Can Retrieval Heads See Images? Multimodal Retrieval Heads in Long-Context Vision-Language Models
Pith reviewed 2026-06-29 18:27 UTC · model grok-4.3
The pith
Sparse attention heads handle most retrieval of both text and images in long-context vision-language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
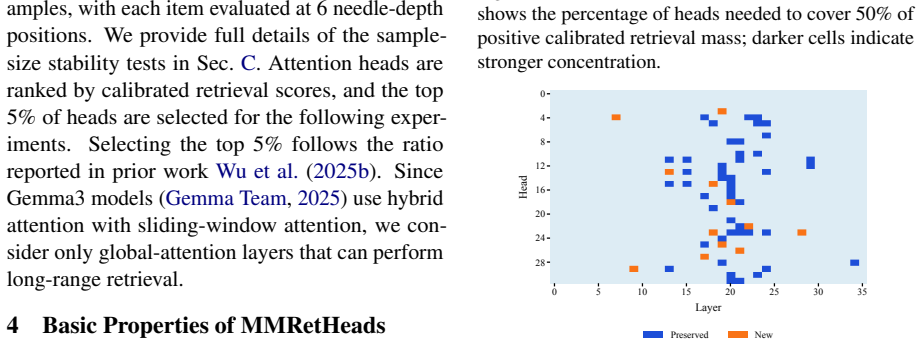
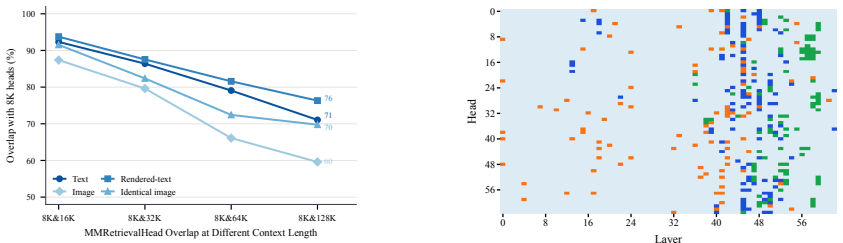
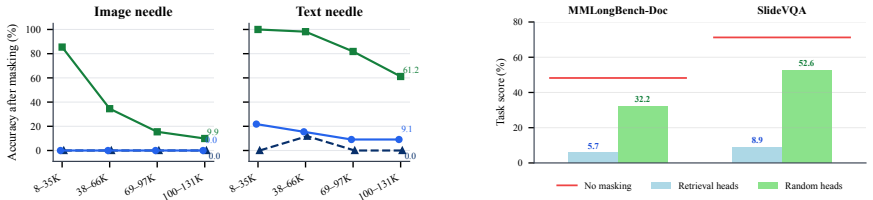
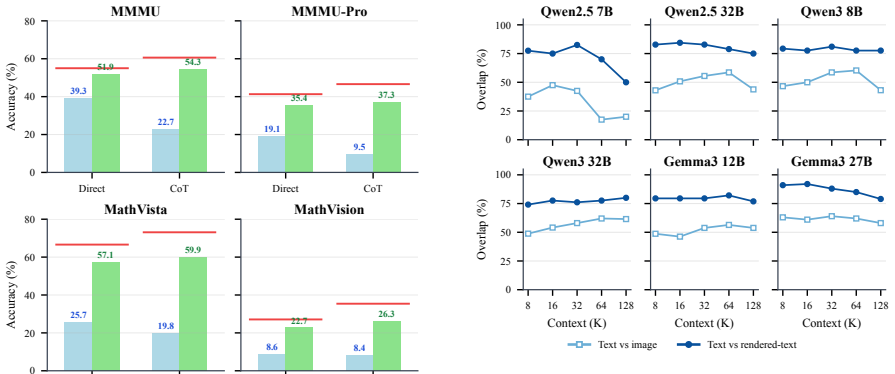
Vision-language models contain sparse multimodal retrieval heads that locate relevant evidence across interleaved text and images. These heads are identified by an attention-scoring method from question tokens to textual or visual evidence tokens. They concentrate 50 percent of the positive retrieval-score mass in only 4.4-10.2 percent of heads and prove causally important because masking the top 5 percent collapses performance on long-context benchmarks while random masking does not. The heads are partly shared across modalities but more dynamic for images as context varies, and they support direct document ranking on MMDocIR without further training.
What carries the argument
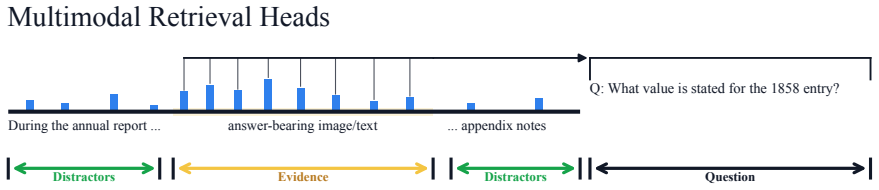
multimodal retrieval head detection method that scores attention from question tokens to textual or visual evidence tokens
If this is right
- Only 4.4-10.2% of heads account for 50% of positive retrieval-score mass.
- Masking the top 5% selected heads drops MMLongBench-Doc from 48.2% to 5.7%.
- The same masking drops SlideVQA from 71.2% to 8.9%.
- The heads are partly shared across text and image modalities but more dynamic for images.
- Without training, the heads improve Recall@1 on MMDocIR page and layout retrieval over baselines.
Where Pith is reading between the lines
- Models could be pruned or specialized around these heads to reduce compute in long-context settings.
- The detection approach may apply to other multimodal inputs such as video or audio sequences.
- Targeted interventions on these heads could debug or enhance retrieval behavior in deployed VLMs.
Load-bearing premise
The attention-scoring method from question tokens to evidence tokens isolates heads that are causally responsible for retrieval performance rather than merely correlated with it.
What would settle it
An experiment in which masking the top 5 percent of selected heads produces no larger performance drop on MMLongBench-Doc or SlideVQA than masking an equal number of random heads would falsify the claim of causal importance.
Figures





read the original abstract
Large vision-language models increasingly rely on long-context modeling to reason over documents, hour-level videos, and long-horizon agent trajectories, requiring them to locate relevant evidence across interleaved text and images. Prior work has studied this behavior using retrieval heads in large language models, but its copy-based criterion does not directly apply when evidence appears in images. We introduce a multimodal retrieval head detection method that scores attention from question tokens to textual or visual evidence. With this method, we show that multimodal retrieval heads are sparse, intrinsic, and causally important: only 4.4-10.2% of attention heads account for 50% of the positive retrieval-score mass, and masking the top-5% selected heads drops MMLongBench-Doc from 48.2% to 5.7% and SlideVQA from 71.2% to 8.9%, while random-head masking is far less damaging. Further analysis shows that these heads are partly shared across modalities yet remain dynamic within each modality, with image retrieval heads changing more than text retrieval heads as context length and haystack modality change. Without further training, we find that these heads can also be used directly to rank visually rich documents: on MMDocIR, Qwen3-VL-8B selected-head scoring improves Recall@1 by 7.7/7.4 macro/micro points for page retrieval and 6.3/6.8 points for layout retrieval over the strongest reported baseline.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a multimodal retrieval head detection method that scores attention from question tokens to textual or visual evidence tokens in long-context VLMs. It claims these heads are sparse (only 4.4-10.2% of heads account for 50% of positive retrieval-score mass), intrinsic, and causally important, as masking the top-5% selected heads drops MMLongBench-Doc from 48.2% to 5.7% and SlideVQA from 71.2% to 8.9% while random masking is far less damaging. The heads are partly shared across modalities but dynamic (image heads change more with context length and haystack modality), and the selected heads can be used zero-shot to improve Recall@1 on MMDocIR page and layout retrieval over baselines.
Significance. If the results hold, the work extends retrieval-head findings from LLMs to multimodal long-context settings and identifies a sparse mechanistic component for evidence retrieval across text and images. The differential ablation (top-k vs. random masking) directly tests causality rather than mere correlation. The zero-shot application to document ranking on MMDocIR is a practical strength. Use of public benchmarks and reporting of concrete performance numbers (including the 50% mass sparsity statistic) aids reproducibility.
minor comments (2)
- [Method (around the multimodal retrieval head detection description)] The exact attention-scoring formula, including how positive retrieval-score mass is aggregated and normalized across heads and modalities, should be stated explicitly with an equation in the method section to support full reproduction of the sparsity percentages.
- [Experiments (ablation results on MMLongBench-Doc and SlideVQA)] The ablation experiments report large performance drops but do not include standard deviations across multiple random seeds or statistical significance tests; adding these would strengthen the claim that the differential effect is robust.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation, accurate summary of our contributions on multimodal retrieval heads, and recommendation for minor revision. The report correctly highlights the sparsity (4.4-10.2% heads for 50% mass), causal importance via differential ablation, partial cross-modal sharing, and zero-shot gains on MMDocIR. No major comments were listed in the report, so we have no points requiring rebuttal or revision at this time.
Circularity Check
No significant circularity identified
full rationale
The paper's central claims rest on an introduced attention-scoring procedure applied to existing models, followed by direct empirical measurements of head sparsity (4.4-10.2% heads for 50% mass) and controlled ablation results on public benchmarks (MMLongBench-Doc, SlideVQA, MMDocIR). These quantities are computed from model outputs and dataset performance; no equations or self-citations reduce the reported percentages or drops to quantities defined by the paper's own fitted parameters or prior author results. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard transformer attention mechanism computes relevance between query and key tokens in the usual way.
invented entities (1)
-
multimodal retrieval head
no independent evidence
Reference graph
Works this paper leans on
-
[1]
InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4135–4144
Unveiling Visual Perception in Language Mod- els: An Attention Head Analysis Approach. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4135–4144. Shijie Chen, Bernal Jiménez Gutiérrez, and Yu Su. 2025. Attention in Large Language Models Yields Efficient Zero-Shot Re-Rankers. InInternational Conference on Learni...
2025
-
[2]
ColPali: Efficient Document Retrieval with Vi- sion Language Models. InInternational Conference on Learning Representations. Chaoyou Fu, Yuhan Dai, Yongdong Luo, Lei Li, Shuhuai Ren, Renrui Zhang, Zihan Wang, Chenyu Zhou, Yunhang Shen, Mengdan Zhang, and 1 oth- ers. 2025. Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
WebWatcher: Breaking New Frontier of Vision-Language Deep Research Agent
Webwatcher: Breaking new frontier of vision-language deep research agent.arXiv preprint arXiv:2508.05748. Qidong Huang, Xiaoyi Dong, Pan Zhang, Bin Wang, Conghui He, Jiaqi Wang, Dahua Lin, Weiming Zhang, and Nenghai Yu. 2024. OPERA: Alleviat- ing Hallucination in Multi-Modal Large Language Models via Over-Trust Penalty and Retrospection- Allocation. InPro...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
MemLens: Benchmarking Multimodal Long-Term Memory in Large Vision-Language Models
Memlens: Benchmarking multimodal long- term memory in large vision-language models.arXiv preprint arXiv:2605.14906. Stephen Robertson and Hugo Zaragoza. 2009. The Probabilistic Relevance Framework: BM25 and Be- 10 yond.Foundations and Trends in Information Re- trieval, 3(4):333–389. Sofia Serrano and Noah A. Smith. 2019. Is Attention Interpretable? InProc...
work page internal anchor Pith review Pith/arXiv arXiv 2009
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.