Automating Formal Verification with Agent-Guided Tree Search
Pith reviewed 2026-06-29 14:51 UTC · model grok-4.3
The pith
Context-based tree search lets LLMs solve more intermediate verification tasks at lower token cost than a plain agent loop.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
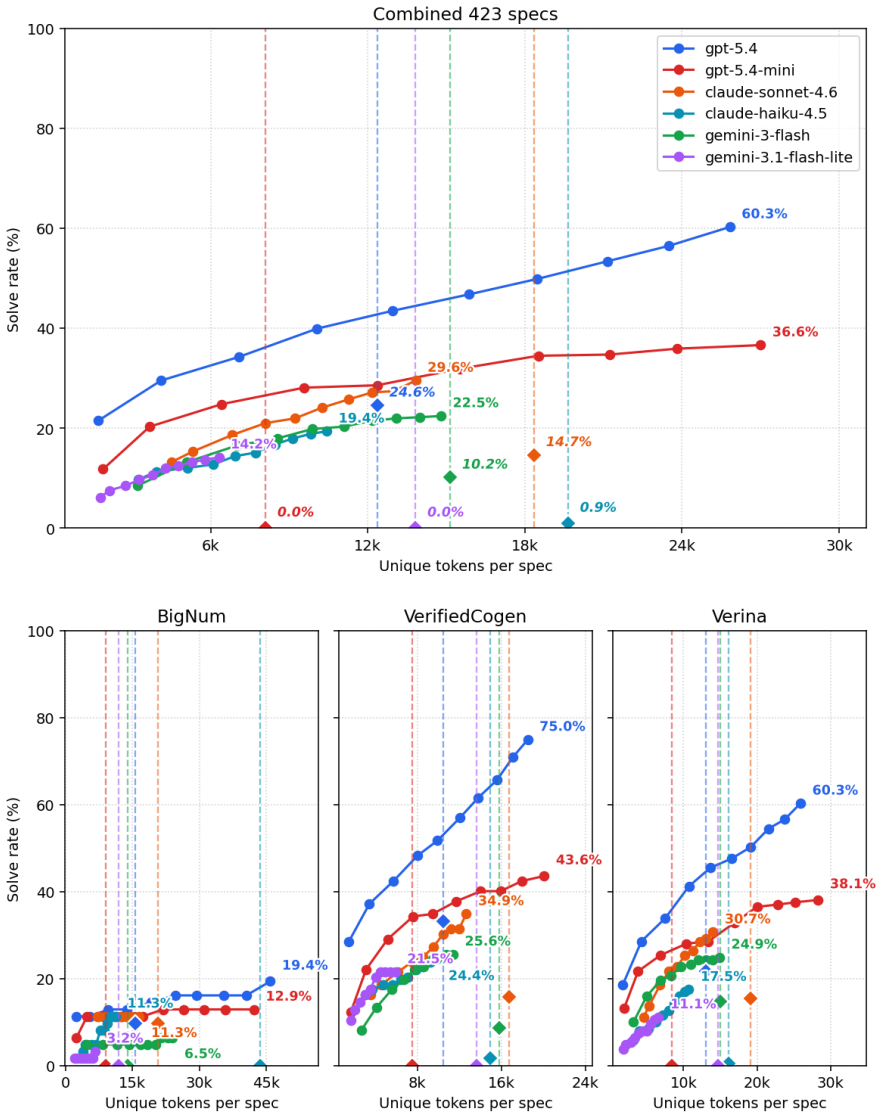
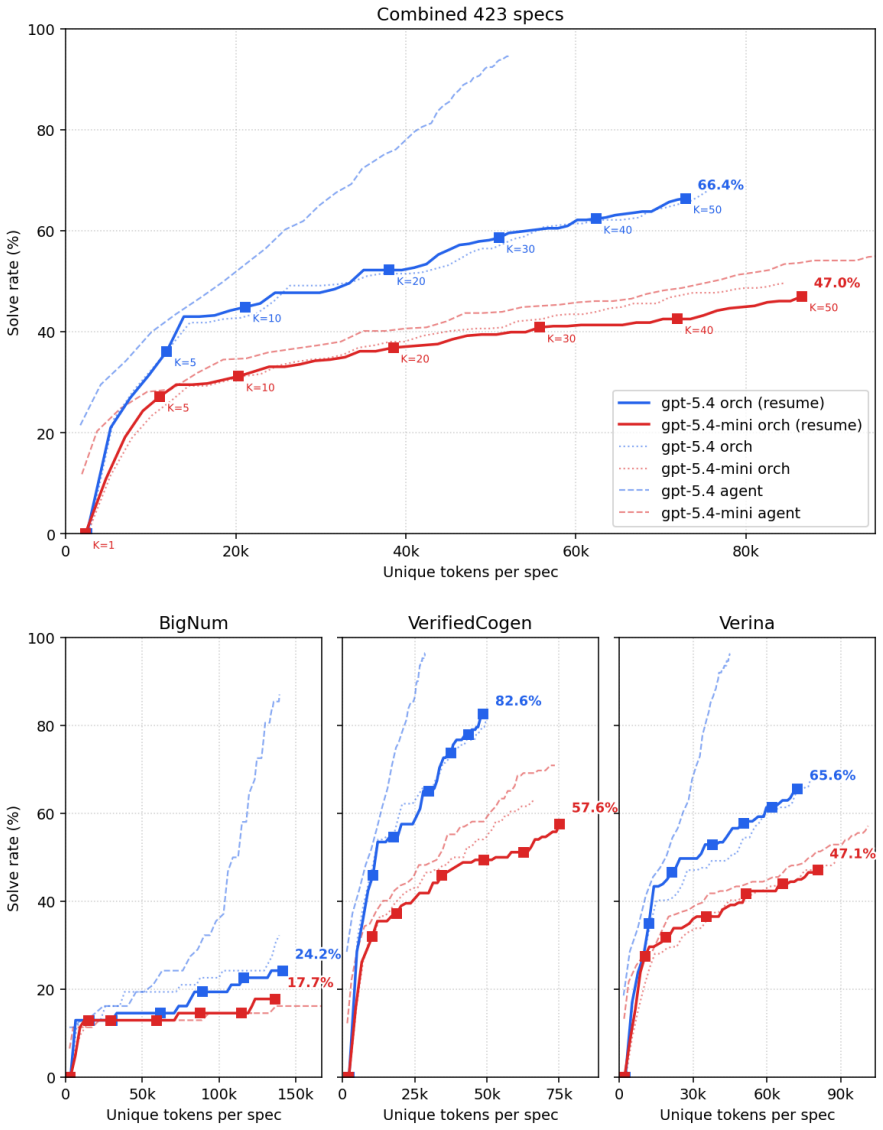
Two agent-directed tree-search methods improve upon a strong agent baseline for turning specifications into verified Lean code. The context-based orchestrator, which branches on full subagent contexts, solves a wider range of intermediate-difficulty specifications at lower token cost. The plain agent baseline retains an advantage on the hardest specifications where uninterrupted iteration matters most. Search structure therefore supplies selective advantages that depend on the difficulty of the verification task.
What carries the argument
The context-based orchestrator that branches on full subagent contexts, allowing the search to explore verification paths while preserving complete conversation state for each branch.
If this is right
- An agentic loop equipped with mathlib search raises model performance on the benchmark and the gains scale with the number of LLM calls permitted.
- The context-based design reduces token usage while covering more intermediate-difficulty specifications than the baseline agent.
- The plain agent loop keeps its lead on the hardest specifications that require long chains of uninterrupted reasoning.
- Search structure can be chosen to match the difficulty profile of the verification tasks at hand.
Where Pith is reading between the lines
- A hybrid system that switches between context-based branching for medium tasks and uninterrupted agent iteration for hard tasks could cover the full difficulty range.
- Embedding the context-based search inside an interactive development environment might let programmers invoke formal verification on selected modules without writing full proofs themselves.
- The selective advantage of search structure suggests that future benchmarks should report results broken down by difficulty tier rather than only aggregate success rates.
- If the pattern holds on larger codebases, verification tools could be tuned per module according to an upfront estimate of proof difficulty.
Load-bearing premise
Performance differences between the search methods and the agent baseline are caused by the choice of search structure rather than by unmeasured factors such as prompt details or model quirks.
What would settle it
Re-running the identical context-based and agent methods on a new collection of verification specifications taken from recent production code and checking whether the context-based method still shows lower token cost on the intermediate-difficulty subset.
Figures






read the original abstract
Formal verification offers a path to provably correct software, but writing verified code remains expensive enough that the technique is rarely used in production. Recent large language models can accelerate this work, and recent benchmarks measure their ability to translate specifications into code and machine-checked proofs of correctness. This thesis evaluates the state of such LLM-driven verified-code generation ("vericoding") in Lean and develops search-based methods for improving verification performance. We first reproduce a subset of the vericoding-benchmark Lean leaderboard on a current cross-vendor model pool, finding that non-reasoning performance remains roughly steady on US closed-source models while open-weight models have slightly improved. We update the iterative methodology of vericoding-benchmark with an agentic loop equipped with mathlib search, finding that model performance greatly improves and scales with agent budget. GPT-5.4 nearly saturates the benchmark at 95.0% on 423 specs with $K=50$ LLM calls. We then design two agent-directed tree-search formulations: a state-based orchestrator that branches on partial-proof states, and a context-based orchestrator that branches on full subagent contexts. Compared against the agent baseline, the context-based design solves a wider range of intermediate-difficulty specs at lower token cost, while the agent baseline retains an advantage on the hardest specs, where uninterrupted iteration matters most. We conclude that search structure has selective advantages over a strong agent baseline, and that more challenging benchmarks drawn from modern code are important to measure and drive further progress in automated formal verification. Code available upon request by contacting the author at leoy@mit.edu.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper evaluates the state of LLM-driven verified-code generation ('vericoding') in Lean. It reproduces a 423-spec subset of the vericoding-benchmark, updates the iterative methodology with an agentic loop equipped with mathlib search (achieving 95.0% success for GPT-5.4 at K=50), and introduces two agent-directed tree-search formulations: a state-based orchestrator branching on partial-proof states and a context-based orchestrator branching on full subagent contexts. The central empirical claim is that the context-based design solves a wider range of intermediate-difficulty specs at lower token cost than the agent baseline, while the baseline retains an advantage on the hardest specs.
Significance. If the comparisons hold under controlled conditions, the work provides evidence that search structure confers selective advantages over a strong agent baseline and that performance scales with agent budget. This is a concrete, falsifiable contribution to automated formal verification. The explicit scaling result and the two contrasting tree-search designs are strengths; however, the code being available only upon request weakens immediate reproducibility.
major comments (2)
- [Abstract / Results comparison] Abstract and comparison section: The claim that 'the context-based design solves a wider range of intermediate-difficulty specs at lower token cost' while the agent baseline wins on hardest specs is load-bearing for the paper's conclusion that 'search structure has selective advantages.' The manuscript provides no explicit statement that base prompts, token accounting, call scheduling, and model-specific behavior are identical between the agent baseline and both tree-search formulations. Without these controls, observed gaps cannot be attributed to branching on full subagent contexts versus uninterrupted iteration.
- [Benchmark reproduction / Results] Benchmark and difficulty section: The 423-spec subset and the partitioning into 'intermediate-difficulty' versus 'hardest' specs are central to the selective-advantage claim. The manuscript does not specify (a) the exact selection criteria for the subset, (b) whether difficulty bins were defined a priori or after observing results, or (c) the precise definition of difficulty used for binning. This information is required to assess whether the reported pattern is robust or an artifact of post-hoc selection.
minor comments (1)
- The abstract states that code is 'available upon request by contacting the author at leoy@mit.edu.' For a methods paper whose central claims rest on empirical comparisons, providing a public repository (even if anonymized) would strengthen reproducibility.
Simulated Author's Rebuttal
We thank the referee for the careful reading and the specific suggestions for strengthening the experimental claims. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract / Results comparison] Abstract and comparison section: The claim that 'the context-based design solves a wider range of intermediate-difficulty specs at lower token cost' while the agent baseline wins on hardest specs is load-bearing for the paper's conclusion that 'search structure has selective advantages.' The manuscript provides no explicit statement that base prompts, token accounting, call scheduling, and model-specific behavior are identical between the agent baseline and both tree-search formulations. Without these controls, observed gaps cannot be attributed to branching on full subagent contexts versus uninterrupted iteration.
Authors: We agree that an explicit statement confirming identical controls is required to support attribution of differences to the branching mechanism. All three conditions (agent baseline, state-based orchestrator, context-based orchestrator) used the same base prompts, the same token-accounting procedure, the same call-scheduling logic, and the same model configuration. In the revised manuscript we will add a dedicated paragraph in the comparison section that states these controls explicitly. revision: yes
-
Referee: [Benchmark reproduction / Results] Benchmark and difficulty section: The 423-spec subset and the partitioning into 'intermediate-difficulty' versus 'hardest' specs are central to the selective-advantage claim. The manuscript does not specify (a) the exact selection criteria for the subset, (b) whether difficulty bins were defined a priori or after observing results, or (c) the precise definition of difficulty used for binning. This information is required to assess whether the reported pattern is robust or an artifact of post-hoc selection.
Authors: We acknowledge that the current text omits these details. The 423-spec subset is the intersection of vericoding-benchmark problems that are Lean-4 compatible and fit within our evaluation budget; difficulty bins were defined from baseline-agent call counts before the tree-search experiments were run. In revision we will state the exact selection criteria, confirm the a-priori definition of the bins, and supply the precise difficulty definition together with the bin assignments for each spec. revision: yes
Circularity Check
No circularity: purely empirical comparisons on external benchmark
full rationale
The paper reports reproduction of an external vericoding-benchmark subset, an updated agentic loop with mathlib search, and head-to-head empirical comparisons of two tree-search orchestrators against an agent baseline. No equations, fitted parameters, or self-citations are used to derive performance claims; all results are direct measurements on the 423-spec benchmark. The derivation chain consists of experimental runs rather than any reduction of outputs to inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Managing extreme AI risks amid rapid progress
Y. Bengio et al. “Managing extreme AI risks amid rapid progress.”Science, 384(6698), May 2024, pp. 842–845.issn: 1095-9203. doi: 10.1126/science.adn0117. url: http: //dx.doi.org/10.1126/science.adn0117
-
[2]
Kwa et al.Measuring AI Ability to Complete Long Software Tasks
T. Kwa et al.Measuring AI Ability to Complete Long Software Tasks. 2025. doi: 10.48550/ARXIV.2503.14499. url: https://arxiv.org/abs/2503.14499
-
[3]
Time Horizon 1.1
METR. Time Horizon 1.1. Model Evaluation & Threat Research, Jan. 2026.url: https://metr.org/blog/2026-1-29-time-horizon-1-1/ (visited on 05/04/2026)
2026
-
[4]
Task-Completion Time Horizons of Frontier AI Models
METR. Task-Completion Time Horizons of Frontier AI Models. Live aggregation page; reports Claude Opus 4.6 at a 14h30m time horizon as of 2026-02-21. Model Evaluation & Threat Research, 2026.url: https://metr.org/time-horizons/ (visited on 05/04/2026)
2026
-
[5]
Hendrycks, M
D. Hendrycks, M. Mazeika, and T. Woodside.An Overview of Catastrophic AI Risks
-
[6]
An Overview of Catastrophic AI Risks
doi: 10.48550/ARXIV.2306.12001. url: https://arxiv.org/abs/2306.12001
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2306.12001
-
[7]
Claude Mythos Preview System Card
Anthropic. Claude Mythos Preview System Card. Anthropic, Apr. 2026.url: https: //anthropic.com/claude-mythos-preview-system-card (visited on 05/04/2026)
2026
-
[8]
GPT-5.5 System Card
OpenAI. GPT-5.5 System Card. OpenAI, Apr. 2026.url: https://openai.com/index/ gpt-5-5-system-card/ (visited on 05/04/2026)
2026
-
[9]
C. Meske, T. Hermanns, E. von der Weiden, K.-U. Loser, and T. Berger.Vibe Coding as a Reconfiguration of Intent Mediation in Software Development: Definition, Implications, 67 and Research Agenda. 2025. doi: 10.48550/ARXIV.2507.21928. url: https://arxiv.org/ abs/2507.21928
-
[10]
Asleep at the Key- board? Assessing the Security of GitHub Copilot’s Code Contributions
H. Pearce, B. Ahmad, B. Tan, B. Dolan-Gavitt, and R. Karri. “Asleep at the Key- board? Assessing the Security of GitHub Copilot’s Code Contributions.” In:2022 IEEE Symposium on Security and Privacy (SP). IEEE, May 2022, pp. 754–768.doi: 10.1109/sp46214.2022.9833571. url: http://dx.doi.org/10.1109/SP46214.2022.9833571
-
[11]
Broken by Default: A Formal Verification Study of Security Vulnerabilities in AI-Generated Code
D. Blain and M. Noiseux.Broken by Default: A Formal Verification Study of Security Vulnerabilities in AI-Generated Code. 2026. doi: 10.48550/ARXIV.2604.05292. url: https://arxiv.org/abs/2604.05292
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2604.05292 2026
-
[12]
The Lean 4 Theorem Prover and Programming Language
L. d. Moura and S. Ullrich. “The Lean 4 Theorem Prover and Programming Language.” In: Automated Deduction – CADE 28. Springer International Publishing, 2021, pp. 625–
2021
-
[13]
doi: 10.1007/978-3-030-79876-5_37
isbn: 9783030798765. doi: 10.1007/978-3-030-79876-5_37. url: http://dx.doi. org/10.1007/978-3-030-79876-5_37
-
[14]
MiniF2F: a cross-system benchmark for formal Olympiad-level mathematics
K. Zheng, J. M. Han, and S. Polu.MiniF2F: a cross-system benchmark for formal Olympiad-level mathematics. 2021. doi: 10.48550/ARXIV.2109.00110. url: https: //arxiv.org/abs/2109.00110
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2109.00110 2021
-
[15]
G. Tsoukalas, J. Lee, J. Jennings, J. Xin, M. Ding, M. Jennings, A. Thakur, and S. Chaudhuri. PutnamBench: Evaluating Neural Theorem-Provers on the Putnam Mathematical Competition. 2024. doi: 10.48550/ARXIV.2407.11214. url: https: //arxiv.org/abs/2407.11214
-
[16]
Olympiad-level formal mathematical reasoning with reinforcement learning
T. Hubert et al. “Olympiad-level formal mathematical reasoning with reinforcement learning.”Nature, 651(8106), Nov. 2025, pp. 607–613.issn: 1476-4687. doi: 10.1038/ s41586-025-09833-y. url: http://dx.doi.org/10.1038/s41586-025-09833-y
-
[17]
HACL*: A Verified Modern Cryptographic Library
J.-K. Zinzindohoué, K. Bhargavan, J. Protzenko, and B. Beurdouche. “HACL*: A Verified Modern Cryptographic Library.” In:Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security. CCS ’17. ACM, Oct. 2017, 68 pp. 1789–1806.doi: 10.1145/3133956.3134043. url: http://dx.doi.org/10.1145/ 3133956.3134043
-
[18]
seL4: formal verification of an OS kernel
G. Klein et al. “seL4: formal verification of an OS kernel.” In:Proceedings of the ACM SIGOPS 22nd symposium on Operating systems principles. SOSP09. ACM, Oct. 2009, pp. 207–220.doi: 10.1145/1629575.1629596. url: http://dx.doi.org/10.1145/1629575. 1629596
-
[19]
A Formally Verified Compiler Back-end
X. Leroy. “A Formally Verified Compiler Back-end.”Journal of Automated Reasoning, 43(4), Nov. 2009, pp. 363–446.issn: 1573-0670. doi: 10.1007/s10817-009-9155-4. url: http://dx.doi.org/10.1007/s10817-009-9155-4
-
[20]
S. Polu, J. M. Han, K. Zheng, M. Baksys, I. Babuschkin, and I. Sutskever.Formal Mathematics Statement Curriculum Learning. 2022. doi: 10.48550/ARXIV.2202.01344. url: https://arxiv.org/abs/2202.01344
-
[21]
S. Varambally, T. Voice, Y. Sun, Z. Chen, R. Yu, and K. Ye.Hilbert: Recursively Building Formal Proofs with Informal Reasoning. 2025. doi: 10.48550/ARXIV.2509.22819. url: https://arxiv.org/abs/2509.22819
-
[22]
G. Lample, M.-A. Lachaux, T. Lavril, X. Martinet, A. Hayat, G. Ebner, A. Rodriguez, and T. Lacroix. HyperTree Proof Search for Neural Theorem Proving. 2022. doi: 10.48550/ARXIV.2205.11491. url: https://arxiv.org/abs/2205.11491
-
[23]
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin.Attention Is All You Need. 2017. doi: 10.48550/ARXIV.1706.03762. url: https://arxiv.org/abs/1706.03762
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1706.03762 2017
-
[24]
T. B. Brown et al.Language Models are Few-Shot Learners. 2020. doi: 10.48550/ ARXIV.2005.14165. url: https://arxiv.org/abs/2005.14165
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[25]
Scaling Laws for Neural Language Models
J. Kaplan, S. McCandlish, T. Henighan, T. B. Brown, B. Chess, R. Child, S. Gray, A. Radford, J. Wu, and D. Amodei.Scaling Laws for Neural Language Models. 2020. doi: 10.48550/ARXIV.2001.08361. url: https://arxiv.org/abs/2001.08361. 69
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2001.08361 2020
-
[26]
Training Compute-Optimal Large Language Models
J. Hoffmann et al. Training Compute-Optimal Large Language Models. 2022. doi: 10.48550/ARXIV.2203.15556. url: https://arxiv.org/abs/2203.15556
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2203.15556 2022
-
[27]
Deep reinforcement learning from human preferences
P. Christiano, J. Leike, T. B. Brown, M. Martic, S. Legg, and D. Amodei.Deep reinforcement learning from human preferences. 2017.doi: 10.48550/ARXIV.1706.03741. url: https://arxiv.org/abs/1706.03741
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1706.03741 2017
-
[28]
Ouyang et al.Training language models to follow instructions with human feedback
L. Ouyang et al.Training language models to follow instructions with human feedback
-
[29]
Training language models to follow instructions with human feedback
doi: 10.48550/ARXIV.2203.02155. url: https://arxiv.org/abs/2203.02155
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2203.02155
-
[30]
Constitutional AI: Harmlessness from AI Feedback
Y. Bai et al. Constitutional AI: Harmlessness from AI Feedback. 2022. doi: 10.48550/ ARXIV.2212.08073. url: https://arxiv.org/abs/2212.08073
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[31]
Direct Preference Optimization: Your Language Model is Secretly a Reward Model
R. Rafailov, A. Sharma, E. Mitchell, S. Ermon, C. D. Manning, and C. Finn.Direct Preference Optimization: Your Language Model is Secretly a Reward Model. 2023. doi: 10.48550/ARXIV.2305.18290. url: https://arxiv.org/abs/2305.18290
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2305.18290 2023
-
[32]
J. Wei, X. Wang, D. Schuurmans, M. Bosma, B. Ichter, F. Xia, E. Chi, Q. Le, and D. Zhou.Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
-
[33]
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
doi: 10.48550/ARXIV.2201.11903. url: https://arxiv.org/abs/2201.11903
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2201.11903
-
[34]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek-AI et al. DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning. 2025. doi: 10.48550/ARXIV.2501.12948. url: https://arxiv. org/abs/2501.12948
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2501.12948 2025
-
[35]
OpenAI o1 System Card
OpenAI. OpenAI o1 System Card. OpenAI, Dec. 2024.url: https://openai.com/index/ openai-o1-system-card/ (visited on 05/04/2026)
2024
-
[36]
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. Narasimhan, and Y. Cao.ReAct: Synergizing Reasoning and Acting in Language Models. 2022. doi: 10.48550/ARXIV. 2210.03629. url: https://arxiv.org/abs/2210.03629
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv 2022
-
[37]
Dwivedi-Yu,R.Dessì,R.Raileanu,M.Lomeli, L.Zettlemoyer, N.Cancedda, and T
T.Schick,J. Dwivedi-Yu,R.Dessì,R.Raileanu,M.Lomeli, L.Zettlemoyer, N.Cancedda, and T. Scialom.Toolformer: Language Models Can Teach Themselves to Use Tools
-
[38]
Toolformer: Language Models Can Teach Themselves to Use Tools
doi: 10.48550/ARXIV.2302.04761. url: https://arxiv.org/abs/2302.04761. 70
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2302.04761
-
[39]
Introducing the Model Context Protocol
Anthropic. Introducing the Model Context Protocol. Anthropic, Nov. 2024.url: https: //www.anthropic.com/news/model-context-protocol (visited on 05/04/2026)
2024
-
[40]
Donating the Model Context Protocol and establishing the Agentic AI Foundation
Anthropic. Donating the Model Context Protocol and establishing the Agentic AI Foundation. Anthropic, Dec. 2025.url: https://www.anthropic.com/news/donating- the-model-context-protocol-and-establishing-of-the-agentic-ai-foundation (visited on 05/04/2026)
2025
-
[41]
Claude Code: Anthropic’s agentic coding system
Anthropic. Claude Code: Anthropic’s agentic coding system. Anthropic, 2025. url: https://www.anthropic.com/product/claude-code (visited on 05/04/2026)
2025
-
[42]
Codex: AI Coding Partner from OpenAI
OpenAI. Codex: AI Coding Partner from OpenAI. OpenAI, 2025.url: https://openai. com/codex/ (visited on 05/05/2026)
2025
-
[43]
OpenCode: The open source AI coding agent
Anomaly. OpenCode: The open source AI coding agent. Anomaly, 2025.url: https: //opencode.ai/ (visited on 05/05/2026)
2025
-
[44]
Milner.Logic for Computable Functions: Description of a Machine Implementation
R. Milner.Logic for Computable Functions: Description of a Machine Implementation. Tech. rep. STAN-CS-72-288. Stanford University, Department of Computer Science, May
-
[45]
url: http://i.stanford.edu/pub/cstr/reports/cs/tr/72/288/CS-TR-72-288.pdf (visited on 05/04/2026)
2026
-
[46]
M. J. Gordon, A. J. Milner, and C. P. Wadsworth.Edinburgh LCF. Springer Berlin Heidelberg, 1979. isbn: 9783540385264. doi: 10.1007/3-540-09724-4. url: http: //dx.doi.org/10.1007/3-540-09724-4
-
[47]
T. Coquand and C. Paulin. “Inductively defined types.” In:COLOG-88. Springer Berlin Heidelberg, 1990, pp. 50–66.isbn: 9783540469636. doi: 10.1007/3-540-52335-9_47. url: http://dx.doi.org/10.1007/3-540-52335-9_47
-
[48]
Formal Proof—The Four-Color Theorem
G. Gonthier. “Formal Proof—The Four-Color Theorem.”Notices of the American Mathematical Society, 55(11), 2008, pp. 1382–1393.url: https://www.ams.org/notices/ 200811/tx081101382p.pdf (visited on 05/04/2026). 71
2008
-
[49]
A Machine-Checked Proof of the Odd Order Theorem
G. Gonthier et al. “A Machine-Checked Proof of the Odd Order Theorem.” In:Interactive Theorem Proving. Springer Berlin Heidelberg, 2013, pp. 163–179.isbn: 9783642396342. doi: 10.1007/978-3-642-39634-2_14. url: http://dx.doi.org/10.1007/978-3-642-39634- 2_14
-
[50]
Springer Berlin Heidelberg, 2002.isbn: 9783540459491
Isabelle/HOL. Springer Berlin Heidelberg, 2002.isbn: 9783540459491. doi: 10.1007/3- 540-45949-9. url: http://dx.doi.org/10.1007/3-540-45949-9
work page doi:10.1007/3- 2002
-
[51]
AFP requests entry- level citations for specific proofs; this cite refers to the archive as a whole
Archive of Formal Proofs contributors.Archive of Formal Proofs. AFP requests entry- level citations for specific proofs; this cite refers to the archive as a whole. Archive of Formal Proofs, 2026.url: https://www.isa-afp.org/ (visited on 05/04/2026)
2026
-
[52]
Towards a practical programming language based on dependent type theory
U. Norell. “Towards a practical programming language based on dependent type theory.” PhD thesis. Göteborg, Sweden: Chalmers University of Technology, Sept. 2007.url: https://research.chalmers.se/en/publication/46311 (visited on 05/04/2026)
2007
-
[53]
2025.Approaches to Automated NACE Coding of German Business Activity Descriptions
L. de Moura, S. Kong, J. Avigad, F. van Doorn, and J. von Raumer. “The Lean Theorem Prover (System Description).” In:Automated Deduction - CADE-25. Springer International Publishing, 2015, pp. 378–388.isbn: 9783319214016. doi: 10.1007/978-3- 319-21401-6_26. url: http://dx.doi.org/10.1007/978-3-319-21401-6_26
-
[54]
A metaprogramming framework for formal verification
G. Ebner, S. Ullrich, J. Roesch, J. Avigad, and L. de Moura. “A metaprogramming framework for formal verification.”Proceedings of the ACM on Programming Languages, 1(ICFP), Aug. 2017, pp. 1–29.issn: 2475-1421. doi: 10.1145/3110278. url: http: //dx.doi.org/10.1145/3110278
-
[55]
T. mathlib Community. “The lean mathematical library.” In:Proceedings of the 9th ACM SIGPLAN International Conference on Certified Programs and Proofs. POPL ’20. ACM, Jan. 2020, pp. 367–381.doi: 10.1145/3372885.3373824. url: http://dx.doi. org/10.1145/3372885.3373824
-
[56]
Lean formalization of the main theorem of liquid vector spaces, completed July 2022 in response to Peter Scholze’s 72 challenge
Lean Prover Community.Liquid Tensor Experiment. Lean formalization of the main theorem of liquid vector spaces, completed July 2022 in response to Peter Scholze’s 72 challenge. GitHub, 2022.url: https://github.com/leanprover-community/lean-liquid (visited on 05/04/2026)
2022
-
[57]
Tao and PFR formalization contributors.The Polynomial Freiman–Ruzsa Conjecture: A digitisation of the proof in Lean 4
T. Tao and PFR formalization contributors.The Polynomial Freiman–Ruzsa Conjecture: A digitisation of the proof in Lean 4. 2023. url: https://teorth.github.io/pfr/ (visited on 05/04/2026)
2023
-
[58]
Aesop: White-Box Best-First Proof Search for Lean
J. Limperg and A. H. From. “Aesop: White-Box Best-First Proof Search for Lean.” In: Proceedings of the 12th ACM SIGPLAN International Conference on Certified Programs and Proofs. CPP ’23. ACM, Jan. 2023, pp. 253–266.doi: 10.1145/3573105.3575671. url: http://dx.doi.org/10.1145/3573105.3575671
-
[59]
Dressler.Lean LSP MCP: Tools for agentic interaction with the Lean theorem prover
O. Dressler.Lean LSP MCP: Tools for agentic interaction with the Lean theorem prover. Mar. 2025. url: https://github.com/oOo0oOo/lean-lsp-mcp (visited on 05/04/2026)
2025
-
[60]
Aeneas:Rustverificationbyfunctionaltranslation
S.HoandJ.Protzenko.“Aeneas:Rustverificationbyfunctionaltranslation.” Proceedings of the ACM on Programming Languages, 6(ICFP), Aug. 2022, pp. 711–741.issn: 2475-
2022
-
[61]
url: http://dx.doi.org/10.1145/3547647
doi: 10.1145/3547647. url: http://dx.doi.org/10.1145/3547647
-
[62]
Lean Language,
Lean FRO.Aeneas: Bridging Rust to Lean for Formal Verification. Lean Language,
-
[63]
url: https://lean-lang.org/use-cases/aeneas/ (visited on 05/04/2026)
2026
-
[64]
Tuma and N
D. Tuma and N. Hopper.VCVio: A Formally Verified Forking Lemma and Fiat-Shamir Transform, via a Flexible and Expressive Oracle Representation. Cryptology ePrint Archive, Paper 2024/1819. Nov. 2024.url: https://eprint.iacr.org/2024/1819 (visited on 05/04/2026)
2024
-
[65]
Dafny: An Automatic Program Verifier for Functional Correctness
K. R. M. Leino. “Dafny: An Automatic Program Verifier for Functional Correctness.” In: Logic for Programming, Artificial Intelligence, and Reasoning. Springer Berlin Heidelberg, 2010, pp. 348–370.isbn: 9783642175114. doi: 10.1007/978-3-642-17511- 4_20. url: http://dx.doi.org/10.1007/978-3-642-17511-4_20. 73
-
[66]
IronFleet: proving practical distributed systems correct
C. Hawblitzel, J. Howell, M. Kapritsos, J. R. Lorch, B. Parno, M. L. Roberts, S. Setty, and B. Zill. “IronFleet: proving practical distributed systems correct.” In:Proceedings of the 25th Symposium on Operating Systems Principles. SOSP ’15. ACM, Oct. 2015, pp. 1–
2015
-
[67]
url: http://dx.doi.org/10.1145/2815400.2815428
doi: 10.1145/2815400.2815428. url: http://dx.doi.org/10.1145/2815400.2815428
-
[68]
Storage Systems are Distributed Systems (So Verify Them That Way!)
T. Hance, A. Lattuada, C. Hawblitzel, J. Howell, R. Johnson, and B. Parno. “Storage Systems are Distributed Systems (So Verify Them That Way!)” In:14th USENIX Symposium on Operating Systems Design and Implementation (OSDI 20). USENIX Association, Nov. 2020, pp. 99–115.isbn: 978-1-939133-19-9. url: https://www.usenix. org/conference/osdi20/presentation/han...
2020
-
[69]
Dependent types and multi-monadic effects in F*
N. Swamy et al. “Dependent types and multi-monadic effects in F*.” In:Proceedings of the 43rd Annual ACM SIGPLAN-SIGACT Symposium on Principles of Programming Languages. POPL ’16. ACM, Jan. 2016, pp. 256–270.doi: 10.1145/2837614.2837655. url: http://dx.doi.org/10.1145/2837614.2837655
-
[70]
libcrux: The formally verified crypto library for Rust
Cryspen. libcrux: The formally verified crypto library for Rust. GitHub, 2024. url: https://github.com/cryspen/libcrux (visited on 05/04/2026)
2024
-
[71]
Verus: Verifying Rust Programs using Linear Ghost Types
A. Lattuada, T. Hance, C. Cho, M. Brun, I. Subasinghe, Y. Zhou, J. Howell, B. Parno, and C. Hawblitzel. “Verus: Verifying Rust Programs using Linear Ghost Types.” Proceedings of the ACM on Programming Languages, 7(OOPSLA1), Apr. 2023, pp. 286–
2023
-
[72]
issn: 2475-1421. doi: 10.1145/3586037. url: http://dx.doi.org/10.1145/3586037
-
[73]
Singh, J
P. Singh, J. Gancher, and B. Parno.OwlC: Compiling Security Protocols to Verified, Secure, High-Performance Libraries. Cryptology ePrint Archive, Paper 2025/1092. June
2025
-
[74]
url: https://eprint.iacr.org/2025/1092 (visited on 05/04/2026)
2025
-
[75]
Verus proofs over a fork ofcurve25519-dalek
Beneficial AI Foundation.dalek-lite: A pure-Rust implementation of group operations on Ristretto and Curve25519. Verus proofs over a fork ofcurve25519-dalek. GitHub,
-
[76]
url: https://github.com/Beneficial-AI-Foundation/dalek-lite (visited on 05/04/2026). 74
2026
-
[77]
Polu and I
S. Polu and I. Sutskever.Generative Language Modeling for Automated Theorem Proving
-
[78]
Generative Language Modeling for Automated Theorem Proving
doi: 10.48550/ARXIV.2009.03393. url: https://arxiv.org/abs/2009.03393
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2009.03393 2009
-
[79]
J. M. Han, J. Rute, Y. Wu, E. W. Ayers, and S. Polu.Proof Artifact Co-training for Theorem Proving with Language Models. 2021. doi: 10.48550/ARXIV.2102.06203. url: https://arxiv.org/abs/2102.06203
-
[80]
K. Yang, A. M. Swope, A. Gu, R. Chalamala, P. Song, S. Yu, S. Godil, R. Prenger, and A. Anandkumar. LeanDojo: Theorem Proving with Retrieval-Augmented Language Models
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.