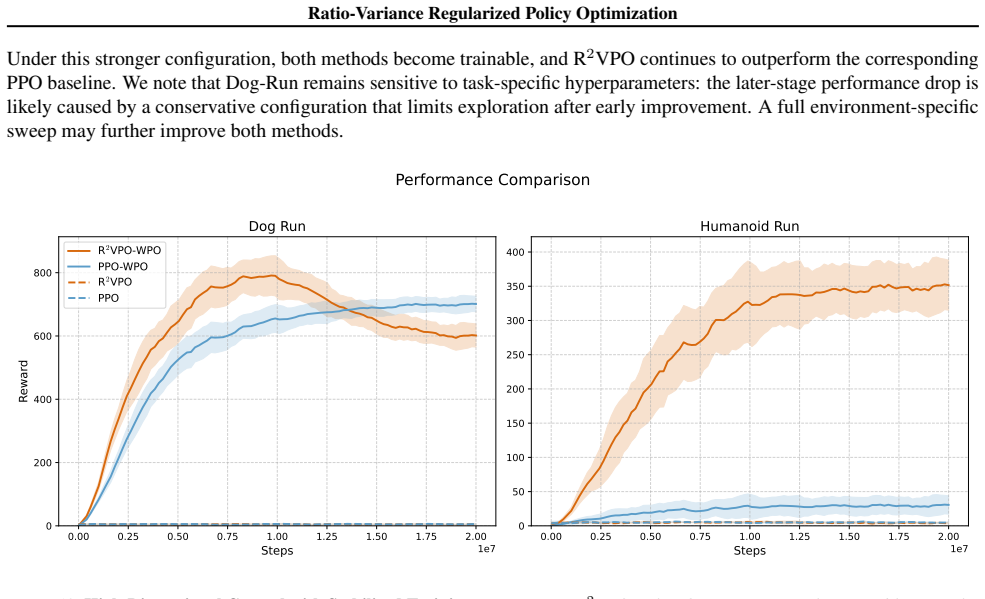
Ratio-Variance Regularized Policy Optimization
Pith reviewed 2026-06-29 19:41 UTC · model grok-4.3
The pith
Constraining policy ratio variance approximates trust-region constraints without hard clipping.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
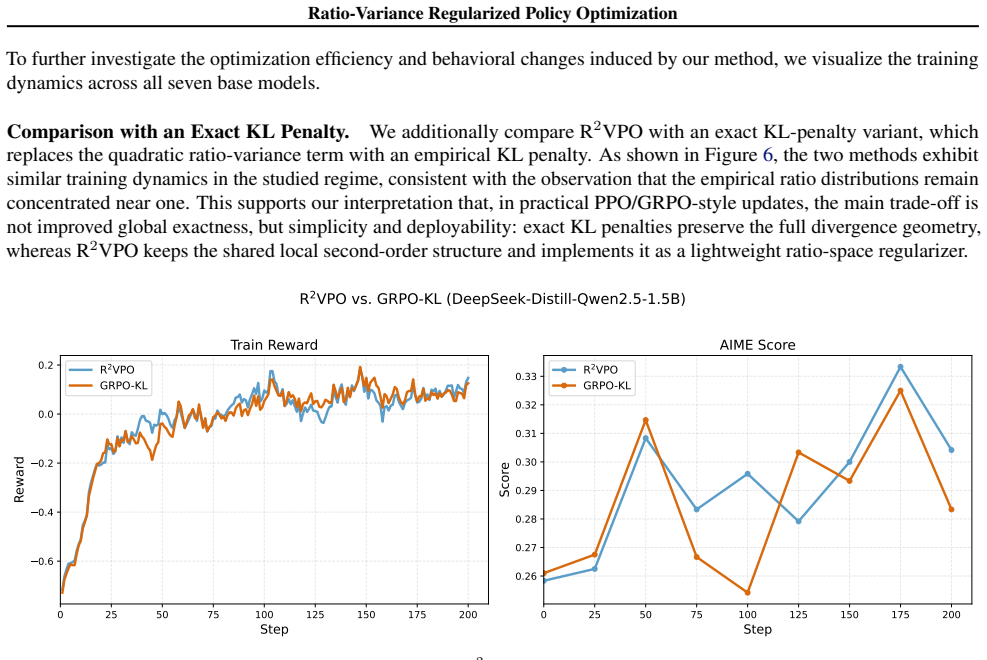
Explicitly constraining the policy ratio variance provides a principled local approximation to trust-region constraints, eliminating the need for binary hard clipping. Implemented via the R²VPO method in a primal-dual optimization framework, the variance penalty acts as a distributional soft brake that preserves critical gradient signals from novel updates while down-weighting stale off-policy data.
What carries the argument
Ratio-variance regularization term enforced by a primal-dual optimization framework that serves as a soft distributional brake on policy updates.
Load-bearing premise
Penalizing variance of the policy ratio will preserve high-return updates while maintaining stability without new instabilities arising from the primal-dual solver or the chosen variance target.
What would settle it
If the method produces training instability or lower returns than clipped PPO specifically in settings with frequent high-divergence high-return updates, the claim that variance constraint reliably approximates trust regions would be falsified.
Figures


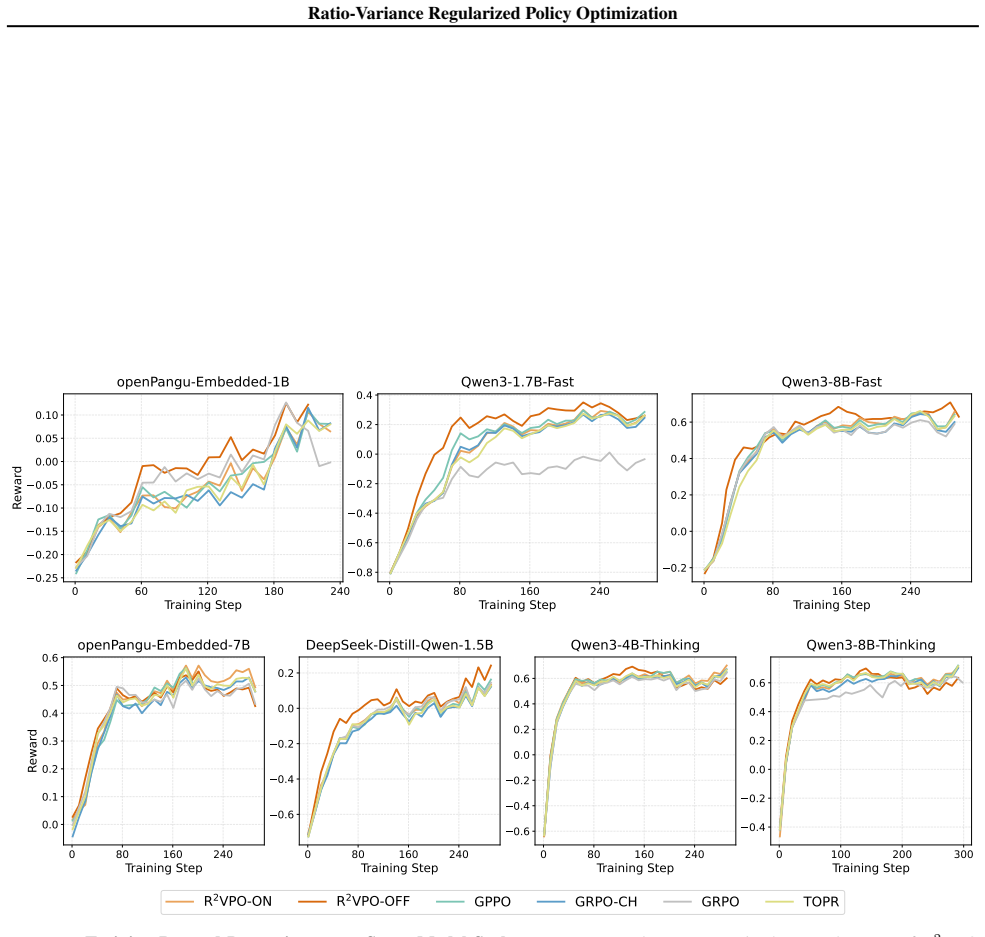
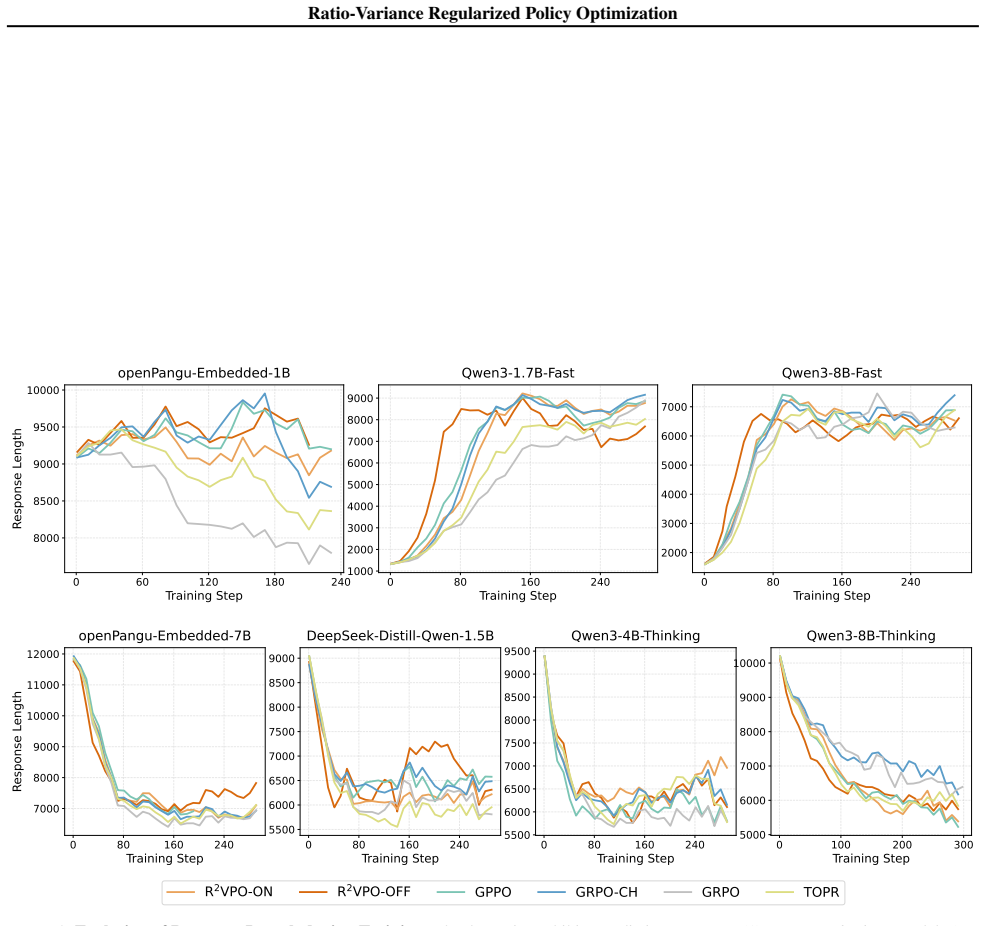
read the original abstract
Standard on-policy reinforcement learning relies on heuristic clipping to enforce trust regions, but this mechanism imposes a severe cost by indiscriminately truncating high-return yet high-divergence updates. We demonstrate that explicitly constraining the policy ratio variance provides a principled local approximation to trust-region constraints, eliminating the need for binary hard clipping. By acting as a distributional ``soft brake'', this approach preserves critical gradient signals from novel discoveries while naturally down-weighting and enabling the reuse of stale, off-policy data. We introduce ${\bf R}^2{\bf VPO}$ (Ratio-Variance Regularized Policy Optimization), which implements this constraint via a primal-dual optimization framework. Extensive evaluations across $7$ LLM scales, spanning both fast and slow reasoning paradigms, and $10$ robotic control tasks demonstrate the generality of the proposed approach. R$^2$VPO achieves substantial performance gains on mathematical reasoning benchmarks, with particularly pronounced improvements on smaller models, while significantly improving sample efficiency. Furthermore, it consistently outperforms PPO baselines in continuous control domains, particularly in sparse-reward and dynamic environments. Together, these findings establish ratio-variance regularization as a principled foundation for stable and data-efficient policy optimization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes R²VPO, a policy optimization algorithm that replaces PPO-style hard clipping with an explicit variance penalty on policy ratios (Var(π_new/π_old)), enforced through a primal-dual optimization framework. This is presented as a soft, distributional approximation to trust-region constraints that preserves high-return gradients while enabling reuse of stale data. The method is evaluated on mathematical reasoning tasks across 7 LLM scales and 10 robotic control tasks, reporting gains in performance and sample efficiency over PPO baselines, especially in sparse-reward settings.
Significance. If the variance penalty can be shown to bound policy divergence comparably to KL or total-variation trust regions without introducing primal-dual instabilities, the approach would supply a more flexible, gradient-preserving alternative to clipping. This could improve data efficiency in on-policy RL for both language and continuous-control domains, particularly where binary clipping discards useful updates.
major comments (2)
- [Abstract] Abstract: the central claim that 'explicitly constraining the policy ratio variance provides a principled local approximation to trust-region constraints' is load-bearing yet unsupported by any derivation, inequality, or limiting argument linking Var(ratio) to KL divergence, total variation, or other standard trust metrics; without this link the elimination of hard clipping cannot be justified as principled.
- [Abstract] Abstract: the primal-dual solver that enforces a fixed variance target is presented without analysis of convergence, oscillation risk, or sensitivity to the chosen target value; the weakest assumption (that this solver will not create new instabilities in sparse-reward or LLM reasoning regimes) therefore remains unexamined.
Simulated Author's Rebuttal
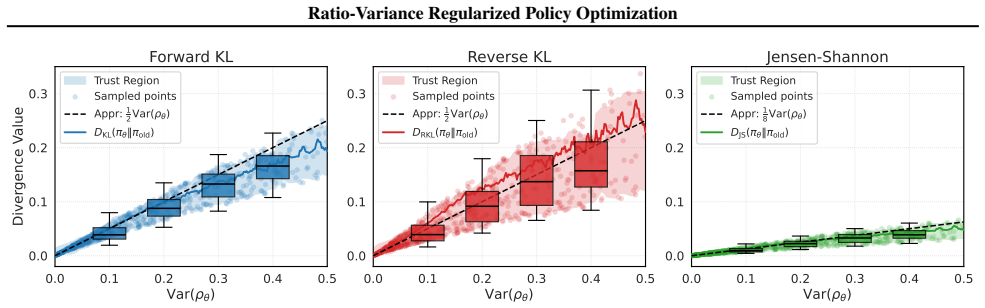
Thank you for the constructive review of our manuscript. We address each major comment below and indicate planned revisions where appropriate.
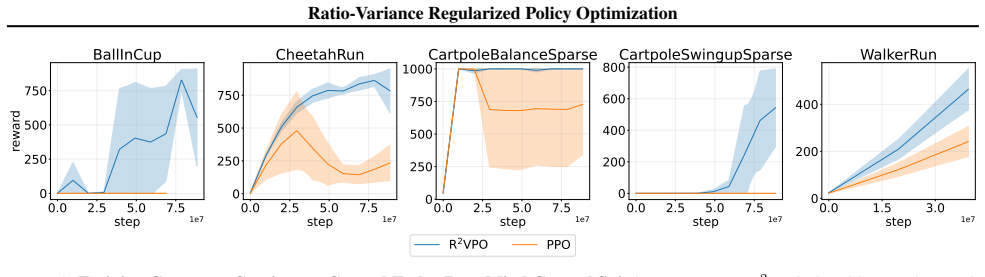
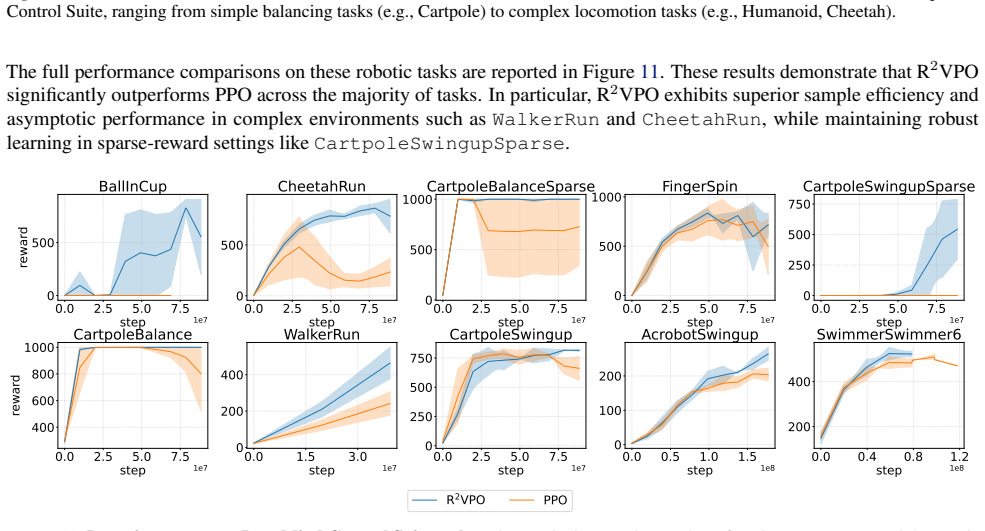
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 'explicitly constraining the policy ratio variance provides a principled local approximation to trust-region constraints' is load-bearing yet unsupported by any derivation, inequality, or limiting argument linking Var(ratio) to KL divergence, total variation, or other standard trust metrics; without this link the elimination of hard clipping cannot be justified as principled.
Authors: The manuscript presents the variance penalty primarily through its empirical behavior as a distributional soft constraint that avoids indiscriminate truncation of high-return updates. We acknowledge that no explicit inequality or limiting argument connecting Var(ratio) to KL or total variation is derived in the current text. In revision we will add a short theoretical subsection providing a local approximation argument under the assumption of small policy steps, relating the second moment of the ratio to a first-order bound on expected divergence. revision: yes
-
Referee: [Abstract] Abstract: the primal-dual solver that enforces a fixed variance target is presented without analysis of convergence, oscillation risk, or sensitivity to the chosen target value; the weakest assumption (that this solver will not create new instabilities in sparse-reward or LLM reasoning regimes) therefore remains unexamined.
Authors: The paper focuses on the practical performance of the primal-dual formulation rather than its theoretical convergence properties. We agree that sensitivity and stability analysis would strengthen the presentation. The revised version will include a dedicated paragraph discussing the observed behavior of the dual variable across the reported domains, together with a brief note on target-value selection and any empirical indications of oscillation. revision: partial
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper presents R²VPO as a primal-dual method that enforces a variance constraint on policy ratios as a soft surrogate for trust regions. The abstract and description frame this as a demonstrated approximation with empirical validation across LLM and robotics tasks. No equations or steps are shown that reduce the core claim (variance penalty as local trust-region proxy) to a fitted parameter renamed as prediction, a self-citation chain, or a definitional equivalence. The variance target and dual variables are part of the proposed algorithm rather than retrofitted to performance metrics. External evaluations on held-out benchmarks provide independent content, satisfying the criteria for a non-circular finding.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Constitutional AI: Harmlessness from AI Feedback
Bai, Y ., Kadavath, S., Kundu, S., Askell, A., Kernion, J., Jones, A., Chen, A., Goldie, A., Mirhoseini, A., McKin- non, C., et al. Constitutional ai: Harmlessness from ai feedback.arXiv preprint arXiv:2212.08073,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Pangu Embedded: An Efficient Dual-system LLM Reasoner with Metacognition,
Chen, H., Wang, Y ., Han, K., Li, D., Li, L., Bi, Z., Li, J., Wang, H., Mi, F., Zhu, M., et al. Pangu embedded: An efficient dual-system llm reasoner with metacognition. arXiv preprint arXiv:2505.22375,
-
[3]
Committees, M. Aime problems and solutions. https://artofproblemsolving.com/wiki/ index.php/AIME_Problems_and_Solutions, 2024,2025. 9 Ratio-Variance Regularized Policy Optimization Engstrom, L., Ilyas, A., Santurkar, S., Tsipras, D., Janoos, F., Rudolph, L., and Madry, A. Implementation matters in deep policy gradients: A case study on ppo and trpo. arXiv...
-
[4]
Emergence of Locomotion Behaviours in Rich Environments
Heess, N., Tb, D., Sriram, S., Lemmon, J., Merel, J., Wayne, G., Tassa, Y ., Erez, T., Wang, Z., Eslami, S., et al. Emer- gence of locomotion behaviours in rich environments. arXiv preprint arXiv:1707.02286,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
SB-TRPO: Towards Safe Reinforcement Learning with Hard Constraints
Kanwar, A., Wagner, D., and Ong, L. Safety-biased policy optimisation: Towards hard-constrained rein- forcement learning via trust regions.arXiv preprint arXiv:2512.23770,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
What can rl bring to vla generalization? an empirical study.arXiv preprint arXiv:2505.19789,
Liu, J., Gao, F., Wei, B., Chen, X., Liao, Q., Wu, Y ., Yu, C., and Wang, Y . What can rl bring to vla generalization? an empirical study.arXiv preprint arXiv:2505.19789,
-
[7]
VLA-RL: Towards Masterful and General Robotic Manipulation with Scalable Reinforcement Learning
Lu, G., Guo, W., Zhang, C., Zhou, Y ., Jiang, H., Gao, Z., Tang, Y ., and Wang, Z. Vla-rl: Towards masterful and general robotic manipulation with scalable reinforcement learning.arXiv preprint arXiv:2505.18719,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Otto, F., Becker, P., Vien, N. A., Ziesche, H. C., and Neu- mann, G. Differentiable trust region layers for deep re- inforcement learning.arXiv preprint arXiv:2101.09207,
-
[9]
Borsa, Jo˜ ao Guilherme Madeira Ara´ ujo, Brendan Daniel Tracey, and Hado van Hasselt
Pfau, D., Davies, I., Borsa, D., Araujo, J. G., Tracey, B., and Van Hasselt, H. Wasserstein policy optimization.arXiv preprint arXiv:2505.00663,
-
[10]
Roux, N. L., Bellemare, M. G., Lebensold, J., Bergeron, A., Greaves, J., Fr ´echette, A., Pelletier, C., Thibodeau- Laufer, E., Toth, S., and Work, S. Tapered off-policy reinforce: Stable and efficient reinforcement learning for llms.arXiv preprint arXiv:2503.14286,
-
[11]
Proximal Policy Optimization Algorithms
10 Ratio-Variance Regularized Policy Optimization Schulman, J., Wolski, F., Dhariwal, P., Radford, A., and Klimov, O. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Bi, X., Zhang, H., Zhang, M., Li, Y ., Wu, Y ., et al. Deepseekmath: Push- ing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
F., Abdolmaleki, A., Springenberg, J
Song, H. F., Abdolmaleki, A., Springenberg, J. T., Clark, A., Soyer, H., Rae, J. W., Noury, S., Ahuja, A., Liu, S., Tirumala, D., et al. V-mpo: On-policy maximum a posteriori policy optimization for discrete and continuous control.arXiv preprint arXiv:1909.12238,
-
[14]
Song, J., He, N., Ding, L., and Zhao, C. Provably conver- gent policy optimization via metric-aware trust region methods.arXiv preprint arXiv:2306.14133,
-
[15]
Su, Z., Pan, L., Bai, X., Liu, D., Dong, G., Huang, J., Hu, W., Zhang, F., Gai, K., and Zhou, G. Klear-reasoner: Advanc- ing reasoning capability via gradient-preserving clipping policy optimization.arXiv preprint arXiv:2508.07629,
-
[16]
Challenging the Boundaries of Reasoning: An Olympiad-Level Math Benchmark for Large Language Models
Sun, H., Min, Y ., Chen, Z., Zhao, W. X., Fang, L., Liu, Z., Wang, Z., and Wen, J.-R. Challenging the boundaries of reasoning: An olympiad-level math benchmark for large language models.arXiv preprint arXiv:2503.21380,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Tassa, Y ., Doron, Y ., Muldal, A., Erez, T., Li, Y ., Casas, D. d. L., Budden, D., Abdolmaleki, A., Merel, J., Lefrancq, A., et al. Deepmind control suite.arXiv preprint arXiv:1801.00690,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Simple policy optimization.arXiv preprint arXiv:2401.16025,
Xie, Z., Zhang, Q., Yang, F., Hutter, M., and Xu, R. Simple policy optimization.arXiv preprint arXiv:2401.16025,
-
[19]
Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388,
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Yu, Q., Zhang, Z., Zhu, R., Yuan, Y ., Zuo, X., Yue, Y ., Dai, W., Fan, T., Liu, G., Liu, L., et al. Dapo: An open-source llm reinforcement learning system at scale.arXiv preprint arXiv:2503.14476,
work page internal anchor Pith review Pith/arXiv arXiv
- [21]
-
[22]
A stochastic trust-region framework for policy optimization.arXiv preprint arXiv:1911.11640,
Zhao, M., Li, Y ., and Wen, Z. A stochastic trust-region framework for policy optimization.arXiv preprint arXiv:1911.11640,
-
[23]
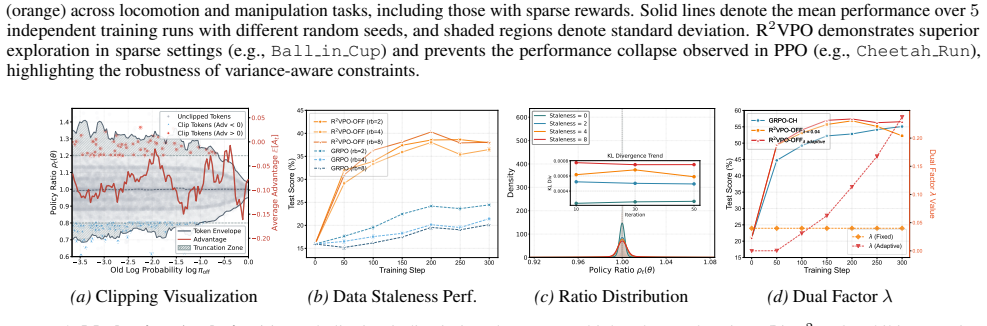
R2VPO utilizes adaptive dual updates for LLMs and fixed dual factors for robotics tasks
Table 3.Unified Hyperparameters.Detailed configuration for LLM mathematical reasoning tasks (Part I) and MuJoCo Playground continuous control tasks (Part II). R2VPO utilizes adaptive dual updates for LLMs and fixed dual factors for robotics tasks. Parameter Value Part I: LLM Mathematical Reasoning Common Training Configuration Optimizer AdamW Learning Rat...
2048
-
[24]
Table 4.Comprehensive Benchmarking Results.We compare R 2VPO against multiple strong baselines (GRPO, GRPO-CH, GPPO, TOPR) across seven model scales.Avgreports the average accuracy, with the relative improvement overBaseshown in parentheses. Method AIME 24 AIME 25 AMC 23 HMMT OlymMath Avg(Gain vs Base) openPangu-Embedded-1B Base 20.83 21.67 60.00 9.59 4.0...
-
[25]
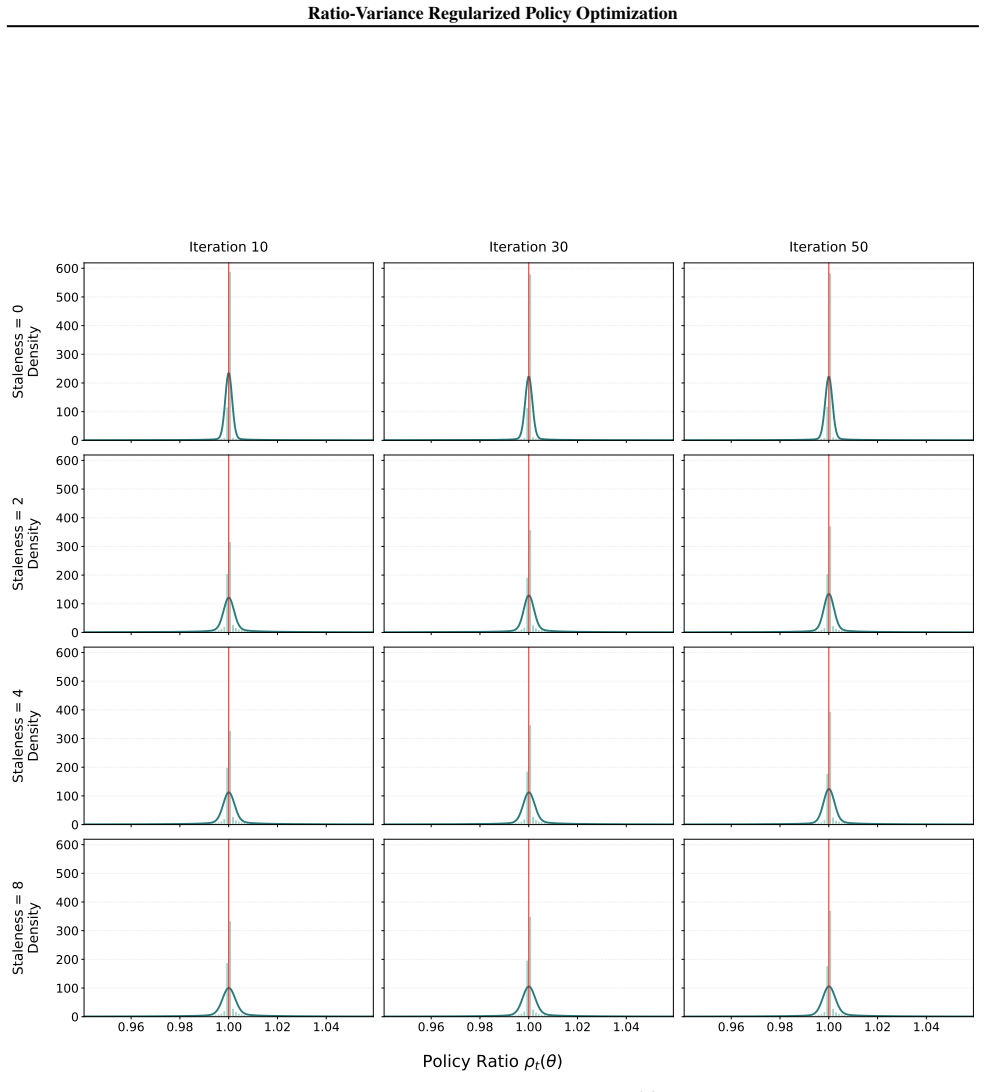
Crucially, the distributions remain tightly concentrated around ρt = 1 (indicated by the red vertical line) even at maximum staleness, providing strong empirical evidence that the optimization trajectory stays within the valid regime of our second-order variance approximation throughout the training process. 16 Ratio-Variance Regularized Policy Optimizati...
2000
-
[26]
These results demonstrate that R2VPO significantly outperforms PPO across the majority of tasks. In particular, R2VPO exhibits superior sample efficiency and asymptotic performance in complex environments such as WalkerRun and CheetahRun, while maintaining robust learning in sparse-reward settings likeCartpoleSwingupSparse. 0.0 2.5 5.0 7.5 step 1e7 0 500r...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.