PARE: Pruning and Adaptive Routing for Efficient Video Generation
Pith reviewed 2026-06-29 18:04 UTC · model grok-4.3
The pith
PARE reduces per-step computation in video diffusion transformers by pruning attention heads according to their spatial-temporal roles and dynamically routing blocks via a content-timestep router while preserving quality.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
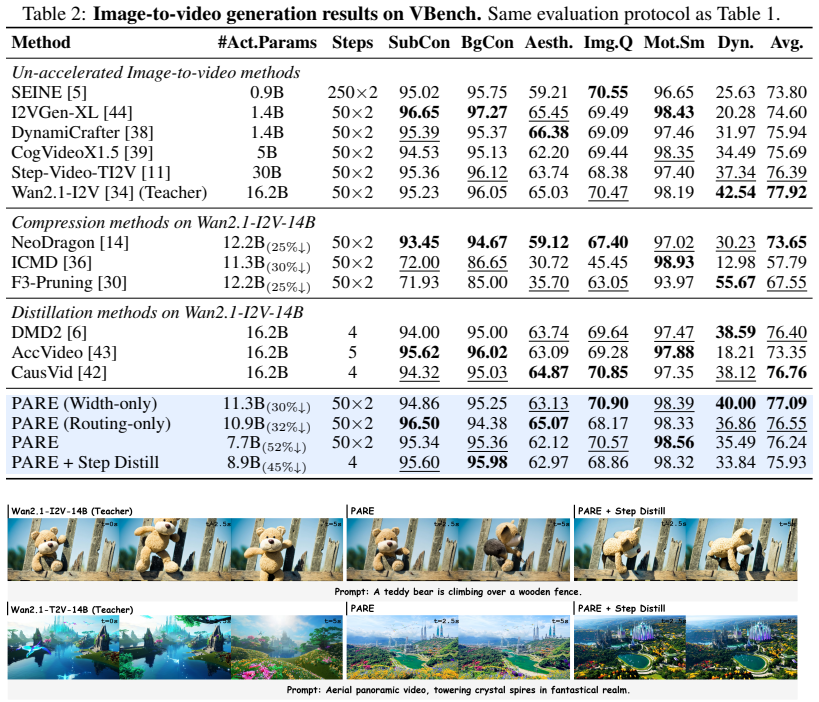
PARE jointly compresses width and depth of Video Diffusion Transformers with structure-aware pruning of attention heads and input-adaptive routing of blocks; a progressive pipeline first recovers from width pruning via distillation then optimizes the student model together with the router, yielding reduced per-step compute on Wan2.1-14B while maintaining quality across VBench dimensions for image-to-video and text-to-video generation.
What carries the argument
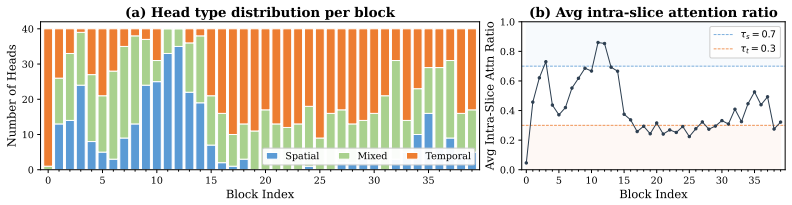
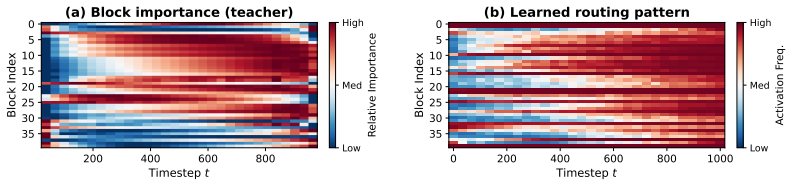
Importance scoring for attention heads that accounts for their observed spatial versus temporal specialization, paired with a lightweight router conditioned on denoising timestep and visual content to select blocks dynamically.
If this is right
- Substantially reduces per-step computation while preserving quality across VBench dimensions.
- Enables per-input and per-timestep compute adaptation instead of fixed architecture changes.
- Composes with step distillation for further acceleration in both image-to-video and text-to-video settings.
- Maintains generation quality after joint width-depth compression on large models like Wan2.1-14B.
Where Pith is reading between the lines
- The observed head specialization could be tested in other diffusion transformer architectures beyond video.
- Dynamic routing might support variable compute budgets based on available hardware without retraining.
- The progressive distillation-then-joint-optimization pipeline may generalize to other joint compression tasks.
Load-bearing premise
Attention heads specialize into distinct spatial and temporal roles so an importance score can safely prune non-motion-critical ones.
What would settle it
If applying the proposed head importance scoring causes a clear drop in motion-related VBench metrics such as motion smoothness or dynamic degree, the specialization premise would be falsified.
Figures

read the original abstract
Video Diffusion Transformers (DiTs) generate high-quality videos but demand substantial compute due to wide blocks, deep architectures, and iterative sampling. Recent methods reduce cost by compressing width, depth, or sampling steps, but typically commit to a fixed architecture that cannot adapt to individual inputs or denoising stages. We propose PARE (Pruning and Adaptive Routing for Efficient video generation), which jointly compresses width and depth with structure-aware pruning and input-adaptive routing. For width, we observe that attention heads specialize into spatial and temporal roles, and design importance scoring that accounts for this distinction to prevent motion-critical temporal heads from being pruned prematurely. For depth, we train a lightweight router conditioned on denoising timestep and visual content to dynamically select which blocks to execute at each step, enabling per-input compute adaptation rather than static block removal. A progressive pipeline first recovers width-pruned quality via distillation, then jointly optimizes the student and router to decouple the two learning objectives. Experiments on Wan2.1-14B for both image-to-video and text-to-video generation show that PARE substantially reduces per-step computation while preserving quality across VBench dimensions, and composes with step distillation for further acceleration.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes PARE, which jointly performs width compression via structure-aware pruning of attention heads (leveraging an observed specialization into spatial vs. temporal roles) and depth compression via a lightweight router that selects blocks conditioned on denoising timestep and visual content. A progressive distillation pipeline first recovers quality after width pruning, then jointly optimizes the student and router. Experiments on Wan2.1-14B for I2V and T2V tasks claim substantial per-step compute reduction while preserving VBench scores and compatibility with step distillation.
Significance. If the specialization observation and router training hold under broader testing, the method would offer a practical route to input- and timestep-adaptive compute reduction in large video DiTs without committing to a single static architecture. The explicit separation of width and depth objectives via the progressive pipeline is a methodological strength.
major comments (2)
- [Abstract] Abstract: the headline claim that PARE 'substantially reduces per-step computation while preserving quality across VBench dimensions' supplies no quantitative results, error bars, ablation tables, or per-dimension scores, so it is impossible to judge whether the data support the claim.
- [Abstract] Abstract: the width-pruning strategy is predicated on the claim that attention heads specialize into distinct spatial and temporal roles, allowing an importance score to protect motion-critical temporal heads. No head-wise motion sensitivity metrics, layer-wise statistics, or ablation that removes the spatial/temporal distinction are reported; this assumption is load-bearing for the quality-preservation result.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate planned revisions to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline claim that PARE 'substantially reduces per-step computation while preserving quality across VBench dimensions' supplies no quantitative results, error bars, ablation tables, or per-dimension scores, so it is impossible to judge whether the data support the claim.
Authors: We agree that the abstract, being a high-level summary, does not contain specific quantitative results. The full manuscript reports detailed per-step FLOPs reductions, VBench per-dimension scores, error bars from multiple runs, and ablation tables in Section 4. We will revise the abstract to incorporate key quantitative highlights (e.g., approximate compute reduction percentages and VBench preservation) with pointers to the relevant tables and figures. revision: yes
-
Referee: [Abstract] Abstract: the width-pruning strategy is predicated on the claim that attention heads specialize into distinct spatial and temporal roles, allowing an importance score to protect motion-critical temporal heads. No head-wise motion sensitivity metrics, layer-wise statistics, or ablation that removes the spatial/temporal distinction are reported; this assumption is load-bearing for the quality-preservation result.
Authors: The manuscript presents the head specialization observation through importance scoring that differentiates spatial and temporal roles, supported by analysis in the methods and experiments. To strengthen the presentation, we will add explicit head-wise motion sensitivity metrics, layer-wise statistics, and an ablation that removes the spatial/temporal distinction in the revised version. revision: yes
Circularity Check
No circularity detected; method is empirically grounded
full rationale
The paper proposes PARE as a pruning-plus-routing technique for video DiTs, grounded in an empirical observation of head specialization and a trained lightweight router. No equations, fitted parameters renamed as predictions, or self-citation chains appear in the abstract or described pipeline that would reduce any claimed result to its own inputs by construction. Performance claims rest on external experimental validation against VBench on Wan2.1-14B rather than self-referential definitions or load-bearing self-citations.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Estimating or Propagating Gradients Through Stochastic Neurons for Conditional Computation
Yoshua Bengio, Nicholas Léonard, and Aaron Courville. Estimating or propagating gradients through stochastic neurons for conditional computation.arXiv preprint arXiv:1308.3432, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[2]
Is space-time attention all you need for video understanding? InIcml, volume 2, page 4, 2021
Gedas Bertasius, Heng Wang, and Lorenzo Torresani. Is space-time attention all you need for video understanding? InIcml, volume 2, page 4, 2021
2021
-
[3]
Videocrafter2: Overcoming data limitations for high-quality video diffusion models
Haoxin Chen, Yong Zhang, Xiaodong Cun, Menghan Xia, Xintao Wang, Chao Weng, and Ying Shan. Videocrafter2: Overcoming data limitations for high-quality video diffusion models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 7310–7320, 2024
2024
- [4]
-
[5]
Seine: Short-to-long video diffusion model for generative transition and prediction
Xinyuan Chen, Yaohui Wang, Lingjun Zhang, Shaobin Zhuang, Xin Ma, Jiashuo Yu, Yali Wang, Dahua Lin, Yu Qiao, and Ziwei Liu. Seine: Short-to-long video diffusion model for generative transition and prediction. InThe Twelfth International Conference on Learning Representations, 2023. 10
2023
-
[6]
Lightx2v: Light video generation inference framework
LightX2V Contributors. Lightx2v: Light video generation inference framework. https: //github.com/ModelTC/lightx2v, 2025
2025
-
[7]
Structural pruning for diffusion models
Gongfan Fang, Xinyin Ma, and Xinchao Wang. Structural pruning for diffusion models. In Advances in Neural Information Processing Systems, 2023
2023
-
[8]
Salt: Self-Consistent Distribution Matching with Cache-Aware Training for Fast Video Generation
Xingtong Ge, Yi Zhang, Yushi Huang, Dailan He, Xiahong Wang, Bingqi Ma, Guanglu Song, Yu Liu, and Jun Zhang. Salt: Self-consistent distribution matching with cache-aware training for fast video generation.arXiv preprint arXiv:2604.03118, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[9]
LTX-Video: Realtime Video Latent Diffusion
Yoav HaCohen, Nisan Chiprut, Benny Brazowski, Daniel Shalem, Dudu Moshe, Eitan Richard- son, Eran Levin, Guy Shiran, Nir Zabari, Ori Gordon, et al. Ltx-video: Realtime video latent diffusion.arXiv preprint arXiv:2501.00103, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
Classifier-Free Diffusion Guidance
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance.arXiv preprint arXiv:2207.12598, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[11]
Haoyang Huang, Guoqing Ma, Nan Duan, Xing Chen, Changyi Wan, Ranchen Ming, Tianyu Wang, Bo Wang, Zhiying Lu, Aojie Li, et al. Step-video-ti2v technical report: A state-of-the-art text-driven image-to-video generation model.arXiv preprint arXiv:2503.11251, 2025
-
[12]
Vbench: Comprehensive benchmark suite for video generative models
Ziqi Huang, Yinan He, Jiashuo Yu, Fan Zhang, Chenyang Si, Yuming Jiang, Yuanhan Zhang, Tianxing Wu, Qingyang Jin, Nattapol Chanpaisit, et al. Vbench: Comprehensive benchmark suite for video generative models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21807–21818, 2024
2024
-
[13]
Albert Q Jiang, Alexandre Sablayrolles, Antoine Roux, Arthur Mensch, Blanche Savary, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Emma Bou Hanna, Florian Bressand, et al. Mixtral of experts.arXiv preprint arXiv:2401.04088, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
Animesh Karnewar, Denis Korzhenkov, Ioannis Lelekas, Adil Karjauv, Noor Fathima, Hanwen Xiong, Vancheeswaran Vaidyanathan, Will Zeng, Rafael Esteves, Tushar Singhal, et al. Neo- dragon: Mobile video generation using diffusion transformer.arXiv preprint arXiv:2511.06055, 2025
-
[15]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Weijie Kong, Qi Tian, Zijian Zhang, Rox Min, Zuozhuo Dai, Jin Zhou, Jiangfeng Xiong, Xin Li, Bo Wu, Jianwei Zhang, et al. Hunyuanvideo: A systematic framework for large video generative models.arXiv preprint arXiv:2412.03603, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
Flow Matching for Generative Modeling
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[17]
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow.arXiv preprint arXiv:2209.03003, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[18]
Latent Consistency Models: Synthesizing High-Resolution Images with Few-Step Inference
Simian Luo, Yiqin Tan, Longbo Huang, Jian Li, and Hang Zhao. Latent consistency models: Synthesizing high-resolution images with few-step inference.arXiv preprint arXiv:2310.04378, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[19]
Learning-to-cache: Accelerating diffusion transformer via layer caching.Advances in Neural Information Processing Systems, 37:133282–133304, 2024
Xinyin Ma, Gongfan Fang, Michael Bi Mi, and Xinchao Wang. Learning-to-cache: Accelerating diffusion transformer via layer caching.Advances in Neural Information Processing Systems, 37:133282–133304, 2024
2024
-
[20]
Deepcache: Accelerating diffusion models for free
Xinyin Ma, Gongfan Fang, and Xinchao Wang. Deepcache: Accelerating diffusion models for free. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 15762–15772, 2024
2024
-
[21]
Are sixteen heads really better than one? Advances in neural information processing systems, 32, 2019
Paul Michel, Omer Levy, and Graham Neubig. Are sixteen heads really better than one? Advances in neural information processing systems, 32, 2019
2019
-
[22]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF international conference on computer vision, pages 4195–4205, 2023. 11
2023
-
[23]
Movie Gen: A Cast of Media Foundation Models
Adam Polyak, Amit Zohar, Andrew Brown, Andros Tjandra, Animesh Sinha, Ann Lee, Apoorv Vyas, Bowen Shi, Chih-Yao Ma, Ching-Yao Chuang, et al. Movie gen: A cast of media foundation models.arXiv preprint arXiv:2410.13720, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
Dynamicvit: Efficient vision transformers with dynamic token sparsification.Advances in neural information processing systems, 34:13937–13949, 2021
Yongming Rao, Wenliang Zhao, Benlin Liu, Jiwen Lu, Jie Zhou, and Cho-Jui Hsieh. Dynamicvit: Efficient vision transformers with dynamic token sparsification.Advances in neural information processing systems, 34:13937–13949, 2021
2021
-
[25]
Progressive Distillation for Fast Sampling of Diffusion Models
Tim Salimans and Jonathan Ho. Progressive distillation for fast sampling of diffusion models. arXiv preprint arXiv:2202.00512, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[26]
Shitong Shao, Yufei Gu, and Zeke Xie. Fastlightgen: Fast and light video generation with fewer steps and parameters.arXiv preprint arXiv:2603.01685, 2026
-
[27]
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, and Jeff Dean. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer.arXiv preprint arXiv:1701.06538, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[28]
Consistency models
Yang Song, Prafulla Dhariwal, Mark Chen, and Ilya Sutskever. Consistency models. 2023
2023
-
[29]
Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu. Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
2024
-
[30]
F 3-pruning: a training-free and generalized pruning strategy towards faster and finer text-to-video synthesis
Sitong Su, Jianzhi Liu, Lianli Gao, and Jingkuan Song. F 3-pruning: a training-free and generalized pruning strategy towards faster and finer text-to-video synthesis. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 4961–4969, 2024
2024
-
[31]
A Simple and Effective Pruning Approach for Large Language Models
Mingjie Sun, Zhuang Liu, Anna Bair, and J Zico Kolter. A simple and effective pruning approach for large language models.arXiv preprint arXiv:2306.11695, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[32]
Branchynet: Fast inference via early exiting from deep neural networks
Surat Teerapittayanon, Bradley McDanel, and Hsiang-Tsung Kung. Branchynet: Fast inference via early exiting from deep neural networks. In2016 23rd international conference on pattern recognition (ICPR), pages 2464–2469. IEEE, 2016
2016
-
[33]
Analyzing multi-head self-attention: Specialized heads do the heavy lifting, the rest can be pruned
Elena V oita, David Talbot, Fedor Moiseev, Rico Sennrich, and Ivan Titov. Analyzing multi-head self-attention: Specialized heads do the heavy lifting, the rest can be pruned. InProceedings of the 57th annual meeting of the association for computational linguistics, pages 5797–5808, 2019
2019
-
[34]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
Yutong Wang, Haiyu Zhang, Tianfan Xue, Yu Qiao, Yaohui Wang, Chang Xu, and Xinyuan Chen. Vdot: Efficient unified video creation via optimal transport distillation.arXiv preprint arXiv:2512.06802, 2025
-
[36]
Yiming Wu, Zhenghao Chen, Huan Wang, and Dong Xu. Individual content and motion dynamics preserved pruning for video diffusion models.arXiv preprint arXiv:2411.18375, 2024
-
[37]
Yushu Wu, Yanyu Li, Anil Kag, Ivan Skorokhodov, Willi Menapace, Ke Ma, Arpit Sahni, Ju Hu, Aliaksandr Siarohin, Dhritiman Sagar, Yanzhi Wang, and Sergey Tulyakov. Taming diffusion transformer for efficient mobile video generation in seconds.arXiv preprint arXiv:2507.13343, 2025
-
[38]
Dynamicrafter: Animating open-domain images with video diffusion priors
Jinbo Xing, Menghan Xia, Yong Zhang, Haoxin Chen, Wangbo Yu, Hanyuan Liu, Gongye Liu, Xintao Wang, Ying Shan, and Tien-Tsin Wong. Dynamicrafter: Animating open-domain images with video diffusion priors. InEuropean Conference on Computer Vision, pages 399–417. Springer, 2024
2024
-
[39]
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiaohan Zhang, Guanyu Feng, et al. Cogvideox: Text-to-video diffusion models with an expert transformer.arXiv preprint arXiv:2408.06072, 2024. 12
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[40]
Improved distribution matching distillation for fast image synthesis
Tianwei Yin, Michaël Gharbi, Taesung Park, Richard Zhang, Eli Shechtman, Fredo Durand, and William T Freeman. Improved distribution matching distillation for fast image synthesis. Advances in neural information processing systems, 37:47455–47487, 2024
2024
-
[41]
One-step diffusion with distribution matching distillation
Tianwei Yin, Michaël Gharbi, Richard Zhang, Eli Shechtman, Fredo Durand, William T Freeman, and Taesung Park. One-step diffusion with distribution matching distillation. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6613–6623, 2024
2024
-
[42]
From slow bidirectional to fast autoregressive video diffusion models
Tianwei Yin, Qiang Zhang, Richard Zhang, William T Freeman, Fredo Durand, Eli Shechtman, and Xun Huang. From slow bidirectional to fast autoregressive video diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22963–22974, 2025
2025
-
[43]
Haiyu Zhang, Xinyuan Chen, Yaohui Wang, Xihui Liu, Yunhong Wang, and Yu Qiao. Accvideo: Accelerating video diffusion model with synthetic dataset.arXiv preprint arXiv:2503.19462, 2025
-
[44]
I2VGen-XL: High-Quality Image-to-Video Synthesis via Cascaded Diffusion Models
Shiwei Zhang, Jiayu Wang, Yingya Zhang, Kang Zhao, Hangjie Yuan, Zhiwu Qin, Xiang Wang, Deli Zhao, and Jingren Zhou. I2vgen-xl: High-quality image-to-video synthesis via cascaded diffusion models.arXiv preprint arXiv:2311.04145, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[45]
Dynamic diffusion transformer.arXiv preprint arXiv:2410.03456, 2024
Wangbo Zhao, Yizeng Han, Jiasheng Tang, Kai Wang, Yibing Song, Gao Huang, Fan Wang, and Yang You. Dynamic diffusion transformer.arXiv preprint arXiv:2410.03456, 2024
-
[46]
Unipc: A unified predictor- corrector framework for fast sampling of diffusion models.Advances in Neural Information Processing Systems, 36:49842–49869, 2023
Wenliang Zhao, Lujia Bai, Yongming Rao, Jie Zhou, and Jiwen Lu. Unipc: A unified predictor- corrector framework for fast sampling of diffusion models.Advances in Neural Information Processing Systems, 36:49842–49869, 2023
2023
-
[47]
Real-time video generation with pyramid attention broadcast.arXiv preprint arXiv:2408.12588, 2024
Xuanlei Zhao, Xiaolong Jin, Kai Wang, and Yang You. Real-time video generation with pyramid attention broadcast.arXiv preprint arXiv:2408.12588, 2024
-
[48]
Large Scale Diffusion Distillation via Score-Regularized Continuous-Time Consistency
Kaiwen Zheng, Yuji Wang, Qianli Ma, Huayu Chen, Jintao Zhang, Yogesh Balaji, Jianfei Chen, Ming-Yu Liu, Jun Zhu, and Qinsheng Zhang. Large scale diffusion distillation via score-regularized continuous-time consistency.arXiv preprint arXiv:2510.08431, 2025. 13
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.