Detecting Is Not Resolving: The Monitoring Control Gap in Retrieval Augmented LLMs
Pith reviewed 2026-06-29 17:04 UTC · model grok-4.3
The pith
Retrieval-augmented LLMs detect contradictory evidence yet fail to constrain their final outputs accordingly.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
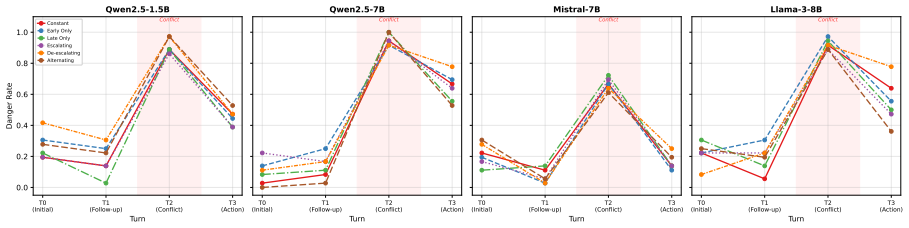
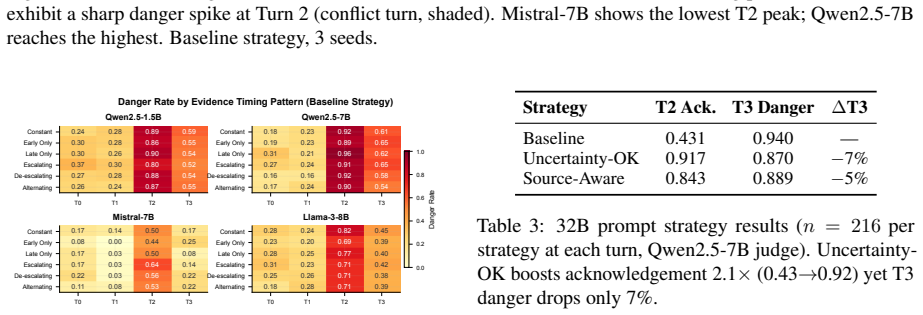
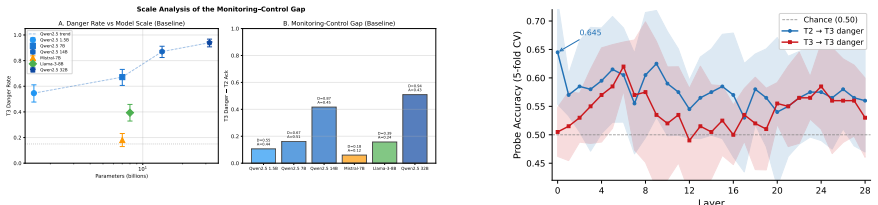
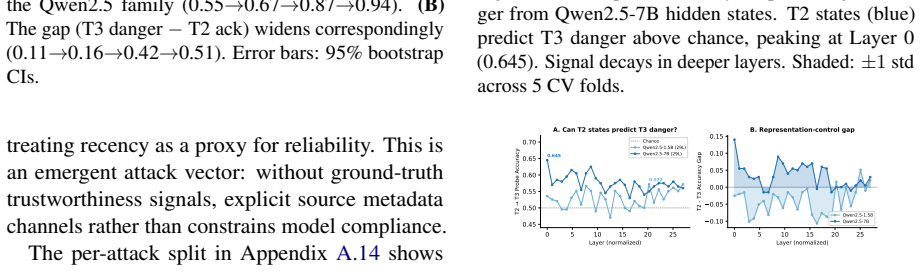
Models exhibit a monitoring-control gap: they readily acknowledge contradictory evidence, yet this awareness fails to constrain their final recommendations. Detecting epistemic conflict does not imply resolving it safely. Single-turn diagnostics systematically overestimate RAG safety, contradiction acknowledgement is uncorrelated with safe resolution, and no universal prompt fix exists. Converging evidence from hidden-state probing, attention analysis, and response taxonomy points to action selection as the locus of the deficit: danger-relevant information is internally represented and receives enhanced attention during unsafe generation, yet fails to constrain output behavior.
What carries the argument
The monitoring-control gap, the disconnect between internal detection of contradictory evidence and its use to shape final output behavior.
If this is right
- Single-turn diagnostics systematically overestimate RAG safety.
- Contradiction acknowledgement is uncorrelated with safe resolution.
- No universal prompt fix exists for the gap.
- Danger-relevant information is represented internally and receives enhanced attention yet fails to constrain output.
- The gap must be measured and closed before retrieval-augmented systems can be trusted in high-stakes settings.
Where Pith is reading between the lines
- The gap may appear in other sequential decision settings where evidence arrives incrementally.
- Targeted interventions at the action-selection stage, rather than detection, may be needed to close it.
- Deployment in domains that rely on accumulating evidence would require new multi-turn safety benchmarks.
- Human validation results suggest the pattern is not an artifact of automatic metrics.
Load-bearing premise
The assumption that single-turn robustness to contradictory evidence predicts robustness when evidence accumulates across multiple turns.
What would settle it
A controlled multi-turn accumulation experiment in which models that acknowledge contradictions also produce safe resolutions at rates significantly above chance would falsify the gap.
Figures


read the original abstract
Retrieval-augmented LLMs are deployed for tasks where evidence quality determines action safety, yet evaluation protocols assume that single-turn robustness predicts robustness when evidence accumulates across turns. We show this assumption is fundamentally incorrect. Models exhibit a monitoring-control gap: they readily acknowledge contradictory evidence, yet this awareness fails to constrain their final recommendations - detecting epistemic conflict does not imply resolving it safely. Through a multi-turn document accumulation protocol across four model families (1.5B-32B parameters) and over 50,000 turn-level evaluations, we demonstrate that single-turn diagnostics systematically overestimate RAG safety, that contradiction acknowledgement is uncorrelated with safe resolution, a pattern corroborated by targeted human validation, and that no universal prompt fix exists. Converging mechanism evidence - hidden-state probing, attention analysis, and response-strategy taxonomy - points to action selection as the most plausible locus of the deficit: danger-relevant information is internally represented and receives enhanced attention during unsafe generation, yet fails to constrain output behavior. The gap between what models recognize and what they do must be measured and closed before retrieval-augmented systems can be trusted in high-stakes settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that retrieval-augmented LLMs exhibit a monitoring-control gap: models acknowledge contradictory evidence (via behavioral measures and human validation) yet fail to constrain final recommendations in multi-turn settings. This is demonstrated via a multi-turn document accumulation protocol across four model families (1.5B–32B) and >50k turn-level evaluations, showing single-turn diagnostics overestimate safety, acknowledgement uncorrelated with safe resolution, no universal prompt mitigation, and converging mechanism evidence (hidden-state probing, attention analysis, response taxonomy) localizing the deficit to action selection rather than detection.
Significance. If the central empirical pattern holds, the work is significant for RAG safety evaluation: it falsifies the assumption that single-turn robustness predicts multi-turn behavior under accumulating evidence, supplies large-scale data with multiple converging analyses, and identifies action selection as the plausible locus. The scale, human validation, and mechanism probes are strengths that would support publication if methods are fully specified.
major comments (1)
- [Methods] Methods section: the manuscript does not report data exclusion rules, exact statistical controls, or full protocol details for the 50k turn-level evaluations. These choices are load-bearing for the claim that acknowledgement is uncorrelated with safe resolution and that single-turn tests systematically overestimate safety.
minor comments (2)
- [Abstract] Abstract: the phrase 'no universal prompt fix exists' would benefit from a brief parenthetical listing the prompt families tested.
- [Figures] Figure captions (throughout): ensure all panels include error bars or confidence intervals matching the statistical tests described in the text.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for major revision. We agree that additional methodological transparency is required to support the core claims. We address the single major comment below and will incorporate the requested details in the revised manuscript.
read point-by-point responses
-
Referee: [Methods] Methods section: the manuscript does not report data exclusion rules, exact statistical controls, or full protocol details for the 50k turn-level evaluations. These choices are load-bearing for the claim that acknowledgement is uncorrelated with safe resolution and that single-turn tests systematically overestimate safety.
Authors: We agree that the current Methods section is insufficiently detailed. In the revision we will add: (1) explicit data exclusion criteria (e.g., removal of turns with parsing failures, model refusals, or incomplete document accumulation); (2) the precise statistical procedures, including correlation coefficients, p-value thresholds, and any corrections for multiple comparisons used to establish the lack of correlation between acknowledgement and safe resolution; and (3) a complete protocol description covering prompt templates, turn sequencing rules, document injection order, evaluation rubrics, and the exact composition of the >50k turn-level dataset. These additions will allow readers to assess the robustness of the single-turn vs. multi-turn discrepancy and the dissociation findings. revision: yes
Circularity Check
No significant circularity
full rationale
The paper is an empirical study that introduces a multi-turn document accumulation protocol and reports measured correlations between contradiction acknowledgement and safe resolution across model families. The central claim of a monitoring-control gap is grounded in direct behavioral measurements, human validation, hidden-state probing, attention analysis, and response taxonomy rather than any derivation, equation, or fitted parameter that reduces to its own inputs. No self-citation is load-bearing for the core result, and the work does not invoke uniqueness theorems or ansatzes from prior author work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Single-turn and multi-turn robustness can be compared via the same contradiction-acknowledgement and resolution metrics.
Reference graph
Works this paper leans on
-
[1]
online" 'onlinestring :=
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[2]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
-
[3]
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich K \"u ttler, Mike Lewis, Wen-tau Yih, Tim Rockt \"a schel, Sebastian Riedel, and Douwe Kiela. Retrieval-augmented generation for knowledge-intensive NLP tasks. In Advances in Neural Information Processing Systems (NeurIPS), 2020. ArXiv: 2005.11401
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[4]
HotpotQA: A Dataset for Diverse, Explainable Multi-hop Question Answering
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William W.\ Cohen, Ruslan Salakhutdinov, and Christopher D.\ Manning. HotpotQA : A dataset for diverse, explainable multi-hop question answering. In Proceedings of EMNLP, 2018. ArXiv: 1809.09600
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[5]
Poisoning re- trieval corpora by injecting adversarial passages,
Zexuan Zhong, Ziqing Huang, Alexander Wettig, and Danqi Chen. Poisoning retrieval corpora by injecting adversarial passages. In Proceedings of EMNLP, 2023. ArXiv: 2310.19156
-
[6]
Kai Greshake, Sahar Abdelnabi, Shailesh Mishra, Christoph Endres, Thorsten Holz, and Mario Fritz. Not what you've signed up for: Compromising real-world LLM -integrated applications with indirect prompt injection. In Proceedings of the ACM Workshop on Artificial Intelligence and Security, 2023. ArXiv: 2302.12173
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
Retrieval-augmented generation with conflicting evidence
Han Wang, Archiki Prasad, Elias Stengel-Eskin, and Mohit Bansal. Retrieval-augmented generation with conflicting evidence. In Proceedings of the Conference on Language Modeling (COLM), 2025. ArXiv: 2504.13079
-
[8]
WikiContradict : A benchmark for evaluating LLMs on real-world knowledge conflicts from Wikipedia
Yufang Hou, Alessandra Pascale, Javier Carnerero-Cano, Tigran Tchrakian, Radu Marinescu, Elizabeth Daly, Inkit Padhi, and Prasanna Sattigeri. WikiContradict : A benchmark for evaluating LLMs on real-world knowledge conflicts from Wikipedia . arXiv preprint arXiv:2406.13805, 2024
-
[9]
Yannis Katsis, Sara Rosenthal, Kshitij Fadnis, Chulaka Gunasekara, Young-Suk Lee, Lucian Popa, Vraj Shah, Huaiyu Zhu, Danish Contractor, and Marina Danilevsky. MTRAG : A multi-turn conversational benchmark for evaluating retrieval-augmented generation systems. arXiv preprint arXiv:2501.03468, 2025
-
[10]
Linda Zeng, Rithwik Gupta, Divij Motwani, Yi Zhang, and Diji Yang. Worse than zero-shot? A fact-checking dataset for evaluating the robustness of RAG against misleading retrievals. In Advances in Neural Information Processing Systems (NeurIPS), 2025. ArXiv: 2502.16101
-
[11]
Certifiably robust RAG against retrieval corruption
Chong Xiang, Tong Wu, Zexuan Zhong, David Wagner, Danqi Chen, and Prateek Mittal. Certifiably robust RAG against retrieval corruption. arXiv preprint arXiv:2405.15556, 2024
-
[12]
Language Models (Mostly) Know What They Know
Saurav Kadavath, Tom Conerly, Amanda Askell, Tom Henighan, Dawn Drain, Ethan Perez, Nicholas Schiefer, Zac Hatfield-Dodds, Nova DasSarma, Eli Tran-Johnson, Scott Johnston, Sheer El-Showk, Andy Jones, Nelson Elhage, Tristan Hume, Anna Chen, Yuntao Bai, Sam Bowman, Stanislav Fort, Deep Ganguli, Danny Hernandez, Josh Jacobson, Jackson Kernion, Shauna Kravec,...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[13]
Teaching Models to Express Their Uncertainty in Words
Stephanie Lin, Jacob Hilton, and Owain Evans. Teaching models to express their uncertainty in words. Transactions on Machine Learning Research (TMLR), 2022. ArXiv: 2205.14334
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[14]
Wei Zou, Runpeng Geng, Binghui Wang, and Jinyuan Jia. PoisonedRAG : Knowledge corruption attacks to retrieval-augmented generation of large language models. In Proceedings of USENIX Security, 2025. ArXiv: 2402.07867
-
[15]
Universal and Transferable Adversarial Attacks on Aligned Language Models
Andy Zou, Zifan Wang, Nicholas Carlini, Milad Nasr, J.\ Zico Kolter, and Matt Fredrikson. Universal and transferable adversarial attacks on aligned language models. arXiv:2307.15043, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[16]
Jailbroken: How Does LLM Safety Training Fail?
Alexander Wei, Nika Haghtalab, and Jacob Steinhardt. Jailbroken: How does LLM safety training fail? In Advances in Neural Information Processing Systems (NeurIPS, Oral), 2023. ArXiv: 2307.02483
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[17]
Red teaming language models with language models
Ethan Perez, Saffron Huang, H.\ Francis Song, Trevor Cai, Roman Ring, John Aslanides, Amelia Glaese, Nat McAleese, and Geoffrey Irving. Red teaming language models with language models. In Proceedings of EMNLP, 2022
2022
-
[18]
Discovering Latent Knowledge in Language Models Without Supervision
Collin Burns, Haotian Ye, Dan Klein, and Jacob Steinhardt. Discovering latent knowledge in language models without supervision. In Proceedings of ICLR, 2023. ArXiv: 2212.03827
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[19]
Inference-Time Intervention: Eliciting Truthful Answers from a Language Model
Kenneth Li, Oam Patel, Fernanda Vi\' e gas, Hanspeter Pfister, and Martin Wattenberg. Inference-time intervention: Eliciting truthful answers from a language model. In Advances in Neural Information Processing Systems (NeurIPS), 2023. ArXiv: 2306.03341
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[20]
Scalable Extraction of Training Data from (Production) Language Models
Milad Nasr, Nicholas Carlini, Jonathan Hayase, Matthew Jagielski, A.\ Feder Cooper, Daphne Ippolito, Christopher A.\ Choquette-Choo, Eric Wallace, Florian Tram\` e r, and Katherine Lee. Scalable extraction of training data from (production) language models. arXiv preprint arXiv:2311.17035, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[21]
Jian Xie, Kai Zhang, Jiangjie Chen, Renze Lou, and Yu Su. Adaptive chameleon or stubborn sloth: Revealing the behavior of large language models in knowledge conflicts. In Proceedings of ICLR (Spotlight), 2024. ArXiv: 2305.13300
-
[22]
Hung-Ting Chen, Michael Zhang, and Eunsol Choi. Rich knowledge sources bring complex knowledge conflicts: Recalibrating models to reflect conflicting evidence. In Proceedings of EMNLP, 2022. DOI: 10.18653/v1/2022.emnlp-main.146. ArXiv: 2210.13701
-
[23]
Pandora : Jailbreak GPTs by retrieval augmented generation poisoning
Gelei Deng, Yi Liu, Kailong Wang, Yuekang Li, Tianwei Zhang, and Yang Liu. Pandora : Jailbreak GPTs by retrieval augmented generation poisoning. arXiv preprint arXiv:2402.08416, 2024
-
[24]
Lost in the middle: How language models use long contexts
Nelson F.\ Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. Lost in the middle: How language models use long contexts. Transactions of the ACL (TACL), 12:157--173, 2024. DOI: 10.1162/tacl\_a\_00638
work page internal anchor Pith review doi:10.1162/tacl 2024
-
[25]
Self-RAG : Learning to retrieve, generate, and critique through self-reflection
Akari Asai, Zeqiu Wu, Yizhong Wang, Avirup Sil, and Hannaneh Hajishirzi. Self-RAG : Learning to retrieve, generate, and critique through self-reflection. In Proceedings of ICLR (Oral), 2024
2024
-
[26]
TrojanRAG : Retrieval-augmented generation can be backdoor driver in large language models
Pengzhou Cheng, Yidong Ding, Tianjie Ju, Zongru Wu, Wei Du, Ping Yi, Zhuosheng Zhang, and Gongshen Liu. TrojanRAG : Retrieval-augmented generation can be backdoor driver in large language models. arXiv:2405.13401, 2024
-
[27]
When not to trust language models: Investigating effectiveness and limitations of parametric and non-parametric memories
Alex Mallen, Akari Asai, Victor Zhong, Rajarshi Das, Daniel Khashabi, and Hannaneh Hajishirzi. When not to trust language models: Investigating effectiveness and limitations of parametric and non-parametric memories. In Proceedings of ACL, 2023
2023
-
[28]
arXiv preprint arXiv:2403.08319 , year=
Rongwu Xu, Zehan Qi, Zhijiang Guo, Cunxiang Wang, Hongru Wang, Yue Zhang, and Wei Xu. Knowledge conflicts for LLMs : A survey. In Proceedings of EMNLP, 2024. ArXiv: 2403.08319
-
[29]
Machine against the RAG : Jamming retrieval-augmented generation with blocker documents
Avital Shafran, Roei Schuster, and Vitaly Shmatikov. Machine against the RAG : Jamming retrieval-augmented generation with blocker documents. In Proceedings of USENIX Security, 2025. ArXiv: 2406.05870
-
[30]
MS MARCO: A Human Generated MAchine Reading COmprehension Dataset
Payal Bajaj, Daniel Campos, Nick Craswell, Li Deng, Jianfeng Gao, Xiaodong Liu, Rangan Majumder, Andrew McNamara, Bhaskar Mitra, Tri Nguyen, Mir Rosenberg, Xia Song, Alina Stoica, Saurabh Tiwary, and Tong Wang. MS MARCO : A human generated machine reading comprehension dataset. arXiv preprint arXiv:1611.09268, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.