Neuro-Symbolic Verification of LLM Outputs for Data-Sensitive Domains (extended preprint)
Pith reviewed 2026-06-29 16:57 UTC · model grok-4.3
The pith
A neuro-symbolic architecture detects over 83 percent of structured hallucinations and 72 percent of semantic fabrications in LLM medical reports while reducing creation time by 30 percent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a hybrid verification architecture combining formal symbolic methods with neural semantic analysis supplies complementary guarantees for LLM-generated content: logical reasoning delivers decidable guarantees on structured input requirements via completeness properties, while embedding-based semantic similarity detects contextual hallucinations in outputs where formal methods lack expressiveness, all realized in a parallel actor-based pipeline that sidesteps the distributional biases of prompt-based self-verification, as demonstrated by over 83 percent detection for structured entities, 72 percent for semantic fabrications, and 30 percent reduction in report creation
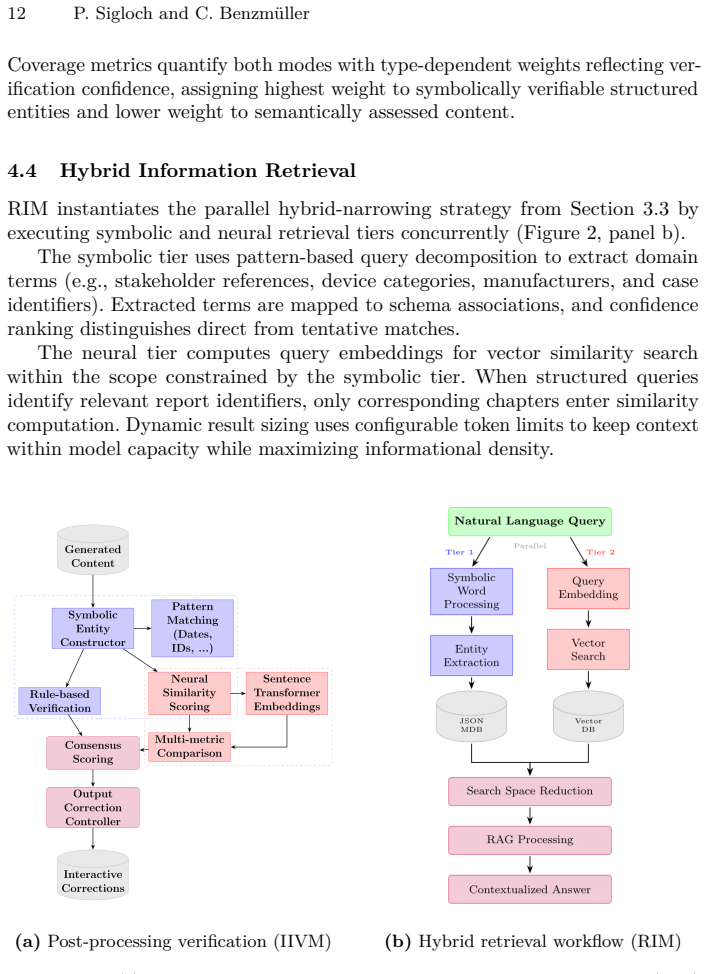
What carries the argument
The hybrid verification architecture that applies logical reasoning to input verification for decidable guarantees and embedding-based semantic similarity to output validation for contextual hallucination detection, implemented as a parallel actor-based pipeline.
If this is right
- Logical reasoning on inputs supplies decidable guarantees on structured requirements through completeness properties.
- Embedding similarity on outputs catches contextual hallucinations beyond the reach of formal methods.
- The actor-based pipeline avoids inheriting distributional biases from prompt-based self-verification.
- Application to the HAIMEDA medical system yields over 83 percent detection of structured entities, 72 percent of semantic fabrications, and 30 percent faster report creation.
Where Pith is reading between the lines
- The separation of logical and semantic checks could extend to other high-stakes reporting tasks such as legal or financial document generation where both precision and context matter.
- The actor-based design implies the architecture may scale to larger volumes of LLM output without sequential bottlenecks.
- Further integration of additional formal logics could enlarge the set of requirements that receive decidable guarantees.
Load-bearing premise
Embedding-based semantic similarity can reliably detect contextual hallucinations that formal methods cannot express.
What would settle it
A controlled test on the HAIMEDA medical reports in which the system flags fewer than 60 percent of known semantic fabrications would falsify the claimed detection performance.
Figures

read the original abstract
LLMs deployed in high-stakes domains face fundamental reliability challenges: hallucinations, inconsistencies, and privacy vulnerabilities introduce unacceptable risks where errors carry legal, financial, or safety consequences. This paper presents a hybrid verification architecture combining formal symbolic methods with neural semantic analysis to provide complementary guarantees for LLM-generated content. This architecture employs logical reasoning for input verification, leveraging completeness properties to provide decidable guarantees on structured requirements. For output validation, embedding-based semantic similarity detects contextual hallucinations where formal methods lack expressiveness. This separation is realized in a parallel, actor-based pipeline, addressing limitations of prompt-based self-verification approaches, which inherit the distributional biases that produce hallucinations. The proposed architecture and type-aware verification method are validated with HAIMEDA, a real-world medical device damage assessment reporting system developed through Action Design Research. Evaluation shows hallucination detection rates of over 83% for structured entities and 72% for semantic fabrications, with a 30% reduction in report creation time, demonstrating that neuro-symbolic architectures can provide principled safeguards for LLM deployment in data-sensitive domains.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a neuro-symbolic hybrid verification architecture for LLM outputs in high-stakes domains. It uses formal symbolic reasoning for input verification (leveraging decidability and completeness) and embedding-based semantic similarity for output validation to detect contextual hallucinations, realized in a parallel actor-based pipeline that avoids the biases of prompt-based self-verification. The system is validated on HAIMEDA, a real-world medical device damage assessment reporting system developed via Action Design Research, with reported results of >83% hallucination detection for structured entities, 72% for semantic fabrications, and 30% reduction in report creation time.
Significance. If the empirical evaluation is sound and reproducible, the work would provide concrete evidence that neuro-symbolic separation of concerns can deliver measurable safeguards against LLM hallucinations in data-sensitive applications such as medical reporting. The architecture's use of complementary formal and neural components, together with the actor-based implementation, addresses a recognized limitation of purely neural verification methods. The HAIMEDA case study offers a practical testbed, but the absence of evaluation details currently prevents assessment of whether the claimed rates demonstrate genuine improvement over baselines.
major comments (2)
- [Abstract / Evaluation] Abstract (and presumably the Evaluation section): The headline performance figures (>83% structured-entity detection, 72% semantic-fabrication detection, 30% time reduction) are presented without any description of the evaluation protocol. No information is supplied on ground-truth construction (how human annotators defined and labeled hallucinations in HAIMEDA reports), baseline systems (plain LLM, prompt-based self-check, or other neuro-symbolic variants), dataset size or construction, statistical tests, or measurement of false positives. These omissions make it impossible to determine whether the actor-based pipeline or the embedding component actually mitigates the distributional biases criticized in the paper.
- [Abstract] Abstract: The central claim that the architecture supplies 'principled safeguards' rests entirely on the reported detection rates. Without the missing protocol details, it is not possible to verify that the 72% semantic-fabrication figure is attributable to embedding cosine similarity rather than post-hoc human review on a non-adversarial set or an under-tuned baseline.
minor comments (1)
- [Abstract] The abstract introduces 'semantic fabrications' and 'type-aware verification method' without concise definitions or pointers to the sections where they are formalized.
Simulated Author's Rebuttal
We thank the referee for the constructive comments highlighting the need for greater transparency in our evaluation protocol. We agree that additional details are required to allow proper assessment of the reported results and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract / Evaluation] Abstract (and presumably the Evaluation section): The headline performance figures (>83% structured-entity detection, 72% semantic-fabrication detection, 30% time reduction) are presented without any description of the evaluation protocol. No information is supplied on ground-truth construction (how human annotators defined and labeled hallucinations in HAIMEDA reports), baseline systems (plain LLM, prompt-based self-check, or other neuro-symbolic variants), dataset size or construction, statistical tests, or measurement of false positives. These omissions make it impossible to determine whether the actor-based pipeline or the embedding component actually mitigates the distributional biases criticized in the paper.
Authors: We agree that the current version lacks sufficient protocol details, which limits evaluation of the claims. In the revised manuscript we will expand both the abstract and Evaluation section to describe: (i) ground-truth construction by two independent medical experts with reported inter-annotator agreement; (ii) the three baselines (plain LLM, prompt-based self-check, and a neuro-symbolic ablation); (iii) dataset size and construction from the HAIMEDA Action Design Research process; (iv) statistical tests performed; and (v) false-positive rates. These additions will directly address whether the actor-based pipeline and embedding component mitigate the distributional biases discussed in the paper. revision: yes
-
Referee: [Abstract] Abstract: The central claim that the architecture supplies 'principled safeguards' rests entirely on the reported detection rates. Without the missing protocol details, it is not possible to verify that the 72% semantic-fabrication figure is attributable to embedding cosine similarity rather than post-hoc human review on a non-adversarial set or an under-tuned baseline.
Authors: We concur that the 72% semantic-fabrication result cannot be properly attributed without protocol information. The revision will include explicit controls showing how the embedding-based detection was isolated from human post-review and will report performance against the prompt-based and ablation baselines on the same HAIMEDA reports. This will substantiate that the observed rate stems from the cosine-similarity component rather than other factors. revision: yes
Circularity Check
No circularity: empirical claims rest on external evaluation of a deployed system
full rationale
The paper presents a hybrid architecture description followed by reported performance numbers (83% structured-entity detection, 72% semantic-fabrication detection, 30% time reduction) obtained from evaluation on the separately developed HAIMEDA medical reporting system. No equations, fitted parameters, or derivations are shown that would make these outcomes equivalent to the architecture inputs by construction. The abstract explicitly frames the results as validation of an independent real-world implementation rather than a tautological restatement of design choices. No self-citation chains or uniqueness theorems are invoked to support the central claims. The evaluation protocol details are unreported in the supplied text, but absence of protocol description is a reproducibility issue, not a circularity reduction. This matches the default expectation that most papers contain no circularity.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Formal symbolic methods leveraging completeness properties provide decidable guarantees on structured requirements.
- domain assumption Embedding-based semantic similarity can detect contextual hallucinations where formal methods lack expressiveness.
Reference graph
Works this paper leans on
- [1]
-
[2]
In: Ph.D
Armstrong, J.L.: Making reliable distributed systems in the presence of software errors. In: Ph.D. Thesis, Royal Institute of Technology, Stockholm, Sweden (2003), https://api.semanticscholar.org/CorpusID:28795665
2003
-
[3]
Artificial Intelligence303, 103649 (2022)
Badreddine, S., d’Avila Garcez, A., Serafini, L., Spranger, M.: Logic tensor networks. Artificial Intelligence303, 103649 (2022). https://doi.org/https://doi.org/10. 1016/j.artint.2021.103649, https://www.sciencedirect.com/science/article/pii/ S0004370221002009
-
[4]
Besold, T.R., d’Avila Garcez, A., Bader, S., Bowman, H., Domingos, P., Hitzler, P., Kühnberger, K.U., Lamb, L.C., Lima, P.M.V., de Penning, L., Pinkas, G., Poon, H., Zaverucha, G.: Neural-symbolic learning and reasoning: A survey and interpretation. In: Hitzler, P., Sarker, M.K. (eds.) Neuro-Symbolic Artificial Intelligence: The State of the Art, Frontier...
-
[5]
Frontiers in Neurorobotics18(2024)
Capitanelli, A., Mastrogiovanni, F.: A framework for neurosymbolic robot action planning using large language models. Frontiers in Neurorobotics18(2024). https: //doi.org/10.3389/fnbot.2024.1342786, https://www.frontiersin.org/journals/ neurorobotics/articles/10.3389/fnbot.2024.1342786
-
[6]
Information and Privacy Commissioner of Ontario, Canada (2009), https://www.ipc.on.ca/wp- content/uploads/resources/7foundationalprinciples.pdf
Cavoukian, A.: Privacy by design: The 7 foundational principles. Information and Privacy Commissioner of Ontario, Canada (2009), https://www.ipc.on.ca/wp- content/uploads/resources/7foundationalprinciples.pdf
2009
-
[7]
O’Reilly Media, Inc., Sebastopol, CA, 1st edn
Cesarini, F., Vinoski, S.: Designing for Scalability with Erlang/OTP. O’Reilly Media, Inc., Sebastopol, CA, 1st edn. (may 2016), first Release: 2016-05-11
2016
-
[8]
IEEE Access 13, 39489–39509 (2025)
Chudasama, Y., Huang, H., Purohit, D., Vidal, M.E.: Toward interpretable hybrid ai: Integrating knowledge graphs and symbolic reasoning in medicine. IEEE Access 13, 39489–39509 (2025). https://doi.org/10.1109/ACCESS.2025.3529133
- [9]
-
[10]
MIT Press, Cambridge, MA, USA (1992)
Dreyfus, H.L.: What computers still can’t do: a critique of artificial reason. MIT Press, Cambridge, MA, USA (1992)
1992
-
[11]
European Parliament and Council of the European Union: Regulation (eu) 2017/745 of the european parliament and of the council of 5 april 2017 on medical devices, amending directive 2001/83/ec, regulation (ec) no 178/2002 and regulation (ec) no 1223/2009 and repealing council directives 90/385/eec and 93/42/eec (text with eea relevance) (2017), http://data...
2017
-
[12]
European Union: Regulation (EU) 2016/679 of the European Parliament and of the Council (General Data Protection Regulation) (2016), http://data.europa.eu/ eli/reg/2016/679/oj, oJ L 119, 4.5.2016
2016
-
[13]
Gao, L., Dai, Z., Pasupat, P., Chen, A., Chaganty, A.T., Fan, Y., Zhao, V., Lao, N., Lee, H., Juan, D.C., Guu, K.: RARR: Researching and revising what language models say, using language models. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers...
-
[14]
Artificial Intelligence Review56(11), 12387–12406 (2023)
Garcez, A.d., Lamb, L.C.: Neurosymbolic AI: The 3rd wave. Artificial Intelligence Review56(11), 12387–12406 (2023). https://doi.org/10.1007/s10462-023-10448-w, https://doi.org/10.1007/s10462-023-10448-w
-
[15]
German Federal Parliament: Medizinprodukterecht-Durchführungsgesetz (mpdg) (2021), https://www.gesetze-im-internet.de/mpdg/, bGBl. I S. 833, as amended by Article 15 of the Act of 20 December 2023 (BGBl. 2023 I Nr. 408)
2021
-
[16]
In: Proceedings of the 3rd International Joint Conference on Artificial Intelligence.p.235–245.IJCAI’73,MorganKaufmannPublishersInc.,SanFrancisco, CA, USA (1973)
Hewitt, C., Bishop, P., Steiger, R.: A universal modular actor formalism for artificial intelligence. In: Proceedings of the 3rd International Joint Conference on Artificial Intelligence.p.235–245.IJCAI’73,MorganKaufmannPublishersInc.,SanFrancisco, CA, USA (1973)
1973
-
[17]
Hu, E.J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., Chen, W.: Lora: Low-rank adaptation of large language models (2021)
2021
- [18]
-
[19]
Large Language Models Cannot Self-Correct Reasoning Yet
Huang, J., Chen, X., Mishra, S., Zheng, H.S., Yu, A.W., Song, X., Zhou, D.: Large language models cannot self-correct reasoning yet (2024), https://arxiv.org/abs/ 2310.01798 18 P. Sigloch and C. Benzmüller
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
The Computer Journal32(2), 98–107 (Jan 1989)
Hughes, J.: Why functional programming matters. The Computer Journal32(2), 98–107 (Jan 1989). https://doi.org/10.1093/comjnl/32.2.98
-
[21]
Ji, Z., Lee, N., Frieske, R., Yu, T., Su, D., Xu, Y., Ishii, E., Bang, Y.J., Madotto, A., Fung, P.: Survey of hallucination in natural language generation. ACM Computing Surveys55(12) (Mar 2023). https://doi.org/10.1145/3571730, https://doi.org/10. 1145/3571730
-
[22]
Kleppmann, M., Wiggins, A., van Hardenberg, P., McGranaghan, M.: Local-first software: you own your data, in spite of the cloud. In: Proceedings of the 2019 ACM SIGPLAN International Symposium on New Ideas, New Paradigms, and Reflections on Programming and Software. pp. 154–178. Onward! 2019, Association for Computing Machinery, New York, NY, USA (2019). ...
-
[23]
In: Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems
Lee, H.P.H., Sarkar, A., Tankelevitch, L., Drosos, I., Rintel, S., Banks, R., Wilson, N.: The impact of generative ai on critical thinking: Self-reported reductions in cognitive effort and confidence effects from a survey of knowledge workers. In: Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems. CHI ’25, Association for Comput...
-
[24]
Li, Z., Huang, J., Naik, M.: Scallop: A language for neurosymbolic programming (2023)
2023
-
[25]
Artificial Intelligence298, 103504 (2021)
Manhaeve, R., Dumančić, S., Kimmig, A., Demeester, T., De Raedt, L.: Neural probabilistic logic programming in deepproblog. Artificial Intelligence298, 103504 (2021). https://doi.org/https://doi.org/10.1016/j.artint.2021.103504, https://www. sciencedirect.com/science/article/pii/S0004370221000552
-
[26]
Pantheon Books, USA (2019)
Marcus, G., Davis, E.: Rebooting AI: Building Artificial Intelligence We Can Trust. Pantheon Books, USA (2019)
2019
- [27]
-
[28]
doi:10.1126/science.adh2586 Office of Institutional Research
Noy, S., Zhang, W.: Experimental evidence on the productivity effects of generative artificial intelligence. Science381(6654), 187–192 (2023). https://doi.org/10.1126/ science.adh2586, https://www.science.org/doi/abs/10.1126/science.adh2586
-
[29]
Parnas, D.L.: On the criteria to be used in decomposing systems into modules. Commun. ACM15(12), 1053–1058 (Dec 1972). https://doi.org/10.1145/361598. 361623, https://doi.org/10.1145/361598.361623
-
[30]
Rebedea, T., Dinu, R., Sreedhar, M.N., Parisien, C., Cohen, J.: NeMo guardrails: A toolkit for controllable and safe LLM applications with programmable rails. In: Feng, Y., Lefever, E. (eds.) Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing: System Demonstrations. pp. 431–445. Association for Computational Linguistics...
-
[31]
Reimers, N., Gurevych, I.: Sentence-BERT: Sentence embeddings using Siamese BERT-networks. In: Inui, K., Jiang, J., Ng, V., Wan, X. (eds.) Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). pp. 3982–3992. Association for Computatio...
-
[32]
Gab- bay, Reiner Hähnle, and Joachim Posegga, eds
de Rijke, M.: Handbook of tableau methods, Marcello D’Agostino, Dov M. Gab- bay, Reiner Hähnle, and Joachim Posegga, eds. Journal of Logic, Language and Information10(4), 518–523 (Dec 2001). https://doi.org/10.1023/A:1017520120752, https://doi.org/10.1023/A:1017520120752 Neuro-Symbolic Verification of LLM Outputs for Data-Sensitive Domains 19
-
[33]
AI Communications34(3), 197–209 (2021)
Sarker, M.K., Zhou, L., Eberhart, A., Hitzler, P.: Neuro-symbolic artificial in- telligence: Current trends. AI Communications34(3), 197–209 (2021). https: //doi.org/10.3233/AIC-210084
-
[34]
In: Proceedings of the SIGCHI Conference on Human Factors in Computing Systems
Sauro, J., Dumas, J.S.: Comparison of three one-question, post-task usability questionnaires. In: Proceedings of the SIGCHI Conference on Human Factors in Computing Systems. pp. 1599–1608. CHI ’09, Association for Computing Machinery, New York, NY, USA (2009). https://doi.org/10.1145/1518701.1518946, https: //doi.org/10.1145/1518701.1518946
-
[35]
MIS Quarterly35(1), 37–56 (2011), http://www.jstor.org/stable/23043488
Sein, M.K., Henfridsson, O., Purao, S., Rossi, M., Lindgren, R.: Action design research. MIS Quarterly35(1), 37–56 (2011), http://www.jstor.org/stable/23043488
-
[36]
Dover, 1 edn
Smullyan, R.M.: First-Order Logic. Dover, 1 edn. (1995)
1995
-
[37]
Wang, X., Wei, J., Schuurmans, D., Le, Q., Chi, E., Narang, S., Chowdhery, A., Zhou, D.: Self-consistency improves chain of thought reasoning in language models (2023), https://arxiv.org/abs/2203.11171
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[38]
Efficient Guided Generation for Large Language Models
Willard, B.T., Louf, R.: Efficient guided generation for large language models (2023), https://arxiv.org/abs/2307.09702 A Appendix Thisappendixprovidesthetechnicaldetailscriticaltoreproducibilitythatsupport the main paper, including classification thresholds, coverage-scoring weights, and inference parameters. Full fine-tuning experiments, analyses, depen...
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.