AgenticVBench: Can AI Agents Complete Real-World Post-Production Tasks?
Pith reviewed 2026-06-29 16:35 UTC · model grok-4.3
The pith
The strongest AI agent stack completes barely 30% of real-world video post-production tasks, far below human experts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
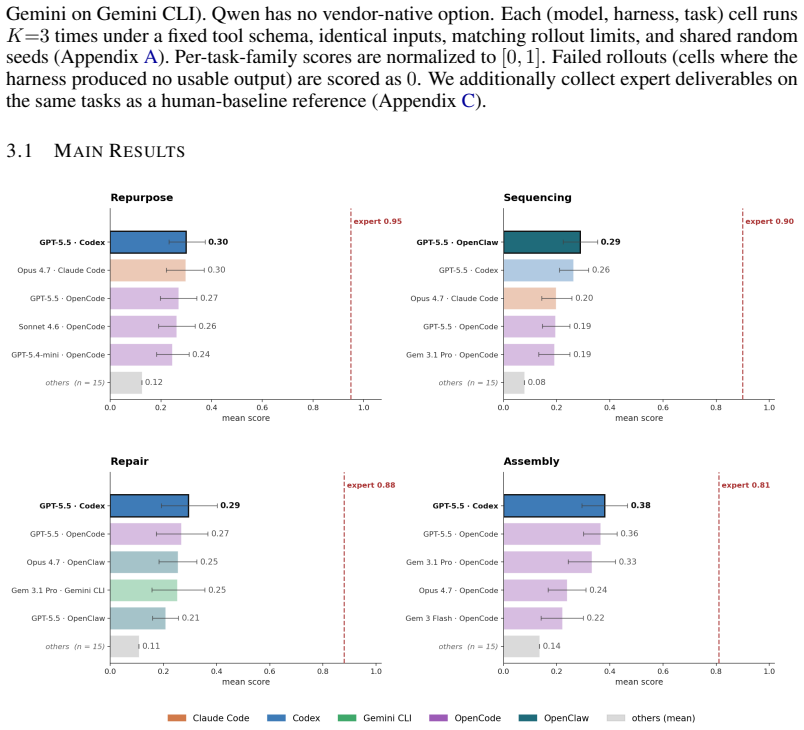
AgenticVBench supplies 100 tasks across four families that mirror real video post-production workflows contributed by twenty practicing experts. When frontier vision-language models are run through vendor-native and open-source harnesses, the best combination succeeds on barely 30 percent of the tasks. Human experts achieve markedly higher performance on the same tasks. Harness selection measurably changes scores, tool-use statistics, and failure modes.
What carries the argument
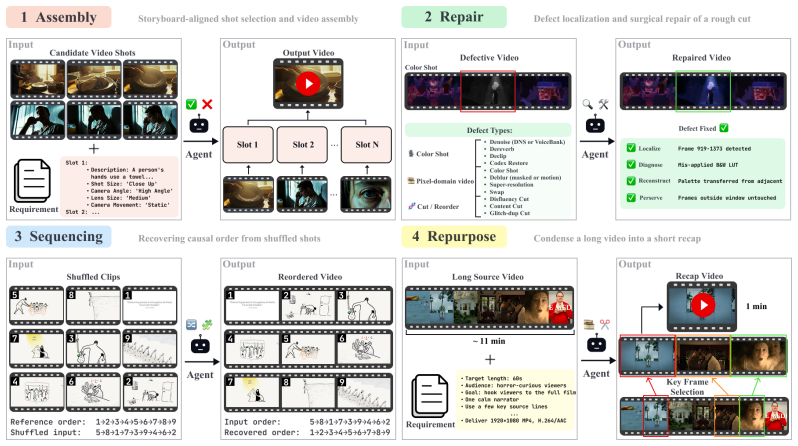
AgenticVBench, a benchmark of 100 tasks paired with programmatic verifiers and expert rubrics that together measure composite multimodal capabilities and long-horizon tool use.
If this is right
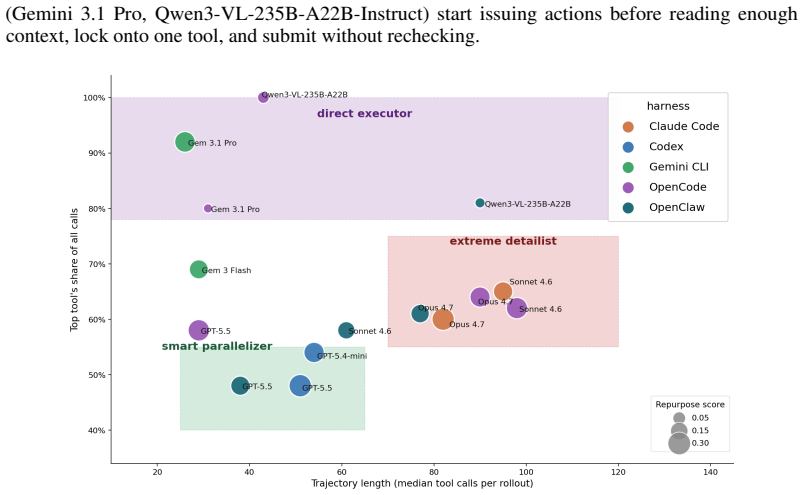
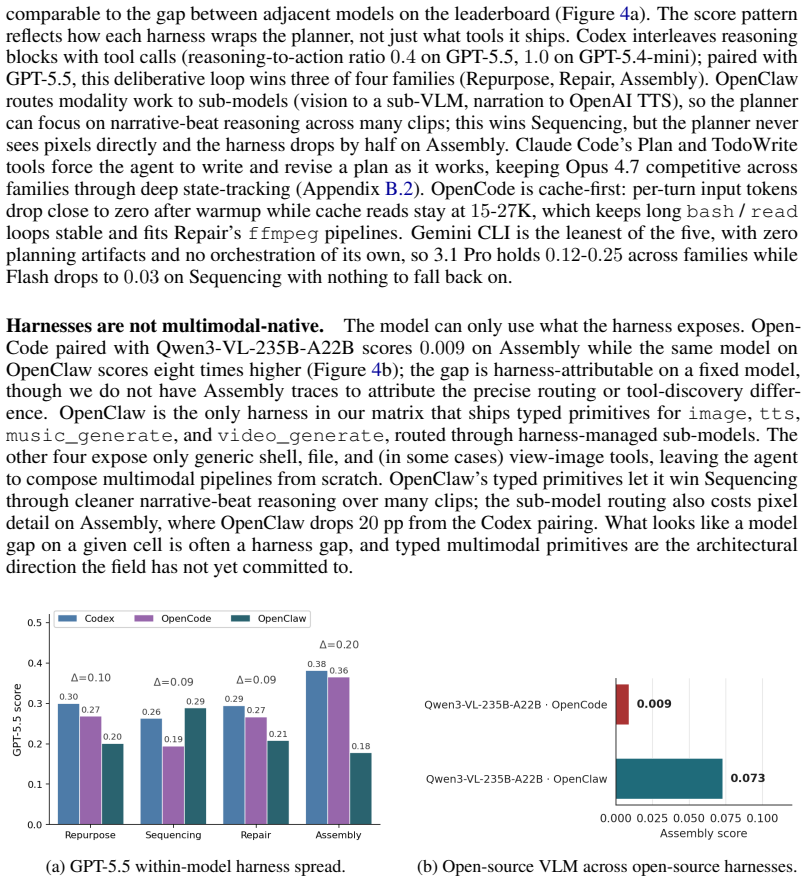
- Harness choice affects not only overall scores but also the specific tool-use patterns and failure modes observed in multimodal agents.
- Current frontier models and harnesses require substantial gains before they can reliably handle the composite demands of video post-production.
- The benchmark supplies concrete diagnostics that can guide targeted improvements to both models and harnesses.
- AgenticVBench supplies a reusable foundation for measuring progress on agentic capabilities in video production.
Where Pith is reading between the lines
- If the tasks capture typical production demands, practical deployment of AI agents in post-production will remain limited until success rates rise substantially.
- The observed sensitivity to harness suggests that engineering the interface layer may be as important as scaling the underlying models.
- The four task families could serve as a template for constructing similar benchmarks in other multimodal creative domains such as audio or 3D asset pipelines.
Load-bearing premise
The 100 tasks drawn from workflows contributed by twenty industry experts form a representative sample of real-world post-production demands.
What would settle it
An independent replication in which the same tasks are shown to omit central post-production operations or in which any agent stack exceeds 70 percent success on the full set would undermine the reported performance gap.
Figures

read the original abstract
Video production workflows offer a rich and demanding arena for evaluating multimodal AI agents: they require composite capabilities across text, image, audio, and video understanding, along with long-horizon planning, and tool use. To this end, we introduce AgenticVBench, a benchmark of 100 agentic tasks across 4 task families spanning the real world post-production workflow, constructed from real production workflows contributed by 20 industry experts averaging 6 years of professional experience. Tasks are paired with evaluation specifications that combine programmatic verifiers and expert rubrics. We evaluate frontier vision-language models (VLMs) with both vendor-native and open-source harnesses. The best evaluated agent stack barely crosses 30%, far below human expert performance on the same tasks. We further find that the choice of harness substantially affects model behavior, including scores, tool-use patterns, and failure modes. AgenticVBench provides a foundation for diagnosing and improving both models and harnesses for agentic video production. Benchmark website: https://agenticvbench.com.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces AgenticVBench, a benchmark of 100 agentic tasks across 4 task families in real-world video post-production workflows. Tasks are constructed from workflows contributed by 20 industry experts (avg. 6 years experience) and paired with programmatic verifiers plus expert rubrics. Frontier VLMs are evaluated using vendor-native and open-source agent harnesses; the best stack exceeds 30% success but remains far below human expert performance on the same tasks. Harness choice is shown to affect scores, tool-use patterns, and failure modes. The benchmark aims to support diagnosis and improvement of models and harnesses for agentic video tasks.
Significance. If the tasks are shown to be representative, the benchmark would provide a grounded evaluation instrument for multimodal long-horizon agent capabilities in a demanding domain. Strengths include grounding in expert-contributed workflows, dual programmatic/rubric evaluation, and the empirical finding that harness design materially changes agent behavior; these elements could usefully guide future model and framework development.
major comments (2)
- [Abstract] Abstract: The headline claim that the best agent stack 'barely crosses 30%' and lies 'far below human expert performance on the same tasks' is load-bearing on the 100 tasks constituting a representative sample of real-world post-production demands. The abstract states construction from workflows by 20 experts across 4 families but supplies no selection criteria, diversity controls (studio size, geography, project scale, tool ecosystems), or post-construction validation against clustering; without these, generalization of the performance gap cannot be assessed.
- [Abstract] Abstract: The 30% result and human comparison are presented without task definitions, exclusion criteria, inter-rater reliability statistics for the expert rubrics, or details on how the aggregate score was computed. These protocol elements are required to establish that the evaluation reliably supports the central performance claim.
minor comments (1)
- [Abstract] The manuscript would benefit from an explicit table or section cross-reference listing the four task families and the number of tasks per family to improve readability of the benchmark scope.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive comments. We address each major comment below and indicate where revisions to the abstract are feasible.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline claim that the best agent stack 'barely crosses 30%' and lies 'far below human expert performance on the same tasks' is load-bearing on the 100 tasks constituting a representative sample of real-world post-production demands. The abstract states construction from workflows by 20 experts across 4 families but supplies no selection criteria, diversity controls (studio size, geography, project scale, tool ecosystems), or post-construction validation against clustering; without these, generalization of the performance gap cannot be assessed.
Authors: The abstract is intentionally concise. The full manuscript (Section 3) explains that the 100 tasks were derived directly from workflows contributed by 20 industry experts (average 6 years experience) and organized into four families that cover core post-production stages. No formal selection criteria, geographic or studio-size stratification, or post-construction clustering validation are described because the benchmark prioritizes ecological validity from real contributed workflows over statistical sampling. The performance gap is reported specifically on these tasks rather than as a claim of universal representativeness. We will revise the abstract to explicitly note the expert-contributed origin and the four-family structure. revision: partial
-
Referee: [Abstract] Abstract: The 30% result and human comparison are presented without task definitions, exclusion criteria, inter-rater reliability statistics for the expert rubrics, or details on how the aggregate score was computed. These protocol elements are required to establish that the evaluation reliably supports the central performance claim.
Authors: Task definitions, exclusion criteria, and the computation of the aggregate success rate (mean across all 100 tasks) appear in Section 3 and Section 4 of the full manuscript, with additional detail in the appendix. Inter-rater reliability statistics for the rubrics were not collected; rubrics were co-developed with the contributing experts and paired with programmatic verifiers to increase objectivity. We will add a single sentence to the abstract summarizing the dual evaluation approach (programmatic verifiers plus expert rubrics) and the aggregate scoring method. revision: partial
Circularity Check
No significant circularity; benchmark is external measurement instrument
full rationale
The paper introduces AgenticVBench as an empirical benchmark of 100 tasks derived from 20 industry experts' workflows, paired with verifiers and rubrics, then reports direct evaluation results (best agent stack ~30%). No equations, fitted parameters, predictions, or derivation chains exist. No self-citations are load-bearing for the central claim. The representativeness assumption is external and falsifiable but does not reduce any result to its own inputs by construction. This matches the default non-circular case for benchmark papers.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Tasks contributed by 20 industry experts with average 6 years experience accurately capture real post-production workflows.
Forward citations
Cited by 1 Pith paper
-
EnterpriseClawBench: Benchmarking Agents from Real Workplace Sessions
EnterpriseClawBench is a benchmark for enterprise agents constructed from proprietary real-world sessions, with the reusable contribution being the construction and evaluation protocol rather than the data itself.
Reference graph
Works this paper leans on
-
[1]
Yinan Chen, Jiangning Zhang, Teng Hu, Yuxiang Zeng, Zhucun Xue, Qingdong He, Chengjie Wang, Yong Liu, Xiaobin Hu, and Shuicheng Yan. Ivebench: Modern benchmark suite for instruction-guided video editing assessment.arXiv preprint arXiv:2510.11647, 2025a. Yupeng Chen, Penglin Chen, Xiaoyu Zhang, Yixian Huang, and Qian Xie. Editboard: Towards a comprehensive...
-
[2]
Video-MME-v2: Towards the Next Stage in Benchmarks for Comprehensive Video Understanding
Chaoyou Fu, Haozhi Yuan, Yuhao Dong, Yi-Fan Zhang, Yunhang Shen, Xiaoxing Hu, Xueying Li, Jinsen Su, Chengwu Long, Xiaoyao Xie, et al. Video-mme-v2: Towards the next stage in benchmarks for comprehensive video understanding.arXiv preprint arXiv:2604.05015,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
VEFX-Bench: A Holistic Benchmark for Generic Video Editing and Visual Effects
Xiangbo Gao, Sicong Jiang, Bangya Liu, Xinghao Chen, Minglai Yang, Siyuan Yang, Mingyang Wu, Jiongze Yu, Qi Zheng, Haozhi Wang, et al. Vefx-bench: A holistic benchmark for generic video editing and visual effects.arXiv preprint arXiv:2604.16272,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Ziqi Huang, Yinan He, Jiashuo Yu, Fan Zhang, Chenyang Si, et al
Accessed: 2026-05-05. Ziqi Huang, Yinan He, Jiashuo Yu, Fan Zhang, Chenyang Si, et al. Vbench: Comprehensive benchmark suite for video generative models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 21807–21818,
2026
-
[5]
DIRECT: Video Mashup Creation via Hierarchical Multi-Agent Planning and Intent-Guided Editing
Ke Li, Maoliang Li, Jialiang Chen, Jiayu Chen, Zihao Zheng, Shaoqi Wang, and Xiang Chen. Direct: Video mashup creation via hierarchical multi-agent planning and intent-guided editing.arXiv preprint arXiv:2604.04875,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Zhengyang Liang, Daoan Zhang, Huichi Zhou, Rui Huang, Bobo Li, Yuechen Zhang, Shengqiong Wu, Xiaohan Wang, Jiebo Luo, Lizi Liao, et al. Univa: Universal video agent towards open-source next-generation video generalist.arXiv preprint arXiv:2511.08521,
-
[7]
Hongbo Liu, Jingwen He, Yi Jin, Dian Zheng, Yuhao Dong, Fan Zhang, Ziqi Huang, Yinan He, Yangguang Li, Weichao Chen, et al. Shotbench: Expert-level cinematic understanding in vision- language models.arXiv preprint arXiv:2506.21356,
-
[8]
MMAU: A Massive Multi-Task Audio Understanding and Reasoning Benchmark
Sakshi Sakshi, Utkarsh Tyagi, Sonal Kumar, Ashish Seth, Ramaneswaran Selvakumar, Oriol Nieto, Ramani Duraiswami, Sreyan Ghosh, and Dinesh Manocha. Mmau: A massive multi-task audio understanding and reasoning benchmark.arXiv preprint arXiv:2410.19168,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Seedance 2.0: Advancing Video Generation for World Complexity
Team Seedance, De Chen, Liyang Chen, Xin Chen, Ying Chen, Zhuo Chen, Zhuowei Chen, Feng Cheng, Tianheng Cheng, Yufeng Cheng, et al. Seedance 2.0: Advancing video generation for world complexity.arXiv preprint arXiv:2604.14148,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Bowen Song, Soo Min Kwon, Zecheng Zhang, Xinyu Hu, Qing Qu, and Liyue Shen. Solving inverse problems with latent diffusion models via hard data consistency.arXiv preprint arXiv:2307.08123,
-
[11]
Diffusion model-based video editing: A survey.arXiv preprint arXiv:2407.07111,
Wenhao Sun, Rong-Cheng Tu, Jingyi Liao, and Dacheng Tao. Diffusion model-based video editing: A survey.arXiv preprint arXiv:2407.07111,
-
[12]
Zihan Wang, Songlin Li, Lingyan Hao, Xinyu Hu, and Bowen Song. What you see is what matters: A novel visual and physics-based metric for evaluating video generation quality.arXiv preprint arXiv:2411.13609,
-
[13]
WebArena: A Realistic Web Environment for Building Autonomous Agents
Shuyan Zhou, Frank F. Xu, Hao Zhu, Xuhui Zhou, Robert Lo, et al. Webarena: A realistic web environment for building autonomous agents.arXiv preprint arXiv:2307.13854,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
no tts" [#2] shell pip install gtts←Google TTS fallback [#3] shell ffprobe film.mp4→6:20, 1920×1080, 24000/1001 fps [#5] shell cat > generate_tts_parts.py parts = [ (
Harness CLI versions are pinned by these images. Anthropic, OpenAI, and Google models are routed through each provider’s native API; Qwen is routed through OpenRouter. Harness npm package Version Models claude_code @anthropic-ai/ claude-code 2.1.129claude-opus-4-7, claude-sonnet-4-6 codex_cli @openai/codex0.128.0gpt-5.5, gpt-5.4-mini gemini_cli @google/ge...
1920
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.