Keyphrase Generative Representation of Youth Crisis Conversations Beyond Static Taxonomies
Pith reviewed 2026-06-29 18:31 UTC · model grok-4.3
The pith
A constrained LLM generates conversation-specific keyphrases that raise youth crisis topic retrieval accuracy from 0.25 to 0.70 and reveal themes missed by fixed taxonomies.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
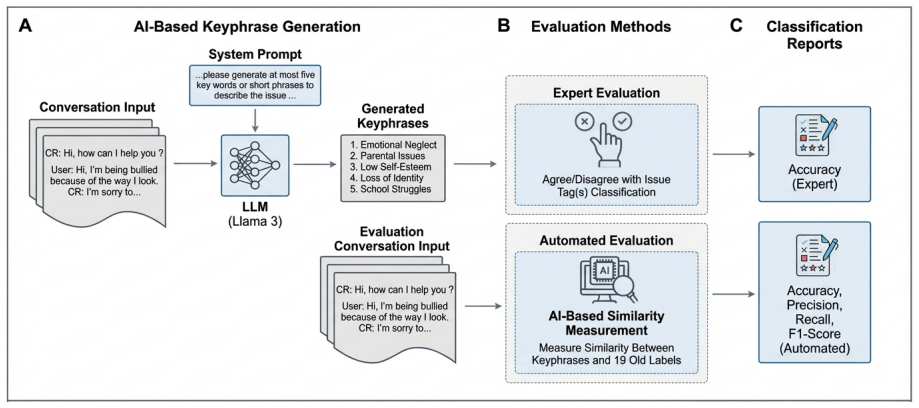
The paper claims that Keyphrase Generative Representation (KGR) using a constrained LLM produces concise keyphrases that accurately reflect conversation content in 81 percent of cases and improve clarity in 74 percent of cases. KGR enables a topic-retrieval workflow that reaches 0.70 accuracy compared with 0.25 for the manual analyst process and surfaces identity-linked themes absent from the original taxonomy, including immigration problems and caregiver burden. The expanded 39-label schema reaches 0.96 expert consensus reliability.
What carries the argument
Keyphrase Generative Representation (KGR), a constrained large language model that outputs concise, conversation-specific keyphrases from youth crisis SMS texts.
If this is right
- The expanded 39-label hierarchical schema reaches 0.96 expert consensus reliability.
- 81 percent of KGR keyphrases accurately reflect content and 74 percent improve clarity over original text.
- KGR surfaces identity-linked themes such as immigration problems and caregiver burden that fixed taxonomies omit.
- The KGR-supported topic-retrieval workflow raises accuracy from 0.25 to 0.70 over manual analysis.
Where Pith is reading between the lines
- The same generative approach could be tested on crisis text from adult populations or other languages to check whether it consistently uncovers culturally specific patterns.
- Integrating KGR into live responder dashboards might let teams flag emerging issues without waiting for taxonomy updates.
- Generated keyphrases could serve as seeds for automatically proposing new taxonomy labels from ongoing data streams.
- The method might reduce reliance on any single fixed label set when applied to other high-volume social-service text archives.
- keywords:[
Load-bearing premise
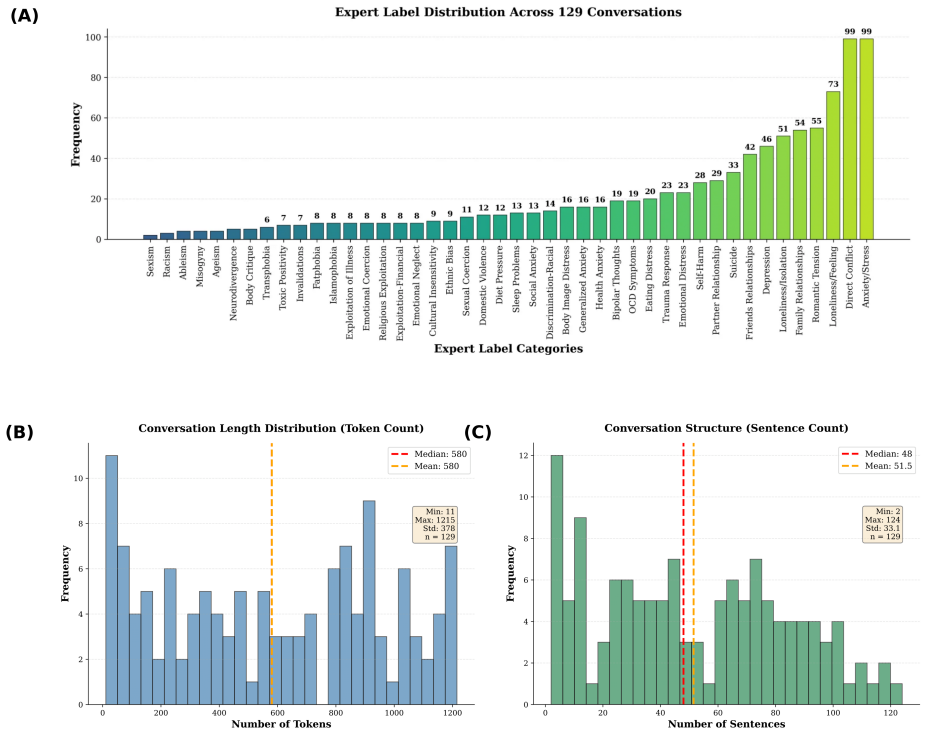
The 387 expert annotations on only 129 conversations provide a reliable proxy for performance across the full 703975-conversation corpus without systematic LLM biases or hallucinations in mental-health contexts.
What would settle it
A fresh expert annotation round on a random sample of several thousand conversations drawn from the full corpus would show whether retrieval accuracy stays near 0.70 and whether keyphrases continue to avoid missing or distorting distress themes.
Figures



read the original abstract
Crisis Responders (CRs) rapidly assess thousands of youth SMS conversations each year to identify mental health concerns and guide support. Yet youth distress is increasingly expressed through evolving and context-specific language that often does not fit fixed-label taxonomies. This work analyzed 703,975 de-identified Kids Help Phone conversations (2018-2023) and expanded KHP's 19-label issue taxonomy into a 39-label hierarchical schema. We then introduce Keyphrase Generative Representation (KGR), a constrained LLM generating concise, conversation-specific keyphrases, evaluated across 129 conversations and 387 expert annotations. The expanded taxonomy achieved expert consensus reliability, with an accuracy of 0.96, and expert review found that 81% of keyphrases accurately reflected content and 74% improved clarity. KGR surfaced identity-linked themes absent from the fixed taxonomy, including immigration problems and caregiver burden, and supported a topic-retrieval workflow that increased accuracy from 0.25 to 0.70 (+0.45) over the manual analyst process. KGR marks a shift toward hybrid, interpretable generative representations that extend crisis response beyond static taxonomies to surface emerging and culturally grounded patterns of youth distress.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript analyzes 703,975 de-identified youth SMS crisis conversations (2018-2023) from Kids Help Phone, expands the existing 19-label taxonomy to a 39-label hierarchical schema, and introduces Keyphrase Generative Representation (KGR) via a constrained LLM to produce conversation-specific keyphrases. Expert evaluation on 129 conversations (387 annotations) reports 0.96 accuracy for the expanded taxonomy, 81% of KGR keyphrases accurately reflecting content, 74% improving clarity, identification of new themes (e.g., immigration problems, caregiver burden), and a topic-retrieval workflow raising accuracy from 0.25 to 0.70.
Significance. If the empirical results hold under proper validation, the work demonstrates a practical hybrid generative approach that can extend static taxonomies in mental-health crisis response by surfacing evolving, context-specific, and culturally grounded patterns. The scale of the analyzed corpus and direct expert annotation provide applied relevance for real-world deployment.
major comments (2)
- [Abstract] Abstract: The headline claim that KGR enables a topic-retrieval workflow increasing accuracy from 0.25 to 0.70 (+0.45) rests on expert review of only 129 conversations. No sampling strategy, stratification by the 39-label taxonomy, or representativeness argument is supplied, so the results cannot be taken as evidence that the method reliably surfaces emerging themes across the full 703,975-conversation corpus without systematic LLM bias.
- [Abstract] Abstract: The reported expert consensus reliability of 0.96 and the 81%/74% keyphrase figures are presented without any description of the evaluation protocol, number of experts, inter-annotator agreement computation, or error bars. This absence prevents verification of the central empirical claims that underwrite the shift to generative representations.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for identifying areas where the abstract requires greater transparency regarding sampling and evaluation details. We address the two major comments below and commit to revisions that strengthen the presentation of our empirical claims without overstating generalizability.
read point-by-point responses
-
Referee: The headline claim that KGR enables a topic-retrieval workflow increasing accuracy from 0.25 to 0.70 (+0.45) rests on expert review of only 129 conversations. No sampling strategy, stratification by the 39-label taxonomy, or representativeness argument is supplied, so the results cannot be taken as evidence that the method reliably surfaces emerging themes across the full 703,975-conversation corpus without systematic LLM bias.
Authors: We agree that the abstract does not describe the sampling procedure or provide a representativeness argument, and that the reported accuracy gain is therefore limited to the evaluated subset. The 129 conversations were selected to enable feasible expert annotation; the topic-retrieval result is presented as an illustration on this sample rather than a claim for the entire corpus. In revision we will update the abstract to state the sample size explicitly, note the absence of a full stratification argument, and qualify the result as sample-based while discussing potential LLM biases in the discussion section. revision: yes
-
Referee: The reported expert consensus reliability of 0.96 and the 81%/74% keyphrase figures are presented without any description of the evaluation protocol, number of experts, inter-annotator agreement computation, or error bars. This absence prevents verification of the central empirical claims that underwrite the shift to generative representations.
Authors: The abstract summarizes the expert-evaluation outcomes but omits protocol details due to length constraints. The full manuscript contains the annotation protocol and expert count in the Methods section; however, we accept that these elements should be referenced in the abstract for immediate verifiability. We will revise the abstract to include a concise statement of the evaluation setup, the number of experts, and any available inter-annotator agreement or confidence information. revision: yes
Circularity Check
No significant circularity; claims rest on independent empirical annotations
full rationale
The paper presents an empirical workflow: taxonomy expansion on 703k conversations, KGR generation via constrained LLM, and evaluation via 387 expert annotations on 129 conversations yielding accuracy figures (0.96 for taxonomy, 81%/74% for keyphrases, 0.25-to-0.70 workflow gain). No equations, fitted parameters, self-definitional loops, or load-bearing self-citations are described that would reduce any prediction or result to its own inputs by construction. All reported metrics derive from external expert review rather than internal redefinition or renaming of known patterns.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Training Therapeutic Judges and Multi-Agent Systems for Human-Aligned Mental Health Support
TheraJudge, trained via preference optimization on human annotations, reaches high clinician agreement (ICC 0.87-0.95) and, when used by TheraAgent, raises human-rated therapeutic quality by 0.43 points on a 5-point s...
Reference graph
Works this paper leans on
-
[1]
Organization, W. H. Adolescent mental health (2021). URLhttps://www.who.int/ news-room/fact-sheets/detail/adolescent-mental-health. Accessed: 2025-08-18
2021
-
[2]
Patel, V. e. a. The lancet commission on global mental health and sustainable development. The Lancet Psychiatry5, 935–984 (2018). URLhttps://www.thelancet.com/journals/ lanpsy/article/PIIS2215-0366(21)00395-3/fulltext
2018
-
[3]
Wiens, K. e. a. A growing need for youth mental health services in canada: examining trends in youth mental health from 2011 to 2018.Epidemiology and Psychiatric Sciences29, e115 (2020). URLhttps://doi.org/10.1017/S2045796020000281
-
[4]
Kids Help Phone.https://kidshelpphone.ca/(2025)
Kids Help Phone. Kids Help Phone.https://kidshelpphone.ca/(2025). URLhttps: //kidshelpphone.ca/. Accessed: 2025-12-02
2025
-
[5]
Turkington, R.et al.Why do people call crisis helplines? identifying taxonomies of presenting reasons and discovering associations between these reasons.Health Informatics Journal26, 2597–2613 (2020)
2020
-
[6]
& Lee, S
Ali, M., Ali, S., Abbas, Q., Abbas, Z. & Lee, S. W. Artificial intelligence for mental health: A narrative review of applications, challenges, and future directions in digital health.Digital Health11, 20552076251395548 (2025)
2025
-
[7]
& Kassam, A
Rose, D., Thornicroft, G., Pinfold, V. & Kassam, A. 250 labels used to stigmatise people with mental illness.BMC Health Services Research7, 97 (2007)
2007
-
[8]
J., Smart, S
Owen, D., Lynham, A. J., Smart, S. E., Pardi˜ nas, A. F. & Camacho-Collados, J. Ai for analyzing mental health disorders among social media users: Quarter-century narrative review of progress and challenges.Journal of Medical Internet Research26, e59225 (2024). 16
2024
-
[9]
Obadinma, S. e. a. The faiir conversational ai agent assistant for youth mental health service provision.npj Digital Medicine8, 1–13 (2025). URLhttps://www.nature.com/articles/ s41746-025-01647-6
2025
-
[10]
Overall trends for child and youth men- tal health (2024)
Canadian Institute for Health Information. Overall trends for child and youth men- tal health (2024). URLhttps://www.cihi.ca/en/child-and-youth-mental-health/ overall-trends-for-child-and-youth-mental-health. Accessed: 2025-08-18
2024
-
[11]
Levis, M., Leonard Westgate, C., Gui, J., Watts, B. V. & Shiner, B. Natural language processing of clinical mental health notes may add predictive value to existing suicide risk models.Psychological Medicine51, 1382–1391 (2021)
2021
-
[12]
Tsui, F. R.et al.Natural language processing and machine learning of electronic health records for prediction of first-time suicide attempts.JAMIA Open4, ooab011 (2021). URL https://doi.org/10.1093/jamiaopen/ooab011.https://academic.oup.com/jamiaopen/ article-pdf/4/1/ooab011/36621506/ooab011.pdf
work page doi:10.1093/jamiaopen/ooab011.https://academic.oup.com/jamiaopen/ 2021
-
[13]
Jain, P., Srinivas, K. R. & Vichare, A. Depression and suicide analysis using machine learning and nlp.Journal of Physics: Conference Series2161, 012034 (2022). URLhttps://dx.doi. org/10.1088/1742-6596/2161/1/012034
-
[14]
P.et al.Quantifying the association between psychotherapy content and clinical outcomes using deep learning.JAMA Psychiatry77, 35–43 (2020)
Ewbank, M. P.et al.Quantifying the association between psychotherapy content and clinical outcomes using deep learning.JAMA Psychiatry77, 35–43 (2020)
2020
-
[15]
M.et al.The promise of machine learning in predicting treatment outcomes in psychiatry.World Psychiatry20, 154–170 (2021)
Chekroud, A. M.et al.The promise of machine learning in predicting treatment outcomes in psychiatry.World Psychiatry20, 154–170 (2021)
2021
-
[16]
B.et al.Machine learning and natural language processing in psychotherapy research: Alliance as example use case.Journal of counseling psychology67, 438 (2020)
Goldberg, S. B.et al.Machine learning and natural language processing in psychotherapy research: Alliance as example use case.Journal of counseling psychology67, 438 (2020)
2020
-
[17]
Lin, B., Cecchi, G. & Bouneffouf, D. Deep annotation of therapeutic working alliance in psychotherapy. InInternational workshop on health intelligence, 193–207 (Springer, 2023). URLhttps://doi.org/10.1007/978-3-031-36938-4_15
-
[18]
D., Zech, J
Malgaroli, M., Hull, T. D., Zech, J. M. & Althoff, T. Natural language processing for mental health interventions: A systematic review and research framework.Translational Psychiatry 13, 309 (2023)
2023
-
[19]
Zhang, Q.et al.Generative ai mental health chatbots as therapeutic tools: Systematic review and meta-analysis of their role in reducing mental health issues.Journal of Medical Internet Research27, e78238 (2025)
2025
-
[20]
Ji, S., Zhang, T., Yang, K., Ananiadou, S. & Cambria, E. Rethinking large language models in mental health applications (2023). URLhttps://arxiv.org/abs/2311.11267.2311.11267
-
[21]
ihealth: The ethics of artificial intelligence and big data in mental healthcare
Rubeis, G. ihealth: The ethics of artificial intelligence and big data in mental healthcare. Internet Interventions28, 100518 (2022). URLhttps://www.sciencedirect.com/science/ article/pii/S2214782922000252
2022
-
[22]
Ai is gone: engagement and ethics in data-driven technology for mental health
Carr, S. Ai is gone: engagement and ethics in data-driven technology for mental health. Journal of Mental Health29, 125–130 (2020). URLhttps://doi.org/10.1080/09638237. 2020.1714011. PMID: 32000544,https://doi.org/10.1080/09638237.2020.1714011. 17
-
[23]
Torous, J.et al.The evolving field of digital mental health: current evidence and implemen- tation issues for smartphone apps, generative artificial intelligence, and virtual reality.World Psychiatry24, 156–174 (2025)
2025
-
[24]
V., Swaroop, S., Simon, A
Mughal, S., McIlwaine, S. V., Swaroop, S., Simon, A. & Shah, J. L. Five years of youth engagement with kids help phone canada (part 1): Phone, chat, text, and peer-to-peer service usage nationally, provincially, and over time.Telemedicine and e-Health30, 788–794 (2024). Epub 2023 Sep 12
2024
-
[25]
V., Swaroop, S., Simon, A
Mughal, S., McIlwaine, S. V., Swaroop, S., Simon, A. & Shah, J. L. Five years of youth engagement with kids help phone canada (part 2): Issues discussed over phone, chat, text, and peer-to-peer services by age range.Telemedicine and e-Health30, 795–804 (2024). Epub 2023 Sep 12
2024
-
[26]
Vector institute for artificial intelligence (2025)
Vector Institute. Vector institute for artificial intelligence (2025). URLhttps:// vectorinstitute.ai/. Accessed: 2026-03-06
2025
-
[27]
S.et al.Crisis text-line interventions: Evaluation of texters’ perceptions of effec- tiveness.Suicide and Life-Threatening Behavior52, 583–595 (2022)
Gould, M. S.et al.Crisis text-line interventions: Evaluation of texters’ perceptions of effec- tiveness.Suicide and Life-Threatening Behavior52, 583–595 (2022). Epub 2022 May 22
2022
-
[28]
Meta llama 3.https://ai.meta.com/blog/meta-llama-3/(2024)
Meta AI. Meta llama 3.https://ai.meta.com/blog/meta-llama-3/(2024). Accessed: 2025-09-29
2024
- [29]
-
[30]
A.et al.On evaluation metrics for medical applications of artificial intelligence
Hicks, S. A.et al.On evaluation metrics for medical applications of artificial intelligence. Scientific Reports12, 5979 (2022). URLhttps://www.ncbi.nlm.nih.gov/pmc/articles/ PMC8993826/
2022
-
[31]
Grattafiori, A., Dubey, A., Jauhri, A.et al.The llama 3 herd of models (2024). URL https://arxiv.org/abs/2407.21783.2407.21783
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[32]
Singhal, K.et al.Large language models encode clinical knowledge.Nature620, 172–180 (2023)
2023
-
[33]
Van Veen, D.et al.Adapted large language models can outperform medical experts in clinical text summarization.Nature Medicine30, 1134–1142 (2024)
2024
-
[34]
Bednarczyk, L.et al.Scientific evidence for clinical text summarization using large language models: Scoping review.Journal of Medical Internet Research27, e68998 (2025)
2025
-
[35]
C.et al.Llm-aix: An open source pipeline for information extraction from un- structured medical text based on privacy preserving large language models.medRxiv(2024)
Wiest, I. C.et al.Llm-aix: An open source pipeline for information extraction from un- structured medical text based on privacy preserving large language models.medRxiv(2024). Preprint
2024
-
[36]
S., Reid, M., Matsuo, Y
Kojima, T., Gu, S. S., Reid, M., Matsuo, Y. & Iwasawa, Y. Large lan- guage models are zero-shot reasoners. In Koyejo, S.et al.(eds.)Advances in Neural Information Processing Systems, vol. 35, 22199–22213 (Curran Associates, Inc., 2022). URLhttps://proceedings.neurips.cc/paper_files/paper/2022/file/ 8bb0d291acd4acf06ef112099c16f326-Paper-Conference.pdf. 18
2022
-
[37]
A.et al.Artificial intelligence for mental health and mental illnesses: an overview
Graham, S. A.et al.Artificial intelligence for mental health and mental illnesses: an overview. Current Psychiatry Reports21, 116 (2019). URLhttps://link.springer.com/article/10. 1007/s11920-019-1094-0
2019
-
[38]
Rose, D., Thornicroft, G., Pinfold, V. & Kassam, A. 250 labels used to stigmatise people with mental illness.BMC Health Services Research7, 97 (2007). URLhttps://link.springer. com/article/10.1186/1472-6963-7-97
-
[39]
URL https://doi.org/10.1038/s41746-023-00951-3
Swaminathan, A.et al.Natural language processing system for rapid detection and inter- vention of mental health crisis chat messages.npj Digital Medicine6, 213 (2023). URL https://doi.org/10.1038/s41746-023-00951-3
-
[40]
URLhttps: //doi.org/10.3389/fpsyt.2023.1110527
Broadbent, M.et al.A machine learning approach to identifying suicide risk among text- based crisis counseling encounters.Frontiers in Psychiatry14, 1110527 (2023). URLhttps: //doi.org/10.3389/fpsyt.2023.1110527
-
[41]
Self-labeling and its effects among adolescents diagnosed with mental disorders
Moses, T. Self-labeling and its effects among adolescents diagnosed with mental disorders. Social Science & Medicine68, 570–578 (2009). URLhttps://www.sciencedirect.com/ science/article/pii/S0277953608005790
2009
-
[42]
Gureje, O., Lewis-Fern´ andez, R., Hall, B. J. & Reed, G. M. Cultural considerations in the classification of mental disorders: why and how in ICD-11.BMC Medicine18, 25 (2020). URLhttps://doi.org/10.1186/s12916-020-1493-4
-
[43]
Lewis-Fern´ andez, R. & Kirmayer, L. J. Cultural concepts of distress and psychiatric disorders: Understanding symptom experience and expression in context.Transcultural Psychiatry56, 786–803 (2019). URLhttps://doi.org/10.1177/1363461519861795
-
[44]
Stupinski, A. M.et al.Quantifying changes in the language used around mental health on twitter over 10 years: Observational study.JMIR Mental Health9, e33685 (2022). URL https://doi.org/10.2196/33685
-
[45]
Dinakar, K., Chen, J., Lieberman, H., Picard, R. W. & Filbin, R. Mixed-initiative real-time topic modeling & visualization for crisis counseling. InProceedings of the 20th International Conference on Intelligent User Interfaces (IUI ’15), 417–426 (Association for Computing Ma- chinery, 2015). URLhttps://doi.org/10.1145/2678025.2701395
-
[46]
Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer
Althoff, T., Clark, K. & Leskovec, J. Large-scale analysis of counseling conversations: An application of natural language processing to mental health.Transactions of the Association for Computational Linguistics4, 463–476 (2016). URLhttps://doi.org/10.1162/tacl_a_ 00111
-
[47]
Adhikary, P. K.et al.Exploring the efficacy of large language models in summarizing mental health counseling sessions: Benchmark study.JMIR Mental Health11, e57306 (2024). URL https://doi.org/10.2196/57306
-
[48]
URLhttps://doi.org/10.2196/58418
So, J.-h.et al.Aligning large language models for enhancing psychiatric interviews through symptom delineation and summarization: Pilot study.JMIR Formative Research8, e58418 (2024). URLhttps://doi.org/10.2196/58418. 19
-
[49]
International statistical classification of diseases and re- lated health problems (ICD).https://www.who.int/standards/classifications/ classification-of-diseases(2026)
World Health Organization. International statistical classification of diseases and re- lated health problems (ICD).https://www.who.int/standards/classifications/ classification-of-diseases(2026). URLhttps://www.who.int/standards/ classifications/classification-of-diseases. Accessed: 2026-03-02
2026
-
[50]
Intended use: SNOMED CT editorial guide (2026)
SNOMED International. Intended use: SNOMED CT editorial guide (2026). URL https://docs.snomed.org/snomed-ct-specifications/snomed-ct-editorial-guide/ readme/snomed-ct-introduction/intended-use. Accessed: 2026-03-02
2026
-
[51]
National guidelines for a behav- ioral health coordinated system of crisis care (2025)
Substance Abuse and Mental Health Services Administration. National guidelines for a behav- ioral health coordinated system of crisis care (2025). URLhttps://library.samhsa.gov/ sites/default/files/national-guidelines-crisis-care-pep24-01-037.pdf. Accessed: 2026-03-02
2025
-
[52]
& Haug, P
Meystre, S. & Haug, P. J. Automation of a problem list using natural language processing. BMC Medical Informatics and Decision Making5, 30 (2005). URLhttps://doi.org/10. 1186/1472-6947-5-30
2005
-
[53]
Zhan, X., Humbert-Droz, M., Mukherjee, P. & Gevaert, O. Structuring clinical text with AI: Old versus new natural language processing techniques evaluated on eight common cardiovas- cular diseases.Patterns2, 100289 (2021). URLhttps://doi.org/10.1016/j.patter.2021. 100289
-
[54]
URLhttps://doi.org/10.1001/ jamanetworkopen.2025.53174
Nguyen, D.et al.Performance of an intelligent messaging tool for clinical communi- cations.JAMA Network Open9, e2553174 (2026). URLhttps://doi.org/10.1001/ jamanetworkopen.2025.53174
-
[55]
Automatica49(11), 3222–3233 (2013)
Sulieman, L.et al.Classifying patient portal messages using convolutional neural networks. Journal of Biomedical Informatics74, 59–70 (2017). URLhttps://doi.org/10.1016/j. jbi.2017.08.014
work page doi:10.1016/j 2017
-
[56]
Cronin, R. M., Fabbri, D., Denny, J. C., Rosenbloom, S. T. & Jackson, G. P. A com- parison of rule-based and machine learning approaches for classifying patient portal mes- sages.International Journal of Medical Informatics105, 110–120 (2017). URLhttps: //doi.org/10.1016/j.ijmedinf.2017.06.004. 20
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.