Sampling Data with Chains of Forward-Backward Diffusion Steps
Pith reviewed 2026-06-29 19:15 UTC · model grok-4.3
The pith
U-turn chains from short forward-backward diffusion steps undergo an ergodicity-breaking phase transition on fragmented manifolds.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
U-turn chains are Markov chains obtained by iterating short forward-backward steps of a diffusion model, in which each step proposes a move that remains on the learned data manifold and, paired with a Metropolis-Hastings correction, samples from energy-modified targets. For synthetic languages, minimal U-turn dynamics undergoes an ergodicity-breaking phase transition driven by fragmentation of the data manifold; ergodicity is restored at larger U-turn magnitude. In the non-ergodic regime, low-level features relax faster than high-level ones, an ordering that inverts only at sufficiently large U-turn magnitude. We test these predictions on natural language and natural images.
What carries the argument
U-turn chains, Markov chains from short forward-backward diffusion steps with Metropolis-Hastings correction that stay on the learned manifold to sample energy-modified targets.
If this is right
- Minimal U-turn dynamics undergoes an ergodicity-breaking phase transition driven by fragmentation of the data manifold.
- Ergodicity is restored at larger U-turn magnitude.
- In the non-ergodic regime, low-level features relax faster than high-level ones.
- This ordering inverts only at sufficiently large U-turn magnitude.
- Minimal U-turns relax slowly on natural language and images, especially for high-level features.
Where Pith is reading between the lines
- The results imply that diffusion-based sampling is sensitive to the scale of steps relative to manifold connectivity.
- High-level features in deep models may require larger perturbations to mix efficiently due to manifold structure.
- The phase transition suggests a general mechanism for understanding slow mixing in generative model sampling.
- Extensions could involve tuning U-turn magnitude based on feature hierarchy for better sampling.
Load-bearing premise
The diffusion model accurately captures the data manifold such that short forward-backward steps remain on it and the Metropolis-Hastings correction introduces no additional bias.
What would settle it
An experiment on synthetic languages showing no phase transition in ergodicity or no inversion in relaxation ordering as U-turn magnitude increases would falsify the main claims.
Figures


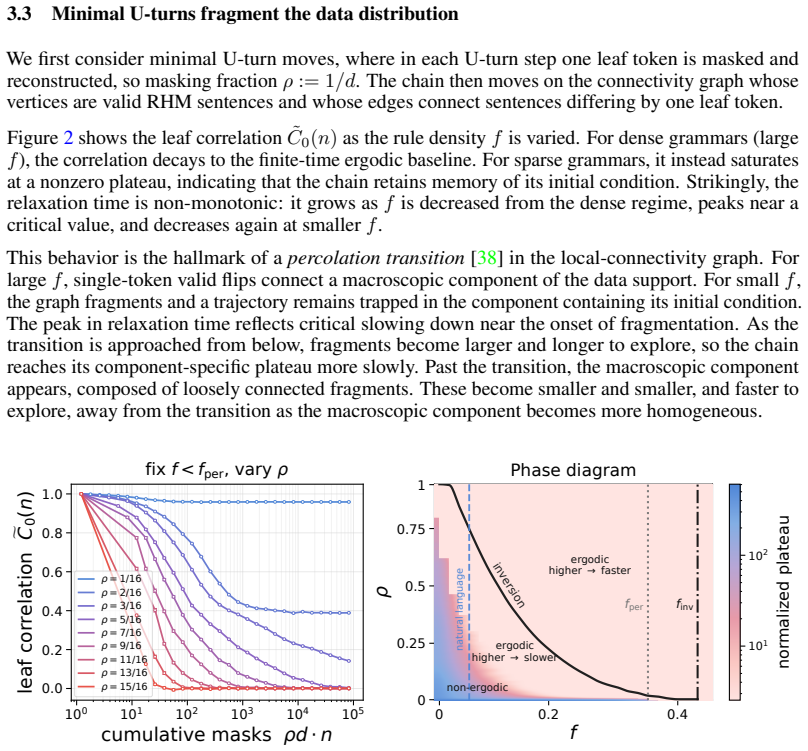
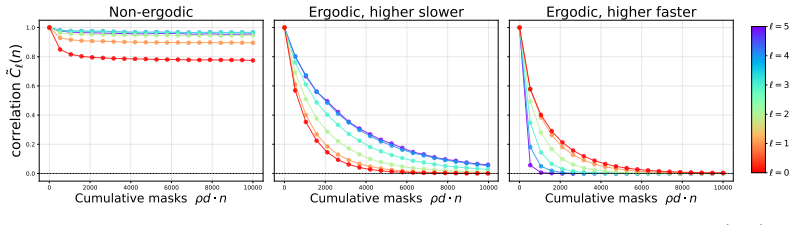

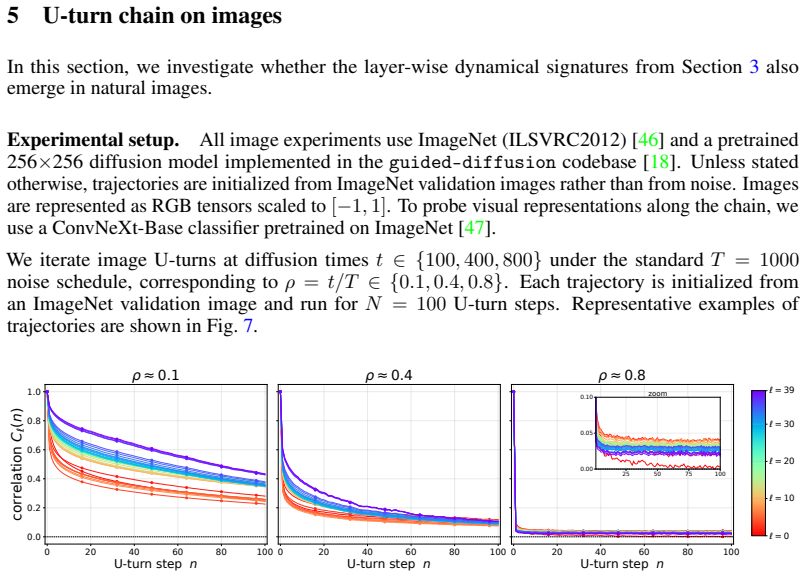

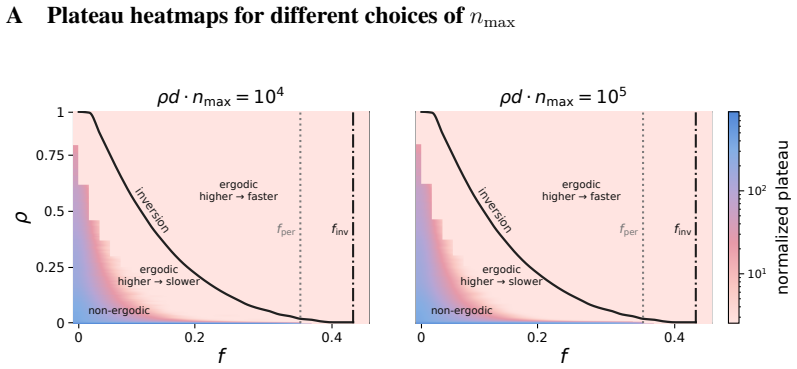








read the original abstract
Sampling from learned high-dimensional distributions is a foundational computational problem. We introduce U-turn chains: Markov chains obtained by iterating short forward-backward steps of a diffusion model, in which each step proposes a move that remains on the learned data manifold and, paired with a Metropolis-Hastings correction, samples from energy-modified targets. For synthetic languages, we show that minimal U-turn dynamics undergoes an ergodicity-breaking phase transition driven by fragmentation of the data manifold; ergodicity is restored at larger U-turn magnitude. In the non-ergodic regime, low-level features relax faster than high-level ones, an ordering that inverts only at sufficiently large U-turn magnitude. We test these predictions on natural language and natural images. In both modalities, minimal U-turns relax slowly, especially for high-level features approximated by deep representations in CNNs or LLMs. The layer-ordering inversion appears only at large noise when mixing is efficient -- signatures consistent with strongly constrained, weakly mixing local dynamics. We discuss the implications of these results for sampling with diffusion models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces U-turn chains: Markov chains formed by iterating short forward-backward steps from a diffusion model, each paired with a Metropolis-Hastings correction to sample from energy-modified targets while remaining on the learned data manifold. For synthetic languages, it claims that minimal U-turn dynamics exhibits an ergodicity-breaking phase transition driven by fragmentation of the data manifold, with ergodicity restored at larger U-turn magnitudes. In the non-ergodic regime, low-level features are reported to relax faster than high-level ones, with this ordering inverting only at sufficiently large U-turn magnitude. The predictions are tested on natural language and natural images, where minimal U-turns show slow relaxation (especially for high-level features from deep CNN or LLM representations), with layer-ordering inversion appearing only at large noise levels where mixing is efficient.
Significance. If the central claims hold after addressing sampling correctness, the work provides a controlled demonstration of ergodicity phase transitions and hierarchical relaxation ordering on learned manifolds, using synthetic languages as a strength for isolating manifold fragmentation effects. This could inform sampling strategies with diffusion models and highlight limitations of local dynamics in high-dimensional generative modeling.
major comments (1)
- [U-turn chain construction and Metropolis-Hastings correction (as described in the abstract and methods)] The phase transition, feature relaxation ordering, and all empirical results on natural data rest on the assumption that MH-corrected U-turn proposals exactly target the intended energy-modified distribution. Manifold approximation errors (unavoidable for learned diffusion models on discrete or high-dimensional data) can render proposals non-reversible or incorrectly normalized, so that the acceptance ratio fails to cancel the correct density ratio and the chain samples a distorted distribution. This makes the reported ergodicity breaking and relaxation inversion potentially artifactual rather than intrinsic to the true manifold. A theoretical analysis or direct empirical validation (e.g., via exact low-dimensional cases or bias diagnostics) of sampling correctness is required.
minor comments (1)
- [Abstract] The abstract states that predictions are tested on natural language and images but provides no detail on the specific relaxation metrics, controls for post-hoc parameter choices, or error bars; these should be added for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review. The concern regarding the exactness of the Metropolis-Hastings correction under manifold approximation is well-taken, and we address it directly below.
read point-by-point responses
-
Referee: [U-turn chain construction and Metropolis-Hastings correction (as described in the abstract and methods)] The phase transition, feature relaxation ordering, and all empirical results on natural data rest on the assumption that MH-corrected U-turn proposals exactly target the intended energy-modified distribution. Manifold approximation errors (unavoidable for learned diffusion models on discrete or high-dimensional data) can render proposals non-reversible or incorrectly normalized, so that the acceptance ratio fails to cancel the correct density ratio and the chain samples a distorted distribution. This makes the reported ergodicity breaking and relaxation inversion potentially artifactual rather than intrinsic to the true manifold. A theoretical analysis or direct empirical validation (e.g., via exact low-dimensional cases or bias diagnostics) of sampling correctness is required.
Authors: We agree that a rigorous check of sampling correctness is essential. In the synthetic-language setting the manifold is generated from an exact, known process and the diffusion model is trained to near-perfect fidelity, so the proposal distribution is reversible with respect to the data measure and the MH ratio is exact; the reported phase transition is therefore intrinsic. For the natural-data experiments we will add (i) a short theoretical paragraph stating the exact-manifold assumption under which the MH correction is valid and (ii) empirical diagnostics (acceptance-rate stability and marginal-moment matching on low-dimensional projections) that quantify residual bias. These additions will be included in the revised manuscript. revision: yes
Circularity Check
No significant circularity detected
full rationale
The provided abstract and summary contain no equations, derivations, or self-citations. Claims about ergodicity-breaking transitions and feature relaxation orderings are presented as empirical simulation results on synthetic languages, with tests on natural data. No steps reduce by construction to fitted parameters, self-definitions, or author-prior ansatzes; the derivation chain is not visible and thus cannot be shown to collapse to inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Robert and George Casella.Monte Carlo Statistical Methods
Christian P. Robert and George Casella.Monte Carlo Statistical Methods. Springer Texts in Statistics. Springer, New York, 2 edition, 2004
2004
-
[2]
M. E. J. Newman and G. T. Barkema.Monte Carlo Methods in Statistical Physics. Oxford University Press, Oxford, 1999
1999
-
[3]
Academic Press, San Diego, 2 edition, 2002
Daan Frenkel and Berend Smit.Understanding Molecular Simulation: From Algorithms to Applications. Academic Press, San Diego, 2 edition, 2002
2002
-
[4]
Rafael C. Bernardi, Marcelo C.R. Melo, and Klaus Schulten. Enhanced sampling tech- niques in molecular dynamics simulations of biological systems.Biochimica et Biophys- ica Acta (BBA) - General Subjects, 1850(5):872–877, 2015. ISSN 0304-4165. doi: https: //doi.org/10.1016/j.bbagen.2014.10.019. URL https://www.sciencedirect.com/science/article/ pii/S030441...
-
[5]
Onuchic, Z Luthey-Schulten, and P.G
J.N. Onuchic, Z Luthey-Schulten, and P.G. Wolynes. Theory of protein folding: the energy landscape perspective.Annual review of physical chemistry, 48, 545–600, 1997. doi: https: //doi.org/10.1146/annurev.physchem.48.1.545
-
[6]
Virasoro.Spin Glass Theory and Beyond: An Introduction to the Replica Method and Its Applications, volume 9 ofWorld Scientific Lecture Notes in Physics
Marc Mézard, Giorgio Parisi, and Miguel A. Virasoro.Spin Glass Theory and Beyond: An Introduction to the Replica Method and Its Applications, volume 9 ofWorld Scientific Lecture Notes in Physics. World Scientific, Singapore, 1987
1987
-
[7]
Levin, Yuval Peres, and Elizabeth L
David A. Levin, Yuval Peres, and Elizabeth L. Wilmer.Markov Chains and Mixing Times. American Mathematical Society, Providence, RI, 2009
2009
-
[8]
Equation of State Calculations by Fast Computing Machines
Nicholas Metropolis, Arianna W. Rosenbluth, Marshall N. Rosenbluth, Augusta H. Teller, and Edward Teller. Equation of state calculations by fast computing machines.The Journal of Chemical Physics, 21(6):1087–1092, 1953. doi: 10.1063/1.1699114
-
[9]
W. K. Hastings. Monte Carlo sampling methods using Markov chains and their applications. Biometrika, 57(1):97–109, 1970. doi: 10.1093/biomet/57.1.97
-
[10]
Bayesian learning via stochastic gradient Langevin dynamics
Max Welling and Yee Whye Teh. Bayesian learning via stochastic gradient Langevin dynamics. InProceedings of the 28th International Conference on Machine Learning (ICML), pages 681–688, 2011
2011
-
[11]
Radford M. Neal. MCMC using Hamiltonian dynamics. In Steve Brooks, Andrew Gelman, Galin L. Jones, and Xiao-Li Meng, editors,Handbook of Markov Chain Monte Carlo, pages 113–162. Chapman & Hall/CRC, Boca Raton, FL, 2011
2011
-
[12]
Robert H. Swendsen and Jian-Sheng Wang. Replica Monte Carlo simulation of spin-glasses. Physical Review Letters, 57(21):2607–2609, 1986. doi: 10.1103/PhysRevLett.57.2607
-
[13]
Earl and Michael W
David J. Earl and Michael W. Deem. Parallel tempering: Theory, applications, and new perspectives.Physical Chemistry Chemical Physics, 7(23):3910–3916, 2005. doi: 10.1039/ B509983H
2005
-
[14]
Weiss, Niru Maheswaranathan, and Surya Ganguli
Jascha Sohl-Dickstein, Eric A. Weiss, Niru Maheswaranathan, and Surya Ganguli. Deep unsupervised learning using nonequilibrium thermodynamics. InInternational Conference on Machine Learning, 2015
2015
-
[15]
Denoising diffusion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. In Advances in Neural Information Processing Systems, 2020. 10
2020
-
[16]
Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole
Yang Song, Jascha Sohl-Dickstein, Diederik P. Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations. In International Conference on Learning Representations (ICLR), 2021
2021
-
[17]
Improved denoising diffusion probabilistic models
Alexander Quinn Nichol and Prafulla Dhariwal. Improved denoising diffusion probabilistic models. InInternational Conference on Machine Learning, pages 8162–8171. PMLR, 2021
2021
-
[18]
Diffusion models beat gans on image synthesis
Prafulla Dhariwal and Alexander Nichol. Diffusion models beat gans on image synthesis. In Advances in Neural Information Processing Systems, 2021
2021
-
[19]
U-turn diffusion.Entropy, 27(4), 2025
Hamidreza Behjoo and Michael Chertkov. U-turn diffusion.Entropy, 27(4), 2025. ISSN 1099-4300. doi: 10.3390/e27040343. URL https://www.mdpi.com/1099-4300/27/4/343
-
[20]
A phase transition in diffusion models reveals the hierarchical nature of data.Proceedings of the National Academy of Sciences, 122(1):e2408799121, 2025
Antonio Sclocchi, Alessandro Favero, and Matthieu Wyart. A phase transition in diffusion models reveals the hierarchical nature of data.Proceedings of the National Academy of Sciences, 122(1):e2408799121, 2025
2025
-
[21]
The MIT Press, 50 edition, 1965
Noam Chomsky.Aspects of the Theory of Syntax. The MIT Press, 50 edition, 1965. ISBN 9780262527408. URL http://www.jstor.org/stable/j.ctt17kk81z
1965
-
[22]
Formal language theory: refining the chomsky hierarchy
Gerhard Jäger and James Rogers. Formal language theory: refining the chomsky hierarchy. Philosophical Transactions of the Royal Society B: Biological Sciences, 367(1598):1956–1970, 2012
1956
-
[23]
JHU Press, 1996
Ulf Grenander.Elements of pattern theory. JHU Press, 1996
1996
-
[24]
Deep Learning and Hierarchal Generative Models
Elchanan Mossel. Deep learning and hierarchal generative models, 2018. URL https://arxiv. org/abs/1612.09057
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[25]
Why and when can deep-but not shallow-networks avoid the curse of dimensionality: a review
Tomaso Poggio, Hrushikesh Mhaskar, Lorenzo Rosasco, Brando Miranda, and Qianli Liao. Why and when can deep-but not shallow-networks avoid the curse of dimensionality: a review. International Journal of Automation and Computing, 14(5):503–519, 2017
2017
-
[26]
A Provably Correct Algorithm for Deep Learning that Actually Works
Eran Malach and Shai Shalev-Shwartz. A provably correct algorithm for deep learning that actually works, 2018. URL https://arxiv.org/abs/1803.09522
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[27]
Nonparametric regression using deep neural networks with relu activation function.The Annals of Statistics, 48(4):1875–1897, 2020
Johannes Schmidt-Hieber. Nonparametric regression using deep neural networks with relu activation function.The Annals of Statistics, 48(4):1875–1897, 2020
2020
-
[28]
Malach and S
E. Malach and S. Shalev-Shwartz. The implications of local correlation on learning some deep functions. InAdvances in Neural Information Processing Systems, volume 33, pages 1322–1332, 2020. URL https://proceedings.neurips.cc/paper_files/paper/2020/file/ 0e4ceef65add6cf21c0f3f9da53b71c0-Paper.pdf
2020
-
[29]
Tomasini, Alessandro Favero, and Matthieu Wyart
Francesco Cagnetta, Leonardo Petrini, Umberto M. Tomasini, Alessandro Favero, and Matthieu Wyart. How deep neural networks learn compositional data: The random hierarchy model. Phys. Rev. X, 14:031001, Jul 2024. doi: 10.1103/PhysRevX.14.031001. URL https://link.aps. org/doi/10.1103/PhysRevX.14.031001
-
[30]
Towards a theory of how the structure of language is acquired by deep neural networks.Advances in Neural Information Processing Systems, 37: 83119–83163, 2024
Francesco Cagnetta and Matthieu Wyart. Towards a theory of how the structure of language is acquired by deep neural networks.Advances in Neural Information Processing Systems, 37: 83119–83163, 2024
2024
-
[31]
Francesco Cagnetta, Allan Raventós, Surya Ganguli, and Matthieu Wyart. Deriving neural scaling laws from the statistics of natural language.arXiv preprint arXiv:2602.07488, 2026
-
[32]
Learning curves theory for hi- erarchically compositional data with power-law distributed features
Francesco Cagnetta, Hyunmo Kang, and Matthieu Wyart. Learning curves theory for hi- erarchically compositional data with power-law distributed features. InProceedings of the 42nd International Conference on Machine Learning, volume 267 ofProceedings of Machine Learning Research, pages 6149–6164. PMLR, 2025. URL https://proceedings.mlr.press/v267/ cagnetta25a.html
2025
-
[33]
Probing the latent hierarchical structure of data via diffusion models
Antonio Sclocchi, Alessandro Favero, Noam Itzhak Levi, and Matthieu Wyart. Probing the latent hierarchical structure of data via diffusion models. InThe Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum?id=0GzqVqCKns. 11
2025
-
[34]
Simoncelli
Florentin Guth, Zahra Kadkhodaie, and Eero P. Simoncelli. Learning normalized image densities via dual score matching. InAdvances in Neural Information Processing Systems, 2025
2025
-
[35]
N.T. Hunt-Smith, W. Melnitchouk, F. Ringer, N. Sato, A.W. Thomas, and M.J. White. Acceler- ating markov chain monte carlo sampling with diffusion models.Computer Physics Communi- cations, 296:109059, 2024. ISSN 0010-4655. doi: https://doi.org/10.1016/j.cpc.2023.109059. URL https://www.sciencedirect.com/science/article/pii/S0010465523004046
-
[36]
Springer, January
Grzegorz Rozenberg and Arto Salomaa.Handbook of Formal Languages. Springer, January
-
[37]
doi: 10.1007/978-3-642-59126-6
-
[38]
Oxford University Press, 2009
Marc Mezard and Andrea Montanari.Information, physics, and computation. Oxford University Press, 2009
2009
-
[39]
Taylor & Francis, London, 2 edition, 1994
Dietrich Stauffer and Ammon Aharony.Introduction to Percolation Theory. Taylor & Francis, London, 2 edition, 1994
1994
-
[40]
Marginal stability in structural, spin, and electron glasses
Markus Müller and Matthieu Wyart. Marginal stability in structural, spin, and electron glasses. Annu. Rev. Condens. Matter Phys., 6(1):177–200, 2015
2015
-
[41]
Dolma: an open corpus of three trillion tokens for language model pretraining research
Luca Soldaini, Rodney Kinney, Akshita Bhagia, Dustin Schwenk, David Atkinson, Russell Authur, Ben Bogin, Khyathi Chandu, Jennifer Dumas, Yanai Elazar, Valentin Hofmann, Ananya Jha, Sachin Kumar, Li Lucy, Xinxi Lyu, Nathan Lambert, Ian Magnusson, Jacob Morrison, Niklas Muennighoff, Aakanksha Naik, Crystal Nam, Matthew Peters, Abhilasha Ravichander, Kyle Ri...
-
[42]
Llada-moe: A sparse moe diffusion language model.arXiv preprint arXiv:2509.24389, 2025
Fengqi Zhu, Zebin You, Yipeng Xing, Zenan Huang, Lin Liu, Yihong Zhuang, Guoshan Lu, Kangyu Wang, Xudong Wang, Lanning Wei, Hongrui Guo, Jiaqi Hu, Wentao Ye, Tieyuan Chen, Chenchen Li, Chengfu Tang, Haibo Feng, Jun Hu, Jun Zhou, Xiaolu Zhang, Zhenzhong Lan, Junbo Zhao, Da Zheng, Chongxuan Li, Jianguo Li, and Ji-Rong Wen. Llada-moe: A sparse moe diffusion ...
-
[43]
Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, Lélio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, and William El Sayed. Mistral 7b, 2023. URL https://arxi...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[44]
Brains and algorithms partially converge in natural language processing.Communications Biology, 5(1):134, 2022
Charlotte Caucheteux and Jean-Rémi King. Brains and algorithms partially converge in natural language processing.Communications Biology, 5(1):134, 2022. doi: 10.1038/ s42003-022-03036-1
2022
-
[45]
Charlotte Caucheteux, Alexandre Gramfort, and Jean-Rémi King. Deep language algorithms predict semantic comprehension from brain activity.Scientific Reports, 12(1):16327, 2022. doi: 10.1038/s41598-022-20460-9
-
[46]
Emergence of a high-dimensional abstraction phase in language transformers
Emily Cheng, Diego Doimo, Corentin Kervadec, Iuri Macocco, Lei Yu, Alessandro Laio, and Marco Baroni. Emergence of a high-dimensional abstraction phase in language transformers. InThe Thirteenth International Conference on Learning Representations, 2025. URL https: //openreview.net/forum?id=0fD3iIBhlV
2025
-
[47]
Imagenet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2009. 12
2009
-
[48]
A convnet for the 2020s
Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, and Saining Xie. A convnet for the 2020s. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022
2022
-
[49]
Conneau, G
A. Conneau, G. Kruszewski, G. Lample, L. Barrault, and M. Baroni. What you can cram into a single $&!#* vector: Probing sentence embeddings for linguistic properties. In Iryna Gurevych and Yusuke Miyao, editors,Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 2126–2136, Melbourne, Australia,
-
[50]
Association for Computational Linguistics. doi: 10.18653/v1/P18-1198. URL https: //aclanthology.org/P18-1198
-
[51]
I. Tenney, D. Das, and E. Pavlick. BERT rediscovers the classical NLP pipeline. In Anna Korhonen, David Traum, and Lluís Màrquez, editors,Proceedings of the 57th An- nual Meeting of the Association for Computational Linguistics, pages 4593–4601, Florence, Italy, 2019. Association for Computational Linguistics. doi: 10.18653/v1/P19-1452. URL https://aclant...
-
[52]
D Manning, K
C. D Manning, K. Clark, J. Hewitt, U. Khandelwal, and O. Levy. Emergent linguistic structure in artificial neural networks trained by self-supervision.Proceedings of the National Academy of Sciences, 117(48):30046–30054, 2020
2020
-
[53]
Schrödinger’s tree—on syntax and neural language models
Artur Kulmizev and Joakim Nivre. Schrödinger’s tree—on syntax and neural language models. Frontiers in Artificial Intelligence, 5:796788, 2022
2022
-
[54]
Deep networks learn to parse uniform-depth context-free languages from local statistics
Jack T. Parley, Francesco Cagnetta, and Matthieu Wyart. Deep networks learn to parse uniform- depth context-free languages from local statistics, 2026. URL https://arxiv.org/abs/2602.06065
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[55]
Physics of language models: Part 1, learning hier- archical language structures.Transactions on Machine Learning Research, 2025
Zeyuan Allen-Zhu and Yuanzhi Li. Physics of language models: Part 1, learning hier- archical language structures.Transactions on Machine Learning Research, 2025. URL https://openreview.net/forum?id=mPQKyzkA1K
2025
-
[56]
Haoyu Zhao, Abhishek Panigrahi, Rong Ge, and Sanjeev Arora. Do transformers parse while predicting the masked word? In Houda Bouamor, Juan Pino, and Kalika Bali, editors, Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 16513–16542, Singapore, December 2023. Association for Computational Linguistics. doi: 10.18...
-
[57]
How transformers learn structured data: Insights from hierarchical filtering
Jerome Garnier-Brun, Marc Mézard, Emanuele Moscato, and Luca Saglietti. How transformers learn structured data: Insights from hierarchical filtering. InInternational Conference on Machine Learning (ICML), 2025. arXiv:2408.15138
-
[58]
E. DeGiuli. Random language model.Phys. Rev. Lett., 122:128301, Mar 2019. doi: 10.1103/ PhysRevLett.122.128301. URL https://link.aps.org/doi/10.1103/PhysRevLett.122.128301
-
[59]
Unraveling Syntax: Language Modeling and the Substructure of Grammars
Laura Ying Schulz, Daniel Mitropolsky, and Tomaso Poggio. Unraveling syntax: How lan- guage models learn context-free grammars, 2025. URL https://arxiv.org/abs/2510.02524. arXiv:2510.02524
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[60]
Dream 7B: Diffusion Large Language Models
Jiacheng Ye, Zhihui Xie, Lin Zheng, Jiahui Gao, Zirui Wu, Xin Jiang, Zhenguo Li, and Lingpeng Kong. Dream 7b: Diffusion large language models.arXiv preprint arXiv:2508.15487, 2025. 13 A Plateau heatmaps for different choices ofn max 0 0.2 0.4 f 0 0.25 0.5 0.75 1 ρ ρd ⋅ nmax = 104 fper finv non-ergodic ergodic higher → slower ergodic higher → faster invers...
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.