture-of-Experts mechanism; this produces complementary adaptations for each user with minimal representation-level misalignment. An adaptive cross-view fusion module then integrates the dual-view outputs into a unified user preference.
What carries the argument
Dual-view Personalized Mixture-of-Experts (DPMoE) mechanism that injects view-specific low-rank perturbations into the shared Transformer parameters.
If this is right
- The method produces complementary behavioral and semantic adaptations from one backbone rather than requiring separate models.
- An adaptive cross-view fusion step integrates the dual outputs into a single preference representation for downstream recommendation.
- The parameter-level approach avoids the distribution gaps that arise from input-level injection or output-level contrastive alignment.
- Experiments on four datasets show consistent outperformance over prior state-of-the-art baselines.
- Online A/B testing on an industrial platform records gains in key engagement metrics.
Where Pith is reading between the lines
- If low-rank view-specific perturbations remain stable across different LLM sizes, the same technique could be applied to other tasks that require simultaneous handling of two data modalities.
- The design suggests that future work could test whether additional views beyond behavior and semantics can be added by extending the mixture-of-experts routing without retraining the full backbone.
- Because the perturbations are low-rank and user-personalized, the approach may allow efficient per-user adaptation at inference time once the experts are learned.
- A direct comparison of training cost versus separate fine-tuned models would clarify whether the shared-backbone strategy yields measurable efficiency gains.
Load-bearing premise
The same Transformer parameters can serve as a shared medium for both behavioral and semantic views when modified only by view-specific low-rank perturbations without creating new distribution gaps.
What would settle it
An experiment that measures representation misalignment between the behavioral and semantic outputs after DPMoE adaptation and finds the gap larger than in separate-backbone baselines would falsify the central claim.
Figures


read the original abstract
Adapting large language models (LLMs) for personalized recommendation requires aligning their general-purpose capabilities with user-specific preferences while effectively leveraging both behavioral and semantic signals. Existing approaches typically integrate these signals at either the input level (e.g., injecting behavioral embeddings into the token space) or the output level (e.g., contrastive alignment of separate encoders), suffering from distribution gaps or lack of end-to-end task supervision. In this work, we introduce L2Rec, which unifies behavioral and semantic understanding at the parameter level of LLMs. Our key insight is that the same set of Transformer parameters can serve as a shared medium for both views: by applying view-specific, personalized low-rank perturbations via a Dual-view Personalized Mixture-of-Experts (DPMoE) mechanism, L2Rec enables a single LLM backbone to produce complementary behavioral and semantic adaptations for each user with minimal representation-level misalignment. An adaptive cross-view fusion module further integrates the dual-view outputs into a unified user preference. Experiments on four datasets show that L2Rec consistently outperforms state-of-the-art baselines, and online A/B testing on a large-scale industrial platform validates significant improvements in key engagement metrics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces L2Rec for adapting LLMs to personalized recommendation by unifying behavioral and semantic signals at the parameter level. It uses a Dual-view Personalized Mixture-of-Experts (DPMoE) to apply view-specific, personalized low-rank perturbations to a shared Transformer backbone, enabling complementary adaptations with minimal misalignment, followed by an adaptive cross-view fusion module. The method is evaluated on four datasets where it outperforms baselines, and validated with online A/B testing showing improvements in engagement metrics.
Significance. If the results are robust, this work offers a significant advancement in LLM-based recommendation systems by addressing distribution gaps through parameter-level unification rather than input or output level integrations. The DPMoE mechanism for dual-view personalization on a single backbone could influence future designs for efficient multi-view modeling in recsys. The online A/B test adds practical relevance.
major comments (2)
- [Abstract] The central claim that the same Transformer parameters can serve as a shared medium for both behavioral and semantic views via low-rank perturbations without introducing new distribution gaps is load-bearing but rests on an unverified assumption. The skeptic note highlights that if the views differ in higher-order statistics, the shared backbone plus rank-r updates may induce distinct activation distributions that the fusion module cannot fully reconcile.
- [Experiments] The abstract asserts consistent outperformance on four datasets and significant A/B-test gains, but without access to the full experimental setup, baselines, metrics, and any post-hoc choices, the soundness of the empirical claims cannot be assessed. This undermines the ability to verify the central claim.
minor comments (1)
- The abstract mentions 'four datasets' but does not name them; providing names in the abstract would improve clarity.
Simulated Author's Rebuttal
We thank the referee for their review and for noting the potential significance of our work on parameter-level unification of behavioral and semantic views. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] The central claim that the same Transformer parameters can serve as a shared medium for both behavioral and semantic views via low-rank perturbations without introducing new distribution gaps is load-bearing but rests on an unverified assumption. The skeptic note highlights that if the views differ in higher-order statistics, the shared backbone plus rank-r updates may induce distinct activation distributions that the fusion module cannot fully reconcile.
Authors: The DPMoE mechanism applies view-specific low-rank perturbations directly to the shared Transformer parameters, which by design keeps the core representations aligned while enabling complementary adaptations; the adaptive cross-view fusion is then used to integrate outputs and address any residual differences. Empirical results across four datasets show consistent gains over input- and output-level baselines, supporting that the approach does not introduce unresolvable gaps in practice. We can add a targeted analysis of activation statistics in revision if requested. revision: partial
-
Referee: [Experiments] The abstract asserts consistent outperformance on four datasets and significant A/B-test gains, but without access to the full experimental setup, baselines, metrics, and any post-hoc choices, the soundness of the empirical claims cannot be assessed. This undermines the ability to verify the central claim.
Authors: Section 4 of the manuscript provides the complete experimental setup, including dataset descriptions, baseline implementations, metrics, training details, ablation studies, and the online A/B test protocol with engagement metric improvements. These sections contain all information needed to evaluate the claims. revision: no
Circularity Check
No circularity: architectural proposal with external empirical validation
full rationale
The paper presents L2Rec as an architectural modification using DPMoE for view-specific low-rank perturbations on a shared LLM backbone, followed by cross-view fusion. No equations, derivations, or predictions are shown that reduce claimed improvements to quantities defined by the method itself. The abstract and description emphasize empirical outperformance on datasets and A/B tests as external checks, with no self-citation chains or fitted inputs renamed as predictions. The derivation chain is self-contained as a design choice validated externally.
Axiom & Free-Parameter Ledger
invented entities (1)
-
DPMoE mechanism
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Damai Dai, Chengqi Deng, Chenggang Zhao, RX Xu, Huazuo Gao, Deli Chen, Jiashi Li, Wangding Zeng, Xingkai Yu, Yu Wu, et al. 2024. Deepseekmoe: Towards ultimate expert specialization in mixture-of-experts language models.arXiv preprint arXiv:2401.06066(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Yupeng Hou, Shanlei Mu, Wayne Xin Zhao, Yaliang Li, Bolin Ding, and Ji-Rong Wen. 2022. Towards universal sequence representation learning for recommender systems. InProceedings of the 28th ACM SIGKDD Conference on Knowledge Dis- covery and Data Mining. 585–593
2022
-
[3]
Jian Jia, Yipei Wang, Yan Li, Honggang Chen, Xuehan Bai, Zhaocheng Liu, Jian Liang, Quan Chen, Han Li, Peng Jiang, et al. 2025. LEARN: Knowledge Adaptation from Large Language Model to Recommendation for Practical Industrial Appli- cation. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 39. 11861–11869
2025
-
[4]
Wang-Cheng Kang and Julian McAuley. 2018. Self-attentive sequential recom- mendation. In2018 IEEE international conference on data mining (ICDM). IEEE, 197–206
2018
-
[5]
Jiacheng Li, Ming Wang, Jin Li, Jinmiao Fu, Xin Shen, Jingbo Shang, and Julian McAuley. 2023. Text is all you need: Learning language representations for sequential recommendation. InProceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 1258–1267
2023
-
[6]
Jiayi Liao, Sihang Li, Zhengyi Yang, Jiancan Wu, Yancheng Yuan, Xiang Wang, and Xiangnan He. 2024. Llara: Large language-recommendation assistant. In Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval. 1785–1795
2024
-
[7]
Jianghao Lin, Xinyi Dai, Yunjia Xi, Weiwen Liu, Bo Chen, Hao Zhang, Yong Liu, Chuhan Wu, Xiangyang Li, Chenxu Zhu, et al . 2025. How can recommender systems benefit from large language models: A survey.ACM Transactions on Information Systems43, 2 (2025), 1–47
2025
-
[8]
Xubin Ren, Wei Wei, Lianghao Xia, Lixin Su, Suqi Cheng, Junfeng Wang, Dawei Yin, and Chao Huang. 2024. Representation learning with large language models for recommendation. InProceedings of the ACM web conference 2024. 3464–3475
2024
-
[9]
Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, and Jeff Dean. 2017. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer.arXiv preprint arXiv:1701.06538(2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[10]
Fei Sun, Jun Liu, Jian Wu, Changhua Pei, Xiao Lin, Wenwu Ou, and Peng Jiang
-
[11]
InProceedings of the 28th ACM international conference on information and knowledge management
BERT4Rec: Sequential recommendation with bidirectional encoder rep- resentations from transformer. InProceedings of the 28th ACM international conference on information and knowledge management. 1441–1450
-
[12]
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yas- mine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhos- ale, et al. 2023. Llama 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[13]
Wei Wei, Xubin Ren, Jiabin Tang, Qinyong Wang, Lixin Su, Suqi Cheng, Jun- feng Wang, Dawei Yin, and Chao Huang. 2024. Llmrec: Large language models with graph augmentation for recommendation. InProceedings of the 17th ACM international conference on web search and data mining. 806–815
2024
-
[14]
Likang Wu, Zhi Zheng, Zhaopeng Qiu, Hao Wang, Hongchao Gu, Tingjia Shen, Chuan Qin, Chen Zhu, Hengshu Zhu, Qi Liu, et al . 2024. A survey on large language models for recommendation.World Wide Web27, 5 (2024), 60
2024
-
[15]
Yunjia Xi, Weiwen Liu, Jianghao Lin, Xiaoling Cai, Hong Zhu, Jieming Zhu, Bo Chen, Ruiming Tang, Weinan Zhang, and Yong Yu. 2024. Towards open-world recommendation with knowledge augmentation from large language models. In Proceedings of the 18th ACM Conference on Recommender Systems. 12–22
2024
-
[16]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. 2025. Qwen3 technical report.arXiv preprint arXiv:2505.09388(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Aiyuan Yang, Bin Xiao, Bingning Wang, Borong Zhang, Ce Bian, Chao Yin, Chenxu Lv, Da Pan, Dian Wang, Dong Yan, et al. 2023. Baichuan 2: Open large- scale language models.arXiv preprint arXiv:2309.10305(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[18]
Yang Zhang, Fuli Feng, Jizhi Zhang, Keqin Bao, Qifan Wang, and Xiangnan He
-
[19]
Collm: Integrating collaborative embeddings into large language models for recommendation.IEEE Transactions on Knowledge and Data Engineering(2025)
2025
-
[20]
Bowen Zheng, Yupeng Hou, Hongyu Lu, Yu Chen, Wayne Xin Zhao, Ming Chen, and Ji-Rong Wen. 2024. Adapting large language models by integrating collaborative semantics for recommendation. In2024 IEEE 40th International Conference on Data Engineering (ICDE). IEEE, 1435–1448
2024
-
[21]
Kun Zhou, Hui Wang, Wayne Xin Zhao, Yutao Zhu, Sirui Wang, Fuzheng Zhang, Zhongyuan Wang, and Ji-Rong Wen. 2020. S3-rec: Self-supervised learning for se- quential recommendation with mutual information maximization. InProceedings of the 29th ACM international conference on information & knowledge management. 1893–1902
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.