G3T Up! Gravity Aligned Coordinate Frames Simplify Pointmap Processing
Pith reviewed 2026-06-29 18:27 UTC · model grok-4.3
The pith
Predicting pointmaps in gravity-aligned frames rather than camera-centric ones improves 3D reconstruction by sharing a common vertical axis across views.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
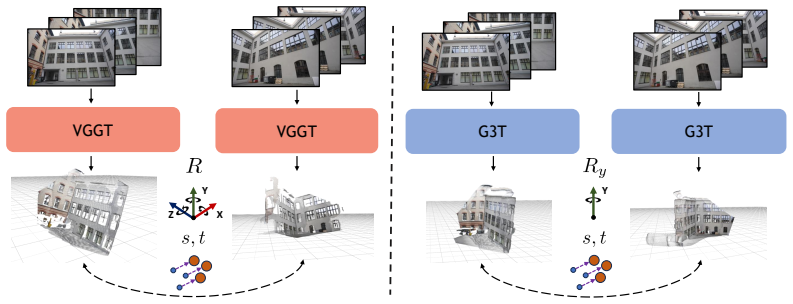
Gravity-aligned frames let pointmaps share a common vertical axis across viewpoints, which reduces the rotational degrees of freedom needed to relate them; the resulting G3T model produces accurate upright pointmaps and camera-to-gravity poses, and the G3T-Long submap pipeline that operates on these predictions delivers significantly higher reconstruction accuracy than camera-centric baselines.
What carries the argument
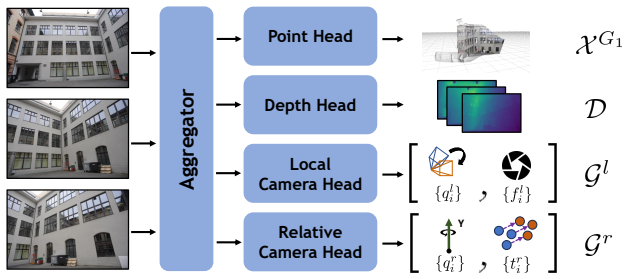
Gravity Grounded Geometry Transformer (G3T), a model fine-tuned to predict pointmaps and poses directly in gravity-aligned frames.
If this is right
- Upright pointmaps share one vertical axis across all views, so only two rotational degrees of freedom remain when aligning them.
- G3T produces both the upright pointmaps and the camera-to-gravity pose estimates needed for incremental reconstruction.
- G3T-Long, the submap-based pipeline, converts the reduced rotational freedom into measurably higher final accuracy.
- The same gravity-aligned output format works for any base model that can be fine-tuned on aligned 3D data.
Where Pith is reading between the lines
- Coordinate-frame choice becomes a first-class design decision for future feed-forward 3D models, comparable to network architecture.
- The method could be combined with IMU or accelerometer data to supply the gravity direction when visual cues are weak.
- Scenes with strong but varying gravity (tilted buildings, sloped terrain) may require an adaptive gravity vector per submap rather than a single global direction.
Load-bearing premise
Many real-world scenes contain strong structural cues with a consistent gravity direction that can be exploited by predicting pointmaps in gravity-aligned frames.
What would settle it
Reconstruction accuracy on a test set of scenes lacking consistent gravity direction (for example, underwater footage or microgravity environments) shows no gain or a drop relative to camera-centric baselines.
Figures






read the original abstract
Modern feed-forward 3D reconstruction methods like VGGT predict pixel-aligned pointmaps in camera-centric coordinate frames. However, this choice of coordinate frame is not always optimal. We propose instead to predict pointmaps in upright, gravity-aligned frames that exploit strong structural cues present in many real-world scenes. Unlike camera-centric frames, gravity-aligned frames share a common vertical axis across viewpoints, reducing the rotational degrees of freedom needed to relate pointmaps to one another. To this end, we introduce the Gravity Grounded Geometry Transformer (G3T), fine-tuned from existing models on gravity-aligned 3D data. G3T produces highly accurate gravity-aware predictions, including upright pointmaps and camera-to-gravity poses. We further introduce G3T-Long, a submap-based incremental 3D reconstruction pipeline that leverages the reduced rotational degrees of freedom afforded by upright frames to achieve significantly improved reconstruction accuracy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes predicting pixel-aligned pointmaps in upright gravity-aligned coordinate frames rather than camera-centric frames (as in VGGT) to exploit consistent vertical axes across views and thereby reduce rotational degrees of freedom in multi-view alignment. It introduces the Gravity Grounded Geometry Transformer (G3T), obtained by fine-tuning existing models on gravity-aligned 3D data, which outputs upright pointmaps together with camera-to-gravity poses, and presents G3T-Long, a submap-based incremental reconstruction pipeline that is claimed to deliver significantly improved accuracy by leveraging the reduced rotational freedom.
Significance. If the claimed accuracy gains are demonstrated, the modeling choice of gravity-aligned frames would constitute a simple, parameter-free structural prior that could improve robustness of feed-forward pointmap methods on man-made and outdoor scenes without altering network architecture or training objectives.
major comments (1)
- [Abstract] Abstract: the claim that G3T-Long 'achieves significantly improved reconstruction accuracy' is load-bearing for the central contribution yet is unsupported by any quantitative results, baselines, error metrics, or experimental protocol; without such evidence the magnitude and reliability of the improvement cannot be evaluated.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The single major comment concerns the abstract's claim of significantly improved accuracy for G3T-Long. We address it directly below and agree that the abstract should better reflect the supporting evidence present in the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that G3T-Long 'achieves significantly improved reconstruction accuracy' is load-bearing for the central contribution yet is unsupported by any quantitative results, baselines, error metrics, or experimental protocol; without such evidence the magnitude and reliability of the improvement cannot be evaluated.
Authors: We agree that the abstract, as currently worded, makes a strong claim without embedding the supporting numbers or protocol. The full manuscript (Sections 4 and 5) reports quantitative comparisons on standard benchmarks, including absolute trajectory error and pointmap accuracy metrics against VGGT and other baselines, with the gravity-aligned formulation yielding consistent reductions in rotational error. To make the abstract self-contained and address the concern, we will revise it to include the key quantitative improvements and a brief reference to the evaluation protocol. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper introduces a modeling choice to predict pointmaps in gravity-aligned upright frames rather than camera-centric ones, justified by the presence of consistent gravity directions in real-world scenes. This choice directly reduces rotational degrees of freedom between views by construction of the coordinate system, but the paper does not derive this as a 'prediction' from fitted parameters or reduce any central claim to self-citation. No equations, uniqueness theorems, or ansatzes are smuggled via self-citation; the pipeline (fine-tuning on gravity-aligned data, predicting camera-to-gravity poses, and incremental reconstruction) is presented as a coherent new approach without load-bearing reductions to inputs. The abstract and described method are self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Real-world scenes often exhibit a consistent vertical direction due to gravity that can be exploited across viewpoints
Reference graph
Works this paper leans on
-
[1]
Neural rgb-d surface reconstruction
Dejan Azinovi´c, Ricardo Martin-Brualla, Dan B Goldman, Matthias Nießner, and Justus Thies. Neural rgb-d surface reconstruction. InCVPR, pages 6290–6301, June 2022
2022
-
[2]
ARKitscenes - a diverse real-world dataset for 3d indoor scene understanding using mobile RGB-d data
Gilad Baruch, Zhuoyuan Chen, Afshin Dehghan, Tal Dimry, Yuri Feigin, Peter Fu, Thomas Gebauer, Brandon Joffe, Daniel Kurz, Arik Schwartz, and Elad Shulman. ARKitscenes - a diverse real-world dataset for 3d indoor scene understanding using mobile RGB-d data. In NeurIPS Datasets and Benchmarks, 2021
2021
-
[3]
Deep regression on manifolds: a 3D rotation case study
Romain Brégier. Deep regression on manifolds: a 3D rotation case study. In2021 International Conference on 3D Vision (3DV), 2021
2021
-
[4]
Can generative video models help pose estimation? InCVPR, 2025
Ruojin Cai, Jason Y Zhang, Philipp Henzler, Zhengqi Li, Noah Snavely, and Ricardo Martin- Brualla. Can generative video models help pose estimation? InCVPR, 2025
2025
-
[5]
Using vanishing points for camera calibration
Bruno Caprile and Vincent Torre. Using vanishing points for camera calibration. InIJCV, 1990
1990
-
[6]
Easi3r: Estimating disentangled motion from dust3r without training
Xingyu Chen, Yue Chen, Yuliang Xiu, Andreas Geiger, and Anpei Chen. Easi3r: Estimating disentangled motion from dust3r without training. InICCV, 2025
2025
-
[7]
Ttt3r: 3d reconstruc- tion as test-time training.ICLR, 2026
Xingyu Chen, Yue Chen, Yuliang Xiu, Andreas Geiger, and Anpei Chen. Ttt3r: 3d reconstruc- tion as test-time training.ICLR, 2026
2026
-
[8]
Kai Deng, Zexin Ti, Jiawei Xu, Jian Yang, and Jin Xie. Vggt-long: Chunk it, loop it, align it – pushing vggt’s limits on kilometer-scale long rgb sequences.arXiv preprint arXiv:2507.16443, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Black, Trevor Darrell, and Angjoo Kanazawa
Haiwen Feng*, Junyi Zhang*, Qianqian Wang, Yufei Ye, Pengcheng Yu, Michael J. Black, Trevor Darrell, and Angjoo Kanazawa. St4rtrack: Simultaneous 4d reconstruction and tracking in the world. InICCV, 2025
2025
-
[10]
Seitz, and Richard Szeliski
Yasutaka Furukawa, Brian Curless, Steven M. Seitz, and Richard Szeliski. Manhattan-world stereo. InCVPR, 2009
2009
-
[11]
Barron, Noah Snavely, and Aleksander Holynski
Haian Jin, Rundi Wu, Tianyuan Zhang, Ruiqi Gao, Jonathan T. Barron, Noah Snavely, and Aleksander Holynski. ZipMap: Linear-time stateful 3d reconstruction via test-time training. In CVPR, 2026
2026
-
[12]
Stereo4d: Learning how things move in 3d from internet stereo videos
Linyi Jin, Richard Tucker, Zhengqi Li, David Fouhey, Noah Snavely, and Aleksander Holynski. Stereo4d: Learning how things move in 3d from internet stereo videos. InCVPR, 2025
2025
-
[13]
Linyi Jin, Jianming Zhang, Yannick Hold-Geoffroy, Oliver Wang, Kevin Matzen, Matthew Sticha, and David F. Fouhey. Perspective fields for single image camera calibration. InCVPR, 2023. 10
2023
-
[14]
MapAnything: Universal feed-forward metric 3D reconstruc- tion
Nikhil Keetha, Norman Müller, Johannes Schönberger, Lorenzo Porzi, Yuchen Zhang, To- bias Fischer, Arno Knapitsch, Duncan Zauss, Ethan Weber, Nelson Antunes, Jonathon Luiten, Manuel Lopez-Antequera, Samuel Rota Bulò, Christian Richardt, Deva Ramanan, Sebastian Scherer, and Peter Kontschieder. MapAnything: Universal feed-forward metric 3D reconstruc- tion....
2026
-
[15]
gradslam: Dense slam meets automatic differentiation
Jatavallabhula Krishna Murthy, Soroush Saryazdi, Ganesh Iyer, and Liam Paull. gradslam: Dense slam meets automatic differentiation. InIEEE International Conference on Robotics & Automation (ICRA), 2020
2020
-
[16]
Closed-form solutions to minimal absolute pose problems with known vertical direction
Zuzana Kukelova, Martin Bujnak, and Tomas Pajdla. Closed-form solutions to minimal absolute pose problems with known vertical direction. InACCV, 2010
2010
-
[17]
Canonical surface mapping via geometric cycle consistency
Nilesh Kulkarni, Abhinav Gupta, and Shubham Tulsiani. Canonical surface mapping via geometric cycle consistency. InICCV, 2019
2019
-
[18]
Automatic upright adjustment of photographs with robust camera calibration
Hyunjoon Lee, Eli Shechtman, Jue Wang, and Seungyong Lee. Automatic upright adjustment of photographs with robust camera calibration. InIEEE TPAMI, 2014
2014
-
[19]
Grounding image matching in 3d with mast3r
Vincent Leroy, Yohann Cabon, and Jérôme Revaud. Grounding image matching in 3d with mast3r. InECCV, 2024
2024
-
[20]
Megadepth: Learning single-view depth prediction from internet photos
Zhengqi Li and Noah Snavely. Megadepth: Learning single-view depth prediction from internet photos. InCVPR, 2018
2018
-
[21]
Depth Anything 3: Recovering the Visual Space from Any Views
Haotong Lin, Sili Chen, Jun Hao Liew, Donny Y . Chen, Zhenyu Li, Guang Shi, Jiashi Feng, and Bingyi Kang. Depth anything 3: recovering the visual space from any views.arXiv preprint arXiv:2511.10647, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
Dl3dv-10k: A large-scale scene dataset for deep learning-based 3d vision
Lu Ling, Yichen Sheng, Zhi Tu, Wentian Zhao, Cheng Xin, Kun Wan, Lantao Yu, Qianyu Guo, Zixun Yu, Yawen Lu, et al. Dl3dv-10k: A large-scale scene dataset for deep learning-based 3d vision. InCVPR, pages 22160–22169, 2024
2024
-
[23]
Vggt-slam: Dense rgb slam optimized on the sl (4) manifold
Dominic Maggio, Hyungtae Lim, and Luca Carlone. Vggt-slam: Dense rgb slam optimized on the sl (4) manifold. InNeurIPS, 2025
2025
-
[24]
Gravity-aligned rotation averaging with circular regression
Linfei Pan, Marc Pollefeys, and Dániel Baráth. Gravity-aligned rotation averaging with circular regression. InECCV, 2024
2024
-
[25]
Schönberger, and Marc Pollefeys
Zador Pataki, Paul-Edouard Sarlin, Johannes L. Schönberger, and Marc Pollefeys. MP-SfM: Monocular Surface Priors for Robust Structure-from-Motion. InCVPR, 2025
2025
-
[26]
Susskind
Mike Roberts, Jason Ramapuram, Anurag Ranjan, Atulit Kumar, Miguel Angel Bautista, Nathan Paczan, Russ Webb, and Joshua M. Susskind. Hypersim: A photorealistic synthetic dataset for holistic indoor scene understanding. InICCV, 2021
2021
-
[27]
Homography based egomotion estimation with a common direction
Olivier Saurer, Pascal Vasseur, Rémi Boutteau, Cédric Demonceaux, Marc Pollefeys, and Friedrich Fraundorfer. Homography based egomotion estimation with a common direction. IEEE TPAMI, 2017
2017
-
[28]
Structure-from-motion revisited
Johannes Lutz Schönberger and Jan-Michael Frahm. Structure-from-motion revisited. In Conference on Computer Vision and Pattern Recognition (CVPR), 2016
2016
-
[29]
Pixelwise view selection for unstructured multi-view stereo
Johannes Lutz Schönberger, Enliang Zheng, Marc Pollefeys, and Jan-Michael Frahm. Pixelwise view selection for unstructured multi-view stereo. InEuropean Conference on Computer Vision (ECCV), 2016
2016
-
[30]
Schönberger, Silvano Galliani, Torsten Sattler, Konrad Schindler, Marc Pollefeys, and Andreas Geiger
Thomas Schöps, Johannes L. Schönberger, Silvano Galliani, Torsten Sattler, Konrad Schindler, Marc Pollefeys, and Andreas Geiger. A multi-view stereo benchmark with high-resolution images and multi-camera videos. InCVPR, 2017
2017
-
[31]
World-grounded human motion recovery via gravity-view coordinates
Zehong Shen, Huaijin Pi, Yan Xia, Zhi Cen, Sida Peng, Zechen Hu, Hujun Bao, Ruizhen Hu, and Xiaowei Zhou. World-grounded human motion recovery via gravity-view coordinates. In SIGGRAPH Asia Conference Proceedings, 2024. 11
2024
-
[32]
Scene coordinate regression forests for camera relocalization in rgb-d images
Jamie Shotton, Ben Glocker, Christopher Zach, Shahram Izadi, Antonio Criminisi, and Andrew Fitzgibbon. Scene coordinate regression forests for camera relocalization in rgb-d images. In CVPR, June 2013
2013
-
[33]
Jefferey A. Shufelt. Performance evaluation and analysis of vanishing point detection techniques. IEEE TPAMI, 21(3):282–288, 1999
1999
-
[34]
Sturm, N
J. Sturm, N. Engelhard, F. Endres, W. Burgard, and D. Cremers. A benchmark for the evaluation of rgb-d slam systems. InProc. of the Int. Conf. on Intelligent Robot Systems (IROS), 2012
2012
-
[35]
Mv-dust3r+: Single-stage scene reconstruction from sparse views in 2 seconds
Zhenggang Tang, Yuchen Fan, Dilin Wang, Hongyu Xu, Rakesh Ranjan, Alexander Schwing, and Zhicheng Yan. Mv-dust3r+: Single-stage scene reconstruction from sparse views in 2 seconds. InCVPR, 2025
2025
-
[36]
Non-iterative approach for fast and accurate vanishing point detection
Jean-Philippe Tardif. Non-iterative approach for fast and accurate vanishing point detection. In ICCV, 2009
2009
-
[37]
Megascenes: Scene-level view synthesis at scale
Joseph Tung, Gene Chou, Ruojin Cai, Guandao Yang, Kai Zhang, Gordon Wetzstein, Bharath Hariharan, and Noah Snavely. Megascenes: Scene-level view synthesis at scale. InECCV, 2024
2024
-
[38]
S. Umeyama. Least-squares estimation of transformation parameters between two point patterns. IEEE TPAMI, 1991
1991
-
[39]
GeoCalib: Single-image Calibration with Geometric Optimization
Alexander Veicht, Paul-Edouard Sarlin, Philipp Lindenberger, and Marc Pollefeys. GeoCalib: Single-image Calibration with Geometric Optimization. InECCV, 2024
2024
-
[40]
PyPose: A library for robot learning with physics-based optimization
Chen Wang, Dasong Gao, Kuan Xu, Junyi Geng, Yaoyu Hu, Yuheng Qiu, Bowen Li, Fan Yang, Brady Moon, Abhinav Pandey, Aryan, Jiahe Xu, Tianhao Wu, Haonan He, Daning Huang, Zhongqiang Ren, Shibo Zhao, Taimeng Fu, Pranay Reddy, Xiao Lin, Wenshan Wang, Jingnan Shi, Rajat Talak, Kun Cao, Yi Du, Han Wang, Huai Yu, Shanzhao Wang, Siyu Chen, Ananth Kashyap, Rohan Ba...
2023
-
[41]
He Wang, Srinath Sridhar, Jingwei Huang, Julien Valentin, Shuran Song, and Leonidas J. Guibas. Normalized object coordinate space for category-level 6d object pose and size estimation. In CVPR, 2019
2019
-
[42]
3d reconstruction with spatial memory
Hengyi Wang and Lourdes Agapito. 3d reconstruction with spatial memory. InInternational Conference on 3D Vision (3DV), 2025
2025
-
[43]
Vggt: Visual geometry grounded transformer
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, and David Novotny. Vggt: Visual geometry grounded transformer. InCVPR, 2025
2025
-
[44]
Efros, and Angjoo Kanazawa
Qianqian Wang*, Yifei Zhang*, Aleksander Holynski, Alexei A. Efros, and Angjoo Kanazawa. Continuous 3d perception model with persistent state. InCVPR, 2025
2025
-
[45]
Dust3r: Geometric 3d vision made easy
Shuzhe Wang, Vincent Leroy, Yohann Cabon, Boris Chidlovskii, and Jerome Revaud. Dust3r: Geometric 3d vision made easy. InCVPR, 2024
2024
-
[46]
Tartanair: A dataset to push the limits of visual slam
Wenshan Wang, Delong Zhu, Xiangwei Wang, Yaoyu Hu, Yuheng Qiu, Chen Wang, Yafei Hu, Ashish Kapoor, and Sebastian Scherer. Tartanair: A dataset to push the limits of visual slam. In 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2020
2020
-
[47]
π3: Permutation-equivariant visual geometry learning.ICLR, 2026
Yifan Wang, Jianjun Zhou, Haoyi Zhu, Wenzheng Chang, Yang Zhou, Zizun Li, Junyi Chen, Jiangmiao Pang, Chunhua Shen, and Tong He. π3: Permutation-equivariant visual geometry learning.ICLR, 2026
2026
-
[48]
Changchang Wu, Sameer Agarwal, Brian Curless, and Steven M. Seitz. Schematic surface reconstruction. InCVPR, 2012
2012
-
[49]
Uprightnet: geometry-aware camera orientation estimation from single images
Wenqi Xian, Zhengqi Li, Matthew Fisher, Jonathan Eisenmann, Eli Shechtman, and Noah Snavely. Uprightnet: geometry-aware camera orientation estimation from single images. In ICCV, 2019. 12
2019
-
[50]
Liang, Mikael Henaff, Hao Tang, Ang Cao, Joyce Chai, Franziska Meier, and Matt Feiszli
Jianing Yang, Alexander Sax, Kevin J. Liang, Mikael Henaff, Hao Tang, Ang Cao, Joyce Chai, Franziska Meier, and Matt Feiszli. Fast3r: Towards 3d reconstruction of 1000+ images in one forward pass. InCVPR, 2025
2025
-
[51]
Monst3r: A simple approach for estimating geometry in the presence of motion.ICLR, 2025
Junyi Zhang, Charles Herrmann, Junhwa Hur, Varun Jampani, Trevor Darrell, Forrester Cole, Deqing Sun, and Ming-Hsuan Yang. Monst3r: A simple approach for estimating geometry in the presence of motion.ICLR, 2025
2025
-
[52]
LoGeR: Long-Context Geometric Reconstruction with Hybrid Memory
Junyi Zhang, Charles Herrmann, Junhwa Hur, Chen Sun, Ming-Hsuan Yang, Forrester Cole, Trevor Darrell, and Deqing Sun. Loger: Long-context geometric reconstruction with hybrid memory.arXiv preprint arXiv:2603.03269, 2026. 13 Supplementary Material A Additional qualitative results We have attached additional qualitative results in Figure 6. We can see that ...
work page internal anchor Pith review Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.