VR-DAgger: Immersive VR for Dexterous Data Collection and Uncertainty-Guided On-Policy Correction
Pith reviewed 2026-06-29 17:32 UTC · model grok-4.3
The pith
VR-DAgger uses uncertainty estimates to select short failure segments for targeted correction in immersive VR, improving dexterous robot policies over behavioral cloning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that Monte Carlo dropout uncertainty computed on autonomous rollouts of a diffusion policy can identify informative failure segments whose selective correction through immersive VR teleoperation yields policies that outperform behavioral cloning on three dexterous manipulation tasks under both standard and challenging initial conditions, while also lowering expert supervision time by concentrating review on high-uncertainty segments rather than entire trajectories.
What carries the argument
Uncertainty-guided selection of short segments from policy rollouts for on-policy correction inside immersive VR, which replays only the chosen clips so the operator can label and override behavior at points of highest model uncertainty.
If this is right
- Active labeling on selected segments raises success rates over behavioral cloning on pan pick-and-place, drawer opening, and valve turning.
- Review time per sample falls when operators correct only high-uncertainty clips instead of full rollouts.
- The gains hold for both standard and challenging starting configurations across the evaluated tasks.
Where Pith is reading between the lines
- The same selection logic could be tested with other policy classes to check whether the time savings generalize beyond the diffusion model used here.
- Lowering the cost of each demonstration might allow collection of larger datasets for tasks that currently lack enough expert data.
- Running the segment replay on physical hardware rather than simulation would test whether the reported time and performance benefits survive real-world latency and sensing differences.
Load-bearing premise
That the uncertainty scores accurately identify the segments whose corrections produce the measured gains in policy performance.
What would settle it
An experiment in which random segment selection produces performance gains and time reductions comparable to uncertainty-guided selection on the same tasks.
Figures







read the original abstract
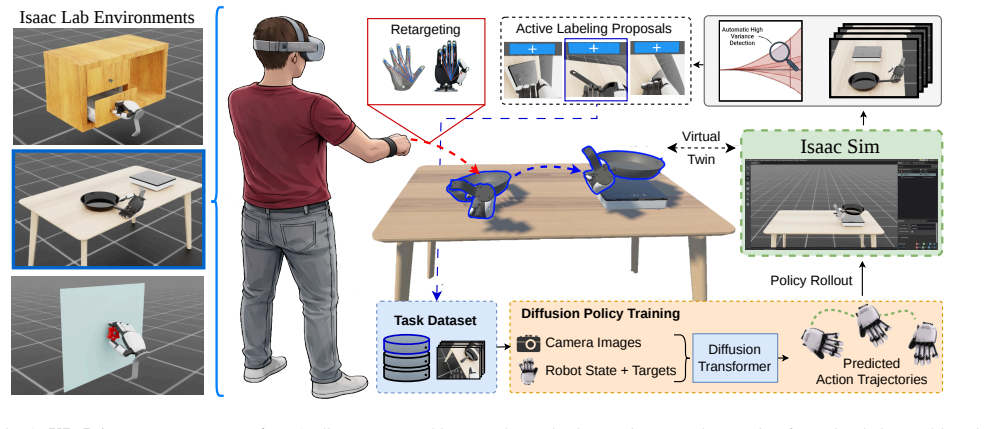
Learning from demonstrations is effective for robotic manipulation, but collecting sufficient task-specific data remains a major bottleneck. Under distribution shift, small errors compound, performance degrades, and expert time is often spent on redundant, low-value corrections instead of the few critical failure cases. We present VR-DAgger, a human-in-the-loop framework centered on an immersive VR application for dexterous teleoperation, demonstration collection, and selective policy correction. The VR client provides intuitive hand control with synchronized scene visualization, while a backend workstation runs simulation and learning, enabling autonomous rollouts without continuous operator oversight. We use Monte Carlo (MC) dropout to score uncertainty during Isaac Lab rollouts of a diffusion policy and select informative failure segments for correction. These segments are replayed in VR as clips, where the operator selectively labels and corrects the policy's behavior, concentrating supervision where uncertainty is highest without full-rollout monitoring or a separate intervention classifier. We evaluate on three dexterous manipulation tasks (Pan pick-and-place, Drawer opening, Valve turning) with a 10-DoF XHand under standard and challenging initial configurations. Active labeling consistently improves over behavioral cloning across all tasks, with gains of up to 23 percentage points. Compared to unguided human-in-the-loop inspection, VR-DAgger reduces per-sample collection time by approximately 40% by focusing review on selected segments rather than full rollouts.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces VR-DAgger, a human-in-the-loop framework for dexterous robotic manipulation using immersive VR for teleoperation, demonstration collection, and selective policy correction. A diffusion policy is trained via behavioral cloning and then refined by running autonomous rollouts in Isaac Lab, scoring uncertainty via Monte Carlo dropout, and replaying high-uncertainty failure segments as VR clips for targeted human correction. The method is evaluated on three tasks (Pan pick-and-place, Drawer opening, Valve turning) with a 10-DoF XHand under standard and challenging initial configurations, claiming consistent improvements over behavioral cloning (up to 23 percentage points) and a 40% reduction in per-sample collection time versus unguided full-rollout inspection.
Significance. If the quantitative claims are supported by properly controlled experiments, the work could offer a practical advance in efficient expert data collection for high-DoF manipulation under distribution shift. The combination of VR immersion with simulation-backed autonomous rollouts and uncertainty-guided segment selection addresses a real bottleneck in human-in-the-loop imitation learning. The engineering integration of a VR client with a backend workstation for non-continuous oversight is a concrete contribution that could be adopted in other teleoperation pipelines.
major comments (2)
- [Abstract] Abstract: the central performance claims ('gains of up to 23 percentage points' and 'reduces per-sample collection time by approximately 40%') are stated without any accompanying experimental details on trial counts, variance or standard-error measures, exact baseline implementations, success metrics, or the precise segment-selection threshold/procedure. These omissions are load-bearing because the headline improvements cannot be assessed for statistical support or reproducibility from the given information.
- [Evaluation] Evaluation section (implied by abstract claims): no ablation or comparison is described that isolates the contribution of MC-dropout segment selection versus simply collecting additional labeled data at random or via full-rollout review. Without such evidence it remains possible that the reported gains arise from increased total supervision volume rather than from the uncertainty-guided targeting of critical failure modes, which is the load-bearing assumption for the 'uncertainty-guided on-policy correction' contribution.
minor comments (1)
- [Abstract] Abstract: the three tasks are named but no definition of success criteria, episode length, or how 'challenging initial configurations' are generated is supplied even at a high level.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and will revise the paper to improve clarity and strengthen the evaluation.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central performance claims ('gains of up to 23 percentage points' and 'reduces per-sample collection time by approximately 40%') are stated without any accompanying experimental details on trial counts, variance or standard-error measures, exact baseline implementations, success metrics, or the precise segment-selection threshold/procedure. These omissions are load-bearing because the headline improvements cannot be assessed for statistical support or reproducibility from the given information.
Authors: We agree that the abstract would benefit from additional context. In the revised manuscript we will expand the abstract to note that results are averaged over 10 independent trials per task-configuration pair with standard errors, that success is measured by binary task completion rate, that the baseline is standard behavioral cloning with a diffusion policy, and that segments are selected using an MC-dropout variance threshold at the 75th percentile. Full statistical details remain in Section 4. revision: yes
-
Referee: [Evaluation] Evaluation section (implied by abstract claims): no ablation or comparison is described that isolates the contribution of MC-dropout segment selection versus simply collecting additional labeled data at random or via full-rollout review. Without such evidence it remains possible that the reported gains arise from increased total supervision volume rather than from the uncertainty-guided targeting of critical failure modes, which is the load-bearing assumption for the 'uncertainty-guided on-policy correction' contribution.
Authors: We acknowledge the value of an explicit ablation. The current experiments already compare against unguided full-rollout inspection, but we lack a random-segment collection arm with matched supervision volume. We will add this baseline in the revised evaluation, collecting an equivalent number of additional labels via random selection and reporting the resulting success rates to isolate the benefit of uncertainty guidance. revision: yes
Circularity Check
No circularity; empirical gains are independent of uncertainty selection mechanism
full rationale
The paper's central claims rest on experimental results from three dexterous tasks showing active labeling gains over behavioral cloning and time savings versus full-rollout review. These outcomes are measured directly from policy performance after VR corrections and are not defined in terms of the MC dropout scores or any fitted quantity. No equations reduce a prediction to its input by construction, no self-citation chains justify uniqueness or ansatzes, and no known results are renamed. The derivation chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Monte Carlo dropout produces reliable uncertainty estimates for the diffusion policy during autonomous rollouts
Forward citations
Cited by 1 Pith paper
-
Grounding Generative Policies in Physics: Optimization-Guided Diffusion for Robot Control
Optimization-guided diffusion replaces sampling perturbations with constrained corrections to enforce physical feasibility in generative robot policies at inference time.
Reference graph
Works this paper leans on
-
[1]
Open x-embodiment: Robotic learning datasets and rt-x models : Open x-embodiment collaboration0,
A. O’Neill, A. Rehman, A. Maddukuri, and e. a. Gupta, Abhishek, “Open x-embodiment: Robotic learning datasets and rt-x models : Open x-embodiment collaboration0,” inICRA (2024), 2024
2024
-
[2]
Octo: An Open-Source Generalist Robot Policy
O. M. Team, D. Ghosh, H. Walke, K. Pertsch, K. Black, O. Mees, S. Dasari, J. Hejna, T. Kreiman, C. Xu,et al., “Octo: An open-source generalist robot policy,”arXiv preprint arXiv:2405.12213, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
Back to reality for imitation learning,
E. Johns, “Back to reality for imitation learning,” inConference on Robot Learning. PMLR, 2022, pp. 1764–1768
2022
-
[4]
A reduction of imitation learning and structured prediction to no-regret online learning,
S. Ross, G. Gordon, and D. Bagnell, “A reduction of imitation learning and structured prediction to no-regret online learning,” inProceedings of the fourteenth international conference on artificial intelligence and statistics. JMLR Workshop, 2011, pp. 627–635
2011
-
[5]
Dexhub and dart: Towards internet scale robot data collection,
Y . Park, J. S. Bhatia, L. Ankile, and P. Agrawal, “Dexhub and dart: Towards internet scale robot data collection,”arXiv preprint arXiv:2411.02214, 2024
-
[6]
R. Hoque, A. Balakrishna, E. Novoseller, A. Wilcox, D. S. Brown, and K. Goldberg, “Thriftydagger: Budget-aware novelty and risk gating for interactive imitation learning,”arXiv preprint arXiv:2109.08273, 2021
-
[7]
Dropout as a Bayesian Approximation: Representing Model Uncertainty in Deep Learning
Y . Gal and Z. Ghahramani, “Dropout as a bayesian approximation: Representing model uncertainty in deep learning,” 2016. [Online]. Available: https://arxiv.org/abs/1506.02142
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[8]
Hg-dagger: Interactive imitation learning with human experts,
M. Kelly, C. Sidrane, K. Driggs-Campbell, and M. J. Kochenderfer, “Hg-dagger: Interactive imitation learning with human experts,” in ICRA (2019). IEEE, 2019, pp. 8077–8083
2019
-
[9]
Diffusion Policy: Visuomotor Policy Learning via Action Diffusion
C. Chi, Z. Xu, S. Feng, E. Cousineau, Y . Du, B. Burchfiel, R. Tedrake, and S. Song, “Diffusion policy: Visuomotor policy learning via action diffusion,” 2024. [Online]. Available: https://arxiv.org/abs/2303.04137
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
Diffusion meets dagger: Supercharging eye-in-hand imitation learning,
X. Zhang, M. Chang, P. Kumar, and S. Gupta, “Diffusion meets dagger: Supercharging eye-in-hand imitation learning,”arXiv preprint arXiv:2402.17768, 2024
-
[11]
Lazydag- ger: Reducing context switching in interactive imitation learning,
R. Hoque, A. Balakrishna, C. Putterman, M. Luo, D. S. Brown, D. Seita, B. Thananjeyan, E. Novoseller, and K. Goldberg, “Lazydag- ger: Reducing context switching in interactive imitation learning,” in 2021 IEEE 17th International Conference on Automation Science and Engineering (CASE), 2021, pp. 502–509
2021
-
[12]
Ensem- bledagger: A bayesian approach to safe imitation learning,
K. Menda, K. Driggs-Campbell, and M. J. Kochenderfer, “Ensem- bledagger: A bayesian approach to safe imitation learning,” in2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2019, pp. 5041–5048
2019
-
[13]
Y . Yang, B. Ikeda, G. Bertasius, and D. Szafir, “Arcade: Scalable demonstration collection and generation via augmented reality for imitation learning,” 2024. [Online]. Available: https://arxiv.org/abs/2410.15994
-
[14]
arXiv preprint arXiv:2309.10175 , year=
A. George and A. B. Farimani, “One act play: Single demonstration behavior cloning with action chunking transformers,” 2023. [Online]. Available: https://arxiv.org/abs/2309.10175
-
[15]
Deep Imitation Learning for Complex Manipulation Tasks from Virtual Reality Teleoperation
T. Zhang, Z. McCarthy, O. Jow, D. Lee, X. Chen, K. Goldberg, and P. Abbeel, “Deep imitation learning for complex manipulation tasks from virtual reality teleoperation,” 2018. [Online]. Available: https://arxiv.org/abs/1710.04615
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[16]
Holo-dex: Teaching dexterity with immersive mixed reality,
S. P. Arunachalam, I. G ¨uzey, S. Chintala, and L. Pinto, “Holo-dex: Teaching dexterity with immersive mixed reality,” 2022. [Online]. Available: https://arxiv.org/abs/2210.06463
-
[17]
Bunny-visionpro: Real-time bimanual dexterous teleoperation for imitation learning
R. Ding, Y . Qin, J. Zhu, C. Jia, S. Yang, R. Yang, X. Qi, and X. Wang, “Bunny-visionpro: Real-time bimanual dexterous teleoperation for imitation learning,” 2024. [Online]. Available: https://arxiv.org/abs/2407.03162
-
[18]
Ar2-d2:training a robot without a robot,
J. Duan, Y . R. Wang, M. Shridhar, D. Fox, and R. Krishna, “Ar2-d2:training a robot without a robot,” 2023. [Online]. Available: https://arxiv.org/abs/2306.13818
-
[19]
Armada: Augmented reality for robot manipulation and robot-free data acquisition,
N. Nechyporenko, R. Hoque, C. Webb, M. Sivapurapu, and J. Zhang, “Armada: Augmented reality for robot manipulation and robot-free data acquisition,” 2024. [Online]. Available: https://arxiv.org/abs/2412.10631
-
[20]
S. Chen, C. Wang, K. Nguyen, L. Fei-Fei, and C. K. Liu, “Arcap: Collecting high-quality human demonstrations for robot learning with augmented reality feedback,” 2024. [Online]. Available: https://arxiv.org/abs/2410.08464
-
[21]
Radiance fields for robotic teleoperation,
M. Wilder-Smith, V . Patil, and M. Hutter, “Radiance fields for robotic teleoperation,” in2024 IEEE/RSJ International Conference on Intelli- gent Robots and Systems (IROS). IEEE, 2024, pp. 13 861–13 868. 8
2024
-
[22]
Isaac Lab: A GPU-Accelerated Simulation Framework for Multi-Modal Robot Learning
M. Mittal, P. Roth, J. Tigue, A. Richard, O. Zhang, P. Du, A. Serrano- Munoz, X. Yao, R. Zurbr ¨ugg, N. Rudin,et al., “Isaac lab: A gpu- accelerated simulation framework for multi-modal robot learning,” arXiv preprint arXiv:2511.04831, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
bhaptics: Next generation full-body haptic suit,
bHaptics, “bhaptics: Next generation full-body haptic suit,” 2026, ac- cessed: 2026-03-06. [Online]. Available: https://www.bhaptics.com/en/
2026
-
[24]
Dexpilot: Vision-based teleop- eration of dexterous robotic hand-arm system,
A. Handa, K. Van Wyk, W. Yang, J. Liang, Y .-W. Chao, Q. Wan, S. Birchfield, N. Ratliff, and D. Fox, “Dexpilot: Vision-based teleop- eration of dexterous robotic hand-arm system,” inICRA. IEEE, 2020, pp. 9164–9170
2020
-
[25]
Dexmv: Imitation learning for dexterous manipulation from human videos,
Y . Qin, Y .-H. Wu, S. Liu, H. Jiang, R. Yang, Y . Fu, and X. Wang, “Dexmv: Imitation learning for dexterous manipulation from human videos,” 2021
2021
-
[26]
Anyteleop: A general vision-based dexterous robot arm- hand teleoperation system,
Y . Qin, W. Yang, B. Huang, K. Van Wyk, H. Su, X. Wang, Y .-W. Chao, and D. Fox, “Anyteleop: A general vision-based dexterous robot arm- hand teleoperation system,” inRobotics: Science and Systems, 2023
2023
-
[27]
On the continuity of rotation representations in neural networks,
Y . Zhou, C. Barnes, J. Lu, J. Yang, and H. Li, “On the continuity of rotation representations in neural networks,” 2020. [Online]. Available: https://arxiv.org/abs/1812.07035 9
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.