On the Hidden Costs of Counterfactual Knowledge Training in LLM Unlearning
Pith reviewed 2026-06-29 17:51 UTC · model grok-4.3
The pith
Counterfactual tuning underperforms other LLM unlearning methods due to knowledge conflicts and hallucination spillover.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
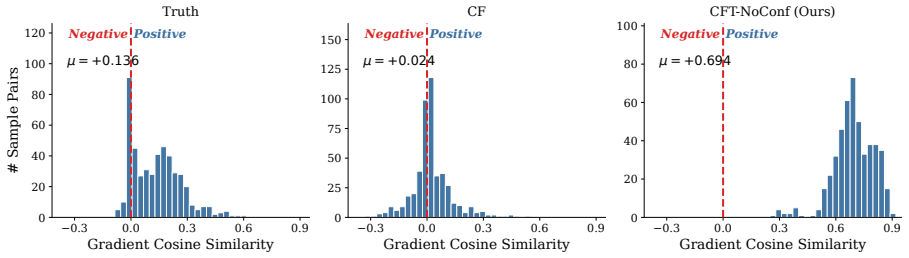
Counterfactual tuning underperforms other unlearning paradigms because mutual inconsistencies within counterfactual corpora induce conflicting gradients that disrupt parameter optimization, and because fitting false targets instills a persistent fabrication bias that inflates hallucination rates on unrelated domains. The work introduces RWKU+ with novel trade-off metrics and gradient-level diagnostic tools to diagnose these issues and discusses the limitations and overhead of the paradigm.
What carries the argument
Knowledge conflict from inconsistent counterfactual corpora and hallucination spillover from fitting false targets, diagnosed via RWKU+ benchmark and gradient diagnostics.
If this is right
- Conflicting gradients from inconsistent data disrupt optimization in counterfactual tuning.
- Hallucination rates increase on domains unrelated to the unlearned content.
- Trade-off metrics in RWKU+ reveal performance gaps not captured by standard evaluations.
- Gradient-level tools help isolate the effects of knowledge conflict.
- The paradigm carries limitations and overhead that other unlearning methods may avoid.
Where Pith is reading between the lines
- If these pitfalls dominate, then developing consistent counterfactual corpora could improve the method.
- Gradient diagnostics might reveal similar issues in other unlearning techniques.
- Models trained this way may require additional calibration to reduce fabrication bias in general use.
- Future benchmarks should incorporate checks for spillover effects to ensure clean unlearning.
Load-bearing premise
That knowledge conflict and hallucination spillover are the primary causes of underperformance rather than other factors like model scale or data choices, and that RWKU+ isolates these effects accurately.
What would settle it
A controlled experiment where counterfactual data is made fully consistent and hallucination rates on unrelated domains remain unchanged after training.
Figures

read the original abstract
Counterfactual tuning (CFT) has emerged as a promising paradigm for Large Language Model (LLM) unlearning by training models to generate alternative fictitious knowledge in place of undesired content. However, in this work, we find that this paradigm still underperforms other paradigms in some aspects, and identify two previously overlooked pitfalls underlying this gap: (1) knowledge conflict, where mutual inconsistencies within counterfactual corpora induce conflicting gradients that disrupt parameter optimization, and (2) hallucination spillover, where fitting false targets instills a persistent fabrication bias, inflating hallucination rates on unrelated domains. To systematically diagnose these issues, we introduce RWKU+, an extended benchmark equipped with novel trade-off metrics and gradient-level diagnostic tools. Our work further discusses the limitations and overhead of the paradigm, aiming to provide insights and actionable guidance for more rigorous LLM unlearning research.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that counterfactual tuning (CFT) for LLM unlearning underperforms other paradigms due to two overlooked pitfalls—knowledge conflict arising from mutual inconsistencies in counterfactual corpora that produce conflicting gradients, and hallucination spillover where fitting false targets induces a persistent fabrication bias on unrelated domains—and introduces the RWKU+ benchmark with novel trade-off metrics and gradient-level diagnostic tools to diagnose these issues while discussing the paradigm's limitations and overhead.
Significance. If the empirical results hold, the work supplies actionable diagnostics and a new benchmark that could improve evaluation standards in LLM unlearning research. The explicit identification of gradient conflict and spillover effects, together with the provision of RWKU+ and associated tools, represents a concrete contribution that future studies can build upon or refute.
major comments (2)
- [Abstract and §4 (RWKU+ benchmark and gradient diagnostics)] The central claim that knowledge conflict and hallucination spillover are the primary drivers of CFT underperformance (abstract and §4) rests on the RWKU+ benchmark isolating these effects; however, the manuscript does not report controls for model scale or data-construction choices that could confound the gradient diagnostics, leaving open whether the observed underperformance is attributable to the two pitfalls rather than other factors.
- [Results section, Table 2] Table 2 (or equivalent results table) reports aggregate hallucination rates but does not include per-domain breakdowns or statistical significance tests against the baseline unlearning methods; without these, the claim of spillover inflating fabrication rates on unrelated domains cannot be evaluated as load-bearing evidence.
minor comments (2)
- [§3.2] Define the precise formulas for the novel trade-off metrics in RWKU+ (e.g., the conflict and spillover scores) in a dedicated subsection or appendix to allow reproducibility.
- [Abstract] The abstract states the existence of pitfalls and the benchmark but supplies no quantitative results, error bars, or experimental details; move at least one key quantitative finding (with confidence intervals) into the abstract for clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights opportunities to strengthen the empirical support for our claims. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract and §4 (RWKU+ benchmark and gradient diagnostics)] The central claim that knowledge conflict and hallucination spillover are the primary drivers of CFT underperformance (abstract and §4) rests on the RWKU+ benchmark isolating these effects; however, the manuscript does not report controls for model scale or data-construction choices that could confound the gradient diagnostics, leaving open whether the observed underperformance is attributable to the two pitfalls rather than other factors.
Authors: We agree that explicit controls for model scale and data-construction choices would further isolate the contributions of knowledge conflict and hallucination spillover. In the revised manuscript we will add experiments on at least two additional model scales (7B and 13B) and two alternative counterfactual corpus construction procedures, reporting the corresponding gradient diagnostics and trade-off metrics in an expanded §4 and appendix. These controls will directly address whether the observed effects persist across these dimensions. revision: yes
-
Referee: [Results section, Table 2] Table 2 (or equivalent results table) reports aggregate hallucination rates but does not include per-domain breakdowns or statistical significance tests against the baseline unlearning methods; without these, the claim of spillover inflating fabrication rates on unrelated domains cannot be evaluated as load-bearing evidence.
Authors: We concur that aggregate rates alone limit the strength of the spillover claim. The revised version will expand Table 2 to include per-domain hallucination rates across the RWKU+ domains and will report paired t-test p-values comparing CFT against each baseline method. These additions will be placed in the main results section with the corresponding statistical details. revision: yes
Circularity Check
No significant circularity
full rationale
The paper is an empirical study identifying pitfalls in counterfactual tuning for LLM unlearning and proposing RWKU+ as a diagnostic benchmark. No derivation chain, first-principles predictions, fitted parameters renamed as outputs, or self-citation load-bearing steps appear in the provided abstract or described claims. The central findings rest on experimental observations and gradient diagnostics rather than any quantity that reduces to its own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Chenyu Shi, Xiao Wang, Qiming Ge, Songyang Gao, Xianjun Yang, Tao Gui, Qi Zhang, Xuanjing Huang, Xun Zhao, and Dahua Lin
Direct preference optimization: Your language model is secretly a reward model.Advances in Neu- ral Information Processing Systems, 36. Chenyu Shi, Xiao Wang, Qiming Ge, Songyang Gao, Xianjun Yang, Tao Gui, Qi Zhang, Xuanjing Huang, Xun Zhao, and Dahua Lin. 2024. Navigating the OverKill in large language models. InProceedings of the 62nd Annual Meeting of...
2024
-
[2]
InThe Thirteenth Interna- tional Conference on Learning Representations
MUSE: Machine unlearning six-way evalua- tion for language models. InThe Thirteenth Interna- tional Conference on Learning Representations. Pratiksha Thaker, Shengyuan Hu, Neil Kale, Yash Mau- rya, Zhiwei Steven Wu, and Virginia Smith. 2025. Position: Llm unlearning benchmarks are weak mea- sures of progress. In2025 IEEE Conference on Se- cure and Trustwo...
2025
-
[3]
Guardrail baselines for unlearning in llms. arXiv preprint arXiv:2403.03329. 10 Wenyu Wang, Mengqi Zhang, Xiaotian Ye, Zhaochun Ren, Pengjie Ren, and Zhumin Chen. 2025a. UIPE: Enhancing LLM unlearning by removing knowledge related to forgetting targets. InFindings of the Asso- ciation for Computational Linguistics: EMNLP 2025, pages 25212–25227, Suzhou, C...
-
[4]
adapters attached to the q_proj and v_proj modules. Unless noted otherwise, we share the same configuration across methods: rank r=8, scale α=16 on AdamW optimizer, with a cosine learning-rate schedule with 20 warmup steps, and a fixed random seed of42. For theCFT-NoConfexperiment, all six mixing ratios (ρ∈ {0,25,50,75,90,100}% ) share a sin- gle configur...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.