Landseer: Exploring the Machine Learning Defense Landscape
Pith reviewed 2026-06-29 17:24 UTC · model grok-4.3
The pith
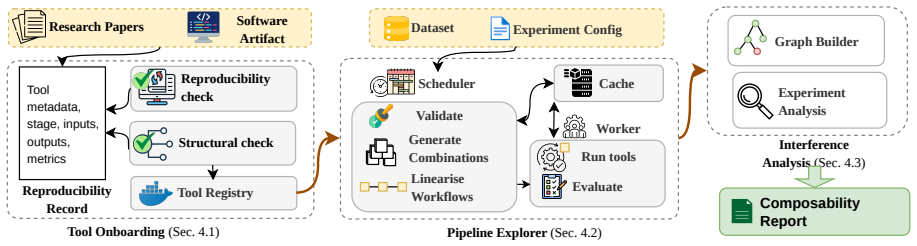
Landseer packages machine learning defenses as containerized modules to let researchers test them individually or in combination through automated experiments.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Landseer encapsulates defenses as containerized modules, allowing existing and new techniques to be plugged in with minimal effort. Its evaluation engine automates experiments across multiple metrics, supporting the study of defenses both individually and in combination. After filtering 35 state-of-the-art defenses for reproducibility, the framework reveals gaps in replicability across defense families and supplies insights into the practical challenges of integrating multiple defenses at once.
What carries the argument
Containerized defense modules that plug into an automated evaluation engine for single and combined testing.
Load-bearing premise
That wrapping defenses inside containers preserves their original behavior and lets fair comparisons be made without new side effects.
What would settle it
A direct side-by-side test showing that a defense's measured performance or security properties change materially once it runs inside a Landseer container versus its original published code.
Figures


read the original abstract
Machine learning systems face diverse threats that undermine robustness, privacy, and fairness. Although many defenses have been proposed, each typically addresses a single risk in isolation. Real-world deployments, however, require these defenses to be composed to meet multiple guarantees simultaneously. The process of composing defenses is complex and not well understood, and its impact on performance and security remains unclear. We present Landseer, a modular framework for integrating machine learning (ML) defenses into the ML lifecycle and systematically evaluating their composition. Landseer encapsulates defenses as containerized modules, allowing existing and new techniques to be plugged in with minimal effort. Its evaluation engine automates experiments across multiple metrics, supporting the study of defenses both individually and in combination. In a preliminary study, we identified 35 state-of-the-art machine learning defenses. After filtering for reproducibility, we analyzed their performance using Landseer's unified evaluation process. Our findings reveal gaps in replicability across defense families and provide insights into the challenges and opportunities in integrating multiple defenses, establishing a foundation for improving the reliability of machine learning systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Landseer, a modular framework that encapsulates machine learning defenses as containerized modules for integration into the ML lifecycle and uses an automated evaluation engine to run experiments on individual defenses and their compositions across multiple metrics. A preliminary study identified 35 state-of-the-art defenses, filtered them for reproducibility, and applied the unified process to analyze performance, revealing replicability gaps across defense families along with insights into composition challenges.
Significance. If the containerized approach and evaluation engine can be shown to preserve original defense behavior and interactions, the work would provide a useful foundation for studying defense composition, an area that is important for real-world ML robustness but currently fragmented. The modular design and automation of multi-metric experiments are strengths that could support reproducible research on defense families if the fidelity concerns are addressed.
major comments (2)
- [Abstract] Abstract: the claim that the unified containerized evaluation process fairly assesses defenses and their compositions without introducing artifacts is load-bearing for the replicability-gap findings, yet no mechanism (differential testing, reference-output comparison, or environment-parity checks) is described to verify that containerized versions match native implementations.
- [Abstract] Abstract: the preliminary study reports replicability gaps after filtering 35 defenses, but supplies no concrete metrics, experimental protocol, reproducibility criteria, or quantitative results, leaving the central empirical claims unsupported.
minor comments (1)
- [Abstract] The abstract would be clearer if it explicitly listed the metrics used by the evaluation engine and the exact number of defenses that survived the reproducibility filter.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments correctly note that the abstract makes claims whose supporting details are not fully elaborated there. We address each point below and will revise the abstract (and body where appropriate) to strengthen the presentation.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the unified containerized evaluation process fairly assesses defenses and their compositions without introducing artifacts is load-bearing for the replicability-gap findings, yet no mechanism (differential testing, reference-output comparison, or environment-parity checks) is described to verify that containerized versions match native implementations.
Authors: We agree that the abstract does not describe verification mechanisms and that this is a substantive omission given the load-bearing role of the claim. The manuscript body explains the use of pinned dependencies and identical base images to reduce environment differences, but does not include explicit differential testing or reference-output comparisons. We will revise the abstract to state that fidelity was checked via performance consistency on standard benchmarks and will add a short fidelity subsection in the methods if space permits. revision: yes
-
Referee: [Abstract] Abstract: the preliminary study reports replicability gaps after filtering 35 defenses, but supplies no concrete metrics, experimental protocol, reproducibility criteria, or quantitative results, leaving the central empirical claims unsupported.
Authors: We agree that the abstract, as written, does not supply the requested concrete elements and therefore leaves the replicability-gap claims without visible support in that section. The full manuscript presents the protocol, criteria (reproduction within 5 % of originally reported accuracy on the defense's original benchmark), metrics, and quantitative outcomes in Section 5. We will revise the abstract to include a concise statement of the reproducibility criteria, the number of defenses that passed filtering, and the main observed gap (e.g., success rate by defense family). revision: yes
Circularity Check
No circularity: descriptive systems framework with no derivations or fitted quantities
full rationale
The paper presents Landseer as a containerized modular framework for composing and evaluating ML defenses. It describes identification of 35 defenses, filtering for reproducibility, and running them through a unified process, but contains no equations, predictions, fitted parameters, or derivation chains. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes. The central claims are about the framework's design and preliminary empirical observations on replicability gaps; these do not reduce to their own inputs by construction. This is the expected non-finding for a systems paper without mathematical content.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Goodfellow, H
Martín Abadi, Andy Chu, Ian J. Goodfellow, H. B. McMahan, Ilya Mironov, Kunal Talwar, and Li Zhang. 2016. Deep Learning with Differential Privacy.Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security (2016). https://api.semanticscholar.org/CorpusID:207241585
2016
-
[2]
Yossi Adi, Carsten Baum, Moustapha Cissé, Benny Pinkas, and Joseph Keshet
-
[3]
InUSENIX Security Symposium
Turning Your Weakness Into a Strength: Watermarking Deep Neu- ral Networks by Backdooring. InUSENIX Security Symposium. https://api. semanticscholar.org/CorpusID:3322503
-
[4]
Alekh Agarwal, Alina Beygelzimer, Miroslav Dudík, John Langford, and Hanna Wallach. 2018. A Reductions Approach to Fair Classification. arXiv:1803.02453 [cs.LG] https://arxiv.org/abs/1803.02453
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[5]
Towards Robust Interpretability with Self-Explaining Neural Networks
David Alvarez-Melis and T. Jaakkola. 2018. Towards Robust Interpretability with Self-Explaining Neural Networks.ArXivabs/1806.07538 (2018). https: //api.semanticscholar.org/CorpusID:49324194
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[6]
Eslam Amer and Ivan Zelinka. 2020. A dynamic Windows malware detection and prediction method based on contextual understanding of API call sequence. Computers & Security92 (2020), 101760. doi:10.1016/j.cose.2020.101760
-
[7]
Julia Angwin, Jeff Larson, Surya Mattu, and Lauren Kirchner. 2022. Machine bias. InEthics of data and analytics. Auerbach Publications, 254–264
2022
-
[8]
Apptainer. 2023. Apptainer. https://apptainer.org/
2023
-
[9]
Giovanni Apruzzese, Pavel Laskov, Edgardo Montes de Oca, Wissam Mallouli, Luis Brdalo Rapa, Athanasios Vasileios Grammatopoulos, and Fabio Di Franco
-
[10]
The Role of Machine Learning in Cybersecurity.Digital Threats4, 1, Article 8 (March 2023), 38 pages. doi:10.1145/3545574
-
[11]
2023.Fairness and machine learning: Limitations and opportunities
Solon Barocas, Moritz Hardt, and Arvind Narayanan. 2023.Fairness and machine learning: Limitations and opportunities. MIT press
2023
-
[12]
Battista Biggio, Blaine Nelson, and Pavel Laskov. 2012. Poisoning attacks against support vector machines.arXiv preprint arXiv:1206.6389(2012)
work page internal anchor Pith review Pith/arXiv arXiv 2012
-
[13]
Fowl, Amin Ghiasi, Jonas Geip- ing, Micah Goldblum, Tom Goldstein, and Arjun Gupta
Eitan Borgnia, Valeriia Cherepanova, Liam H. Fowl, Amin Ghiasi, Jonas Geip- ing, Micah Goldblum, Tom Goldstein, and Arjun Gupta. 2020. Strong Data Augmentation Sanitizes Poisoning and Backdoor Attacks Without an Accuracy Tradeoff.ICASSP 2021 - 2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)(2020), 3855–3859. https://...
2020
-
[14]
Barbara Bravi. 2024. Development and use of machine learning algorithms in vaccine target selection.npj Vaccines9, 1 (2024), 15
2024
-
[15]
Canonne, Gautam Kamath, and Thomas Steinke
Clément L. Canonne, Gautam Kamath, and Thomas Steinke. 2020. The Discrete Gaussian for Differential Privacy.ArXivabs/2004.00010 (2020). https://api. semanticscholar.org/CorpusID:214743526
- [16]
-
[17]
Nicholas Carlini, Chang Liu, Úlfar Erlingsson, Jernej Kos, and Dawn Song. 2019. The secret sharer: Evaluating and testing unintended memorization in neural networks. In28th USENIX security symposium (USENIX security 19). 267–284
2019
-
[18]
CCache Developers. 2026. ccache — compiler cache_2026. https://ccache.dev/
2026
-
[19]
Huili Chen, Bita Darvish Rouhani, and Farinaz Koushanfar. 2018. Black- Marks: Blackbox Multibit Watermarking for Deep Neural Networks.ArXiv abs/1904.00344 (2018). https://api.semanticscholar.org/CorpusID:90260955
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[20]
Huili Chen, Bita Darvish Rouhani, and Farinaz Koushanfar. 2018. DeepMarks: A Digital Fingerprinting Framework for Deep Neural Networks.IACR Cryptol. ePrint Arch.2018 (2018), 322. https://api.semanticscholar.org/CorpusID:4759464
2018
-
[21]
Huiqiang Chen, Tianqing Zhu, Tao Zhang, Wanlei Zhou, and Philip S. Yu. 2023. Privacy and Fairness in Federated Learning: On the Perspective of Tradeoff. ACM Comput. Surv.56, 2, Article 39 (Sept. 2023), 37 pages. doi:10.1145/3606017
-
[22]
Christopher A Choquette-Choo, Florian Tramer, Nicholas Carlini, and Nicolas Papernot. 2021. Label-only membership inference attacks. InInternational conference on machine learning. PMLR, 1964–1974
2021
-
[23]
Moustapha Cissé, Piotr Bojanowski, Edouard Grave, Yann Dauphin, and Nicolas Usunier. 2017. Parseval Networks: Improving Robustness to Adversarial Exam- ples.ArXivabs/1704.08847 (2017). https://api.semanticscholar.org/CorpusID: 26714567
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[24]
Gilad Cohen and Raja Giryes. 2021. Simple Post-Training Robustness using Test Time Augmentations and Random Forest.2024 IEEE/CVF Winter Conference on Applications of Computer Vision (W ACV)(2021), 3984–3994. https://api. semanticscholar.org/CorpusID:244709418
2021
-
[25]
Gilad Cohen and Raja Giryes. 2024. Simple post-training robustness using test time augmentations and random forest. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. 3996–4006
2024
-
[26]
Certified Adversarial Robustness via Randomized Smoothing
Jeremy M. Cohen, Elan Rosenfeld, and J. Zico Kolter. 2019. Certified Adversarial Robustness via Randomized Smoothing.ArXivabs/1902.02918 (2019). https: //api.semanticscholar.org/CorpusID:59842968
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[27]
Jesse Davis and Mark Goadrich. 2006. The relationship between Precision-Recall and ROC curves. InProceedings of the 23rd international conference on Machine learning. 233–240
2006
-
[28]
Kang Liu Brendan Dolan-Gavitt and Siddharth Garg. 2018. Fine-Pruning: De- fending Against Backdooring Attacks on Deep. InResearch in Attacks, Intrusions, and Defenses: 21st International Symposium, RAID 2018, Heraklion, Crete, Greece, September 10-12, 2018, Proceedings, Vol. 11050. Springer, 273
2018
-
[29]
Varshney
Flávio du Pin Calmon, Dennis Wei, Bhanukiran Vinzamuri, Karthikeyan Nate- san Ramamurthy, and Kush R. Varshney. 2017. Optimized Pre-Processing for Discrimination Prevention. InNeural Information Processing Systems. https: //api.semanticscholar.org/CorpusID:3801798
2017
-
[30]
Vasisht Duddu, Sebastian Szyller, and N. Asokan. 2024. SoK: Unintended Inter- actions among Machine Learning Defenses and Risks. In2024 IEEE Symposium on Security and Privacy (SP). 2996–3014. doi:10.1109/SP54263.2024.00243
- [31]
-
[32]
Kevin Eykholt, Ivan Evtimov, Earlence Fernandes, Bo Li, Amir Rahmati, Chaowei Xiao, Atul Prakash, Tadayoshi Kohno, and Dawn Song. 2018. Robust Physical- World Attacks on Deep Learning Models. arXiv:1707.08945 [cs.CR] https: //arxiv.org/abs/1707.08945
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[33]
Samuel G. Finlayson, John D. Bowers, Joichi Ito, Jonathan L. Zittrain, Andrew L. Beam, and Isaac S. Kohane. 2019. Adversarial attacks on medical machine learning.Science363, 6433 (2019), 1287–1289. arXiv:https://www.science.org/doi/pdf/10.1126/science.aaw4399 doi:10.1126/ science.aaw4399
-
[34]
Matt Fredrikson, Somesh Jha, and Thomas Ristenpart. 2015. Model Inversion Attacks that Exploit Confidence Information and Basic Countermeasures.Pro- ceedings of the 22nd ACM SIGSAC Conference on Computer and Communications Security(2015). https://api.semanticscholar.org/CorpusID:207229839
2015
-
[35]
Alex Gittens, Bülent Yener, and Moti Yung. 2022. An Adversarial Perspective on Accuracy, Robustness, Fairness, and Privacy: Multilateral-Tradeoffs in Trust- worthy ML.IEEE Access10 (2022), 120850–120865. doi:10.1109/ACCESS.2022. 3218715
-
[36]
Ian J Goodfellow, Jonathon Shlens, and Christian Szegedy. 2014. Explaining and harnessing adversarial examples.arXiv preprint arXiv:1412.6572(2014)
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[37]
Tianyu Gu, Brendan Dolan-Gavitt, and Siddharth Garg. 2017. Badnets: Identify- ing vulnerabilities in the machine learning model supply chain.arXiv preprint arXiv:1708.06733(2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[38]
Chuan Guo, Mayank Rana, Moustapha Cissé, and Laurens van der Maaten
-
[39]
Countering Adversarial Images using Input Transformations
Countering Adversarial Images using Input Transformations.ArXiv abs/1711.00117 (2018). https://api.semanticscholar.org/CorpusID:12308095
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[40]
Bo Han, Quanming Yao, Xingrui Yu, Gang Niu, Miao Xu, Weihua Hu, Ivor Wai-Hung Tsang, and Masashi Sugiyama. 2018. Co-teaching: Robust training of deep neural networks with extremely noisy labels. InNeural Information Processing Systems. https://api.semanticscholar.org/CorpusID:52065462
2018
-
[41]
Moritz Hardt, Eric Price, and Nathan Srebro. 2016. Equality of Opportunity in Supervised Learning.ArXivabs/1610.02413 (2016). https://api.semanticscholar. org/CorpusID:7567061
work page internal anchor Pith review Pith/arXiv arXiv 2016
- [42]
-
[43]
Jamie Hayes, Borja Balle, and M. Pawan Kumar. 2022. Learning to be ad- versarially robust and differentially private.CoRRabs/2201.02265 (2022). arXiv:2201.02265 https://arxiv.org/abs/2201.02265
-
[44]
Naoise Holohan, Stefano Braghin, Pól Mac Aonghusa, and Killian Levacher. 2019. Diffprivlib: the IBM differential privacy library.arXiv preprint arXiv:1907.02444 (2019)
work page internal anchor Pith review Pith/arXiv arXiv 2019
- [45]
-
[46]
Yerlan Idelbayev. [n. d.]. Proper ResNet Implementation for CIFAR10/CIFAR100 in PyTorch. https://github.com/akamaster/pytorch_resnet_cifar10. Accessed: 2025-05-06
2025
-
[47]
Ziyu Jiang, Tianlong Chen, Ting Chen, and Zhangyang Wang. 2020. Robust pre-training by adversarial contrastive learning.Advances in neural information processing systems33 (2020), 16199–16210
2020
-
[48]
Hamid Khayyam, Bahman Javadi, Mahdi Jalili, and Reza N. Jazar. 2020.Artificial Intelligence and Internet of Things for Autonomous Vehicles. Springer International Publishing, Cham, 39–68
2020
-
[49]
Cai, James Wexler, Fer- nanda B
Been Kim, Martin Wattenberg, Justin Gilmer, Carrie J. Cai, James Wexler, Fer- nanda B. Viégas, and Rory Sayres. 2017. Interpretability Beyond Feature At- tribution: Quantitative Testing with Concept Activation Vectors (TCAV). In International Conference on Machine Learning. https://api.semanticscholar.org/ CorpusID:51737170
2017
-
[50]
Jonathan Knauer, Phillip Rieger, Hossein Fereidooni, and Ahmad-Reza Sadeghi
-
[51]
In Proceedings of the 2024 on ACM SIGSAC Conference on Computer and Communi- cations Security
Phantom: Untargeted Poisoning Attacks on Semi-Supervised Learning. In Proceedings of the 2024 on ACM SIGSAC Conference on Computer and Communi- cations Security. 615–629
2024
- [52]
-
[53]
Artificial Intelligence as a Service
Kornel Lewicki, Michelle Seng Ah Lee, Jennifer Cobbe, and Jatinder Singh. 2023. Out of Context: Investigating the Bias and Fairness Concerns of “Artificial Intelligence as a Service”. InProceedings of the 2023 CHI Conference on Human Factors in Computing Systems(Hamburg, Germany)(CHI ’23). Association for Computing Machinery, New York, NY, USA, Article 13...
-
[54]
Lyu, Xixiang Lyu, Bo Li, and Xingjun Ma
Yige Li, Nodens Koren, L. Lyu, Xixiang Lyu, Bo Li, and Xingjun Ma. 2021. Neural Attention Distillation: Erasing Backdoor Triggers from Deep Neural Net- works.ArXivabs/2101.05930 (2021). https://api.semanticscholar.org/CorpusID: 231627799
-
[55]
Lyu, Bo Li, and Yugang Jiang
Yige Li, Xixiang Lyu, Xingjun Ma, Nodens Koren, L. Lyu, Bo Li, and Yugang Jiang
-
[56]
InInternational Conference on Machine Learning
Reconstructive Neuron Pruning for Backdoor Defense. InInternational Conference on Machine Learning. https://api.semanticscholar.org/CorpusID: 258865980
- [57]
-
[58]
Zachary C Lipton. 2018. The mythos of model interpretability: In machine learning, the concept of interpretability is both important and slippery.Queue 16, 3 (2018), 31–57
2018
-
[59]
Lan Liu, Yi Wang, Gaoyang Liu, Kai Peng, and Chen Wang. 2022. Membership inference attacks against machine learning models via prediction sensitivity. IEEE Transactions on Dependable and Secure Computing20, 3 (2022), 2341–2347
2022
-
[60]
Nils Lukas, Edward Jiang, Xinda Li, and Florian Kerschbaum. 2021. SoK: How Robust is Image Classification Deep Neural Network Watermarking?2022 IEEE Symposium on Security and Privacy (SP)(2021), 787–804. https://api. semanticscholar.org/CorpusID:236975869
2021
- [61]
-
[62]
Scott M Lundberg and Su-In Lee. 2017. A unified approach to interpreting model predictions.Advances in neural information processing systems30 (2017)
2017
-
[63]
Scott M Lundberg and Su-In Lee. 2017. A Unified Approach to Interpreting Model Predictions. InAdvances in Neural Information Processing Systems, I. Guyon, U. Von Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Gar- nett (Eds.), Vol. 30. Curran Associates, Inc. https://proceedings.neurips.cc/ paper_files/paper/2017/file/8a20a8621978632d7...
2017
-
[64]
Aleksander Madry, Aleksandar Makelov, Ludwig Schmidt, Dimitris Tsipras, and Adrian Vladu. 2017. Towards Deep Learning Models Resistant to Adversarial Attacks.ArXivabs/1706.06083 (2017). https://api.semanticscholar.org/CorpusID: 3488815
work page internal anchor Pith review Pith/arXiv arXiv 2017
- [65]
- [66]
-
[67]
Luca Melis, Congzheng Song, Emiliano De Cristofaro, and Vitaly Shmatikov
-
[68]
https://api
Exploiting Unintended Feature Leakage in Collaborative Learning.2019 IEEE Symposium on Security and Privacy (SP)(2018), 691–706. https://api. semanticscholar.org/CorpusID:53099247
2019
-
[69]
Dongyu Meng and Hao Chen. 2017. MagNet: A Two-Pronged Defense against Adversarial Examples.Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security(2017). https://api.semanticscholar.org/ CorpusID:3583538
2017
-
[70]
Dirk Merkel. 2014. Docker: lightweight Linux containers for consistent devel- opment and deployment.Linux J.2014, 239, Article 2 (March 2014)
2014
-
[71]
Ilya Mironov. 2017. Rényi differential privacy. In2017 IEEE 30th computer security foundations symposium (CSF). IEEE, 263–275
2017
-
[72]
Hoffman, Evaline Ju, Karthikeyan Natesan Ramamurthy, and Kush R
Manish Nagireddy, Moninder Singh, Samuel C. Hoffman, Evaline Ju, Karthikeyan Natesan Ramamurthy, and Kush R. Varshney. 2023. Function Com- position in Trustworthy Machine Learning: Implementation Choices, Insights, and Questions. arXiv:2302.09190 [cs.LG] https://arxiv.org/abs/2302.09190
-
[73]
Akm Iqtidar Newaz, Nur Imtiazul Haque, Amit Kumar Sikder, Moham- mad Ashiqur Rahman, and A. Selcuk Uluagac. 2020. Adversarial Attacks to Machine Learning-Based Smart Healthcare Systems. InGLOBECOM 2020 - 2020 IEEE Global Communications Conference. 1–6. doi:10.1109/GLOBECOM42002. 2020.9322472
-
[74]
Maximilian Noppel and Christian Wressnegger. 2024. SoK: Explainable Machine Learning in Adversarial Environments. In2024 IEEE Symposium on Security and Privacy (SP). 2441–2459. doi:10.1109/SP54263.2024.00021
-
[75]
Daryna Oliynyk, Rudolf Mayer, and Andreas Rauber. 2023. I Know What You Trained Last Summer: A Survey on Stealing Machine Learning Models and Defences.ACM Comput. Surv.55, 14s, Article 324 (July 2023), 41 pages. doi:10.1145/3595292
-
[76]
Daniel Olszewski, Allison Lu, Carson Stillman, Kevin Warren, Cole Kitroser, Alejandro Pascual, Divyajyoti Ukirde, Kevin Butler, and Patrick Traynor
-
[77]
Get in Researchers; We’re Measuring Reproducibility
"Get in Researchers; We’re Measuring Reproducibility": A Reproducibil- ity Study of Machine Learning Papers in Tier 1 Security Conferences(CCS ’23). Association for Computing Machinery, New York, NY, USA, 3433–3459. doi:10.1145/3576915.3623130
-
[78]
Open Container Initiative. 2015. Open Container Initiative. https:// opencontainers.org
2015
-
[79]
Nicolas Papernot, Patrick McDaniel, Arunesh Sinha, and Michael P. Wellman
-
[80]
In2018 IEEE European Symposium on Security and Privacy (EuroS&P)
SoK: Security and Privacy in Machine Learning. In2018 IEEE European Symposium on Security and Privacy (EuroS&P). 399–414. doi:10.1109/EuroSP. 2018.00035
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.