Learning to Act under Noise: Enhancing Agent Robustness via Noisy Environments
Pith reviewed 2026-06-29 16:48 UTC · model grok-4.3
The pith
Training LLM agents with controlled user and tool noise improves robustness in imperfect environments and boosts performance on clean benchmarks too.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
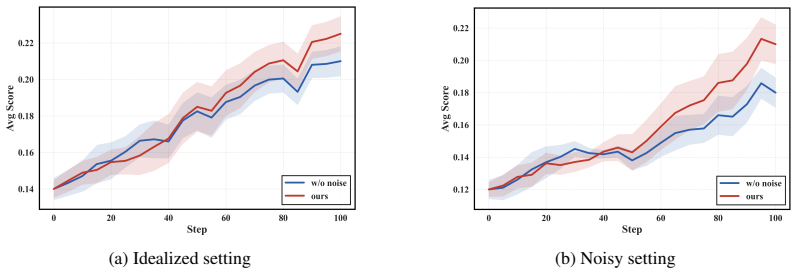
NoisyAgent adds user noise by altering interaction patterns and tool noise by simulating execution anomalies, applying these perturbations progressively to only part of the rollouts so the agent learns to handle increasing levels of imperfection; this produces agents that maintain higher performance under stochastic conditions and also improve on standard idealized benchmarks.
What carries the argument
NoisyAgent, the training framework that selectively perturbs user interactions and tool results during rollouts while scaling noise difficulty as the model adapts.
If this is right
- Agents exhibit greater stability when user requests contain ambiguity or when tools return unexpected results.
- The same training procedure produces measurable gains even on benchmarks that contain no added noise.
- Progressive noise scheduling prevents training instability while still building tolerance to harder imperfections.
- Generalization improves because the agent must develop reasoning that does not assume perfect inputs or outputs.
Where Pith is reading between the lines
- The approach could be tested by measuring whether the same noise-injection schedule transfers to agents using different base models or different tool sets.
- If the method works, it suggests that other forms of environmental stochasticity, such as delayed tool responses or partial observations, might be added in similar controlled ways.
- A practical next step would be to replace the simulated noise with logged traces from actual user sessions and tool logs to check whether the gains hold.
Load-bearing premise
The specific changes made to user patterns and tool outcomes during training match the kinds of noise that actually appear in real deployments.
What would settle it
Deploy the trained agents in a live setting with genuine user ambiguity and tool failures; if they show no robustness gain over agents trained without noise, the central claim is false.
Figures


read the original abstract
Recent advances in large language models (LLMs) have facilitated the widespread deployment of LLMs as interactive agents capable of reasoning, planning, and tool use. Despite strong performance on existing benchmarks, such agents often exhibit notable degradation when deployed in real-world settings, where environments are inherently stochastic and imperfect. We argue that this discrepancy arises from a fundamental mismatch between idealized training settings and real-world interaction dynamics, where current paradigms rely on carefully curated task instructions and stable, well-controlled environments. To address this gap, we propose NoisyAgent, an agentic training framework that explicitly incorporates environmental imperfections into the agent learning process. We identify two major sources of interaction noise in real-world scenarios: user noise, which captures ambiguity and variability in user interaction, and tool noise, which reflects failures and anomalies in tool execution. We introduce such perturbations into the training pipeline by modifying user interaction patterns and simulating tool execution results within the training environment. To stabilize training while encouraging agents to handle increasingly challenging imperfections, noise is applied to only a subset of rollouts and progressively increased in difficulty as the model adapts to the current noise level. Extensive experiments demonstrate that our approach consistently improves agent robustness under noisy and dynamic environments. Our analysis reveals that training under noise conditions also yields performance gains on idealized benchmarks, suggesting that controlled exposure to environmental noise promotes more generalizable reasoning and decision-making behaviors. Our findings highlight the importance of modeling interaction imperfections for bridging the gap between agent training and real-world deployment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes NoisyAgent, a framework for training LLM-based interactive agents that explicitly incorporates two sources of environmental noise—user noise (ambiguity in interactions) and tool noise (execution anomalies)—by perturbing user patterns and simulating tool results during rollouts. Noise is applied to only a subset of trajectories and increased progressively in difficulty to stabilize learning. The central claim is that this yields consistent robustness gains in noisy/dynamic settings and, surprisingly, also improves performance on clean idealized benchmarks, thereby narrowing the gap between training and real-world deployment.
Significance. If substantiated, the result would provide a concrete, scalable recipe for making agentic systems more reliable under stochastic conditions that are unavoidable in deployment. The progressive noise schedule is a methodological strength that could generalize beyond the specific perturbations studied.
major comments (2)
- [Abstract] Abstract: the headline claim that the method 'consistently improves agent robustness under noisy and dynamic environments' and produces gains on idealized benchmarks is asserted without any metrics, baselines, dataset sizes, number of runs, or statistical tests; this absence prevents evaluation of effect size or reliability and is load-bearing for the empirical contribution.
- [Abstract] Abstract / method description: the perturbations (modified user interaction patterns and simulated tool execution anomalies) are presented as capturing 'the two major sources of interaction noise in real-world scenarios,' yet no quantitative comparison to production logs, user studies, or observed error distributions is supplied to establish that the synthetic noise matches real deployments in frequency, type, or severity; without this, observed gains may be artifacts of the chosen schedule rather than evidence of improved real-world robustness.
minor comments (1)
- [Abstract] Abstract: the phrase 'extensive experiments' should be accompanied by at least a high-level summary of the benchmarks, agent backbones, and noise schedules used.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments correctly identify areas where the abstract and motivation require greater specificity and substantiation. We address each point below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline claim that the method 'consistently improves agent robustness under noisy and dynamic environments' and produces gains on idealized benchmarks is asserted without any metrics, baselines, dataset sizes, number of runs, or statistical tests; this absence prevents evaluation of effect size or reliability and is load-bearing for the empirical contribution.
Authors: We agree that the abstract should be revised to include quantitative details supporting the claims. In the updated version, we will report specific metrics such as average performance gains (e.g., X% on noisy environments and Y% on clean benchmarks), the number of evaluation runs (5 random seeds), dataset sizes, baselines used, and references to statistical significance testing. This will enable readers to assess effect sizes and reliability directly from the abstract. revision: yes
-
Referee: [Abstract] Abstract / method description: the perturbations (modified user interaction patterns and simulated tool execution anomalies) are presented as capturing 'the two major sources of interaction noise in real-world scenarios,' yet no quantitative comparison to production logs, user studies, or observed error distributions is supplied to establish that the synthetic noise matches real deployments in frequency, type, or severity; without this, observed gains may be artifacts of the chosen schedule rather than evidence of improved real-world robustness.
Authors: We acknowledge the absence of direct quantitative validation against production data or user studies. Such proprietary logs are not available to us. In revision, we will (1) cite prior literature on observed agent failure modes that qualitatively motivate these noise types, (2) revise the wording from 'the two major sources' to 'two primary sources of noise commonly encountered in deployments,' and (3) add an explicit limitations paragraph discussing that the perturbations are synthetic and may not perfectly match any specific real-world distribution. We will also include sensitivity analysis on the noise schedule to address concerns about arbitrariness. revision: partial
Circularity Check
No circularity: empirical training method with external benchmark validation
full rationale
The paper introduces NoisyAgent by explicitly defining two noise sources (user interaction variability and tool execution anomalies) and applying them to a subset of rollouts with progressive difficulty. Performance gains are measured on separate idealized and noisy benchmarks rather than being derived from the noise schedule itself. No equations, fitted parameters, or self-citations are shown that would make the reported robustness improvements equivalent to the input perturbations by construction. The central claims rest on experimental outcomes, not on renaming or self-referential definitions.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Introducing gpt-5.2
OpenAI. Introducing gpt-5.2. 2025. URL https://openai.com/index/ introducing-gpt-5-2/
2025
-
[2]
Gemini 3 pro model card.https://storage.googleapis.com/deepmind-media/Model- Cards/Gemini-3-Pro-Model-Card.pdf, 2025
Google. Gemini 3 pro model card.https://storage.googleapis.com/deepmind-media/Model- Cards/Gemini-3-Pro-Model-Card.pdf, 2025
2025
-
[3]
Introducing longcat-flash-thinking: A technical report.arXiv preprint arXiv:2509.18883, 2025
Meituan LongCat Team, Anchun Gui, Bei Li, Bingyang Tao, Bole Zhou, Borun Chen, Chao Zhang, Chengcheng Han, Chenhui Yang, Chi Zhang, et al. Introducing longcat-flash-thinking: A technical report.arXiv preprint arXiv:2509.18883, 2025
-
[4]
Kimi K2: Open Agentic Intelligence
Kimi Team, Yifan Bai, Yiping Bao, Guanduo Chen, Jiahao Chen, Ningxin Chen, Ruijue Chen, Yanru Chen, Yuankun Chen, Yutian Chen, et al. Kimi k2: Open agentic intelligence.arXiv preprint arXiv:2507.20534, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models
Aohan Zeng, Xin Lv, Qinkai Zheng, Zhenyu Hou, Bin Chen, Chengxing Xie, Cunxiang Wang, Da Yin, Hao Zeng, Jiajie Zhang, et al. Glm-4.5: Agentic, reasoning, and coding (arc) foundation models.arXiv preprint arXiv:2508.06471, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Longcat-flash technical report.arXiv preprint arXiv:2509.01322, 2025
Meituan LongCat Team, Bei Li, Bingye Lei, Bo Wang, Bolin Rong, Chao Wang, Chao Zhang, Chen Gao, Chen Zhang, Cheng Sun, et al. Longcat-flash technical report.arXiv preprint arXiv:2509.01322, 2025
-
[7]
$\tau$-bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains
Shunyu Yao, Noah Shinn, Pedram Razavi, and Karthik Narasimhan. τ-bench: A benchmark for tool-agent-user interaction in real-world domains.CoRR, abs/2406.12045, 2024. doi: 10.48550/ARXIV .2406.12045. URLhttps://doi.org/10.48550/arXiv.2406.12045
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv 2024
-
[8]
$\tau^2$-Bench: Evaluating Conversational Agents in a Dual-Control Environment
Victor Barres, Honghua Dong, Soham Ray, Xujie Si, and Karthik Narasimhan. τ 2-bench: Eval- uating conversational agents in a dual-control environment.arXiv preprint arXiv:2506.07982, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Wei He, Yueqing Sun, Hongyan Hao, Xueyuan Hao, Zhikang Xia, Qi Gu, Chengcheng Han, Dengchang Zhao, Hui Su, Kefeng Zhang, et al. Vitabench: Benchmarking llm agents with versatile interactive tasks in real-world applications.arXiv preprint arXiv:2509.26490, 2025
-
[10]
Mind2web: Towards a generalist agent for the web.Advances in Neural Information Processing Systems, 36:28091–28114, 2023
Xiang Deng, Yu Gu, Boyuan Zheng, Shijie Chen, Sam Stevens, Boshi Wang, Huan Sun, and Yu Su. Mind2web: Towards a generalist agent for the web.Advances in Neural Information Processing Systems, 36:28091–28114, 2023
2023
-
[11]
WebArena: A Realistic Web Environment for Building Autonomous Agents
Shuyan Zhou, Frank F Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, et al. Webarena: A realistic web environment for building autonomous agents.arXiv preprint arXiv:2307.13854, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[12]
Tianci Xue, Weijian Qi, Tianneng Shi, Chan Hee Song, Boyu Gou, Dawn Song, Huan Sun, and Yu Su. An illusion of progress? assessing the current state of web agents.arXiv preprint arXiv:2504.01382, 2025
-
[13]
Agenttuning: Enabling generalized agent abilities for llms
Aohan Zeng, Mingdao Liu, Rui Lu, Bowen Wang, Xiao Liu, Yuxiao Dong, and Jie Tang. Agenttuning: Enabling generalized agent abilities for llms. InFindings of the Association for Computational Linguistics: ACL 2024, pages 3053–3077, 2024. 10
2024
-
[14]
Zehan Qi, Xiao Liu, Iat Long Iong, Hanyu Lai, Xueqiao Sun, Wenyi Zhao, Yu Yang, Xinyue Yang, Jiadai Sun, Shuntian Yao, et al. Webrl: Training llm web agents via self-evolving online curriculum reinforcement learning.arXiv preprint arXiv:2411.02337, 2024
-
[16]
Communication accommodation theory.Theo- rizing about intercultural communication, pages 121–148, 2005
Cindy Gallois, Tania Ogay, and Howard Giles. Communication accommodation theory.Theo- rizing about intercultural communication, pages 121–148, 2005
2005
-
[17]
What do users really ask large language models? an initial log analysis of google bard interactions in the wild
Johanne R Trippas, Sara Fahad Dawood Al Lawati, Joel Mackenzie, and Luke Gallagher. What do users really ask large language models? an initial log analysis of google bard interactions in the wild. InProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 2703–2707, 2024
2024
-
[19]
Sri Vatsa Vuddanti, Aarav Shah, Satwik Kumar Chittiprolu, Tony Song, Sunishchal Dev, Kevin Zhu, and Maheep Chaudhary. Paladin: Self-correcting language model agents to cure tool-failure cases.arXiv preprint arXiv:2509.25238, 2025
-
[20]
Qian Xiong, Yuekai Huang, Ziyou Jiang, Zhiyuan Chang, Yujia Zheng, Tianhao Li, and Mingyang Li. Butterfly effects in toolchains: A comprehensive analysis of failed parameter filling in llm tool-agent systems.arXiv preprint arXiv:2507.15296, 2025
-
[21]
AndroidWorld: A Dynamic Benchmarking Environment for Autonomous Agents
Christopher Rawles, Sarah Clinckemaillie, Yifan Chang, Jonathan Waltz, Gabrielle Lau, Mary- beth Fair, Alice Li, William Bishop, Wei Li, Folawiyo Campbell-Ajala, et al. Androidworld: A dynamic benchmarking environment for autonomous agents.arXiv preprint arXiv:2405.14573, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
Gui-xplore: Empowering generalizable gui agents with one exploration
Yuchen Sun, Shanhui Zhao, Tao Yu, Hao Wen, Samith Va, Mengwei Xu, Yuanchun Li, and Chongyang Zhang. Gui-xplore: Empowering generalizable gui agents with one exploration. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 19477–19486, 2025
2025
-
[23]
Out-of-distribution segmentation in autonomous driving: Problems and state of the art
Youssef Shoeb, Azarm Nowzad, and Hanno Gottschalk. Out-of-distribution segmentation in autonomous driving: Problems and state of the art. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 4310–4320, 2025
2025
-
[24]
Domain randomization for transferring deep neural networks from simulation to the real world
Josh Tobin, Rachel Fong, Alex Ray, Jonas Schneider, Wojciech Zaremba, and Pieter Abbeel. Domain randomization for transferring deep neural networks from simulation to the real world. InIEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2017
2017
-
[25]
Cad2rl: Real single-image flight without a single real image
Fereshteh Sadeghi and Sergey Levine. Cad2rl: Real single-image flight without a single real image. InRobotics: Science and Systems (RSS), 2017
2017
-
[26]
Robust reinforcement learning as a stackelberg game
Minghao Zhao, Wenhan Xiong, Lei Zhang, et al. Robust reinforcement learning as a stackelberg game. InInternational Conference on Machine Learning (ICML), 2021
2021
-
[27]
The Landscape of Agentic Reinforcement Learning for LLMs: A Survey
Hao Zhao et al. The landscape of agentic reinforcement learning for LLMs: A survey.arXiv preprint arXiv:2509.02547, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
Verltool: Towards holistic agentic reinforcement learning with tool use
Qiushi Jiang et al. Verltool: Towards holistic agentic reinforcement learning with tool use. arXiv preprint arXiv:2509.01055, 2025
-
[31]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[32]
Longcat-flash-thinking-2601 technical report.CoRR, abs/2601.16725, 2026
Meituan LongCat Team. Longcat-flash-thinking-2601 technical report.CoRR, abs/2601.16725, 2026
-
[33]
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
Aixin Liu, Aoxue Mei, Bangcai Lin, Bing Xue, Bingxuan Wang, Bingzheng Xu, Bochao Wu, Bowei Zhang, Chaofan Lin, Chen Dong, et al. Deepseek-v3. 2: Pushing the frontier of open large language models.arXiv preprint arXiv:2512.02556, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
Dunwei Tu, Hongyan Hao, Hansi Yang, Yihao Chen, Yi-Kai Zhang, Zhikang Xia, Yu Yang, Yueqing Sun, Xingchen Liu, Furao Shen, Qi Gu, Hui Su, and Xunliang Cai. Scaleenv: Scaling environment synthesis from scratch for generalist interactive tool-use agent training.arXiv preprint arXiv:2602.06820, 2026
-
[35]
Ruipeng Wang, Yuxin Chen, Yukai Wang, Chang Wu, Junfeng Fang, Xiaodong Cai, Qi Gu, Hui Su, An Zhang, Xiang Wang, Xunliang Cai, and Tat-Seng Chua. AgentNoiseBench: Benchmarking robustness of tool-using LLM agents under noisy condition.arXiv preprint arXiv:2602.11348, 2026
-
[36]
React: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. InInternational Conference on Learning Representations (ICLR), 2023
2023
-
[37]
Toolformer: Language models can teach themselves to use tools.Advances in Neural Information Processing Systems, 36: 68539–68551, 2023
Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools.Advances in Neural Information Processing Systems, 36: 68539–68551, 2023
2023
-
[38]
Reflexion: Language agents with verbal reinforcement learning
Noah Shinn, Federico Cassano, Edward Berman, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning. InAdvances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[39]
Voyager: An Open-Ended Embodied Agent with Large Language Models
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. V oyager: An open-ended embodied agent with large language models. arXiv preprint arXiv:2305.16291, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[40]
AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, Li Jiang, Xiaoyun Zhang, Shaokun Zhang, Jiale Liu, et al. Autogen: Enabling next-gen llm applications via multi-agent conversation.arXiv preprint arXiv:2308.08155, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[41]
Metagpt: Meta programming for a multi-agent collaborative framework
Sirui Hong, Mingchen Zhuge, Jonathan Chen, Xiawu Zheng, Yuheng Cheng, Ceyao Zhang, Jin- lin Wang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, et al. Metagpt: Meta programming for a multi-agent collaborative framework. InInternational Conference on Learning Representations (ICLR), 2024
2024
-
[42]
Generative agents: Interactive simulacra of human behavior
Joon Sung Park, Joseph C O’Brien, Carrie J Cai, Meredith Ringel Morris, Percy Liang, and Michael S Bernstein. Generative agents: Interactive simulacra of human behavior. InACM Symposium on User Interface Software and Technology (UIST), 2023
2023
-
[43]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[44]
Tulu 3: Pushing Frontiers in Open Language Model Post-Training
Nathan Lambert, Jacob Morrison, Valentina Pyatkin, Shengyi Huang, Hamish Ivison, Faeze Brahman, Lester James V . Miranda, Alisa Liu, Nouha Dziri, Shane Lyu, et al. Tülu 3: Pushing frontiers in open language model post-training.arXiv preprint arXiv:2411.15124, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[45]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y .K. Li, Y . Wu, and Daya Guo. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024. 12
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[46]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Tiantian Fan, Gaohong Liu, Lingjun Liu, Xin Liu, et al. DAPO: An open-source LLM reinforcement learning system at scale.arXiv preprint arXiv:2503.14476, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[47]
Group Sequence Policy Optimization
Chujie Zheng, Shixuan Liu, Mingze Li, Xiong-Hui Chen, Bowen Yu, Chang Gao, Kai Dang, Yuqiong Liu, Rui Men, An Yang, Jingren Zhou, and Junyang Lin. Group sequence policy optimization.arXiv preprint arXiv:2507.18071, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[48]
Understanding R1-Zero-Like Training: A Critical Perspective
Zichen Liu, Changyu Chen, Wenjun Li, Penghui Qi, Tianyu Pang, Chao Du, Wee Sun Lee, and Min Lin. Understanding R1-zero-like training: A critical perspective.arXiv preprint arXiv:2503.20783, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[49]
VAPO: Efficient and Reliable Reinforcement Learning for Advanced Reasoning Tasks
Yufeng Yuan, Qiying Yu, Xiaochen Zuo, Ruofei Zhu, Wenyuan Xu, Jiaze Chen, Chengyi Wang, Tiantian Fan, Zhengyin Du, Xiangpeng Yan, et al. V APO: Efficient and reliable reinforcement learning for advanced reasoning tasks.arXiv preprint arXiv:2504.05118, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[50]
Zhiyuan Yao, Yi-Kai Zhang, Yuxin Chen, Yueqing Sun, Zishan Xu, Yu Yang, Tianhao Hu, Qi Gu, Hui Su, and Xunliang Cai. Coba-rl: Capability-oriented budget allocation for reinforcement learning in llms.arXiv preprint arXiv:2602.03048, 2026
-
[51]
ReTool: Reinforcement Learning for Strategic Tool Use in LLMs
Jiazhan Feng, Shijue Huang, Xingwei Qu, Ge Zhang, Yujia Qin, Baoquan Zhong, Chengquan Jiang, Jinxin Chi, and Wanjun Zhong. ReTool: Reinforcement learning for strategic tool use in LLMs.arXiv preprint arXiv:2504.11536, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[52]
Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning
Bowen Jin, Hansi Zeng, Zhenrui Yue, Jinsung Yoon, Sercan Arik, Dong Wang, Hamed Zamani, and Jiawei Han. Search-R1: Training LLMs to reason and leverage search engines with reinforcement learning.arXiv preprint arXiv:2503.09516, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[53]
R1-Searcher: Incentivizing the Search Capability in LLMs via Reinforcement Learning
Huatong Song, Jinhao Jiang, Yingqian Min, Jie Chen, Zhipeng Chen, Wayne Xin Zhao, Lei Fang, and Ji-Rong Wen. R1-Searcher: Incentivizing the search capability in LLMs via reinforcement learning.arXiv preprint arXiv:2503.05592, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[54]
Look back to reason forward: Revisitable memory for long-context llm agents
Yaorui Shi, Yuxin Chen, Siyuan Wang, Sihang Li, Hengxing Cai, Qi Gu, Xiang Wang, and An Zhang. Look back to reason forward: Revisitable memory for long-context llm agents. arXiv preprint arXiv:2509.23040, 2025
-
[55]
Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. SWE-bench: Can language models resolve real-world GitHub issues? In International Conference on Learning Representations (ICLR), 2024
2024
-
[56]
Training Software Engineering Agents and Verifiers with SWE-Gym
Jiayi Pan, Xingyao Wang, Graham Neubig, Navdeep Jaitly, Heng Ji, Alane Suhr, and Yizhe Zhang. Training software engineering agents and verifiers with SWE-Gym.arXiv preprint arXiv:2412.21139, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[57]
Yuxiang Wei, Olivier Duchenne, Jade Copet, Quentin Carbonneaux, Lingming Zhang, Daniel Fried, Gabriel Synnaeve, Rishabh Singh, and Sida I. Wang. SWE-RL: Advancing LLM reason- ing via reinforcement learning on open software evolution.arXiv preprint arXiv:2502.18449, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[58]
Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, Uri Alon, and Graham Neubig
Shuyan Zhou, Frank F. Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, Uri Alon, and Graham Neubig. WebArena: A realistic web environment for building autonomous agents. InInternational Conference on Learning Representations (ICLR), 2024
2024
-
[59]
OSWorld: Benchmarking multimodal agents for open-ended tasks in real computer environments
Tianbao Xie, Danyang Zhang, Jixuan Chen, Xiaochuan Li, Siheng Zhao, Ruisheng Cao, Toh Jing Hua, Zhoujun Cheng, Dongchan Shin, Fangyu Lei, et al. OSWorld: Benchmarking multimodal agents for open-ended tasks in real computer environments. InAdvances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[60]
AppWorld: A controllable world of apps and people for benchmarking interactive coding agents
Harsh Trivedi, Tushar Khot, Mareike Hartmann, Ruskin Manku, Vinty Dong, Edward Li, Shashank Gupta, Ashish Sabharwal, and Niranjan Balasubramanian. AppWorld: A controllable world of apps and people for benchmarking interactive coding agents. InAnnual Meeting of the Association for Computational Linguistics (ACL), 2024. 13
2024
-
[61]
Zike Li, Mingwei Liu, An Li, Kaifeng He, Yanlin Wang, Xin Peng, and Zibin Zheng. Enhancing the robustness of LLM-generated code: Empirical study and framework.arXiv preprint arXiv:2503.20197, 2025
-
[62]
Natan Levy, Adiel Ashrov, and Guy Katz. Towards robust LLMs: An adversarial robustness measurement framework.arXiv preprint arXiv:2504.17723, 2025
-
[63]
Aryan Agrawal, Lisa Alazraki, Shahin Honarvar, and Marek Rei. Enhancing LLM robustness to perturbed instructions: An empirical study.arXiv preprint arXiv:2504.02733, 2025
-
[64]
Anghel, Emilia Pecheanu, Adina Cocu, Adrian Istrate, and Con- stantin A
Catalin Anghel, Andreea A. Anghel, Emilia Pecheanu, Adina Cocu, Adrian Istrate, and Con- stantin A. Andrei. Diagnosing bias and instability in LLM evaluation: A scalable pairwise meta-evaluator.Information, 16(8):652, 2025
2025
-
[65]
Robust LLM training infrastructure at ByteDance
Borui Wan, Gaohong Liu, Zhe Song, Jiarui Wang, Yukang Zhang, Guangming Sheng, Shuguang Wang, Hui Wei, Chao Wang, Wen Lou, et al. Robust LLM training infrastructure at ByteDance. pages 186–203, 2025
2025
-
[66]
David Herrera-Poyatos, Carlos Peláez-González, Cristina Zuheros, Andrés Herrera-Poyatos, Virilo Tejedor, Francisco Herrera, and Rosana Montes. An overview of model uncertainty and variability in LLM-based sentiment analysis: Challenges, mitigation strategies, and the role of explainability.Frontiers in Artificial Intelligence, 8:1609097, 2025
2025
-
[67]
Evaluating the performance and robustness of LLMs in materials science Q&A and property predictions.Digital Discovery, 2025
Hongchen Wang, Kangming Li, Scott Ramsay, Yvonne Fehlis, Edward Kim, and Jason Hattrick- Simpers. Evaluating the performance and robustness of LLMs in materials science Q&A and property predictions.Digital Discovery, 2025
2025
-
[68]
Benchmarking reasoning robustness in large language models.arXiv preprint arXiv:2503.04550, 2025
Tong Yu, Yongcheng Jing, Xikun Zhang, Wentao Jiang, Wenjie Wu, Yingjie Wang, Wenbin Hu, Bo Du, and Dacheng Tao. Benchmarking reasoning robustness in large language models.arXiv preprint arXiv:2503.04550, 2025
-
[69]
Jinnan Li, Jinzhe Li, Yue Wang, Yi Chang, and Yuan Wu. StructFlowBench: A structured flow benchmark for multi-turn instruction following.arXiv preprint arXiv:2502.14494, 2025
-
[70]
Multichallenge: A realistic multi-turn conversation evaluation benchmark challenging to frontier llms
Kaustubh Deshpande, Ved Sirdeshmukh, Johannes Baptist Mols, Lifeng Jin, Ed-Yeremai Hernandez-Cardona, Dean Lee, Jeremy Kritz, Willow E Primack, Summer Yue, and Chen Xing. Multichallenge: A realistic multi-turn conversation evaluation benchmark challenging to frontier llms. InFindings of the Association for Computational Linguistics: ACL 2025, pages 18632–...
2025
-
[71]
Agentif: Benchmarking instruction following of large language models in agentic scenarios
Yunjia Qi, Hao Peng, Xiaozhi Wang, Amy Xin, Youfeng Liu, Bin Xu, Lei Hou, and Juanzi Li. Agentif: Benchmarking instruction following of large language models in agentic scenarios. arXiv preprint arXiv:2505.16944, 2025
-
[72]
Jiayin Wang, Weizhi Ma, Peijie Sun, Min Zhang, and Jian-Yun Nie. Understanding user experience in large language model interactions.arXiv preprint arXiv:2401.08329, 2024
-
[73]
Yujian Gan, Changling Li, Jinxia Xie, Luou Wen, Matthew Purver, and Massimo Poesio. CLARQ-LLM: A benchmark for models clarifying and requesting information in task-oriented dialog.arXiv preprint arXiv:2409.06097, 2024
-
[74]
Tong Zhang, Peixin Qin, Yang Deng, Chen Huang, Wenqiang Lei, Junhong Liu, Dingnan Jin, Hongru Liang, and Tat-Seng Chua. Clamber: A benchmark of identifying and clarifying ambiguous information needs in large language models.arXiv preprint arXiv:2405.12063, 2024
-
[75]
What Prompts Don't Say: Understanding and Managing Underspecification in LLM Prompts
Chenyang Yang, Yike Shi, Qianou Ma, Michael Xieyang Liu, Christian Kästner, and Tongshuang Wu. What prompts don’t say: Understanding and managing underspecification in LLM prompts. arXiv preprint arXiv:2505.13360, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[76]
Reducing tool hallucination via reliability alignment.arXiv preprint arXiv:2412.04141, 2024
Hongshen Xu, Zichen Zhu, Lei Pan, Zihan Wang, Su Zhu, Da Ma, Ruisheng Cao, Lu Chen, and Kai Yu. Reducing tool hallucination via reliability alignment.arXiv preprint arXiv:2412.04141, 2024. 14
-
[77]
Yuxiang Zhang, Jing Chen, Junjie Wang, Yaxin Liu, Cheng Yang, Chufan Shi, Xinyu Zhu, Zihao Lin, Hanwen Wan, Yujiu Yang, et al. Toolbehonest: A multi-level hallucination diagnostic benchmark for tool-augmented large language models.arXiv preprint arXiv:2406.20015, 2024
-
[78]
Toolscan: A benchmark for characterizing errors in tool-use llms
Shirley Kokane, Ming Zhu, Tulika Manoj Awalgaonkar, Jianguo Zhang, Akshara Prabhakar, Thai Quoc Hoang, Zuxin Liu, Rithesh RN, Liangwei Yang, Weiran Yao, et al. Toolscan: A benchmark for characterizing errors in tool-use llms. InICLR 2025 Workshop on Building Trust in Language Models and Applications
2025
-
[79]
InjecAgent: Benchmarking Indirect Prompt Injections in Tool-Integrated Large Language Model Agents
Qiusi Zhan, Zhixiang Liang, Zifan Ying, and Daniel Kang. Injecagent: Benchmarking indirect prompt injections in tool-integrated large language model agents.arXiv preprint arXiv:2403.02691, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[80]
From allies to adversaries: Manipulating LLM tool-calling through adversarial injection
Ruian Zhang, Hao Wang, Jiaxin Wang, Min Li, Yu Huang, Dawei Wang, and Qi Wang. From allies to adversaries: Manipulating LLM tool-calling through adversarial injection. In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL-HLT), pages 2009– 2028, 2025
2025
-
[81]
Zhu et al
X. Zhu et al. Compounding errors in tool-augmented agents.arXiv preprint, 2025
2025
-
[82]
Yifan Song, Da Yin, Xiang Yue, Jie Huang, Sujian Li, and Bill Yuchen Lin. Trial and error: Exploration-based trajectory optimization for LLM agents.arXiv preprint arXiv:2403.02502, 2024
-
[83]
Grigor Nalbandyan, Rima Shahbazyan, and Evelina Bakhturina. Score: Systematic consistency and robustness evaluation for large language models.arXiv preprint arXiv:2503.00137, 2025
-
[84]
Z. Wen, Z. Liu, Z. Tian, S. Pan, Z. Huang, D. Li, and M. Huang. Scenario-independent uncertainty estimation for LLM-based question answering via factor analysis. InProceedings of the ACM on Web Conference, pages 2378–2390, 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.