Recon: Reconstruction-Guided Reasoning Synthesis for User Modeling
Pith reviewed 2026-06-29 18:48 UTC · model grok-4.3
The pith
Reconstruction of actions from reasoning traces identifies better decision paths than conditioning on the action itself.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
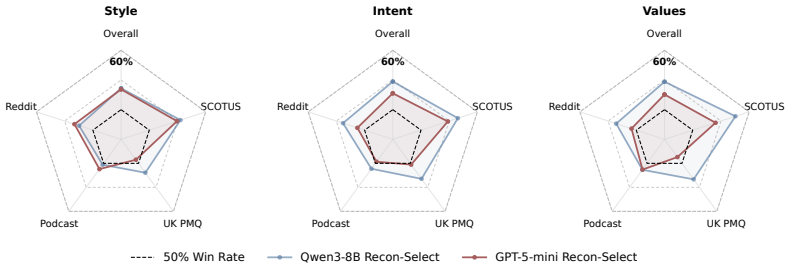
Recon scores candidate reasoning traces by their ability to let a reconstruction model recover the observed action from context alone; traces that enable higher-fidelity reconstruction are retained or used as rewards. This replaces post-hoc rationalization with a predictive criterion and yields reasoning that improves downstream user modeling accuracy while transferring across models.
What carries the argument
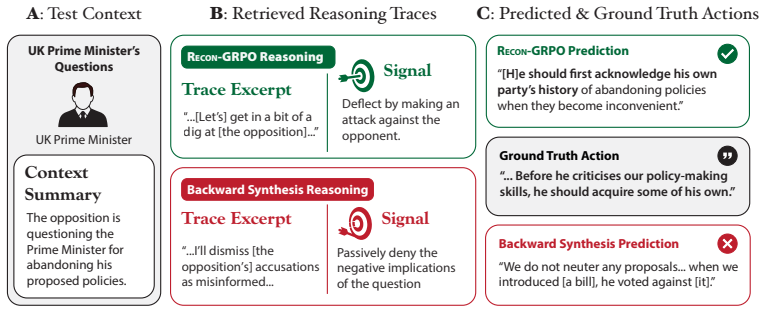
Action reconstruction fidelity, the accuracy with which a model predicts the action given context plus a candidate reasoning trace.
If this is right
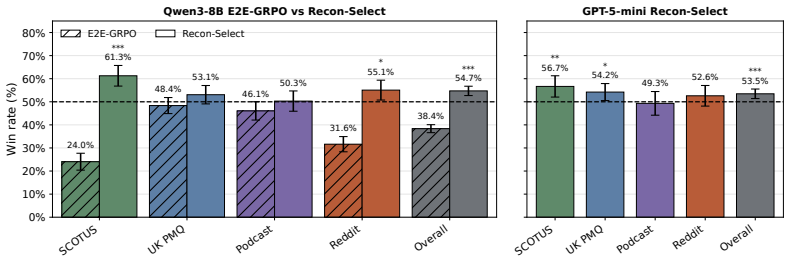
- Recon achieves a 54.7 percent win rate against backward synthesis across four domains.
- Reward-based training with Recon scores reaches up to 70 percent win rate on user modeling tasks.
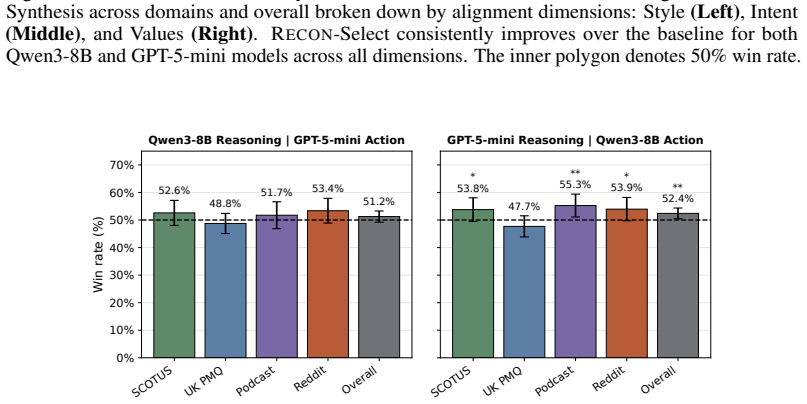
- Reasoning synthesized under Recon transfers to different language models and improves performance beyond the reconstruction model itself.
- Post-hoc rationalization is shown to be insufficient when the goal is to recover causal decision structure.
Where Pith is reading between the lines
- If reconstruction fidelity tracks causal structure, the same scoring could be applied to chain-of-thought traces in non-user-modeling tasks to reduce spurious justifications.
- User simulators built this way might produce more stable long-horizon behavior predictions because the traces are constrained to be predictive rather than merely consistent.
- The approach supplies an automatic filter that could be inserted into any pipeline that generates synthetic reasoning from observed behavior.
- Testing whether Recon traces generalize to new contexts where human decisions are known would directly test whether the method captures transferable decision rules.
Load-bearing premise
That accurate reconstruction of the observed action indicates the trace encodes the true latent decision process rather than incidental correlations.
What would settle it
A controlled experiment in which user models trained on Recon traces are tested on held-out human actions and fail to outperform models trained on post-hoc rationales.
Figures



read the original abstract
User modeling aims to use language models (LMs) to mimic an individual's behavior from a corpus of past context-action pairs (e.g., conversation turns), enabling the simulation of users in settings like behavioral science, human-AI collaboration, and market research. Recent approaches augment these corpora with synthesized reasoning traces, typically generated by conditioning on both context and action. However, such conditioning constitutes post-hoc rationalization rather than reasoning: the trace is guaranteed to justify the action, but may not encode the underlying latent causal decision paths. We propose Recon, which uses action reconstruction to score reasoning traces by their predictive power: given a context and candidate reasoning, a reconstruction model predicts the action, and reconstruction fidelity determines reasoning quality. Across four domains, Recon achieves a 54.7% win rate over Backward Synthesis, a standard post-hoc rationalization baseline. Further, we find that training a reasoning synthesis model with rewards derived from Recon improves downstream user modeling performance, achieving a win rate of up to 70.0% over baselines. We further show that Recon-synthesized reasoning transfers across models, and improves user modeling beyond the reconstruction model. Our work demonstrates that post-hoc rationalization is insufficient for reasoning synthesis, and that useful and interpretable reasoning should naturally elicit the action from the context.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents Recon, a reconstruction-guided method for synthesizing reasoning traces in user modeling tasks. Unlike traditional approaches that generate reasoning conditioned on both context and action (post-hoc rationalization), Recon employs a reconstruction model to evaluate candidate reasoning traces based on their ability to predict the observed action from the context alone. The quality is determined by reconstruction fidelity. The paper reports that Recon achieves a 54.7% win rate against Backward Synthesis across four domains and that incorporating Recon-derived rewards into training a reasoning synthesis model yields up to 70.0% win rate over baselines in downstream user modeling. Additional results show transferability across models and improvements beyond the reconstruction model.
Significance. Should the results and the underlying assumption prove robust, this approach could advance the field of user modeling by providing a more principled way to generate interpretable reasoning that aligns with actual decision-making processes. The distinction drawn between rationalization and predictive reasoning is important, and the reported gains suggest potential for better simulation in applications like behavioral science and human-AI interaction. The cross-model transfer is a positive indicator of generality.
major comments (2)
- [Abstract] Abstract: The abstract states win-rate numbers (54.7% and 70.0%) but provides no information on experimental design, statistical tests, baseline implementations, data splits, or controls. This absence prevents assessment of whether the reported results support the central claims about Recon's superiority.
- [Abstract] Abstract: The core assumption that reconstruction fidelity serves as a valid proxy for the reasoning trace encoding the latent causal decision process (rather than merely capturing correlational patterns) is not directly tested or justified in the provided description. A reconstruction model could achieve high fidelity through shared lexical cues or post-hoc patterns without the reasoning reflecting the actual causal path, which would undermine the claim that this is superior for causal modeling.
minor comments (1)
- [Abstract] The abstract mentions 'four domains' but does not specify what they are; including this would improve clarity for readers.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive feedback. We address each major comment below, proposing revisions to improve clarity and address concerns where feasible.
read point-by-point responses
-
Referee: [Abstract] Abstract: The abstract states win-rate numbers (54.7% and 70.0%) but provides no information on experimental design, statistical tests, baseline implementations, data splits, or controls. This absence prevents assessment of whether the reported results support the central claims about Recon's superiority.
Authors: We agree the abstract is too concise and omits key details needed to contextualize the reported win rates. In the revised version, we will expand the abstract to briefly note the evaluation across four domains, the Backward Synthesis baseline, the use of win-rate metrics from comparative judgments, and that full experimental design, data splits, controls, and statistical details appear in Sections 4 and 5. This will better support the claims while respecting abstract length constraints. revision: yes
-
Referee: [Abstract] Abstract: The core assumption that reconstruction fidelity serves as a valid proxy for the reasoning trace encoding the latent causal decision process (rather than merely capturing correlational patterns) is not directly tested or justified in the provided description. A reconstruction model could achieve high fidelity through shared lexical cues or post-hoc patterns without the reasoning reflecting the actual causal path, which would undermine the claim that this is superior for causal modeling.
Authors: The paper explicitly contrasts post-hoc rationalization with predictive reasoning and positions reconstruction fidelity as a proxy for the latter. While we lack direct causal intervention experiments to rule out lexical or correlational confounds, the downstream gains (up to 70% win rate) and cross-model transfer results provide empirical support that Recon-derived traces improve user modeling beyond what post-hoc methods achieve. We will add a dedicated paragraph in the discussion clarifying this assumption, its predictive (rather than strictly causal) framing, and the supporting evidence, while acknowledging the limitation. revision: partial
Circularity Check
No significant circularity detected
full rationale
The paper's core mechanism uses a separate reconstruction model to score candidate reasoning traces via action prediction fidelity. The abstract and description explicitly state that Recon-synthesized reasoning transfers across models and improves user modeling performance beyond the reconstruction model itself. No equations, self-citations, or definitional steps are present that reduce the claimed prediction or scoring to inputs by construction. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Using large language models to simulate multiple humans and replicate human subject studies
Gati V Aher, Rosa I Arriaga, and Adam Tauman Kalai. Using large language models to simulate multiple humans and replicate human subject studies. InInternational conference on machine learning, 2023
2023
-
[2]
How to Train Your Advisor: Steering Black-Box LLMs with Advisor Models
Parth Asawa, Alan Zhu, Abby O’Neill, Matei Zaharia, Alexandros G Dimakis, and Joseph E Gonzalez. How to train your advisor: Steering black-box LLMs with advisor models.arXiv preprint arXiv:2510.02453, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Aligning language models from user interactions.arXiv preprint arXiv:2603.12273, 2026
Thomas Kleine Buening, Jonas Hübotter, Barna Pásztor, Idan Shenfeld, Giorgia Ramponi, and Andreas Krause. Aligning language models from user interactions.arXiv preprint arXiv:2603.12273, 2026
-
[4]
PAL: Pluralistic alignment framework for learning from heterogeneous preferences
Daiwei Chen, Yi Chen, Aniket Rege, and Ramya Korlakai Vinayak. PAL: Pluralistic alignment framework for learning from heterogeneous preferences. InNeurIPS 2024 Workshop on Behavioral Machine Learning, 2024
2024
-
[5]
A coefficient of agreement for nominal scales.Educational and Psychological Measurement, 1960
Jacob Cohen. A coefficient of agreement for nominal scales.Educational and Psychological Measurement, 1960
1960
-
[6]
TRACE the evidence: Constructing knowledge-grounded reasoning chains for retrieval-augmented generation
Jinyuan Fang, Zaiqiao Meng, and Craig Macdonald. TRACE the evidence: Constructing knowledge-grounded reasoning chains for retrieval-augmented generation. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 8472–8494, 2024
2024
-
[7]
Gemini 3.1 flash-lite preview
Google. Gemini 3.1 flash-lite preview. https://ai.google.dev/gemini-api/docs/ models/gemini-3.1-flash-lite-preview, 2026. Accessed: 2026-05-04
2026
-
[8]
LoRA: Low-rank adaptation of large language models.Iclr, 1(2):3, 2022
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Liang Wang, Weizhu Chen, et al. LoRA: Low-rank adaptation of large language models.Iclr, 1(2):3, 2022
2022
-
[9]
Human subjects research in the age of generative AI: Opportunities and challenges of applying LLM-simulated data to HCI studies
Angel Hsing-Chi Hwang, Michael S Bernstein, S Shyam Sundar, Renwen Zhang, Manoel Horta Ribeiro, Yingdan Lu, Serina Chang, Tongshuang Wu, Aimei Yang, Dmitri Williams, et al. Human subjects research in the age of generative AI: Opportunities and challenges of applying LLM-simulated data to HCI studies. InProceedings of the Extended Abstracts of the CHI Conf...
2025
-
[10]
Joel Jang, Seungone Kim, Bill Yuchen Lin, Yizhong Wang, Jack Hessel, Luke Zettlemoyer, Hannaneh Hajishirzi, Yejin Choi, and Prithviraj Ammanabrolu. Personalized soups: Per- sonalized large language model alignment via post-hoc parameter merging.arXiv preprint arXiv:2310.11564, 2023
-
[11]
Improv- ing language model personas via rationalization with psychological scaffolds
Brihi Joshi, Xiang Ren, Swabha Swayamdipta, Rik Koncel-Kedziorski, and Tim Paek. Improv- ing language model personas via rationalization with psychological scaffolds. InFindings of the Association for Computational Linguistics: EMNLP 2025, 2025
2025
-
[12]
Xinyu Li, Ruiyang Zhou, Zachary C Lipton, and Liu Leqi. Personalized language modeling from personalized human feedback.arXiv preprint arXiv:2402.05133, 2024
-
[13]
Can LLM Agents Simulate Multi-Turn Human Behavior? Evidence from Real Online Customer Behavior Data
Yuxuan Lu, Jing Huang, Yan Han, Bingsheng Yao, Sisong Bei, Jiri Gesi, Yaochen Xie, Qi He, Dakuo Wang, et al. Can LLM agents simulate multi-turn human behavior? evidence from real online customer behavior data.arXiv preprint arXiv:2503.20749, 2025. 10
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
Mihran Miroyan, Rose Niousha, Joseph E Gonzalez, Gireeja Ranade, and Narges Norouzi. Parastudent: Generating and evaluating realistic student code by teaching llms to struggle.arXiv preprint arXiv:2507.12674, 2025
-
[15]
Tarek Naous, Philippe Laban, Wei Xu, and Jennifer Neville. Flipping the dialogue: Training and evaluating user language models.arXiv preprint arXiv:2510.06552, 2025
-
[16]
Telling more than we can know: Verbal reports on mental processes.Psychological review, 84(3):231, 1977
Richard E Nisbett and Timothy D Wilson. Telling more than we can know: Verbal reports on mental processes.Psychological review, 84(3):231, 1977
1977
-
[17]
Oyez.https://www.oyez.org/, 2026
Oyez. Oyez.https://www.oyez.org/, 2026. Accessed: 2026-05-06
2026
-
[18]
Generative agents: Interactive simulacra of human behavior
Joon Sung Park, Joseph O’Brien, Carrie Jun Cai, Meredith Ringel Morris, Percy Liang, and Michael S Bernstein. Generative agents: Interactive simulacra of human behavior. InProceed- ings of the 36th annual acm symposium on user interface software and technology, 2023
2023
-
[19]
LLM Agents Grounded in Self-Reports Enable General-Purpose Simulation of Individuals
Joon Sung Park, Carolyn Q Zou, Aaron Shaw, Benjamin Mako Hill, Carrie Cai, Meredith Ringel Morris, Robb Willer, Percy Liang, and Michael S Bernstein. Generative agent simulations of 1,000 people.arXiv preprint arXiv:2411.10109, 52, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
Per- sonalizing reinforcement learning from human feedback with variational preference learning
Sriyash Poddar, Yanming Wan, Hamish Ivison, Abhishek Gupta, and Natasha Jaques. Per- sonalizing reinforcement learning from human feedback with variational preference learning. Advances in Neural Information Processing Systems, 37:52516–52544, 2024
2024
-
[21]
SynthesizeMe! inducing persona-guided prompts for personalized reward models in LLMs
Michael J Ryan, Omar Shaikh, Aditri Bhagirath, Daniel Frees, William Barr Held, and Diyi Yang. SynthesizeMe! inducing persona-guided prompts for personalized reward models in LLMs. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), pages 8045–8078, 2025
2025
-
[22]
Synthetic prompting: Generating chain-of-thought demonstrations for large language models
Zhihong Shao, Yeyun Gong, Yelong Shen, Minlie Huang, Nan Duan, and Weizhu Chen. Synthetic prompting: Generating chain-of-thought demonstrations for large language models. InInternational conference on machine learning, pages 30706–30775. PMLR, 2023
2023
-
[23]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, et al. DeepSeekMath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaughlin, Aiden Low, AJ Ostrow, Akhila Ananthram, et al. OpenAI GPT-5 system card. arXiv preprint arXiv:2601.03267, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
FSPO: Few-Shot Optimization of Synthetic Preferences Personalizes to Real Users
Anikait Singh, Sheryl Hsu, Kyle Hsu, Eric Mitchell, Stefano Ermon, Tatsunori Hashimoto, Archit Sharma, and Chelsea Finn. FSPO: Few-shot optimization of synthetic preferences personalizes to real users.arXiv preprint arXiv:2502.19312, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
arXiv preprint arXiv:2502.00640 , note =
Shirley Wu, Michel Galley, Baolin Peng, Hao Cheng, Gavin Li, Yao Dou, Weixin Cai, James Zou, Jure Leskovec, and Jianfeng Gao. CollabLLM: From passive responders to active collabo- rators.arXiv preprint arXiv:2502.00640, 2025
-
[27]
Shirley Wu, Evelyn Choi, Arpandeep Khatua, Zhanghan Wang, Joy He-Yueya, Tharindu Cyril Weerasooriya, Wei Wei, Diyi Yang, Jure Leskovec, and James Zou. HumanLM: Simulating users with state alignment beats response imitation.arXiv preprint arXiv:2603.03303, 2026
-
[28]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
STaR: Bootstrapping reasoning with reasoning.Advances in Neural Information Processing Systems, 35:15476–15488, 2022
Eric Zelikman, Yuhuai Wu, Jesse Mu, and Noah Goodman. STaR: Bootstrapping reasoning with reasoning.Advances in Neural Information Processing Systems, 35:15476–15488, 2022
2022
-
[30]
How to Steal Reasoning Without Reasoning Traces
Tingwei Zhang, John X Morris, and Vitaly Shmatikov. How to steal reasoning without reasoning traces.arXiv preprint arXiv:2603.07267, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[31]
(?i)inaudible
Siyan Zhao, John Dang, and Aditya Grover. Group preference optimization: Few-shot alignment of large language models. InNeurIPS 2023 Workshop on Instruction Tuning and Instruction F ollowing, 2023. 11 A Ethics Statement Our work uses real human interaction data for user modeling experiments. The data consists of (i) publicly available transcripts of publi...
2023
-
[32]
Retrieve context-action pairs:{(c i, a∗ i )}k i=1
-
[33]
Obtain Backward Synthesis augmentations:{ˆr b i }k i=1 =f b(c, a∗)
-
[34]
Obtain Backward Synthesis-based action:ˆab T =M a({(ci,ˆrb i , a∗ i )}k i=1}, cT )
-
[35]
Obtain augmentations fromf:{ˆr f i }k i=1 =f(c, a ∗)
-
[36]
Obtainf-based action:ˆa f T =M a({(ci,ˆrf i , a∗ i )}k i=1}, cT )
-
[37]
I">. It is possible you have yet to speak in the conversation, in which case no turns in the Current Context are labeled with <turn author=
Compareˆab T andˆaf T for similarity toa ∗ T . Step 6 is performed using an LM pairwise judge, specifically Gemini-3.1 Flash Lite with the default recommended sampling parameters. We describe the prompt below. D.2 Action Generation Following Equation 1, we provide the action generation model with the augmented retrieved examples and the current test conte...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.