VitaBench 2.0: Evaluating Personalized and Proactive Agents in Long-Term User Interactions
Pith reviewed 2026-06-29 17:07 UTC · model grok-4.3
The pith
VitaBench 2.0 shows that state-of-the-art LLMs still struggle to personalize and act proactively in long-term user interactions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
VitaBench 2.0 organizes evaluation tasks as temporally ordered sequences for individual users in which preferences are embedded in fragmented and heterogeneous interactions; successful performance demands that agents continuously extract, utilize, and update those preferences while also recognizing and acquiring missing information from users or environments, and frontier models exhibit a substantial gap from the required capabilities.
What carries the argument
The VitaBench 2.0 benchmark of user-specific temporal task sequences with embedded preferences, combined with proactiveness tasks that test acquisition of missing information and an extensible memory interface for architecture comparisons.
Load-bearing premise
The constructed tasks and preference embeddings accurately capture the inference and proactivity demands of genuine long-term user interactions.
What would settle it
A direct comparison in which agents that perform well on VitaBench 2.0 are deployed in real extended user sessions and their personalization accuracy or user satisfaction is measured against benchmark scores.
Figures

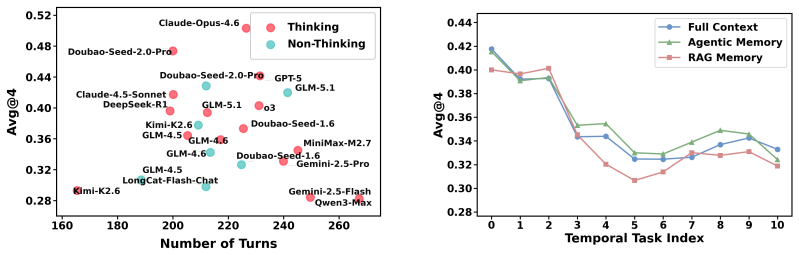



read the original abstract
Large language models (LLMs) have evolved into interactive agents that collaborate with users in real-world tasks. Effective collaboration in such settings increasingly depends on understanding the user beyond what is explicitly stated, as user intent is often reflected in fragmented daily interactions and requires both personalized modeling and proactive interaction. However, existing agent benchmarks primarily evaluate reasoning and tool use, largely overlooking the challenges of inferring and leveraging user preferences in realistic scenarios. To address this gap, we introduce VitaBench 2.0, a benchmark for evaluating personalized and proactive agent behavior in long-term user interactions. In VitaBench 2.0, tasks are organized as temporally ordered sequences for individual users, where preferences are embedded in fragmented and heterogeneous interactions. Successful completion of tasks requires the agent to continuously extract, utilize, and update user preferences from these interactions. We further evaluate proactiveness through tasks that require agents to recognize missing information and actively acquire it from users or environments before making decisions. To support systematic analysis, we provide an extensible memory interface that enables controlled comparison across different memory architectures. We benchmark a diverse set of frontier proprietary and open-source LLMs. Results show that real-world personalization remains highly challenging even for state-of-the-art models, revealing a substantial gap between current capabilities and practical requirements. Extensive analysis further reveals the failure modes and capability bottlenecks of current agents in real-world personalized decision-making, providing insights for future model improvements.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces VitaBench 2.0, a benchmark for evaluating personalized and proactive agent behavior in long-term user interactions. Tasks are organized as temporally ordered sequences for individual users with preferences embedded in fragmented and heterogeneous interactions; successful completion requires agents to continuously extract, utilize, and update user preferences. Proactiveness is evaluated via tasks that require recognizing missing information and actively acquiring it from users or environments. An extensible memory interface supports controlled comparisons across memory architectures. Benchmarking of frontier proprietary and open-source LLMs shows that real-world personalization remains highly challenging, revealing a substantial gap between current capabilities and practical requirements, along with analysis of failure modes.
Significance. If the benchmark construction and evaluation protocol hold, the work fills a clear gap in existing agent benchmarks by targeting long-term personalization and proactivity rather than isolated reasoning or tool use. The extensible memory interface is a concrete strength that enables systematic ablation across architectures. The paper supplies the task-generation procedure, memory interface, and evaluation protocol, supporting reproducibility; the scoped claim of a capability gap on this benchmark is internally consistent and provides actionable insights into bottlenecks for future model development.
Simulated Author's Rebuttal
We thank the referee for their positive assessment of VitaBench 2.0, their recognition of the benchmark's contributions to long-term personalization and proactivity, and their recommendation to accept the manuscript.
Circularity Check
No significant circularity
full rationale
The paper introduces VitaBench 2.0 as an empirical benchmark for agent personalization and proactivity, with tasks organized as temporally ordered sequences embedding fragmented preferences, plus an extensible memory interface and evaluation protocol. The central claim—that state-of-the-art models exhibit a substantial gap on these tasks—is supported directly by reported benchmark results rather than any derivation, equation, fitted parameter, or self-citation chain that reduces to prior inputs. No load-bearing step equates a prediction to its own construction; the argument remains self-contained within the supplied task-generation and evaluation procedures.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Deepseek-v3.1 model card
DeepSeekAI. Deepseek-v3.1 model card. 2025. URL https://huggingface.co/ deepseek-ai/DeepSeek-V3.1
2025
-
[2]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Introducing gpt-5
OpenAI. Introducing gpt-5. 2025. URL https://openai.com/index/ introducing-gpt-5/
2025
-
[4]
Claude sonnet 4.5 model card
Anthropic. Claude sonnet 4.5 model card. 2025. URL https://www.anthropic.com/ news/claude-sonnet-4-5
2025
-
[5]
Longcat-flash-thinking-2601 technical report.CoRR, abs/2601.16725, 2026
Meituan LongCat Team. Longcat-flash-thinking-2601 technical report.CoRR, abs/2601.16725, 2026
-
[6]
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
Aixin Liu et al. Deepseek-v3.2: Pushing the frontier of open large language models.arXiv preprint arXiv:2512.02556, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Qwen3-max model card
Qwen Team. Qwen3-max model card. 2025. URL https://qwen.ai/blog?id= qwen3-max
2025
-
[8]
Jiahong Liu, Zexuan Qiu, Zhongyang Li, Quanyu Dai, Wenhao Yu, Jieming Zhu, Minda Hu, Menglin Yang, Tat-Seng Chua, and Irwin King. A survey of personalized large language models: Progress and future directions.arXiv preprint arXiv:2502.11528, 2025
-
[9]
Bowen Jiang, Yuan Yuan, Maohao Shen, Zhuoqun Hao, Zhangchen Xu, Zichen Chen, et al. PersonaMem-v2: Towards personalized intelligence via learning implicit user personas and agentic memory.arXiv preprint arXiv:2512.06688, 2025
-
[10]
Bowen Jiang, Zhuoqun Hao, Young-Min Cho, Bryan Li, Yuan Yuan, Sihao Chen, Lyle Ungar, Camillo J Taylor, and Dan Roth. Know me, respond to me: Benchmarking LLMs for dynamic user profiling and personalized responses at scale.arXiv preprint arXiv:2504.14225, 2025
-
[11]
KnowU-Bench: Towards Interactive, Proactive, and Personalized Mobile Agent Evaluation
Tongbo Chen, Zhengxi Lu, Zhan Xu, Guocheng Shao, Shaohan Zhao, Fei Tang, Yong Du, Kaitao Song, Yizhou Liu, Yuchen Yan, et al. Knowu-bench: Towards interactive, proactive, and personalized mobile agent evaluation.arXiv preprint arXiv:2604.08455, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[12]
SWE-bench: Can language models resolve real-world GitHub issues? In International Conference on Learning Representations, 2024
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. SWE-bench: Can language models resolve real-world GitHub issues? In International Conference on Learning Representations, 2024
2024
-
[13]
Agent- Bench: Evaluating LLMs as agents
Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, Xuanyu Lei, Hanyu Lai, Yu Gu, et al. Agent- Bench: Evaluating LLMs as agents. InInternational Conference on Learning Representations, 2024. 10
2024
-
[14]
WebArena: A realistic web environment for building autonomous agents
Shuyan Zhou, Frank F Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Yonatan Bisk, Daniel Fried, Uri Alon, et al. WebArena: A realistic web environment for building autonomous agents. InInternational Conference on Learning Representations, 2024
2024
-
[15]
$\tau$-bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains
Shunyu Yao, Noah Shinn, Pedram Razavi, and Karthik Narasimhan. τ-bench: A benchmark for tool-agent-user interaction in real-world domains.arXiv preprint arXiv:2406.12045, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
Victor Barres, Honghua Dong, Soham Ray, Xujie Si, and Karthik Narasimhan.τ 2-bench: Eval- uating conversational agents in a dual-control environment.arXiv preprint arXiv:2506.07982, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Wei He, Yueqing Sun, Hongyan Hao, Xueyuan Hao, Zhikang Xia, Qi Gu, Chengcheng Han, et al. VitaBench: Benchmarking LLM agents with versatile interactive tasks in real-world applications.arXiv preprint arXiv:2509.26490, 2025
-
[18]
Personalization of large language models: A survey.arXiv preprint arXiv:2411.00027, 2024
Zhehao Zhang, Ryan Lutz, Aidan Mao, Tianyue Bao, Zijian Wang, Zhoujian Zhao, Kaixin Xiang, Liwei Ding, Le Tong, Jiaxin Zhuo, et al. Personalization of large language models: A survey.arXiv preprint arXiv:2411.00027, 2024
-
[19]
Mem0: The memory layer for personalized AI.https://mem0.ai, 2024
Mem0. Mem0: The memory layer for personalized AI.https://mem0.ai, 2024
2024
-
[22]
Yu-Min Tseng, Yu-Chao Huang, Teng-Yun Hsiao, Wei-Lin Huang, et al. Two tales of persona in LLMs: A survey of role-playing and personalization.arXiv preprint arXiv:2406.01171, 2024
-
[23]
Optimization methods for personalizing large language models through retrieval augmentation
Alireza Salemi, Sheshera Mysore, Michael Bendersky, and Hamed Zamani. Optimization methods for personalizing large language models through retrieval augmentation. InPro- ceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval, 2024
2024
-
[24]
PEARL: Personalizing large language model writing assistants with generation-calibrated retrievers
Sheshera Mysore, Zhuoran Lu, Mengting Wan, Julian McAuley, and Hamed Zamani. PEARL: Personalizing large language model writing assistants with generation-calibrated retrievers. In Proceedings of the 1st Workshop on Customizable NLP, 2024
2024
-
[25]
Jesse Richardson, Kristen Bloom, Aggeliki Founta, and Brendan Mathew. Integrating summa- rization and retrieval for enhanced personalization via large language models.arXiv preprint arXiv:2310.20081, 2023
-
[26]
Cheng Li, Mingyang Chen, Haoping Wang, Bin Zhu, Haoyu Luo, et al. Teach LLMs to personalize–an approach inspired by writing education.arXiv preprint arXiv:2308.07968, 2023
-
[27]
Ostap Wu, Max Haim, Tanmay Dey, et al. Understanding the role of user profile in the personalization of large language models.arXiv preprint arXiv:2406.17803, 2024
-
[28]
Democra- tizing large language models via personalized parameter-efficient fine-tuning
Zhaoxuan Tan, Qingkai Zeng, Yijun Tian, Zheyuan Liu, Bing Yin, and Meng Jiang. Democra- tizing large language models via personalized parameter-efficient fine-tuning. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, 2024
2024
-
[29]
PLoRA: Personalized low-rank adaptation for human- centered text understanding
Yuting Zhang, Yuliang Ding, et al. PLoRA: Personalized low-rank adaptation for human- centered text understanding. InProceedings of the AAAI Conference on Artificial Intelligence, 2024
2024
-
[30]
Tao Zhuang, Xin Wang, Zhirui Yuan, et al. HYDRA: Model factorization framework for black-box LLM personalization.arXiv preprint arXiv:2406.02888, 2024. 11
-
[31]
Joel Jang, Seungone Kim, Bill Yuchen Lin, Yizhong Wang, Jack Shafran, Yejin Choi, et al. Personalized soups: Personalized large language model alignment via post-hoc parameter merging.arXiv preprint arXiv:2310.11564, 2023
-
[32]
Zhanhui Zhou, Jie Liu, Jing Dong, Jiaheng Yang, et al. Beyond one-preference-fits-all alignment: Multi-objective direct preference optimization.arXiv preprint arXiv:2310.03708, 2023
-
[33]
Xiaoyan Zhao, Juntao You, Yang Zhang, Wenjie Wang, Hong Cheng, Fuli Feng, See-Kiong Ng, and Tat-Seng Chua. NextQuill: Causal preference modeling for enhancing LLM personal- ization.arXiv preprint arXiv:2506.02368, 2025
-
[34]
MemGPT: Towards LLMs as Operating Systems
Charles Packer, Sarah Wooders, Kevin Lin, Vivian Fang, Shishir G Patil, Ion Stoica, and Joseph E Gonzalez. MemGPT: Towards LLMs as operating systems.arXiv preprint arXiv:2310.08560, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[35]
A-MEM: Agentic Memory for LLM Agents
Wujiang Xu, Zujie Liang, Kai Mei, et al. A-MEM: Agentic memory for LLM agents.arXiv preprint arXiv:2502.12110, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
PersonalLLM: Tailoring LLMs to individual preferences.arXiv preprint arXiv:2409.20296, 2024
Thomas P Zollo, Andrew Weidinger, et al. PersonalLLM: Tailoring LLMs to individual preferences.arXiv preprint arXiv:2409.20296, 2024
-
[37]
Do LLMs recognize your preferences? evaluating personalized preference following in LLMs
Xiaoyan Zhao, Yang Zhang, Juntao You, Wenjie Wang, Fuli Feng, et al. Do LLMs recognize your preferences? evaluating personalized preference following in LLMs. InInternational Conference on Learning Representations, 2025
2025
-
[38]
PersonaBench: Evaluating AI models on understanding personal informa- tion through accessing (synthetic) private user data
Zhaoxuan Tan et al. PersonaBench: Evaluating AI models on understanding personal informa- tion through accessing (synthetic) private user data. InInternational Conference on Learning Representations, 2025
2025
-
[39]
LaMP: When large language models meet personalization
Alireza Salemi, Sheshera Mysore, Michael Bendersky, and Hamed Zamani. LaMP: When large language models meet personalization. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics, 2024
2024
-
[40]
Ishita Kumar, Snigdha Viswanathan, et al. LongLaMP: A benchmark for personalized long- form text generation.arXiv preprint arXiv:2407.11016, 2024
-
[41]
Evaluating very long-term conversational memory of LLM agents
Adyasha Maharana, Dong-Ho Lee, Sergey Tulyakov, Mohit Bansal, Francesco Barbieri, and Yuwei Fang. Evaluating very long-term conversational memory of LLM agents. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics, 2024
2024
-
[42]
LongMemEval: Benchmarking Chat Assistants on Long-Term Interactive Memory
Di Wu, Hongwei Wang, Wenhao Yu, Yuwei Wu, Kai Yu, et al. LongMemEval: Benchmarking chat assistants on long-term interactive memory.arXiv preprint arXiv:2410.10813, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[43]
Zeyu Zhang et al. MemSim: A Bayesian simulator for evaluating memory of personal assistants.arXiv preprint arXiv:2409.20163, 2024
-
[44]
AlpsBench: An LLM Personalization Benchmark for Real-Dialogue Memorization and Preference Alignment
Jianfei Xiao, Xiang Yu, Chengbing Wang, Wuqiang Zheng, Xinyu Lin, Kaining Liu, Hongxun Ding, Yang Zhang, Wenjie Wang, Fuli Feng, and Xiangnan He. AlpsBench: An LLM personalization benchmark for real-dialogue memorization and preference alignment.arXiv preprint arXiv:2603.26680, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[45]
Toolformer: Language models can teach themselves to use tools
Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools. InAdvances in Neural Information Processing Systems, 2023
2023
-
[46]
API-Bank: A comprehensive benchmark for tool-augmented LLMs
Minghao Li, Feifan Song, Bowen Yu, Haiyang Yu, Zhoujun Li, Fei Huang, and Yongbin Li. API-Bank: A comprehensive benchmark for tool-augmented LLMs. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, 2023
2023
-
[47]
Gorilla: Large language model connected with massive APIs
Shishir G Patil, Tianjun Zhang, Xin Wang, and Joseph E Gonzalez. Gorilla: Large language model connected with massive APIs. InAdvances in Neural Information Processing Systems, 2024. 12
2024
-
[48]
ToolTalk: Evaluating tool-usage in a conversational setting
Nicholas Farn and Richard Shin. ToolTalk: Evaluating tool-usage in a conversational setting. arXiv preprint arXiv:2311.10775, 2023
-
[49]
MINT: Evaluating LLMs in multi-turn interaction with tools and language feedback
Xingyao Wang, Zihan Wang, Jiateng Liu, Yangyi Chen, Lifan Yuan, Hao Peng, and Heng Ji. MINT: Evaluating LLMs in multi-turn interaction with tools and language feedback. In International Conference on Learning Representations, 2024
2024
-
[50]
ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs
Yujia Qin, Shihao Liang, Yining Ye, Kunlun Zhu, Lan Yan, Yaxi Lu, Yankai Lin, Xin Cong, Xiangru Tang, et al. ToolLLM: Facilitating large language models to master 16000+ real-world APIs.arXiv preprint arXiv:2307.16789, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[51]
Jiarui Lu, Thomas Zhu, Hao Jiang, Marta Skreta, Arun Sai Rawat, et al. ToolSandbox: A stateful, conversational, interactive evaluation benchmark for LLM tool use capabilities.arXiv preprint arXiv:2408.04682, 2024
-
[52]
AJ-Bench: Benchmarking Agent-as-a-Judge for Environment-Aware Evaluation
Wentao Shi, Yu Wang, Yuyang Zhao, Yuxin Chen, Fuli Feng, Xueyuan Hao, Xi Su, Qi Gu, Hui Su, Xunliang Cai, et al. Aj-bench: Benchmarking agent-as-a-judge for environment-aware evaluation.arXiv preprint arXiv:2604.18240, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[53]
OSWorld: Benchmarking multimodal agents for open-ended tasks in real computer environments
Tianbao Xie, Danyang Zhang, Jixuan Chen, Xiaochuan Li, Siheng Zhao, Ruisheng Cao, Toh Jing Hua, et al. OSWorld: Benchmarking multimodal agents for open-ended tasks in real computer environments. InAdvances in Neural Information Processing Systems, 2024
2024
-
[54]
AppWorld: A controllable world of apps and people for benchmarking interactive coding agents
Harsh Trivedi, Tushar Khot, Mareike Hartmann, Reshef Manber, Vinty Baber, David Fishi, et al. AppWorld: A controllable world of apps and people for benchmarking interactive coding agents. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics, 2024
2024
-
[55]
SkillsBench: Benchmarking How Well Agent Skills Work Across Diverse Tasks
Xiangyi Li, Wenbo Chen, Yimin Liu, Shenghan Zheng, et al. SkillsBench: Benchmarking how well agent skills work across diverse tasks.arXiv preprint arXiv:2602.12670, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[56]
Ruipeng Wang, Yuxin Chen, Yukai Wang, Chang Wu, Junfeng Fang, Xiaodong Cai, Qi Gu, Hui Su, An Zhang, Xiang Wang, et al. Agentnoisebench: Benchmarking robustness of tool-using llm agents under noisy condition.arXiv preprint arXiv:2602.11348, 2026
-
[57]
Jingnan Zheng, Yanzhen Luo, Jingjun Xu, Bingnan Liu, Yuxin Chen, Chenhang Cui, Gelei Deng, Chaochao Lu, Xiang Wang, An Zhang, et al. Risky-bench: Probing agentic safety risks under real-world deployment.arXiv preprint arXiv:2602.03100, 2026
-
[58]
Introducing gpt-4.1 in the api
OpenAI. Introducing gpt-4.1 in the api. 2025. URL https://openai.com/index/ gpt-4-1/
2025
-
[59]
Introducing gpt-5.1
OpenAI. Introducing gpt-5.1. 2025. URLhttps://openai.com/index/gpt-5-1/
2025
-
[60]
Introducing gpt-5.2
OpenAI. Introducing gpt-5.2. 2025. URL https://openai.com/index/ introducing-gpt-5-2/
2025
-
[61]
Introducing o3 and o4-mini
OpenAI. Introducing o3 and o4-mini. 2025. URL https://openai.com/index/ introducing-o3-and-o4-mini/
2025
-
[62]
Deepseek-v4 model card
DeepSeekAI. Deepseek-v4 model card. 2026. URL huggingface.co/deepseek-ai/ DeepSeek-V4-Pro
2026
-
[63]
Claude sonnet 4 system card
Anthropic. Claude sonnet 4 system card. 2025. URL https://www.anthropic.com/news/ claude-4
2025
-
[64]
Claude opus 4.6 system card
Anthropic. Claude opus 4.6 system card. 2026. URL https://www.anthropic.com/ claude-opus-4-6-system-card
2026
-
[65]
Gheorghe Comanici et al. Gemini 2.5: Advanced reasoning, multimodality, and agentic capabilities.arXiv preprint arXiv:2507.06261, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[66]
Gemini 2.5 pro model card
Google. Gemini 2.5 pro model card. 2025. URL https://modelcards.withgoogle.com/ assets/documents/gemini-2.5-pro.pdf. 13
2025
-
[67]
Gemini 2.5 flash model card
Google. Gemini 2.5 flash model card. 2025. URL https://storage.googleapis.com/ deepmind-media/Model-Cards/Gemini-2-5-Flash-Model-Card.pdf
2025
-
[68]
GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models
Aohan Zeng et al. Glm-4.5: Agentic, reasoning, and coding foundation models.arXiv preprint arXiv:2508.06471, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[69]
Glm-4.6 technical blog
Z.ai. Glm-4.6 technical blog. 2025. URLhttps://z.ai/blog/glm-4.6
2025
-
[70]
GLM-5.1 model card
Z.ai. GLM-5.1 model card. 2026. URLhttps://huggingface.co/zai-org/GLM-5.1
2026
-
[71]
Seed 1.6 technical introduction
ByteDance. Seed 1.6 technical introduction. 2025. URL https://seed.bytedance.com/ en/seed1_6
2025
-
[72]
Seed 2.0 model card: Towards intelligence frontier for real-world complexity
ByteDance Seed. Seed 2.0 model card: Towards intelligence frontier for real-world complexity
-
[73]
URLseed.bytedance.com/en/seed2
-
[74]
Kimi-K2.6 model card
Moonshot AI. Kimi-K2.6 model card. 2026. URL https://huggingface.co/ moonshotai/Kimi-K2.6
2026
-
[75]
Longcat-flash technical report.arXiv preprint arXiv:2509.01322, 2025
Meituan LongCat Team. Longcat-flash technical report.arXiv preprint arXiv:2509.01322, 2025
-
[76]
MiniMax-M2.7: Model self-improvement, driving productivity innovation through technological breakthroughs
MiniMax. MiniMax-M2.7: Model self-improvement, driving productivity innovation through technological breakthroughs. 2026. URLhttps://www.minimax.io/models/text/m27
2026
-
[77]
Efficient streaming language models with attention sinks
Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis. Efficient streaming language models with attention sinks. InInternational Conference on Learning Representations (ICLR), 2024
2024
-
[78]
Augmenting language models with long-term memory
Weizhi Wang, Li Dong, Hao Cheng, Xiaodong Liu, Xifeng Yan, Jianfeng Gao, and Furu Wei. Augmenting language models with long-term memory. InAdvances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[79]
Qingyue Wang, Liang Ding, Yanan Cao, Zhiliang Tian, Shi Wang, Dacheng Tao, and Li Guo. Recursively summarizing enables long-term dialogue memory in large language models.arXiv preprint arXiv:2308.15022, 2023
-
[80]
Yusen Zhang, Ruoxi Sun, Yanfei Chen, Tomas Pfister, Rui Zhang, and Sercan O. Arik. Chain of agents: Large language models collaborating on long-context tasks. InAdvances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[81]
Xixi Wu, Kuan Li, Yida Zhao, Yong Jiang, Pengjun Xie, Fei Huang, Jingren Zhou, et al. ReSum: Unlocking long-horizon search intelligence via context summarization.arXiv preprint arXiv:2509.13313, 2025
-
[82]
Scaling long-horizon LLM agent via context-folding
Weiwei Sun, Miao Lu, Zhan Ling, et al. Scaling long-horizon LLM agent via context-folding. arXiv preprint arXiv:2510.11967, 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.