Query Symbolically or Retrieve Semantically? A Dataset and Method for Semi-Structured Question Answering
Pith reviewed 2026-06-29 17:00 UTC · model grok-4.3
The pith
DualGraph improves semi-structured question answering by maintaining both a textual knowledge graph for semantic retrieval and a symbolic knowledge graph for precise triple-based queries.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
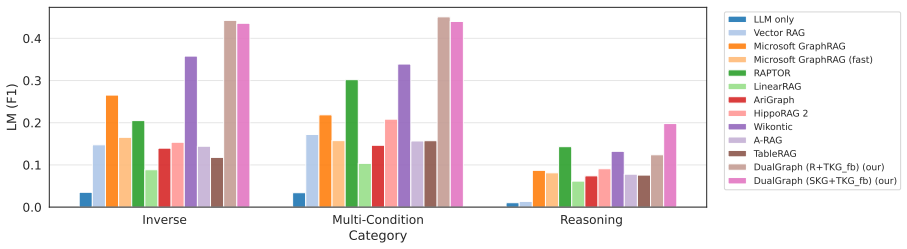
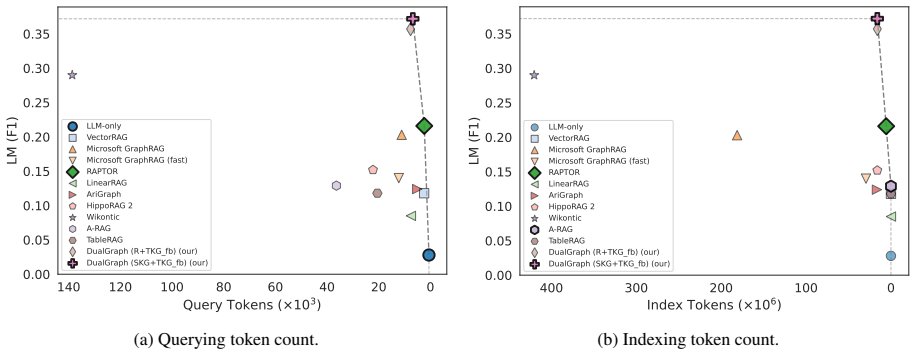
DualGraph represents each document through a Textual Knowledge Graph suited to semantic similarity search and a Symbolic Knowledge Graph that stores typed subject-predicate-object triples, then applies multiple selection or combination strategies to retrieve evidence; this dual representation yields higher accuracy than either semantic-only or symbolic-only methods on semi-structured corpora.
What carries the argument
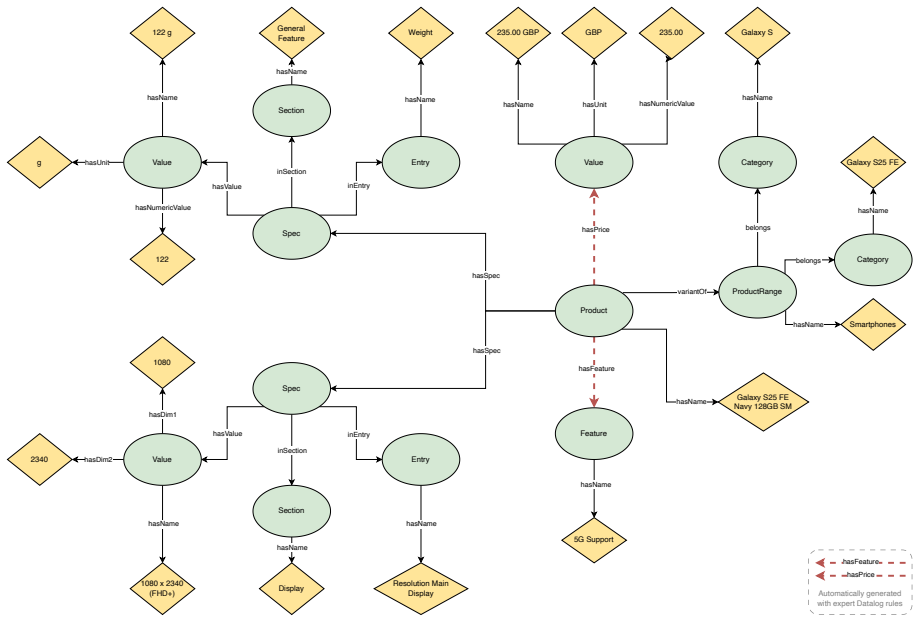
DualGraph framework that builds and fuses a Textual Knowledge Graph for semantic retrieval with a Symbolic Knowledge Graph for exact querying over typed triples.
If this is right
- The hybrid approach improves accuracy on both open-ended semantic questions and specification-oriented questions that require exact attribute matching or aggregation.
- Symbolic querying supplies operations such as filtering and exhaustive enumeration that pure dense retrieval misses on structured attributes.
- The framework remains effective on noisy natural-language documents where a purely symbolic system would fail.
- SpecsQA provides a reusable test set for evaluating any method that must handle both semantic and structured requirements on product-style data.
Where Pith is reading between the lines
- The same dual-graph construction could be tested on other semi-structured domains such as regulatory filings or scientific tables where both fuzzy matches and precise numeric comparisons appear.
- Advances in automatic triple extraction quality would be expected to widen the performance gap between DualGraph and semantic-only baselines.
- The SpecsQA dataset could become a standard yardstick for measuring progress on hybrid retrieval systems.
Load-bearing premise
Reliable symbolic triples can be extracted from noisy natural-language product documents at scale without introducing errors that undermine the symbolic component.
What would settle it
If DualGraph performance on SpecsQA drops to or below the strongest semantic baseline once the symbolic graph is removed or its triples are replaced with noisy extractions, the central claim does not hold.
Figures




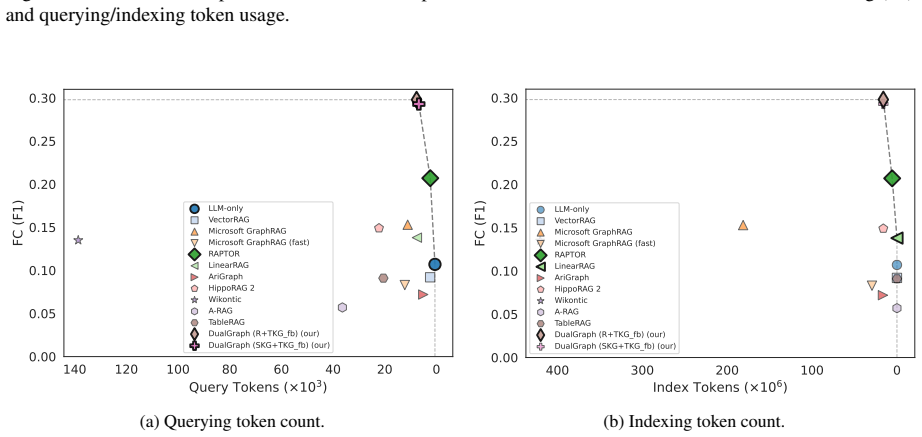





read the original abstract
Retrieval-Augmented Generation (RAG) systems for question answering typically retrieve evidence by semantic similarity between the query and document chunks. While effective for unstructured text, this approach is less reliable on semi-structured corpora where answering may require exact filtering, aggregation, or exhaustive retrieval over structured attributes across multiple documents. Symbolic approaches support such operations, but they are often brittle on noisy natural-language corpora. We address this gap with DualGraph, a RAG framework that represents documents through two complementary views: a Textual Knowledge Graph for semantic retrieval and a Symbolic Knowledge Graph for symbolic querying over typed subject--predicate--object triples. Building on these two components, we provide multiple strategies for selecting or combining semantic and symbolic evidence.We also introduce SpecsQA, a benchmark from a commercial shopping website with semi-structured product documents and manually curated questions spanning open-ended and specification-oriented retrieval. Experiments show that DualGraph consistently outperforms state-of-the-art dense-retrieval, GraphRAG, symbolic, and table-oriented baselines across question types.Code and data are available at https://github.com/corneliocristina/DualGraphRAG.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DualGraph, a hybrid RAG framework that maintains a Textual Knowledge Graph for semantic retrieval alongside a Symbolic Knowledge Graph of typed S-P-O triples to enable exact filtering, aggregation, and exhaustive operations on semi-structured documents. It also releases SpecsQA, a new benchmark of commercial product documents paired with manually curated questions spanning open-ended and specification-oriented types. Experiments claim that DualGraph consistently outperforms dense-retrieval, GraphRAG, symbolic, and table-oriented baselines across question categories.
Significance. If the reported gains hold after verification of the symbolic component, the work demonstrates a practical hybrid strategy for semi-structured QA that leverages complementary strengths of semantic similarity and symbolic reasoning. The public release of code, data, and benchmark strengthens reproducibility and enables follow-on research.
major comments (3)
- [Symbolic KG construction] Symbolic Knowledge Graph construction section: No precision, recall, or error-rate metrics are reported for the extraction of typed S-P-O triples from noisy product text. This extraction step is load-bearing for the central claim that the symbolic component supplies reliable exact operations unavailable to semantic retrieval; without these numbers the outperformance could be illusory or non-reproducible.
- [Experiments] Experiments section: No ablation results are shown for the multiple strategies that select or combine semantic and symbolic evidence. The absence of these controls prevents isolation of which component drives the reported gains over baselines.
- [Results] Results tables: Performance numbers lack error bars, standard deviations across runs, or statistical significance tests. This weakens the assertion of consistent outperformance across question types.
minor comments (2)
- [Method] Clarify in the method section how the symbolic extraction pipeline is implemented (LLM-based, rule-based, or hybrid) and whether the same pipeline is used for the symbolic baselines.
- [Figures] Figure captions and legends could more explicitly distinguish the Textual KG from the Symbolic KG to aid readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and will incorporate revisions to strengthen the paper.
read point-by-point responses
-
Referee: [Symbolic KG construction] Symbolic Knowledge Graph construction section: No precision, recall, or error-rate metrics are reported for the extraction of typed S-P-O triples from noisy product text. This extraction step is load-bearing for the central claim that the symbolic component supplies reliable exact operations unavailable to semantic retrieval; without these numbers the outperformance could be illusory or non-reproducible.
Authors: We agree that metrics on the symbolic extraction quality are necessary to support the central claims. In the revised manuscript we will add a new subsection under Symbolic KG construction that reports precision, recall, and F1 on a manually annotated sample of product documents, together with a qualitative error analysis. This will allow readers to assess the reliability of the typed S-P-O triples. revision: yes
-
Referee: [Experiments] Experiments section: No ablation results are shown for the multiple strategies that select or combine semantic and symbolic evidence. The absence of these controls prevents isolation of which component drives the reported gains over baselines.
Authors: We acknowledge that the current experiments do not isolate the contribution of each combination strategy. We will add a dedicated ablation study in the revised Experiments section that evaluates every individual strategy (semantic-only, symbolic-only, and each hybrid variant) on SpecsQA, thereby clarifying which components are responsible for the observed improvements. revision: yes
-
Referee: [Results] Results tables: Performance numbers lack error bars, standard deviations across runs, or statistical significance tests. This weakens the assertion of consistent outperformance across question types.
Authors: We agree that variability measures and significance testing would strengthen the results. In the revision we will rerun the main experiments with multiple random seeds, report standard deviations in the tables, and include paired statistical significance tests (e.g., McNemar or t-tests) comparing DualGraph against each baseline across question categories. revision: yes
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper introduces a new benchmark (SpecsQA) from commercial product documents and a DualGraph framework combining Textual KG for semantic retrieval with Symbolic KG for typed S-P-O queries. The central claim is empirical outperformance versus external baselines (dense retrieval, GraphRAG, symbolic, table-oriented) on this new data. No equations, parameter-fitting steps, or self-citations are shown that reduce the reported gains to construction from the inputs themselves. The extraction pipeline is presented as an engineering component whose accuracy is not quantified here, but that is a correctness/assumption issue rather than a circular derivation. The evaluation uses a freshly curated test set and external comparators, satisfying the criteria for a non-circular result.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
online" 'onlinestring :=
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[2]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
-
[3]
Petr Anokhin, Nikita Semenov, Artyom Sorokin, Dmitry Evseev, Andrey Kravchenko, Mikhail Burtsev, and Evgeny Burnaev. 2025. https://doi.org/10.24963/ijcai.2025/2 Arigraph: Learning knowledge graph world models with episodic memory for llm agents . In Proceedings of the Thirty-Fourth International Joint Conference on Artificial Intelligence, IJCAI-25 , page...
-
[4]
Jonathan Berant, Andrew Chou, Roy Frostig, and Percy Liang. 2013. https://aclanthology.org/D13-1160/ Semantic parsing on F reebase from question-answer pairs . In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, pages 1533--1544, Seattle, Washington, USA. Association for Computational Linguistics
2013
- [5]
-
[6]
Chia-Yuan Chang, Zhimeng Jiang, Vineeth Rakesh, Menghai Pan, Chin-Chia Michael Yeh, Guanchu Wang, Mingzhi Hu, Zhichao Xu, Yan Zheng, Mahashweta Das, and Na Zou. 2025. https://doi.org/10.18653/v1/2025.acl-long.131 MAIN - RAG : Multi-agent filtering retrieval-augmented generation . In Proceedings of the 63rd Annual Meeting of the Association for Computation...
-
[7]
Wenhu Chen, Hanwen Zha, Zhiyu Chen, Wenhan Xiong, Hong Wang, and William Yang Wang. 2020. https://aclanthology.org/2020.findings-emnlp.91/ HybridQA : A dataset of multi-hop question answering over tabular and textual data . In Findings of EMNLP 2020, pages 1026--1036
2020
-
[8]
Zhiyu Chen, Wenhu Chen, Charese Smiley, Sameena Shah, Iana Borova, Dylan Langdon, Reema Moussa, Matt Beane, Ting-Hao Huang, Bryan Routledge, and William Yang Wang. 2021. https://aclanthology.org/2021.emnlp-main.300/ FinQA : A dataset of numerical reasoning over financial data . In Proceedings of EMNLP 2021, pages 3697--3711
2021
-
[9]
Zhiyu Chen, Shiyang Li, Charese Smiley, Zhiqiang Ma, Sameena Shah, and William Yang Wang. 2022. https://doi.org/10.18653/v1/2022.emnlp-main.421 C onv F in QA : Exploring the chain of numerical reasoning in conversational finance question answering . In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 6279--6292...
-
[10]
Zihan Chen, Lei Zheng, and Di Zhu. 2026. https://papers.ssrn.com/sol3/papers.cfm?abstract_id=6713979 A survey of agentic graphrag: From retrieval-augmented generation to graph-native agents . (6713979)
2026
- [11]
- [12]
-
[13]
Darren Edge, Ha Trinh, Newman Cheng, Joshua Bradley, Alex Chao, Apurva Mody, Steven Truitt, Dasha Metropolitansky, Robert Osazuwa Ness, and Jonathan Larson. 2025. https://arxiv.org/abs/2404.16130 From local to global: A graph rag approach to query-focused summarization . Preprint, arXiv:2404.16130
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
Vincent Emonet, Jerven Bolleman, Severine Duvaud, Tarcisio Mendes de Farias, and Ana Claudia Sima. 2025. Llm-based sparql query generation from natural language over federated knowledge graphs. In ISWC 2024 Special Session on Harmonising Generative AI and Semantic Web Technologies, November 13, 2024, Baltimore, Maryland, volume 3953 of CEUR Workshop Proce...
2025
- [15]
-
[16]
Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yixin Dai, Jiawei Sun, Haofen Wang, Haofen Wang, and 1 others. 2023. Retrieval-augmented generation for large language models: A survey. arXiv preprint arXiv:2312.10997, 2(1):32
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[17]
Bernal Jiménez Gutiérrez, Yiheng Shu, Yu Gu, Michihiro Yasunaga, and Yu Su. 2024. https://openreview.net/forum?id=hkujvAPVsg Hipporag: Neurobiologically inspired long-term memory for large language models . In The Thirty-eighth Annual Conference on Neural Information Processing Systems
2024
-
[18]
Bernal Jiménez Gutiérrez, Yiheng Shu, Weijian Qi, Sizhe Zhou, and Yu Su. 2025. https://arxiv.org/abs/2502.14802 From rag to memory: Non-parametric continual learning for large language models . Preprint, arXiv:2502.14802
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
Xanh Ho, Anh-Khoa Duong Nguyen, Saku Sugawara, and Akiko Aizawa. 2020. https://arxiv.org/abs/2011.01060 Constructing a multi-hop qa dataset for comprehensive evaluation of reasoning steps . Preprint, arXiv:2011.01060
work page internal anchor Pith review Pith/arXiv arXiv 2020
- [20]
- [21]
-
[22]
Mandar Joshi, Eunsol Choi, Daniel Weld, and Luke Zettlemoyer. 2017. https://doi.org/10.18653/v1/P17-1147 T rivia QA : A large scale distantly supervised challenge dataset for reading comprehension . In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1601--1611, Vancouver, Canada. Assoc...
-
[23]
Kezhi Kong, Jiani Zhang, Zhengyuan Shen, Balasubramaniam Srinivasan, Chuan Lei, Christos Faloutsos, Huzefa Rangwala, and George Karypis. 2024. Opentab: Advancing large language models as open-domain table reasoners. arXiv preprint arXiv:2402.14361. ICLR 2024, Code: https://github.com/amazon-science/llm-open-domain-table-reasoner
-
[24]
Dai, Jakob Uszkoreit, Quoc Le, and Slav Petrov
Tom Kwiatkowski, Jennimaria Palomaki, Olivia Redfield, Michael Collins, Ankur Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Jacob Devlin, Kenton Lee, Kristina Toutanova, Llion Jones, Matthew Kelcey, Ming-Wei Chang, Andrew M. Dai, Jakob Uszkoreit, Quoc Le, and Slav Petrov. 2019. https://doi.org/10.1162/tacl_a_00276 Natural questions: A benchma...
-
[25]
u ttler, Mike Lewis, Wen-tau Yih, Tim Rockt\
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich K\" u ttler, Mike Lewis, Wen-tau Yih, Tim Rockt\" a schel, Sebastian Riedel, and Douwe Kiela. 2020. https://proceedings.neurips.cc/paper_files/paper/2020/file/6b493230205f780e1bc26945df7481e5-Paper.pdf Retrieval-augmented generation for knowledge-intens...
2020
-
[26]
Feiyang Li, Peng Fang, Zhan Shi, Arijit Khan, Fang Wang, Weihao Wang, Zhangxin-hw, and Yongjian Cui. 2025 a . https://doi.org/10.18653/v1/2025.findings-emnlp.168 CoT - RAG : Integrating chain of thought and retrieval-augmented generation to enhance reasoning in large language models . In Findings of the Association for Computational Linguistics: EMNLP 202...
-
[27]
Yangning Li, Weizhi Zhang, Yuyao Yang, Wei-Chieh Huang, Yaozu Wu, Junyu Luo, Yuanchen Bei, Henry Peng Zou, Xiao Luo, Yusheng Zhao, and 1 others. 2025 b . A survey of rag-reasoning systems in large language models. In Findings of the Association for Computational Linguistics: EMNLP 2025, pages 12120--12145
2025
- [28]
-
[29]
Reza Yousefi Maragheh, Pratheek Vadla, Priyank Gupta, Kai Zhao, Aysenur Inan, Kehui Yao, Jianpeng Xu, Praveen Kanumala, Jason Cho, and Sushant Kumar. 2025. https://arxiv.org/abs/2506.21931 ARAG : Agentic retrieval augmented generation for personalized recommendation . In Proceedings of the 48th ACM SIGIR Conference (SIGIR 2025)
-
[30]
Belinda Mo, Kyssen Yu, Joshua Kazdan, Proud Mpala, Lisa Yu, Chris Cundy, Charilaos I. Kanatsoulis, and Sanmi Koyejo. 2025. Kggen: Extracting knowledge graphs from plain text with language models. CoRR, abs/2502.09956
- [31]
- [32]
-
[33]
OpenAI. 2025. https://arxiv.org/abs/2508.10925 gpt-oss-120b & gpt-oss-20b model card . Preprint, arXiv:2508.10925
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
Panupong Pasupat and Percy Liang. 2015. https://aclanthology.org/P15-1142/ Compositional semantic parsing on semi-structured tables . In Proceedings of ACL 2015, pages 1470--1480
2015
-
[35]
Boci Peng, Yun Zhu, Yongchao Liu, Xiaohe Bo, Haizhou Shi, Chuntao Hong, Yan Zhang, and Siliang Tang. 2025. https://doi.org/10.1145/3777378 Graph retrieval-augmented generation: A survey . ACM Trans. Inf. Syst., 44(2)
-
[36]
Pydantic. 2023. https://github.com/pydantic/pydantic-ai pydantic/pydantic-ai: Genai agent framework, the pydantic way . [Online; accessed 2026-01-30]
2023
-
[37]
Rishiraj Saha Roy, Chris Hinze, Joel Schlotthauer, Farzad Naderi, Viktor Hangya, Andreas Foltyn, Luzian Hahn, and Fabian K \" u ch. 2025. https://doi.org/10.18420/BTW2025-43 RAGONITE: iterative retrieval on induced databases and verbalized RDF for conversational QA over kgs with RAG . In Datenbanksysteme f \" u r Business, Technologie und Web (BTW 2025), ...
-
[38]
Rishiraj Saha Roy, Chris Hinze, Joel Schlotthauer, Farzad Naderi, Viktor Hangya, Andreas Foltyn, Luzian Hahn, and Fabian Kuech. 2024. https://arxiv.org/abs/2412.17690 Ragonite: Iterative retrieval on induced databases and verbalized rdf for conversational qa over kgs with rag . Preprint, arXiv:2412.17690
-
[39]
Parth Sarthi, Salman Abdullah, Aditi Tuli, Shubh Khanna, Anna Goldie, and Christopher D. Manning. 2024. https://openreview.net/forum?id=GN921JHCRw RAPTOR: recursive abstractive processing for tree-organized retrieval . In The Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024 . OpenReview.net
2024
-
[40]
Aditi Singh, Abul Ehtesham, Saket Kumar, and Tala Talaei Khoei. 2025. Agentic retrieval-augmented generation: A survey on agentic rag. arXiv preprint arXiv:2501.09136
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [41]
-
[42]
Jan Strich, Enes Kutay Isgorur, Maximilian Trescher, Chris Biemann, and Martin Semmann. 2026. https://doi.org/10.18653/v1/2026.eacl-long.8 T ^2 - RAGB ench: Text-and-table benchmark for evaluating retrieval-augmented generation . In Proceedings of the 19th Conference of the E uropean Chapter of the A ssociation for C omputational L inguistics (Volume 1: L...
-
[43]
Alon Talmor and Jonathan Berant. 2018. https://doi.org/10.18653/v1/N18-1059 The web as a knowledge-base for answering complex questions . In Proceedings of the 2018 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers) , pages 641--651, New Orleans, Louisiana. Associ...
-
[44]
Harsh Trivedi, Niranjan Balasubramanian, Tushar Khot, and Ashish Sabharwal. 2022. https://aclanthology.org/2022.tacl-1.31/ MuSiQue : Multihop questions via single-hop question composition . TACL, 10:539--554
2022
-
[45]
Ryszard Tuora, Mateusz Galiński, Michał Godziszewski, Michał Karpowicz, Mateusz Czyżnikiewicz, Adam Kozakiewicz, and Tomasz Ziętkiewicz. 2026. https://arxiv.org/abs/2603.29875 Unweaving the knots of graphrag -- turns out vectorrag is almost enough . Preprint, arXiv:2603.29875
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[46]
VibrantLabs. 2024. Ragas: Supercharge your llm application evaluations. https://github.com/vibrantlabsai/ragas
2024
-
[47]
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William Cohen, Ruslan Salakhutdinov, and Christopher D. Manning. 2018. https://aclanthology.org/D18-1259/ HotpotQA : A dataset for diverse, explainable multi-hop question answering . In Proceedings of EMNLP 2018, pages 2369--2380
2018
-
[48]
Tao Yu, Rui Zhang, Kai Yang, Michihiro Yasunaga, Dongxu Wang, Zifan Li, James Ma, Irene Li, Qingning Yao, Shanelle Roman, Zilin Zhang, and Dragomir Radev. 2018. https://doi.org/10.18653/v1/D18-1425 S pider: A large-scale human-labeled dataset for complex and cross-domain semantic parsing and text-to- SQL task . In Proceedings of the 2018 Conference on Emp...
-
[50]
Xiaohan Yu, Pu Jian, and Chong Chen. 2025 b . https://doi.org/10.18653/v1/2025.emnlp-main.710 T able RAG : A retrieval augmented generation framework for heterogeneous document reasoning . In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 14063--14082, Suzhou, China. Association for Computational Linguistics
- [51]
-
[52]
Xiaohan Yu, Zhihan Yang, and Chong Chen. 2025 d . https://arxiv.org/abs/2501.15470 CogPlanner : Unveiling the potential of agentic multimodal retrieval augmented generation with planning . In Proceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR 2025)
-
[53]
Yanzhao Zhang, Mingxin Li, Dingkun Long, Xin Zhang, Huan Lin, Baosong Yang, Pengjun Xie, An Yang, Dayiheng Liu, Junyang Lin, Fei Huang, and Jingren Zhou. 2025. Qwen3 embedding: Advancing text embedding and reranking through foundation models. arXiv preprint arXiv:2506.05176
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[54]
Victor Zhong, Caiming Xiong, and Richard Socher. 2017. https://arxiv.org/abs/1709.00103 Seq2sql: Generating structured queries from natural language using reinforcement learning . Preprint, arXiv:1709.00103
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[55]
Hongli Zhou, Hui Huang, Yunfei Long, Bing Xu, Conghui Zhu, Hailong Cao, Muyun Yang, and Tiejun Zhao. 2024. Mitigating the bias of large language model evaluation. In Proceedings of the 23rd Chinese National Conference on Computational Linguistics (Volume 1: Main Conference), pages 1310--1319
2024
-
[56]
Fengbin Zhu, Wenqiang Lei, Youcheng Huang, Chao Wang, Shuo Zhang, Jiancheng Lv, Fuli Feng, and Tat-Seng Chua. 2021. https://aclanthology.org/2021.acl-long.254/ TAT-QA : A question answering benchmark on a hybrid of tabular and textual content in finance . In Proceedings of ACL-IJCNLP 2021, pages 3277--3287
2021
- [57]
-
[58]
Jiaru Zou, Dongqi Fu, Sirui Chen, Xinrui He, Zihao Li, Yada Zhu, Jiawei Han, and Jingrui He. 2025. https://arxiv.org/abs/2504.01346 Rag over tables: Hierarchical memory index, multi-stage retrieval, and benchmarking . arXiv preprint arXiv:2504.01346. Code: https://github.com/jiaruzouu/T-RAG
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.