Recognition: 2 theorem links
· Lean TheoremSalt: Self-Consistent Distribution Matching with Cache-Aware Training for Fast Video Generation
Pith reviewed 2026-05-13 19:35 UTC · model grok-4.3
The pith
Salt distills video models to 2-4 steps by regularizing the endpoint consistency of consecutive denoising updates and conditioning on KV cache states.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
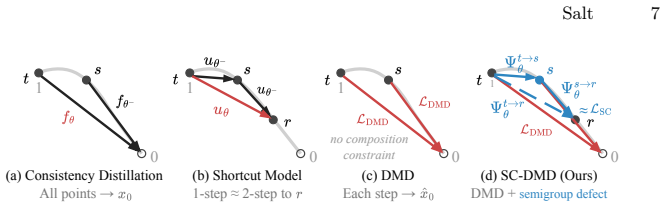
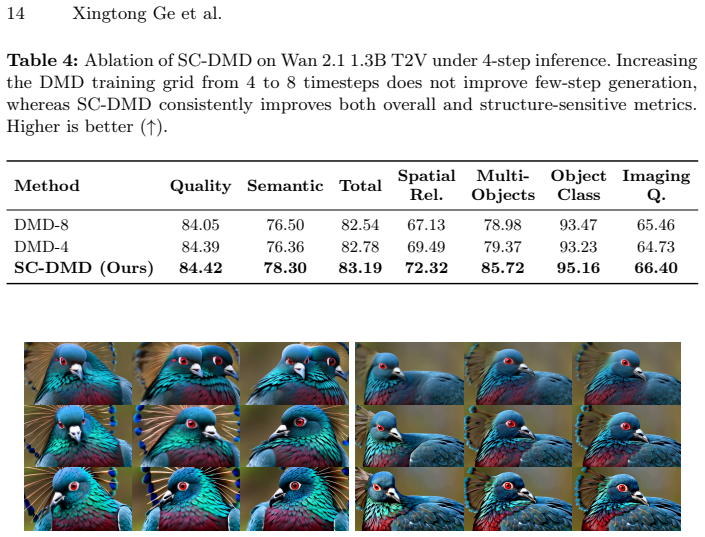
Self-Consistent Distribution Matching Distillation (SC-DMD) explicitly regularizes the endpoint-consistent composition of consecutive denoising updates so that multi-step rollouts avoid drift, while Cache-Distribution-Aware training treats the KV cache as a quality-parameterized condition and adds cache-conditioned feature alignment to steer low-quality autoregressive outputs toward high-quality references, yielding higher-quality video at 2-4 NFEs across tested non-autoregressive and autoregressive architectures.
What carries the argument
Self-Consistent Distribution Matching Distillation (SC-DMD) that enforces endpoint consistency across consecutive denoising updates, together with cache-conditioned feature alignment that uses the KV cache as a conditioning variable.
If this is right
- Low-NFE video quality improves on non-autoregressive backbones such as Wan 2.1.
- Autoregressive real-time models such as Self Forcing gain quality while remaining compatible with existing KV-cache mechanisms.
- Sharp, mode-seeking samples are recovered without the conservative smoothing typical of trajectory consistency distillation.
- The method adds no extra inference cost or memory overhead beyond the original backbone.
Where Pith is reading between the lines
- The same endpoint-consistency idea could be tested on image or audio generation tasks that also rely on multi-step sampling.
- Cache-aware alignment might extend naturally to streaming or online generation where the cache state evolves over time.
- Combining the regularization with other acceleration methods such as step-size scheduling could be checked for additive gains.
Load-bearing premise
That enforcing endpoint consistency on composed denoising updates will prevent drift in full rollouts and that cache-conditioned feature alignment will reliably improve quality without creating new inconsistencies.
What would settle it
Quantitative comparison of motion consistency and perceptual sharpness metrics on identical prompts at 2-4 NFEs between Salt and baseline distribution matching distillation, checking whether trajectory drift or over-smoothing visibly decreases.
Figures





read the original abstract
Distilling video generation models to extremely low inference budgets (e.g., 2--4 NFEs) is crucial for real-time deployment, yet remains challenging. Trajectory-style consistency distillation often becomes conservative under complex video dynamics, yielding an over-smoothed appearance and weak motion. Distribution matching distillation (DMD) can recover sharp, mode-seeking samples, but its local training signals do not explicitly regularize how denoising updates compose across timesteps, making composed rollouts prone to drift. To overcome this challenge, we propose Self-Consistent Distribution Matching Distillation (SC-DMD), which explicitly regularizes the endpoint-consistent composition of consecutive denoising updates. For real-time autoregressive video generation, we further treat the KV cache as a quality parameterized condition and propose Cache-Distribution-Aware training. This training scheme applies SC-DMD over multi-step rollouts and introduces a cache-conditioned feature alignment objective that steers low-quality outputs toward high-quality references. Across extensive experiments on both non-autoregressive backbones (e.g., Wan~2.1) and autoregressive real-time paradigms (e.g., Self Forcing), our method, dubbed \textbf{Salt}, consistently improves low-NFE video generation quality while remaining compatible with diverse KV-cache memory mechanisms. Source code will be released at \href{https://github.com/XingtongGe/Salt}{https://github.com/XingtongGe/Salt}.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Salt for distilling video generation models to low NFEs (2-4). It proposes Self-Consistent Distribution Matching Distillation (SC-DMD) that adds explicit regularization on the endpoint-consistent composition of consecutive denoising updates to reduce drift in composed rollouts, and Cache-Distribution-Aware training that treats the KV cache as a quality-conditioned input, applies SC-DMD over multi-step autoregressive rollouts, and adds a cache-conditioned feature alignment loss to steer outputs toward high-quality references. Experiments on non-autoregressive backbones (e.g., Wan 2.1) and autoregressive paradigms (e.g., Self Forcing) report consistent quality gains at low NFEs while remaining compatible with diverse KV-cache mechanisms.
Significance. If the added regularization demonstrably closes the composition gap for high-dimensional video dynamics and the cache alignment improves quality without new inconsistencies, the work would meaningfully extend distribution-matching distillation to practical real-time video generation. The compatibility with both non-autoregressive and autoregressive KV-cache setups, plus the promise of open-sourced code, would strengthen its utility for deployment.
major comments (2)
- [§3.1] §3.1 (SC-DMD formulation): the central claim that explicit endpoint-consistent regularization prevents drift in low-NFE rollouts is load-bearing, yet the manuscript provides no derivation showing that the added term closes the composition gap beyond the local signals already present in standard DMD; without this or an ablation isolating the regularization's effect on accumulated error over timesteps, the improvement over baseline DMD remains unverified for complex motions.
- [§4.3] §4.3 (Cache-Distribution-Aware training): the cache-conditioned feature alignment is asserted to steer low-quality outputs toward references without introducing new inconsistencies, but the reported experiments contain no direct metric (e.g., temporal consistency or endpoint mismatch) quantifying whether the alignment term creates fresh drift or artifacts in autoregressive rollouts, which is required to support the claim for real-time paradigms.
minor comments (2)
- [Abstract] The abstract and §1 could more precisely state the exact quantitative metrics (e.g., FVD, CLIP score) and NFE settings used to claim 'consistent improvements'.
- [§3.2] Notation for the KV-cache conditioning in Eq. (X) is introduced without an explicit diagram showing how the cache state is injected into the feature alignment loss.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments. We address each major comment below and have revised the manuscript accordingly to strengthen the presentation and empirical support.
read point-by-point responses
-
Referee: [§3.1] §3.1 (SC-DMD formulation): the central claim that explicit endpoint-consistent regularization prevents drift in low-NFE rollouts is load-bearing, yet the manuscript provides no derivation showing that the added term closes the composition gap beyond the local signals already present in standard DMD; without this or an ablation isolating the regularization's effect on accumulated error over timesteps, the improvement over baseline DMD remains unverified for complex motions.
Authors: We appreciate this observation. In the revised manuscript we have added an explicit derivation in Section 3.1 (and expanded in Appendix A) showing that the endpoint-consistent regularization term penalizes discrepancies between the composed multi-step trajectory and the direct endpoint mapping, thereby addressing the composition gap that is invisible to the per-step local signals of standard DMD. We have also inserted a targeted ablation in Section 4.2 that isolates the regularization's contribution by measuring accumulated temporal error over long rollouts on complex motion sequences, confirming a measurable reduction in drift relative to baseline DMD. revision: yes
-
Referee: [§4.3] §4.3 (Cache-Distribution-Aware training): the cache-conditioned feature alignment is asserted to steer low-quality outputs toward references without introducing new inconsistencies, but the reported experiments contain no direct metric (e.g., temporal consistency or endpoint mismatch) quantifying whether the alignment term creates fresh drift or artifacts in autoregressive rollouts, which is required to support the claim for real-time paradigms.
Authors: We agree that direct quantification is necessary. In the revised Section 4.3 we now report temporal consistency (optical-flow-based frame-to-frame coherence) and endpoint mismatch metrics on autoregressive rollouts. These measurements show that the cache-conditioned feature alignment improves fidelity to high-quality references while keeping both consistency and endpoint error at or below the levels observed with the unaligned baseline, supporting the claim that no new drift is introduced. revision: yes
Circularity Check
No circularity: new regularization terms and training scheme introduced independently
full rationale
The paper proposes SC-DMD as an explicit regularization of endpoint-consistent composition of denoising updates on top of standard DMD, plus a cache-conditioned feature alignment objective for autoregressive rollouts. These are framed as novel additions to address drift in low-NFE video generation, without any equations or claims reducing to self-citations, fitted parameters renamed as predictions, or ansatzes smuggled from prior author work. The derivation chain builds on established distribution matching principles with independent methodological content that does not collapse by construction to its inputs. No load-bearing steps exhibit self-definitional loops or uniqueness imported from overlapping citations.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Distribution matching distillation recovers sharp mode-seeking samples from teacher models
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearSC-DMD augments DMD with shortcut self-consistency regularizer L_SC = E[d(x(1)_te, x(2)_te)] where x(1)_te = Ψ_ts→te_θ(xts) and x(2)_te is the two-step composition, enforcing semigroup defect on the student Euler operator.
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanalpha_pin_under_high_calibration unclearCache-conditioned feature alignment L_align on relational matrices R_low and R_ref for mixed K∈{2,4,8} rollouts.
Reference graph
Works this paper leans on
-
[1]
Boffi, N.M., Albergo, M.S., Vanden-Eijnden, E.: Flow map matching with stochas- tic interpolants: A mathematical framework for consistency models. arXiv preprint arXiv:2406.07507 (2024) 5
-
[2]
In: The Thirty-ninth Annual Conference on Neural Information Processing Systems 5
Boffi, N.M., Albergo, M.S., Vanden-Eijnden, E.: How to build a consistency model: Learning flow maps via self-distillation. In: The Thirty-ninth Annual Conference on Neural Information Processing Systems 5
-
[3]
arXiv preprint arXiv:2510.17858 (2025) 1
Cai, X., Wu, Y., Chen, Q., Wu, H., Xiang, L., Wen, H.: Shortcutting pre- trained flow matching diffusion models is almost free lunch. arXiv preprint arXiv:2510.17858 (2025) 1
-
[4]
SkyReels-V2: Infinite-length Film Generative Model
Chen, G., Lin, D., Yang, J., Lin, C., Zhu, J., Fan, M., Zhang, H., Chen, S., Chen, Z., Ma, C., et al.: Skyreels-v2: Infinite-length film generative model. arXiv preprint arXiv:2504.13074 (2025) 4 16 Xingtong Ge et al
work page internal anchor Pith review arXiv 2025
-
[5]
arXiv preprint arXiv:2508.21019 (2025) 2, 3, 4
Cheng, J., Ma, B., Ren, X., Jin, H.H., Yu, K., Zhang, P., Li, W., Zhou, Y., Zheng, T., Lu, Q.: Phased one-step adversarial equilibrium for video diffusion models. arXiv preprint arXiv:2508.21019 (2025) 2, 3, 4
-
[6]
Contributors, L.: Lightx2v: Light video generation inference framework.https: //github.com/ModelTC/lightx2v(2025) 2, 3, 10, 11
work page 2025
-
[7]
One step diffusion via shortcut models.arXiv preprint arXiv:2410.12557, 2024
Frans,K.,Hafner,D.,Levine,S.,Abbeel,P.:Onestepdiffusionviashortcutmodels. arXiv preprint arXiv:2410.12557 (2024) 1, 7
-
[8]
arXiv preprint arXiv:2506.00523 (2025) 3
Ge, X., Zhang, X., Xu, T., Zhang, Y., Zhang, X., Wang, Y., Zhang, J.: Sense- flow: Scaling distribution matching for flow-based text-to-image distillation. arXiv preprint arXiv:2506.00523 (2025) 3
-
[9]
Mean Flows for One-step Generative Modeling
Geng,Z.,Deng,M.,Bai,X.,Kolter,J.Z.,He,K.:Meanflowsforone-stepgenerative modeling. arXiv preprint arXiv:2505.13447 (2025) 1
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Hastie, T., Tibshirani, R., Friedman, J.H., Friedman, J.H.: The elements of sta- tistical learning: data mining, inference, and prediction, vol. 2. Springer (2009) 2
work page 2009
-
[11]
arXiv preprint arXiv:2511.16955 (2025) 3
He, D., Feng, G., Ge, X., Niu, Y., Zhang, Y., Ma, B., Song, G., Liu, Y., Li, H.: Neighbor grpo: Contrastive ode policy optimization aligns flow models. arXiv preprint arXiv:2511.16955 (2025) 3
-
[12]
Advances in neural information processing systems33, 6840–6851 (2020) 1
Ho, J., Jain, A., Abbeel, P.: Denoising diffusion probabilistic models. Advances in neural information processing systems33, 6840–6851 (2020) 1
work page 2020
-
[13]
Self Forcing: Bridging the Train-Test Gap in Autoregressive Video Diffusion
Huang, X., Li, Z., He, G., Zhou, M., Shechtman, E.: Self forcing: Bridging the train-test gap in autoregressive video diffusion. arXiv preprint arXiv:2506.08009 (2025) 2, 3, 4, 5, 10, 11, 12, 21, 22
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
Linvideo: A post-training framework towards o (n) attention in efficient video generation,
Huang, Y., Ge, X., Gong, R., Lv, C., Zhang, J.: Linvideo: A post-training framework towards o (n) attention in efficient video generation. arXiv preprint arXiv:2510.08318 (2025) 2
- [15]
- [16]
-
[17]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2024) 10
Huang, Z., He, Y., Yu, J., Zhang, F., Si, C., Jiang, Y., Zhang, Y., Wu, T., Jin, Q., Chanpaisit, N., Wang, Y., Chen, X., Wang, L., Lin, D., Qiao, Y., Liu, Z.: VBench: Comprehensive benchmark suite for video generative models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2024) 10
work page 2024
-
[18]
IEEE Transactions on Pattern Analysis and Machine Intelligence (2025)
Huang, Z., Zhang, F., Xu, X., He, Y., Yu, J., Dong, Z., Ma, Q., Chanpaisit, N., Si, C., Jiang, Y., Wang, Y., Chen, X., Chen, Y.C., Wang, L., Lin, D., Qiao, Y., Liu, Z.: VBench++: Comprehensive and versatile benchmark suite for video generative models. IEEE Transactions on Pattern Analysis and Machine Intelligence (2025). https://doi.org/10.1109/TPAMI.2025...
-
[19]
In: Kim, B., Yue, Y., Chaudhuri, S., Fragkiadaki, K., Khan, M., Sun, Y
Kim, D., Lai, C.H., Liao, W., Murata, N., Takida, Y., Uesaka, T., He, Y., Mit- sufuji, Y., Ermon, S.: Consistency trajectory models: Learning probability flow ode trajectory of diffusion. In: Kim, B., Yue, Y., Chaudhuri, S., Fragkiadaki, K., Khan, M., Sun, Y. (eds.) International Conference on Learning Representations. vol. 2024, pp. 44493–44525 (2024),ht...
work page 2024
-
[20]
arXiv preprint arXiv:2501.08316 (2025) 2, 3, 4
Lin, S., Xia, X., Ren, Y., Yang, C., Xiao, X., Jiang, L.: Diffusion adversarial post- training for one-step video generation. arXiv preprint arXiv:2501.08316 (2025) 2, 3, 4
-
[21]
arXiv preprint arXiv:2506.09350 (2025) 2, 4
Lin, S., Yang, C., He, H., Jiang, J., Ren, Y., Xia, X., Zhao, Y., Xiao, X., Jiang, L.: Autoregressive adversarial post-training for real-time interactive video generation. arXiv preprint arXiv:2506.09350 (2025) 2, 4
- [22]
-
[23]
arXiv preprint arXiv:2509.25161 (2025) 4
Liu, K., Hu, W., Xu, J., Shan, Y., Lu, S.: Rolling forcing: Autoregressive long video diffusion in real time. arXiv preprint arXiv:2509.25161 (2025) 4
-
[24]
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
Liu, X., Gong, C., Liu, Q.: Flow straight and fast: Learning to generate and transfer data with rectified flow. arXiv preprint arXiv:2209.03003 (2022) 1
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[25]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Liu, Y., Liu, B., Zhang, Y., Hou, X., Song, G., Liu, Y., You, H.: See further when clear: Curriculum consistency model. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 18103–18112 (2025) 3
work page 2025
-
[26]
Lu, Y., Zeng, Y., Li, H., Ouyang, H., Wang, Q., Cheng, K.L., Zhu, J., Cao, H., Zhang, Z., Zhu, X., et al.: Reward forcing: Efficient streaming video generation with rewarded distribution matching distillation. arXiv preprint arXiv:2512.04678 (2025) 3, 4
-
[27]
Latent Consistency Models: Synthesizing High-Resolution Images with Few-Step Inference
Luo, S., Tan, Y., Huang, L., Li, J., Zhao, H.: Latent consistency mod- els: Synthesizing high-resolution images with few-step inference. arXiv preprint arXiv:2310.04378 (2023) 1, 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[28]
Lv, Z., Si, C., Pan, T., Chen, Z., Wong, K.Y.K., Qiao, Y., Liu, Z.: Dual-expert consistencymodelforefficientandhigh-qualityvideogeneration.In:Proceedingsof the IEEE/CVF International Conference on Computer Vision (ICCV). pp. 14983– 14993 (October 2025) 3
work page 2025
-
[29]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Mao, X., Jiang, Z., Wang, F.Y., Zhang, J., Chen, H., Chi, M., Wang, Y., Luo, W.: Osv: One step is enough for high-quality image to video generation. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 12585–12594 (2025) 2
work page 2025
-
[30]
Transition matching distillation for fast video generation.arXiv preprint arXiv:2601.09881, 2026
Nie, W., Berner, J., Ma, N., Liu, C., Xie, S., Vahdat, A.: Transition matching distillation for fast video generation. arXiv preprint arXiv:2601.09881 (2026) 2, 3, 21
-
[31]
arXiv preprint arXiv:2404.13686 (2024) 3
Ren, Y., Xia, X., Lu, Y., Zhang, J., Wu, J., Xie, P., Wang, X., Xiao, X.: Hyper- sd: Trajectory segmented consistency model for efficient image synthesis. arXiv preprint arXiv:2404.13686 (2024) 3
-
[32]
In: The Thirty-ninth Annual Conference on Neural Information Processing Systems 2, 3, 5, 6, 7
Sabour, A., Fidler, S., Kreis, K.: Align your flow: Scaling continuous-time flow map distillation. In: The Thirty-ninth Annual Conference on Neural Information Processing Systems 2, 3, 5, 6, 7
-
[33]
In: Interna- tional Conference on Machine Learning
Song, Y., Dhariwal, P., Chen, M., Sutskever, I.: Consistency models. In: Interna- tional Conference on Machine Learning. pp. 32211–32252. PMLR (2023) 1, 3, 5, 6
work page 2023
-
[34]
MAGI-1: Autoregressive Video Generation at Scale
Teng, H., Jia, H., Sun, L., Li, L., Li, M., Tang, M., Han, S., Zhang, T., Zhang, W., Luo, W., et al.: Magi-1: Autoregressive video generation at scale. arXiv preprint arXiv:2505.13211 (2025) 4
work page internal anchor Pith review arXiv 2025
-
[35]
Wan: Open and Advanced Large-Scale Video Generative Models
Wan, T., Wang, A., Ai, B., Wen, B., Mao, C., Xie, C.W., Chen, D., Yu, F., Zhao, H., Yang, J., et al.: Wan: Open and advanced large-scale video generative models. arXiv preprint arXiv:2503.20314 (2025) 1, 2, 6, 10, 20
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
Wang, F.Y., Huang, Z., Bergman, A., Shen, D., Gao, P., Lingelbach, M., Sun, K., Bian, W., Song, G., Liu, Y., et al.: Phased consistency models. Advances in neural information processing systems37, 83951–84009 (2024) 3, 10, 11 18 Xingtong Ge et al
work page 2024
-
[37]
arXiv preprint arXiv:2512.06802 (2025) 3
Wang, Y., Zhang, H., Xue, T., Qiao, Y., Wang, Y., Xu, C., Chen, X.: Vdot: Efficient unified video creation via optimal transport distillation. arXiv preprint arXiv:2512.06802 (2025) 3
-
[38]
Advances in Neural Information Processing Systems36, 8406–8441 (2023) 2
Wang, Z., Lu, C., Wang, Y., Bao, F., Li, C., Su, H., Zhu, J.: Prolificdreamer: High-fidelity and diverse text-to-3d generation with variational score distillation. Advances in Neural Information Processing Systems36, 8406–8441 (2023) 2
work page 2023
-
[39]
Longlive: Real-time interactive long video generation.arXiv preprint arXiv:2509.22622, 2025
Yang, S., Huang, W., Chu, R., Xiao, Y., Zhao, Y., Wang, X., Li, M., Xie, E., Chen, Y., Lu, Y., et al.: Longlive: Real-time interactive long video generation. arXiv preprint arXiv:2509.22622 (2025) 2, 3, 4, 10, 11, 12, 13, 21, 22
-
[40]
Yesiltepe, H., Meral, T.H.S., Akan, A.K., Oktay, K., Yanardag, P.: Infinity-rope: Action-controllable infinite video generation emerges from autoregressive self- rollout. arXiv preprint arXiv:2511.20649 (2025) 4
-
[41]
Advances in neural information processing systems37, 47455–47487 (2024) 2, 3, 5
Yin, T., Gharbi, M., Park, T., Zhang, R., Shechtman, E., Durand, F., Freeman, B.: Improved distribution matching distillation for fast image synthesis. Advances in neural information processing systems37, 47455–47487 (2024) 2, 3, 5
work page 2024
-
[42]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Yin, T., Gharbi, M., Zhang, R., Shechtman, E., Durand, F., Freeman, W.T., Park, T.: One-step diffusion with distribution matching distillation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 6613– 6623 (2024) 2, 3, 4, 10, 11, 12, 21
work page 2024
-
[43]
In: Pro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion
Yin, T., Zhang, Q., Zhang, R., Freeman, W.T., Durand, F., Shechtman, E., Huang, X.: From slow bidirectional to fast autoregressive video diffusion models. In: Pro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion. pp. 22963–22974 (2025) 2, 3, 4, 5, 12, 21, 22
work page 2025
-
[44]
Advances in Neural Information Processing Systems37, 111000–111021 (2024) 2
Zhai, Y., Lin, K., Yang, Z., Li, L., Wang, J., Lin, C.C., Doermann, D., Yuan, J., Wang, L.: Motion consistency model: Accelerating video diffusion with disentan- gled motion-appearance distillation. Advances in Neural Information Processing Systems37, 111000–111021 (2024) 2
work page 2024
-
[45]
arXiv preprint arXiv:2511.20123 (2025) 4
Zhao, M., Zhu, H., Wang, Y., Yan, B., Zhang, J., He, G., Yang, L., Li, C., Zhu, J.: Ultravico: Breaking extrapolation limits in video diffusion transformers. arXiv preprint arXiv:2511.20123 (2025) 4
-
[46]
Large Scale Diffusion Distillation via Score-Regularized Continuous-Time Consistency
Zheng, K., Wang, Y., Ma, Q., Chen, H., Zhang, J., Balaji, Y., Chen, J., Liu, M.Y., Zhu, J., Zhang, Q.: Large scale diffusion distillation via score-regularized continuous-time consistency. arXiv preprint arXiv:2510.08431 (2025) 3, 10, 12, 20, 21
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[47]
Zhu, H., Zhao, M., He, G., Su, H., Li, C., Zhu, J.: Causal forcing: Autoregressive diffusion distillation done right for high-quality real-time interactive video genera- tion. arXiv preprint arXiv:2602.02214 (2026) 2, 4, 10, 11, 12, 13, 21, 22, 23 Salt 19 A More results about SC-DMD A.1 Measuring Semigroup Defect on the Test-Time Inference Path A key moti...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.