GraphReview: Scientific Paper Evaluation via LLM-Based Graph Message Passing
Pith reviewed 2026-06-29 18:24 UTC · model grok-4.3
The pith
GraphReview evaluates scientific papers by passing LLM review signals across a graph of related works.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
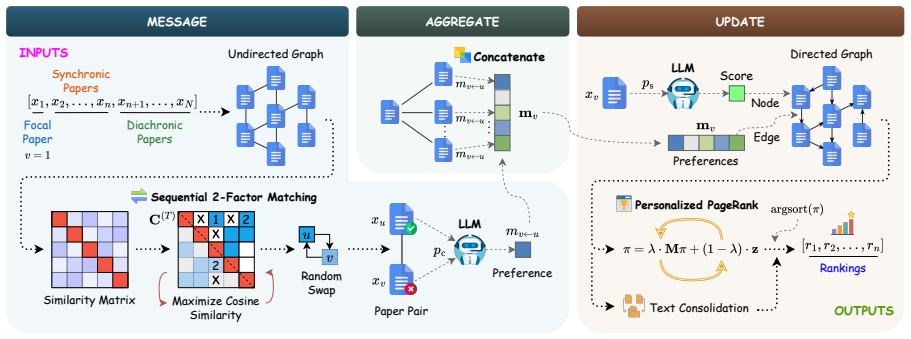
GraphReview formulates paper evaluation as review-signal message passing over a semantic paper graph that jointly captures intrinsic quality, synchronic links among contemporaneous papers, and diachronic links to prior work. LLMs estimate node-level quality priors and generate edge-level comparative evidence through pairwise comparisons. Personalized PageRank then integrates these signals for quality ranking, decision prediction, and review generation. Reward-induced maximum likelihood objectives are used to train the LLM backbones for higher-quality graph evidence.
What carries the argument
The semantic paper graph where LLMs supply node quality priors and edge comparative evidence, propagated by Personalized PageRank.
If this is right
- Outperforms the strongest baseline with average improvements of 29.7% on decision and ranking metrics.
- Achieves specific gains of 23.7% in Accuracy and 57.6% in Spearman's ρ.
- Generates higher-quality review texts.
- Generalizes effectively across time periods and conference venues.
Where Pith is reading between the lines
- Automating relational evaluation this way might help scale peer review processes without losing context.
- Connecting papers in graphs could reveal patterns in how quality signals spread in research fields.
- Testing on papers from emerging fields might show if the method adapts when literature connections are sparse.
Load-bearing premise
LLM-generated node priors and pairwise comparative evidence on the edges accurately reflect true paper quality and relationships.
What would settle it
Human expert evaluations on a held-out set of papers that show no correlation or even negative correlation with the GraphReview rankings and decisions.
Figures



read the original abstract
Scientific paper evaluation often involves not only assessing a manuscript itself, but also relating it to contemporaneous research and prior literature. However, existing LLM-based methods typically model these signals separately and lack a unified mechanism for propagating review evidence across papers. We propose $\textbf{GraphReview}$, a graph-based LLM framework that formulates paper evaluation as review-signal message passing over a semantic paper graph. The graph jointly captures intrinsic quality, synchronic links among contemporaneous papers, and diachronic links to prior work. LLMs are used to estimate node-level quality priors and generate edge-level comparative evidence through pairwise paper comparisons, while Personalized PageRank integrates review signals for quality ranking, decision prediction, and review generation. To produce higher-quality graph evidence, we propose reward-induced maximum likelihood objectives for training the LLM backbones. Experiments show that GraphReview consistently outperforms the strongest baseline, achieving average improvements of 29.7% on decision and ranking metrics, including gains of 23.7% in Accuracy and 57.6% in Spearman's $\rho$. It also produces higher-quality review texts and generalizes effectively across time periods and conference venues. The code is available at https://github.com/ECNU-Text-Computing/GraphReview.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes GraphReview, a graph-based LLM framework that formulates scientific paper evaluation as review-signal message passing over a semantic paper graph capturing intrinsic quality (node priors), synchronic links among contemporaneous papers, and diachronic links to prior work (edge comparisons). LLMs generate node-level quality priors and pairwise comparative evidence; Personalized PageRank integrates these signals for quality ranking, decision prediction, and review generation. Reward-induced maximum likelihood objectives are introduced to train the LLM backbones. Experiments report consistent outperformance over baselines with average improvements of 29.7% on decision and ranking metrics (including 23.7% Accuracy and 57.6% Spearman's ρ), higher-quality review texts, and effective generalization across time periods and venues. Code is released at the provided GitHub link.
Significance. If the results hold after addressing verification gaps, the work provides a unified mechanism for propagating relational review evidence in LLM-based evaluation, potentially improving consistency over isolated per-paper assessments. The explicit code release is a clear strength supporting reproducibility.
major comments (3)
- [§4 Experiments] §4 Experiments: The headline gains (29.7% average improvement, 23.7% Accuracy, 57.6% Spearman's ρ) are reported without details on dataset construction, baseline implementations, statistical significance tests, or controls for LLM variability; these omissions are load-bearing because the central claim attributes gains to the graph message-passing mechanism rather than prompting artifacts.
- [§3 Method] §3 Method (LLM node priors and edge generation): No human agreement rates, ablation removing the graph propagation step, or independent validation of the LLM-generated priors/edges is provided; without this, the weakest assumption—that LLM outputs accurately reflect true quality and relationships—cannot be falsified, leaving open the possibility that PageRank merely propagates noisy or biased signals.
- [Abstract and §3.2] Abstract and §3.2 (reward-induced MLE objectives): The training of LLM backbones via reward-induced maximum likelihood risks circularity if rewards derive from the same evaluation signals used in downstream ranking/decision tasks, which could inflate the reported improvements without an explicit control experiment.
minor comments (2)
- [§3.1] Notation for synchronic vs. diachronic edges could be clarified with explicit definitions in the graph construction subsection to aid reproducibility.
- [§4.2] Table reporting per-metric results should include standard deviations or confidence intervals given the stochastic nature of LLM calls.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below with clarifications and planned revisions to improve the manuscript.
read point-by-point responses
-
Referee: [§4 Experiments] The headline gains (29.7% average improvement, 23.7% Accuracy, 57.6% Spearman's ρ) are reported without details on dataset construction, baseline implementations, statistical significance tests, or controls for LLM variability; these omissions are load-bearing because the central claim attributes gains to the graph message-passing mechanism rather than prompting artifacts.
Authors: We agree the manuscript omits key experimental details. The released code contains the implementations, but to make the paper self-contained we will expand §4 with: (i) full dataset construction protocol including time/venue splits and filtering criteria, (ii) precise baseline re-implementation steps and hyper-parameters, (iii) statistical significance results (paired t-tests and Wilcoxon tests across 5 random seeds), and (iv) explicit controls for LLM variability (temperature sweeps, prompt paraphrases, and seed-averaged runs). These additions will better isolate the contribution of the graph propagation step. revision: yes
-
Referee: [§3 Method] No human agreement rates, ablation removing the graph propagation step, or independent validation of the LLM-generated priors/edges is provided; without this, the weakest assumption—that LLM outputs accurately reflect true quality and relationships—cannot be falsified, leaving open the possibility that PageRank merely propagates noisy or biased signals.
Authors: This point is well-taken. We will add: (i) an ablation that disables message passing and ranks solely by node priors, (ii) human agreement rates (Cohen’s κ) on a 200-instance sample of LLM-generated priors and pairwise edges annotated by two domain experts, and (iii) correlation of LLM edge labels with citation-based proxies. These results will appear in a new subsection of §3 and an expanded §4. revision: yes
-
Referee: [Abstract and §3.2] The training of LLM backbones via reward-induced maximum likelihood risks circularity if rewards derive from the same evaluation signals used in downstream ranking/decision tasks, which could inflate the reported improvements without an explicit control experiment.
Authors: The rewards are computed from ground-truth labels (accept/reject decisions and citation counts) that are disjoint from the test-set evaluation metrics. Nevertheless, to eliminate any perception of circularity we will add a control experiment that trains the LLM backbones with standard MLE and compares downstream ranking/decision performance against the reward-induced variant; results will be reported in the revised §3.2 and §4. revision: yes
Circularity Check
No significant circularity; derivation uses external LLM signals and standard graph propagation
full rationale
The paper formulates evaluation as message passing over a graph whose nodes receive LLM-generated quality priors and whose edges receive LLM-generated pairwise comparisons, after which Personalized PageRank produces the final rankings and decisions. No equation or training objective is shown to define the output ranking in terms of itself or to rename a fitted parameter as a prediction. The reward-induced MLE training is described only as a means to improve the quality of the LLM-generated evidence; the abstract supplies no indication that the reward signal is constructed from the downstream ranking metrics in a closed loop. Experiments report gains against external baselines and across time/venue splits, indicating evaluation on independent ground truth rather than self-referential fitting. No self-citation, uniqueness theorem, or ansatz-smuggling steps appear in the provided text.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Personalized PageRank integrates review signals for quality ranking, decision prediction, and review generation
invented entities (1)
-
semantic paper graph with synchronic and diachronic links
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Reviewing peer review. Yuan Chang, Ziyue Li, Hengyuan Zhang, Yuanbo Kong, Yanru Wu, Hayden Kwok-Hay So, Zhijiang Guo, Liya Zhu, and Ngai Wong. 2025. Treereview: A dynamic tree of questions framework for deep and efficient llm-based scientific peer review. InProceed- ings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 156...
-
[2]
Justin Gilmer, Samuel S Schoenholz, Patrick F Riley, Oriol Vinyals, and George E Dahl
Revieweval: An evaluation framework for ai- generated reviews.arXiv preprint arXiv:2502.11736. Justin Gilmer, Samuel S Schoenholz, Patrick F Riley, Oriol Vinyals, and George E Dahl. 2017. Neural mes- sage passing for quantum chemistry. InInternational conference on machine learning, pages 1263–1272. Pmlr. Zirui Guo, Lianghao Xia, Yanhua Yu, Tian Ao, and C...
-
[3]
arXiv preprint arXiv:2405.02150
The ai review lottery: Widespread ai-assisted peer reviews boost paper scores and acceptance rates. arXiv preprint arXiv:2405.02150. Chuanlei Li, Xu Hu, Minghui Xu, Kun Li, Yue Zhang, and Xiuzhen Cheng. 2025. Can large language mod- els be trusted paper reviewers? a feasibility study. arXiv preprint arXiv:2506.17311. Chris Lu, Cong Lu, Robert Tjarko Lange...
-
[4]
G-reasoner: Foundation Models for Unified Reasoning over Graph-structured Knowledge
G-reasoner: Foundation models for unified reasoning over graph-structured knowledge.arXiv preprint arXiv:2509.24276. Junbo Niu, Zheng Liu, Zhuangcheng Gu, Bin Wang, Linke Ouyang, Zhiyuan Zhao, Tao Chu, Tianyao He, Fan Wu, Qintong Zhang, and 1 others. 2025. Mineru2. 5: A decoupled vision-language model for efficient high-resolution document parsing.arXiv p...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Jiabin Tang, Yuhao Yang, Wei Wei, Lei Shi, Lixin Su, Suqi Cheng, Dawei Yin, and Chao Huang
Peer review as a multi-turn and long-context dialogue with role-based interactions.arXiv preprint arXiv:2406.05688. Jiabin Tang, Yuhao Yang, Wei Wei, Lei Shi, Lixin Su, Suqi Cheng, Dawei Yin, and Chao Huang. 2024. Graphgpt: Graph instruction tuning for large lan- guage models. InProceedings of the 47th Interna- tional ACM SIGIR Conference on Research and ...
-
[6]
Ai can learn scientific taste.arXiv preprint arXiv:2603.14473. Keith Tyser, Ben Segev, Gaston Longhitano, Xin-Yu Zhang, Zachary Meeks, Jason Lee, Uday Garg, Nicholas Belsten, Avi Shporer, Madeleine Udell, and 1 others. 2024. Ai-driven review systems: evaluating llms in scalable and bias-aware academic reviews. arXiv preprint arXiv:2408.10365. Petar Veliˇc...
-
[7]
Graph attention networks.arXiv preprint arXiv:1710.10903. Duo Wang, Yuan Zuo, Guangyue Lu, and Junjie Wu
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
arXiv preprint arXiv:2510.16885
Unigte: Unified graph-text encoding for zero- shot generalization across graph tasks and domains. arXiv preprint arXiv:2510.16885. Heng Wang, Shangbin Feng, Tianxing He, Zhaoxuan Tan, Xiaochuang Han, and Yulia Tsvetkov. 2023. Can language models solve graph problems in natural language?Advances in Neural Information Process- ing Systems, 36:30840–30861. Y...
-
[9]
InThe Thirteenth Inter- national Conference on Learning Representations
Cycleresearcher: Improving automated re- search via automated review. InThe Thirteenth Inter- national Conference on Learning Representations. Lingfei Wu, Dashun Wang, and James A Evans. 2019. Large teams develop and small teams disrupt science and technology.Nature, 566(7744):378–382. Zhikai Xue, Guoxiu He, Zhuoren Jiang, Sichen Gu, Yangyang Kang, Star Z...
-
[10]
Is Chain-of-Thought Reasoning of LLMs a Mirage? A Data Distribution Lens
From replication to redesign: Exploring pair- wise comparisons for LLM-based peer review. In The Thirty-ninth Annual Conference on Neural Infor- mation Processing Systems. Chengshuai Zhao, Zhen Tan, Pingchuan Ma, Dawei Li, Bohan Jiang, Yancheng Wang, Yingzhen Yang, and Huan Liu. 2025a. Is chain-of-thought reasoning of llms a mirage? a data distribution le...
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
arXiv preprint arXiv:2310.01089
Graphtext: Graph reasoning in text space. arXiv preprint arXiv:2310.01089. Penghai Zhao, Jinyu Tian, Qinghua Xing, Xin Zhang, Zheng Li, Jianjun Qian, Ming-Ming Cheng, and Xi- ang Li. 2025b. Naipv2: Debiased pairwise learning for efficient paper quality estimation.arXiv preprint arXiv:2509.25179. Penghai Zhao, Qinghua Xing, Kairan Dou, Jinyu Tian, Ying Tai...
-
[12]
InPro- ceedings of the 63rd Annual Meeting of the Associa- tion for Computational Linguistics (Volume 1: Long Papers), pages 29330–29355
Deepreview: Improving llm-based paper re- view with human-like deep thinking process. InPro- ceedings of the 63rd Annual Meeting of the Associa- tion for Computational Linguistics (Volume 1: Long Papers), pages 29330–29355. Zhenzhen Zhuang, Jiandong Chen, Hongfeng Xu, Yuwen Jiang, and Jialiang Lin. 2025. Large lan- guage models for automated scholarly pap...
2025
-
[13]
Assuming a unique optimal 2-factor exists, the algorithm is permutation equivariant, meaning the optimal result is invariant to node relabel- ing
-
[14]
This follows from the fact that any complete graph KN with N≥3 admits a 2-factor; see Appendix G for a proof
For T≥1 and N≥3 , the loop executes at least once, so the graph always contains edges. This follows from the fact that any complete graph KN with N≥3 admits a 2-factor; see Appendix G for a proof. D.2 Text Consolidation In practice, for node-level inference, an LLM’s output can be decomposed into two types of infor- mation, denoted as fLLM(xv, ps) = (ˆys,...
-
[15]
Metadata Acquisition Top-tier Conference Metadata
-
[16]
PDF Downloading PDF Cache Semantic Attention Local Vector Database (Training Set) Cosine Similarity Greedy, One-time use Score Gap Random Swap (Metigating Positional Bias) Initial Prompt
-
[17]
Cold-start SFT Metadata API Download API Top-tier Conference Metadata
-
[18]
Content Parsing Markdown Cache MinerU PDF Cache
-
[19]
Build Database Local Vector Database Embedding Model Markdown Cache
-
[20]
Prompt Optimization LLM as a Judge Generate Answers Prompt Self-evolving Best Prompt EdgeNode Node Edge Instruct LLM
-
[21]
RWML Training Open-source LLM Cold-started LLM Cold-started LLM GraphReview LLM LLM Judger LLM Evolver Figure 5: Pipeline of dataset construction (left) and training process (right). E Experiment Details E.1 Dataset Construction As shown in Figure 5 (left), we first collect the full text of all papers through the OpenReview API, parse the PDFs with MinerU...
2025
-
[22]
combined with DeepReview-14B (Zhu et al., 2025), and (2) PairReview (Zhang et al., 2025) combined with CycleReviewer-7B (Weng et al., 2025). The results reported in Table 9 and 10 show that graph-based fusion consistently integrates hetero- geneous review signals and outperforms each indi- vidual method on most metrics. For the combina- tion of CNPE-7B an...
-
[23]
However, our experiments show that such models perform poorly on paper reviewing and fall substantially behind the pro- posed GraphReview framework
treat text embeddings as node features and then learn node representations through neigh- borhood aggregation. However, our experiments show that such models perform poorly on paper reviewing and fall substantially behind the pro- posed GraphReview framework. Although both paradigms leverage graph structure and involve message passing, a fundamental quest...
2024
-
[24]
On Representing Convex Quadratically Constrained Quadratic Programs via Graph Neural Networks,\
typically treat paper review as a task to be solved through decomposition, iterative reflec- tion, or retrieval-augmented analysis. Although retrieved evidence may provide useful background knowledge, it is usually incorporated only as aux- iliary context (Zhu et al., 2025) rather than as a structured signal that directly shapes evaluation. As a result, t...
2025
-
[25]
**Disadvantages**:
**Relevant Problem Selection:** The task of representing and solving convex QCQPs ... **Disadvantages**:
-
[26]
**Questions**:
**Incremental and Poorly Justified Technical Contribution:** The proposed ... **Questions**:
-
[27]
**Suggestions**:
The theorem states that a GNN can universally approximate the ... **Suggestions**:
-
[28]
Finally, we produce a complete evaluation report with an associated score for paper 68J0pJFCi3
**Complete and Justify the Theoretical Claims:** The authors ... Finally, we produce a complete evaluation report with an associated score for paper 68J0pJFCi3. Table 11: Case study. An example illustrating the complete workflow for evaluating a paper. Criteria Optimization Prompt You are an expert prompt optimizer. Your task is to optimize the {criteria}...
2000
-
[29]
Use the provided`single_paper_review`as the primary foundation and preserve its core judgment unless the comparative evidence clearly justifies adjustment.,→
-
[30]
For each entry in`related_pairs`, briefly extract only the most relevant information from `pair_comparison`, especially comparative strengths, weaknesses, missing validations, or clearer methodological standards that are directly useful for evaluating this paper. ,→ ,→
-
[31]
Citation format: e.g.`(#0, 2025)`
Integrate these insights naturally into the`single_paper_review`, citing the relevant literature in the merged text. Citation format: e.g.`(#0, 2025)`. Use comparisons selectively and only when they strengthen or clarify the review. ,→ ,→
2025
-
[32]
Make sure the ranking, decision, and all arguments are fully consistent with each other after revision
You must output content related to`ranking`and`decision`at first, e.g.`**Ranking:** (0/500)`and`**Decision:** Accept`. Make sure the ranking, decision, and all arguments are fully consistent with each other after revision. ,→ ,→
-
[33]
Avoid repetition across sections
Structure the review clearly into layered sections: first give an overall assessment, then list the most important strengths, then the most important weaknesses, and finally concrete questions/suggestions. Avoid repetition across sections. ,→ ,→
-
[34]
The questions and suggestions proposed must all be highly practical, specific, feasible, and directly actionable for the authors to address.,→
-
[35]
Avoid exaggerated claims or unsupported criticism.,→
Keep the tone professional, evidence-based, and concise. Avoid exaggerated claims or unsupported criticism.,→
-
[36]
Do not include any other content
Only output the merged text. Do not include any other content. Here is all the content related to the paper: ``` {json_str} ``` The output format you need to follow: ``` **Ranking:** **Decision:** **Summary**: **Advantages**: **Disadvantages**: **Questions**: **Suggestions**: ``` Table 16: Text consolidation prompt. Merge the texts to generate complete re...
-
[37]
Return a valid JSON object only, with no extra text
-
[38]
technical_depth
The JSON must contain exactly these ten keys: - "technical_depth" - "technical_depth_reason" - "evidence_grounding" - "evidence_grounding_reason" - "scientific_rigor" - "scientific_rigor_reason" - "revision_utility" - "revision_utility_reason" - "overall_preference" - "overall_preference_reason"
-
[39]
A", "B", or
For each label key, the value must be exactly one of: "A", "B", or "Tie"
-
[40]
For each reason key, the value must be one brief sentence of at most 22 words
-
[41]
EVALUATION DIMENSIONS:
Do not output anything except the JSON object. EVALUATION DIMENSIONS:
-
[42]
technical_depth: Which review engages more deeply with the paper's technical substance, such as method details, assumptions, derivations, proofs, experiments, evaluation design, complexity, or implementation? ,→ ,→
-
[43]
evidence_grounding: Which review ties its judgments more directly to paper-specific evidence, claims, equations, tables, figures, baselines, metrics, or clearly missing analyses?,→
-
[44]
scientific_rigor: Which review more rigorously evaluates validity, claim-evidence alignment, fairness of comparisons, reproducibility, completeness of argumentation, and whether the paper's conclusions are actually supported? ,→ ,→
-
[45]
revision_utility: Which review gives more useful and actionable guidance for improving the paper, especially through concrete, acceptance-relevant revisions?,→
-
[46]
overall_preference: Overall, which review is more valuable for editorial decision-making and author revision, considering technical insight, evidence-based criticism, exposure of substantive weaknesses, and usefulness for improving the paper? ,→ ,→ CORE JUDGING PRINCIPLES:
-
[47]
Judge only the quality of the reviews, not the quality of the paper
-
[48]
Prefer reviews that identify central technical weaknesses, unsupported claims, weak evidence, missing controls, incomplete proofs, confounds, unfair baselines, or reproducibility gaps.,→
-
[49]
Prefer paper-specific critique over generic balance, polished wording, soft tone, or formulaic reviewing language.,→
-
[50]
Do not reward a review merely for sounding more diplomatic, more moderate, more balanced, or more polished.,→
-
[51]
Do not penalize a review merely for being critical, forceful, technically dense, or highly detailed, if its concerns are concrete and grounded in the paper.,→
-
[52]
Strong reviews often directly explain why the current evidence is insufficient for the paper's claims.,→
-
[53]
Comparative references to related work may be useful when they concretely support criticism about novelty, baselines, theory, or evaluation standards; do not dismiss them automatically unless they substantially replace paper-specific analysis. ,→ ,→
-
[54]
Ignore superficial differences in politeness or rhetorical style unless they materially affect scientific clarity or introduce unsupported claims.,→
-
[55]
If one review is sharper but better exposes acceptance-relevant weaknesses, it can be better overall even if it is less smooth stylistically.,→
-
[56]
In close cases, prefer the review that better identifies substantive risks to validity or acceptance.,→
-
[57]
Tie" rather than defaulting to
If the two reviews are difficult to distinguish in quality, choose "Tie" rather than defaulting to "A" due to positional bias.,→
-
[58]
technical_depth
If one review is empty, select the other review accordingly. Continued on next page. Table 17: Text evaluation prompt. Comparing the text quality with other approaches. Text Evaluation Prompt(Continued) Compare Review A and Review B as peer-review reports for the same paper. Return only a valid JSON object with exactly these keys: "technical_depth" "techn...
-
[59]
Judge only the quality of the reviews, not the paper itself
-
[60]
Prefer reviews that identify important technical flaws, unsupported claims, weak evidence, missing experiments, incomplete proofs, unfair comparisons, or reproducibility issues.,→
-
[61]
Prefer paper-specific, evidence-linked criticism over smoother wording or more diplomatically balanced tone.,→
-
[62]
Do not reward a review merely for sounding more polished, more measured, or more conventionally editorial.,→
-
[63]
A sharper or more critical review can be better if its concerns are concrete, technically meaningful, and grounded in the paper.,→
-
[64]
Related-work comparisons may be useful when they concretely support criticism about novelty, baselines, theory, or evaluation standards.,→
-
[65]
In close cases, overall_preference should favor the review that better exposes acceptance-relevant weaknesses and better helps an editor decide.,→
-
[66]
Tie" rather than defaulting to
If the two reviews are difficult to distinguish in quality, output "Tie" rather than defaulting to "A" because of positional bias.,→ Review A: {review_a} Review B: {review_b} Table 17: Text evaluation prompt (Continued). Comparing the text quality with other approaches
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.