MemLens: Benchmarking Multimodal Long-Term Memory in Large Vision-Language Models
Pith reviewed 2026-06-30 20:58 UTC · model grok-4.3
The pith
New benchmark shows neither long-context vision-language models nor memory agents reliably handle multi-session multimodal reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
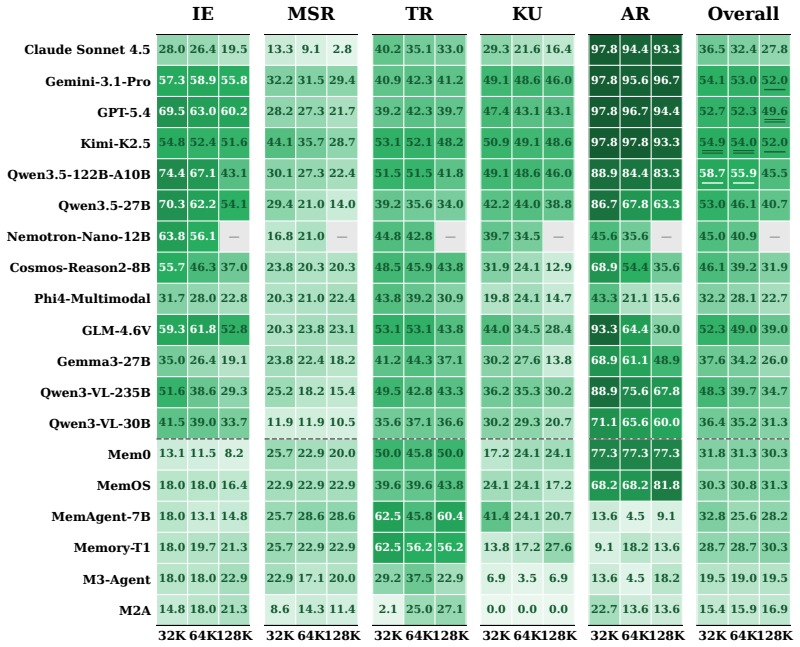
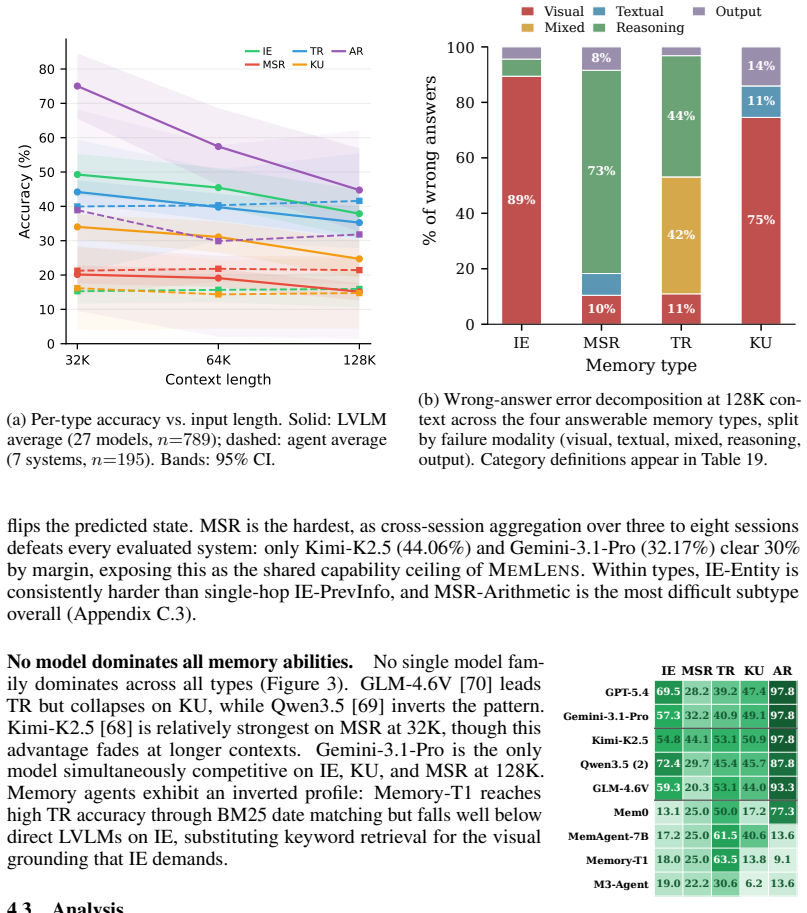
MEMLENS demonstrates that long-context LVLMs achieve high short-context accuracy through direct visual grounding but degrade with longer conversations, whereas memory-augmented agents maintain length stability at the cost of visual fidelity under storage compression; multi-session reasoning caps most systems below 30 percent, and neither approach alone solves the task.
What carries the argument
The MEMLENS benchmark, which tests five memory abilities including multi-session reasoning and knowledge update across four context lengths using a cross-modal token-counting scheme.
If this is right
- Long-context LVLMs will require additional mechanisms to sustain performance beyond current context windows.
- Memory-augmented agents will need improved multimodal compression methods that preserve visual information.
- Hybrid systems combining long-context attention with structured retrieval will be necessary to address the observed gaps.
- Future evaluations of memory in LVLMs should include multi-session reasoning as a core test.
Where Pith is reading between the lines
- Applications involving extended image-based dialogues, such as video analysis over sessions, will remain limited until hybrid memory solutions are developed.
- The benchmark could be extended to test real-time updates in live multimodal streams.
- Models trained with explicit retrieval during generation might close the performance gap on the hardest reasoning categories.
Load-bearing premise
The 789 questions genuinely require multimodal evidence from the conversation images.
What would settle it
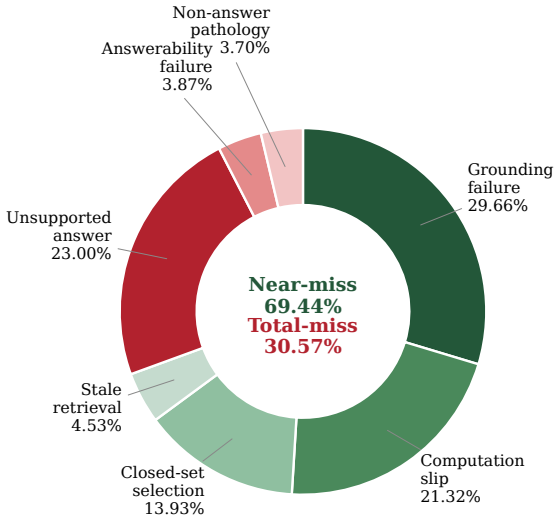
If an image-ablation test on the benchmark questions shows accuracy remaining above 2 percent on more than 20 percent of the items whose evidence includes images, the claim that visual evidence is essential would not hold.
Figures












read the original abstract
Memory is essential for large vision-language models (LVLMs) to handle long, multimodal interactions, with two method directions providing this capability: long-context LVLMs and memory-augmented agents. However, no existing benchmark conducts a systematic comparison of the two on questions that genuinely require multimodal evidence. To close this gap, we introduce MEMLENS, a comprehensive benchmark for memory in multimodal multi-session conversations, comprising 789 questions across five memory abilities (information extraction, multi-session reasoning, temporal reasoning, knowledge update, and answer refusal) at four standard context lengths (32K-256K tokens) under a cross-modal token-counting scheme. An image-ablation study confirms that solving MEMLENS requires visual evidence: removing evidence images drops two frontier LVLMs below 2% accuracy on the 80.4% of questions whose evidence includes images. Evaluating 27 LVLMs and 7 memory-augmented agents, we find that long-context LVLMs achieve high short-context accuracy through direct visual grounding but degrade as conversations grow, whereas memory agents are length-stable but lose visual fidelity under storage-time compression. Multi-session reasoning caps most systems below 30%, and neither approach alone solves the task. These results motivate hybrid architectures that combine long-context attention with structured multimodal retrieval. Our code is available at https://github.com/xrenaf/MEMLENS.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MEMLENS, a benchmark of 789 questions spanning five memory abilities (information extraction, multi-session reasoning, temporal reasoning, knowledge update, answer refusal) and four context lengths (32K-256K tokens) under a cross-modal token scheme. It evaluates 27 LVLMs and 7 memory-augmented agents, reports that long-context LVLMs achieve high short-context accuracy but degrade with length while agents remain length-stable but lose visual fidelity, finds multi-session reasoning capped below 30% for most systems, and concludes that neither approach alone solves the task. An image-ablation study is presented showing accuracy drops below 2% on 80.4% of image-containing questions when evidence images are removed, motivating hybrid architectures combining long-context attention with structured multimodal retrieval. Code is released at the provided GitHub link.
Significance. If the empirical results hold under scrutiny, the work fills a gap by providing the first systematic head-to-head comparison of long-context LVLMs versus memory-augmented agents on questions that demonstrably require multimodal evidence. The public code release is a clear strength that supports reproducibility and follow-on research. The benchmark could become a standard testbed for multimodal memory research and the hybrid-architecture motivation is a direct, falsifiable implication of the reported performance ceilings.
major comments (3)
- [§3] §3 (Benchmark Construction): The manuscript provides no description of how the 789 questions were generated, filtered, or validated to ensure they require multimodal evidence beyond the high-level image-ablation summary; this detail is load-bearing for the central claim that the benchmark tests genuine visual dependence and that neither method class solves the task.
- [§4] §4 (Evaluation Protocol): Model selection criteria for the 27 LVLMs and 7 agents, together with the precise definition and implementation of the cross-modal token-counting scheme, are not specified in the main text; without these, the reported accuracy patterns (short-context strength vs. length stability) cannot be independently assessed or replicated from the paper alone.
- [Results] Results section: The statement that multi-session reasoning 'caps most systems below 30%' is presented without per-model breakdowns, variance estimates, or statistical tests across the 34 evaluated systems; this weakens the evidential basis for the claim that neither approach alone suffices.
minor comments (2)
- [Abstract] The abstract refers to 'four standard context lengths' without listing the exact token values in the abstract itself; adding them would improve standalone readability.
- [Figures] Figure captions for the ablation study should explicitly state the two frontier models used and the exact percentage of questions affected (80.4%) to avoid forcing readers to cross-reference the text.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to incorporate the requested details for improved clarity and reproducibility.
read point-by-point responses
-
Referee: [§3] §3 (Benchmark Construction): The manuscript provides no description of how the 789 questions were generated, filtered, or validated to ensure they require multimodal evidence beyond the high-level image-ablation summary; this detail is load-bearing for the central claim that the benchmark tests genuine visual dependence and that neither method class solves the task.
Authors: We agree that a detailed account of question generation, filtering, and validation is necessary to support the central claims. In the revised manuscript we will expand Section 3 with a full description of the data curation pipeline, selection and filtering criteria, and additional validation steps confirming multimodal evidence requirements for each ability category. revision: yes
-
Referee: [§4] §4 (Evaluation Protocol): Model selection criteria for the 27 LVLMs and 7 agents, together with the precise definition and implementation of the cross-modal token-counting scheme, are not specified in the main text; without these, the reported accuracy patterns (short-context strength vs. length stability) cannot be independently assessed or replicated from the paper alone.
Authors: We acknowledge the need for explicit protocol details. The revised Section 4 will specify the model selection criteria and rationale for the 27 LVLMs and 7 agents, together with a precise definition and implementation description (including tokenization rules across modalities) of the cross-modal counting scheme. revision: yes
-
Referee: [Results] Results section: The statement that multi-session reasoning 'caps most systems below 30%' is presented without per-model breakdowns, variance estimates, or statistical tests across the 34 evaluated systems; this weakens the evidential basis for the claim that neither approach alone suffices.
Authors: The aggregate figure summarizes the full evaluation set, but we agree that granular reporting strengthens the claim. We will add per-model breakdowns, variance estimates, and relevant statistical comparisons to the Results section (with full tables already available in the appendix and released code). revision: partial
Circularity Check
No significant circularity identified
full rationale
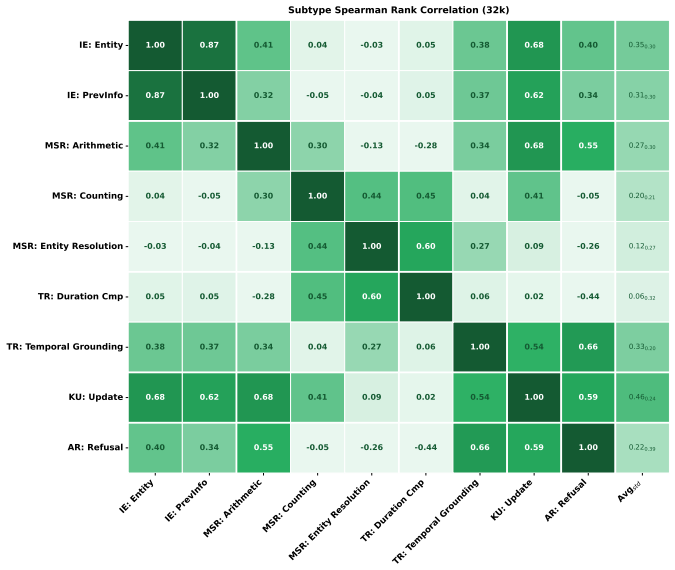
This is an empirical benchmark paper that introduces MEMLENS with 789 questions across five abilities and evaluates 27 LVLMs plus 7 agents on external test data. No derivations, equations, fitted parameters, or predictions appear in the abstract or described content; performance ceilings (e.g., multi-session reasoning <30%) and the image-ablation study (accuracy drop below 2% on 80.4% of image questions) are direct measurements against held-out questions. The motivation for hybrid architectures is a qualitative inference from observed results rather than any self-referential reduction. The paper is self-contained against external benchmarks with no load-bearing self-citations or ansatzes.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 2 Pith papers
-
Can Retrieval Heads See Images? Multimodal Retrieval Heads in Long-Context Vision-Language Models
Multimodal retrieval heads in VLMs are sparse (4.4-10.2% heads carry 50% retrieval mass), causally important (top-5% masking collapses benchmark scores), partly shared across modalities, and improve Recall@1 on MMDocI...
-
SciLens: Multi-modal Scientific Claim Verification with Agentic Entailment and Grounding
SciLens introduces an evidence-conditioned atomic entailment framework that grounds claims to modality-specific witnesses in tables and figures, achieving 79.2% macro-F1 on SciClaimEval.
Reference graph
Works this paper leans on
-
[1]
Bytedance Seed. Seed2. 0 model card: Towards intelligence frontier for real-world complex- ity. Technical report, Technical report, Bytedance, 2025. URL https://lf3-static. bytednsdoc. com
2025
-
[2]
OpenAI. Openai gpt-5 system card, 2025. URLhttps://arxiv.org/abs/2601.03267
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
OpenAI. Gpt-4 technical report, 2023. URLhttps://arxiv.org/abs/2303.08774
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Claude 3 model card
Anthropic. Claude 3 model card. https://assets.anthropic.com/m/61e7d27f8c8f5 919/original/Claude-3-Model-Card.pdf, 2024. Accessed: 2026-04-30
2024
-
[5]
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Gemini Team, Petko Georgiev, Ving Ian Lei, Ryan Burnell, Libin Bai, Anmol Gulati, Garrett Tanzer, Damien Vincent, Zhufeng Pan, Shibo Wang, et al. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context.arXiv preprint arXiv:2403.05530, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
Bytedance Seed. Seed1. 8 model card: Towards generalized real-world agency.arXiv preprint arXiv:2603.20633, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[7]
Claude Sonnet 4.5 System Card
Anthropic. Claude Sonnet 4.5 System Card. https://assets.anthropic.com/m/12f21 4efcc2f457a/original/Claude-Sonnet-4-5-System-Card.pdf, 2025
2025
-
[8]
MemGPT: Towards LLMs as Operating Systems
Charles Packer, Sarah Wooders, Kevin Lin, Vivian Fang, Shishir G. Patil, Ion Stoica, and Joseph E. Gonzalez. Memgpt: Towards llms as operating systems, 2024. URL https: //arxiv.org/abs/2310.08560
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
Mem0: Building production-ready AI agents with scalable long-term memory, 2025
Deshraj Yadav, Taranjeet Singh, and Prashant Srivastava. Mem0: Building production-ready AI agents with scalable long-term memory, 2025. URL https://arxiv.org/abs/2504.1 9413
2025
-
[10]
Bowen Jin, Jinsung Yoon, Jiawei Han, and Sercan O Arik. Long-context llms meet rag: Overcoming challenges for long inputs in rag.arXiv preprint arXiv:2410.05983, 2024
-
[11]
MMLong- Bench: Benchmarking long-context vision-language models effectively and thoroughly, 2025
Zhaowei Wang, Wenhao Yu, Xiyu Ren, Jipeng Zhang, Yu Zhao, Rohit Saxena, Liang Cheng, Ginny Wong, Simon See, Pasquale Minervini, Yangqiu Song, and Mark Steedman. MMLong- Bench: Benchmarking long-context vision-language models effectively and thoroughly, 2025. URLhttps://arxiv.org/abs/2505.10610
-
[12]
Needle in a multimodal haystack, 2024
Weiyun Wang, Shuibo Zhang, Yiming Ren, Yuchen Duan, Tiantong Li, Shuo Liu, Mengkang Hu, Zhe Chen, Kaipeng Zhang, Lewei Lu, Xizhou Zhu, Ping Luo, Yu Qiao, Jifeng Dai, Wenqi Shao, and Wenhai Wang. Needle in a multimodal haystack, 2024. URL https: //arxiv.org/abs/2406.07230
-
[13]
Mmlongbench-doc: Benchmarking long-context document understanding with visualizations, 2024
Yubo Ma, Yuhang Zang, Liangyu Chen, Meiqi Chen, Yizhu Jiao, Xinze Li, Xinyuan Lu, Ziyu Liu, Yan Ma, Xiaoyi Dong, Pan Zhang, Liangming Pan, Yu-Gang Jiang, Jiaqi Wang, Yixin Cao, and Aixin Sun. Mmlongbench-doc: Benchmarking long-context document understanding with visualizations, 2024. URLhttps://arxiv.org/abs/2407.01523
-
[14]
LongMemEval: Benchmarking Chat Assistants on Long-Term Interactive Memory
Di Wu, Hongwei Wang, Wenhao Yu, Yuwei Zhang, Kai-Wei Chang, and Dong Yu. Long- memeval: Benchmarking chat assistants on long-term interactive memory, 2025. URL https://arxiv.org/abs/2410.10813. 11
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
Evaluating Memory in LLM Agents via Incremental Multi-Turn Interactions
Yuanzhe Hu, Yu Wang, and Julian McAuley. Evaluating memory in LLM agents via incremen- tal multi-turn interactions, 2026. URLhttps://arxiv.org/abs/2507.05257
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[16]
Evaluating Very Long-Term Conversational Memory of LLM Agents
Adyasha Maharana, Dong-Ho Lee, Sergey Tulyakov, Mohit Bansal, Francesco Barbieri, and Yuwei Fang. Evaluating very long-term conversational memory of llm agents, 2024. URL https://arxiv.org/abs/2402.17753
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
Mem-Gallery: Benchmarking multimodal long-term conversational memory for MLLM agents, 2026
Yuanchen Bei, Tianxin Wei, Xuying Ning, Yanjun Zhao, Zhining Liu, Xiao Lin, Yada Zhu, Hendrik Hamann, Jingrui He, and Hanghang Tong. Mem-Gallery: Benchmarking multimodal long-term conversational memory for MLLM agents, 2026. URL https://arxiv.org/ab s/2601.03515
-
[18]
Memorybank: Enhancing large language models with long-term memory, 2023
Wanjun Zhong, Lianghong Guo, Qiqi Gao, He Ye, and Yanlin Wang. Memorybank: Enhancing large language models with long-term memory, 2023. URL https://arxiv.org/abs/23 05.10250
2023
-
[19]
MRAG-Bench: Vision-centric evaluation for retrieval-augmented multimodal models,
Wenbo Hu, Jia-Chen Gu, Zi-Yi Dou, Mohsen Fayyaz, Pan Lu, Kai-Wei Chang, and Nanyun Peng. MRAG-Bench: Vision-centric evaluation for retrieval-augmented multimodal models,
- [20]
-
[21]
Hengyi Wang, Haizhou Shi, Shiwei Tan, Weiyi Qin, Wenyuan Wang, Tunyu Zhang, Akshay Nambi, Tanuja Ganu, and Hao Wang. Multimodal needle in a haystack: Benchmarking long-context capability of multimodal large language models, 2025. URL https://arxiv. org/abs/2406.11230
-
[22]
Needle in a haystack — pressure testing LLMs
Greg Kamradt. Needle in a haystack — pressure testing LLMs. https://github.com/gka mradt/LLMTest_NeedleInAHaystack, 2023. GitHub repository
2023
- [23]
-
[24]
SCM: Enhancing large language model with self-controlled memory framework, 2025
Bing Wang, Xinnian Liang, Jian Yang, Hui Huang, Shuangzhi Wu, Peihao Wu, Lu Lu, Zejun Ma, and Zhoujun Li. SCM: Enhancing large language model with self-controlled memory framework, 2025. URLhttps://arxiv.org/abs/2304.13343
-
[25]
Parth Sarthi, Salman Abdullah, Aditi Tuli, Shubh Khanna, Anna Goldie, and Christopher D. Manning. RAPTOR: Recursive abstractive processing for tree-organized retrieval, 2024
2024
-
[26]
Hipporag: Neurobiologically inspired long-term memory for large language models, 2025
Bernal Jiménez Gutiérrez, Yiheng Shu, Yu Gu, Michihiro Yasunaga, and Yu Su. Hipporag: Neurobiologically inspired long-term memory for large language models, 2025. URL https: //arxiv.org/abs/2405.14831
-
[27]
A-MEM: Agentic Memory for LLM Agents
Wujiang Xu, Zujie Liang, Kai Mei, Hang Gao, Juntao Tan, and Yongfeng Zhang. A-MEM: Agentic memory for LLM agents, 2025. URLhttps://arxiv.org/abs/2502.12110
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
Pan, Ruifeng Xu, and Kam-Fai Wong
Yiming Du, Bingbing Wang, Yang He, Bin Liang, Baojun Wang, Zhongyang Li, Lin Gui, Jeff Z. Pan, Ruifeng Xu, and Kam-Fai Wong. Memguide: Intent-driven memory selection for goal-oriented multi-session llm agents, 2025. URL https://arxiv.org/abs/2505.20231
-
[29]
Pan, Yuxin Jiang, and Kam-Fai Wong
Yiming Du, Baojun Wang, Yifan Xiang, Zhaowei Wang, Wenyu Huang, Boyang Xue, Bin Liang, Xingshan Zeng, Fei Mi, Haoli Bai, Lifeng Shang, Jeff Z. Pan, Yuxin Jiang, and Kam-Fai Wong. Memory-t1: Reinforcement learning for temporal reasoning in multi-session agents,
- [30]
-
[31]
Memos: An operating system for memory-augmented generation (mag) in large language models, 2025
Zhiyu Li, Shichao Song, Hanyu Wang, Simin Niu, Ding Chen, Jiawei Yang, Chenyang Xi, Huayi Lai, Jihao Zhao, Yezhaohui Wang, Junpeng Ren, Zehao Lin, Jiahao Huo, Tianyi Chen, Kai Chen, Kehang Li, Zhiqiang Yin, Qingchen Yu, Bo Tang, Hongkang Yang, Zhi-Qin John Xu, and Feiyu Xiong. Memos: An operating system for memory-augmented generation (mag) in large langu...
-
[32]
MemAgent: Reshaping Long-Context LLM with Multi-Conv RL-based Memory Agent
Hongli Yu, Tinghong Chen, Jiangtao Feng, Jiangjie Chen, Weinan Dai, Qiying Yu, Ya-Qin Zhang, Wei-Ying Ma, Jingjing Liu, Mingxuan Wang, and Hao Zhou. Memagent: Reshaping long-context llm with multi-conv rl-based memory agent, 2025. URL https://arxiv.org/ abs/2507.02259
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
M3docrag: Multi- modal retrieval is what you need for multi-page multi-document understanding, 2024
Jaemin Cho, Debanjan Mahata, Ozan Irsoy, Yujie He, and Mohit Bansal. M3docrag: Multi- modal retrieval is what you need for multi-page multi-document understanding, 2024. URL https://arxiv.org/abs/2411.04952. 12
-
[34]
ColPali: Efficient Document Retrieval with Vision Language Models
Manuel Faysse, Hugues Sibille, Tony Wu, Bilel Omrani, Gautier Viaud, Céline Hudelot, and Pierre Colombo. Colpali: Efficient document retrieval with vision language models, 2025. URLhttps://arxiv.org/abs/2407.01449
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
VLM2Vec-V2: Advancing Multimodal Embedding for Videos, Images, and Visual Documents
Rui Meng, Ziyan Jiang, Ye Liu, Mingyi Su, Xinyi Yang, Yuepeng Fu, Can Qin, Zeyuan Chen, Ran Xu, Caiming Xiong, Yingbo Zhou, Wenhu Chen, and Semih Yavuz. VLM2Vec-V2: Advancing multimodal embedding for videos, images, and visual documents, 2025. URL https://arxiv.org/abs/2507.04590
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
Junyu Feng, Binxiao Xu, Jiayi Chen, Mengyu Dai, Cenyang Wu, Haodong Li, Bohan Zeng, Yunliu Xie, Hao Liang, Ming Lu, and Wentao Zhang. M2A: Multimodal memory agent with dual-layer hybrid memory for long-term personalized interactions, 2026. URL https: //arxiv.org/abs/2602.07624
-
[37]
Seeing, listening, remembering, and reasoning: A multimodal agent with long-term memory,
Lin Long, Yichen He, Wentao Ye, Yiyuan Pan, Yuan Lin, Hang Li, Junbo Zhao, and Wei Li. Seeing, listening, remembering, and reasoning: A multimodal agent with long-term memory,
- [38]
-
[39]
Moviechat: From dense token to sparse memory for long video understanding
Enxin Song, Wenhao Chai, Guanhong Wang, Yucheng Zhang, Haoyang Zhou, Feiyang Wu, Haozhe Chi, Xun Guo, Tian Ye, Yanting Zhang, et al. Moviechat: From dense token to sparse memory for long video understanding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18221–18232, 2024
2024
-
[40]
Jihyoung Jang, Minwook Bae, Minji Kim, Dilek Hakkani-Tur, and Hyounghun Kim. Enabling chatbots with eyes and ears: An immersive multimodal conversation system for dynamic interactions, 2025. URLhttps://arxiv.org/abs/2506.00421
-
[41]
Bingbing Wang, Yiming Du, Bin Liang, Zhixin Bai, Min Yang, Baojun Wang, Kam-Fai Wong, and Ruifeng Xu. A new formula for sticker retrieval: Reply with stickers in multi- modal and multi-session conversation.Proceedings of the AAAI Conference on Artificial Intelligence, 39(24):25327–25335, Apr. 2025. doi: 10.1609/aaai.v39i24.34720. URL https://ojs.aaai.org/...
-
[42]
Ziyan Jiang, Xueguang Ma, and Wenhu Chen. Longrag: Enhancing retrieval-augmented generation with long-context llms.arXiv preprint arXiv:2406.15319, 2024
-
[43]
Self-rag: Learning to retrieve, generate, and critique through self-reflection
Akari Asai, Zeqiu Wu, Yizhong Wang, Avirup Sil, and Hannaneh Hajishirzi. Self-rag: Learning to retrieve, generate, and critique through self-reflection. InThe Twelfth International Conference on Learning Representations, 2023
2023
-
[44]
Longbench: A bilingual, multitask benchmark for long context understanding
Yushi Bai, Xin Lv, Jiajie Zhang, Hongchang Lyu, Jiankai Tang, Zhidian Huang, Zhengxiao Du, Xiao Liu, Aohan Zeng, Lei Hou, et al. Longbench: A bilingual, multitask benchmark for long context understanding. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 3119–3137, 2024
2024
-
[45]
LongBench v2: Towards Deeper Understanding and Reasoning on Realistic Long-context Multitasks
Yushi Bai, Shangqing Tu, Jiajie Zhang, Hao Peng, Xiaozhi Wang, Xin Lv, Shulin Cao, Jiazheng Xu, Lei Hou, Yuxiao Dong, et al. Longbench v2: Towards deeper understanding and reasoning on realistic long-context multitasks.arXiv preprint arXiv:2412.15204, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[46]
Ruler: What’s the real context size of your long-context language models? InFirst Conference on Language Modeling, 2024
Cheng-Ping Hsieh, Simeng Sun, Samuel Kriman, Shantanu Acharya, Dima Rekesh, Fei Jia, and Boris Ginsburg. Ruler: What’s the real context size of your long-context language models? InFirst Conference on Language Modeling, 2024
2024
-
[47]
Howard Yen, Tianyu Gao, Minmin Hou, Ke Ding, Daniel Fleischer, Peter Izsak, Moshe Wasserblat, and Danqi Chen. Helmet: How to evaluate long-context language models effec- tively and thoroughly.arXiv preprint arXiv:2410.02694, 2024
-
[48]
L-eval: Instituting standardized evaluation for long context language models
Chenxin An, Shansan Gong, Ming Zhong, Xingjian Zhao, Mukai Li, Jun Zhang, Lingpeng Kong, and Xipeng Qiu. L-eval: Instituting standardized evaluation for long context language models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 14388–14411, 2024
2024
-
[49]
∞Bench: Extending long context evaluation beyond 100k tokens
Xinrong Zhang, Yingfa Chen, Shengding Hu, Zihang Xu, Junhao Chen, Moo Hao, Xu Han, Zhen Thai, Shuo Wang, Zhiyuan Liu, et al. ∞Bench: Extending long context evaluation beyond 100k tokens. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 15262–15277, 2024
2024
-
[50]
Mo Li, Songyang Zhang, Yunxin Liu, and Kai Chen. Needlebench: Can llms do retrieval and reasoning in 1 million context window?arXiv preprint arXiv:2407.11963, 2024. 13
-
[51]
MLVU: Benchmarking Multi-task Long Video Understanding
Junjie Zhou, Yan Shu, Bo Zhao, Boya Wu, Zhengyang Liang, Shitao Xiao, Minghao Qin, Xi Yang, Yongping Xiong, Bo Zhang, Tiejun Huang, and Zheng Liu. Mlvu: Benchmarking multi-task long video understanding, 2025. URLhttps://arxiv.org/abs/2406.04264
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[52]
LongVideoBench: A Benchmark for Long-context Interleaved Video-Language Understanding
Haoning Wu, Dongxu Li, Bei Chen, and Junnan Li. Longvideobench: A benchmark for long-context interleaved video-language understanding, 2024. URL https://arxiv.org/ abs/2407.15754
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[53]
Chao Deng, Jiale Yuan, Pi Bu, Peijie Wang, Zhong-Zhi Li, Jian Xu, Xiao-Hui Li, Yuan Gao, Jun Song, Bo Zheng, et al. Longdocurl: a comprehensive multimodal long document benchmark integrating understanding, reasoning, and locating.arXiv preprint arXiv:2412.18424, 2024
-
[54]
M-longdoc: A benchmark for multimodal super-long document understanding and a retrieval-aware tuning framework
Yew Ken Chia, Liying Cheng, Hou Pong Chan, CHAOQUN LIU, Maojia Song, Mahani Aljunied, Soujanya Poria, and Lidong Bing. M-longdoc: A benchmark for multimodal super-long document understanding and a retrieval-aware tuning framework. 2024
2024
-
[55]
Zhaowei Wang, Hongming Zhang, Tianqing Fang, Ye Tian, Yue Yang, Kaixin Ma, Xiaoman Pan, Yangqiu Song, and Dong Yu. Divscene: Towards open-vocabulary object navigation with large vision language models in diverse scenes.arXiv preprint arXiv:2410.02730, 2024
-
[56]
Milebench: Benchmarking mllms in long context.arXiv preprint arXiv:2404.18532, 2024
Dingjie Song, Shunian Chen, Guiming Hardy Chen, Fei Yu, Xiang Wan, and Benyou Wang. Milebench: Benchmarking mllms in long context.arXiv preprint arXiv:2404.18532, 2024
-
[57]
Xidong Wang, Dingjie Song, Shunian Chen, Chen Zhang, and Benyou Wang. Longllava: Scaling multi-modal llms to 1000 images efficiently via a hybrid architecture.arXiv preprint arXiv:2409.02889, 2024
-
[58]
mplug-owl3: Towards long image-sequence understanding in multi-modal large language models.CoRR, 2024
Jiabo Ye, Haiyang Xu, Haowei Liu, Anwen Hu, Ming Yan, Qi Qian, Ji Zhang, Fei Huang, and Jingren Zhou. mplug-owl3: Towards long image-sequence understanding in multi-modal large language models.CoRR, 2024
2024
-
[59]
Yiming Du, Hongru Wang, Zhengyi Zhao, Bin Liang, Baojun Wang, Wanjun Zhong, Zezhong Wang, and Kam-Fai Wong. Perltqa: A personal long-term memory dataset for memory classification, retrieval, and synthesis in question answering, 2024. URL https://arxiv.or g/abs/2402.16288
-
[60]
Knowledge conflicts for LLMs: A survey
Rongwu Xu, Zehan Qi, Zhijiang Guo, Cunxiang Wang, Hongru Wang, Yue Zhang, and Wei Xu. Knowledge conflicts for LLMs: A survey. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 8541–8565, 2024
2024
-
[61]
I don’t know
Hanning Zhang, Shizhe Diao, Yong Lin, Yi R. Fung, Qing Lian, Xingyao Wang, Yangyi Chen, Heng Ji, and Tong Zhang. R-tuning: Instructing large language models to say “I don’t know”. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 7...
2024
-
[62]
Gemini 3 Pro Model Card
Google DeepMind. Gemini 3 Pro Model Card. https://deepmind.google/models/mod el-cards/gemini-3-pro/, 2026
2026
-
[63]
Obelics: An open web-scale filtered dataset of interleaved image-text documents.Advances in Neural Information Processing Systems, 36:71683–71702, 2023
Hugo Laurençon, Lucile Saulnier, Léo Tronchon, Stas Bekman, Amanpreet Singh, Anton Lozhkov, Thomas Wang, Siddharth Karamcheti, Alexander Rush, Douwe Kiela, et al. Obelics: An open web-scale filtered dataset of interleaved image-text documents.Advances in Neural Information Processing Systems, 36:71683–71702, 2023
2023
-
[64]
Open-domain visual entity recognition: Towards recognizing millions of wikipedia entities
Hexiang Hu, Yi Luan, Yang Chen, Urvashi Khandelwal, Mandar Joshi, Kenton Lee, Kristina Toutanova, and Ming-Wei Chang. Open-domain visual entity recognition: Towards recognizing millions of wikipedia entities. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 12065–12075, 2023
2023
-
[65]
Abspyramid: Benchmarking the abstraction ability of language models with a unified entailment graph
Zhaowei Wang, Haochen Shi, Weiqi Wang, Tianqing Fang, Hongming Zhang, Sehyun Choi, Xin Liu, and Yangqiu Song. Abspyramid: Benchmarking the abstraction ability of language models with a unified entailment graph. InFindings of the Association for Computational Linguistics: NAACL 2024, pages 3991–4010, 2024
2024
-
[66]
Absinstruct: Eliciting abstraction ability from llms through explanation tuning with plausibility estimation
Zhaowei Wang, Wei Fan, Qing Zong, Hongming Zhang, Sehyun Choi, Tianqing Fang, Xin Liu, Yangqiu Song, Ginny Wong, and Simon See. Absinstruct: Eliciting abstraction ability from llms through explanation tuning with plausibility estimation. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), page...
2024
-
[67]
Cross-modal retrieval for knowledge- based visual question answering, 2024
Paul Lerner, Olivier Ferret, and Camille Guinaudeau. Cross-modal retrieval for knowledge- based visual question answering, 2024. URLhttps://arxiv.org/abs/2401.05736
-
[68]
Enhancing chat language models by scaling high-quality instructional conversations
Ning Ding, Yulin Chen, Bokai Xu, Yujia Qin, Zhi Zheng, Shengding Hu, Zhiyuan Liu, Maosong Sun, and Bowen Zhou. Enhancing chat language models by scaling high-quality instructional conversations. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 3029–3051, 2023
2023
-
[69]
When not to trust language models: Investigating effectiveness of parametric and non-parametric memories
Alex Mallen, Akari Asai, Victor Zhong, Rajarshi Das, Daniel Khashabi, and Hannaneh Hajishirzi. When not to trust language models: Investigating effectiveness of parametric and non-parametric memories. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 9802–9822, 2023
2023
-
[70]
Gemini 3.1 pro, February 2026
Google DeepMind. Gemini 3.1 pro, February 2026. URL https://storage.googleap is.com/deepmind-media/Model-Cards/Gemini-3-1-Pro-Model-Card.pdf . Model card
2026
-
[71]
Kimi K2.5: Visual Agentic Intelligence
Kimi Team. Kimi k2.5: Visual agentic intelligence, 2026. URL https://arxiv.org/abs/ 2602.02276
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[72]
Qwen3.5: Towards Native Multimodal Agents
Qwen Team. Qwen3.5: Towards Native Multimodal Agents. https://www.alibabacloud .com/blog/qwen3-5-towards-native-multimodal-agents_602894, 2026
2026
-
[73]
GLM-4.6V Model Card
Zhipu AI. GLM-4.6V Model Card. https://huggingface.co/zai-org/GLM-4.6V , 2025
2025
-
[74]
Gemma 3 technical report, 2025
Gemma Team. Gemma 3 technical report, 2025. URL https://arxiv.org/abs/2503.1 9786
2025
-
[75]
BLIP-2: Bootstrapping language- image pre-training with frozen image encoders and large language models
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. BLIP-2: Bootstrapping language- image pre-training with frozen image encoders and large language models. InProceedings of the 40th International Conference on Machine Learning, volume 202 ofProceedings of Machine Learning Research, pages 19730–19742. PMLR, 2023
2023
-
[76]
Xing, Hao Zhang, Joseph E
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. Judging LLM-as-a-judge with MT-Bench and Chatbot Arena. InAdvances in Neural Information Processing Systems, volume 36, 2023
2023
-
[77]
Abstain-R1: Calibrated abstention and post-refusal clarification via verifiable RL, 2026
Skylar Zhai, Jingcheng Liang, and Dongyeop Kang. Abstain-R1: Calibrated abstention and post-refusal clarification via verifiable RL, 2026. URL https://arxiv.org/abs/2604.1 7073
2026
-
[78]
Same task, more tokens: the impact of input length on the reasoning performance of large language models
Mosh Levy, Alon Jacoby, and Yoav Goldberg. Same task, more tokens: the impact of input length on the reasoning performance of large language models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 15339–15353, 2024
2024
-
[79]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, Wenbin Ge, Zhifang Guo, Qidong Huang, Jie Huang, Fei Huang, Binyuan Hui, Shutong Jiang, Zhaohai Li, Mingsheng Li, Mei Li, Kaixin Li, Zicheng Lin, Junyang Lin, Xuejing Liu, Jiawei Liu, Chenglong Liu, Yang Liu, Dayiheng Liu, Shixuan ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[80]
V Team. Glm-4.5v and glm-4.1v-thinking: Towards versatile multimodal reasoning with scalable reinforcement learning, 2026. URLhttps://arxiv.org/abs/2507.01006
work page internal anchor Pith review Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.