Chain-based Adaptive Reconfiguration Over Lattices for Hallucination Reduction
Pith reviewed 2026-06-29 18:02 UTC · model grok-4.3
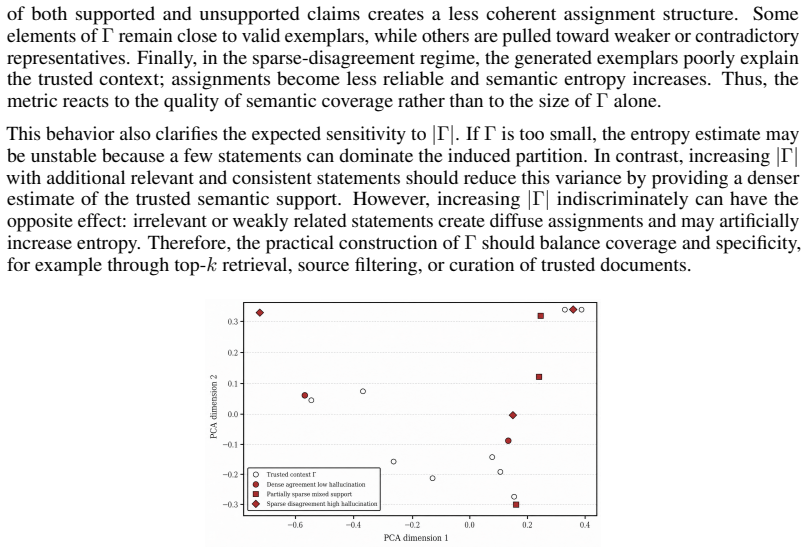
The pith
CAROL reduces hallucinations in large language models by casting semantic consistency as a string-submodular objective solved through Markov chain accept-reject steps over text lattices.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
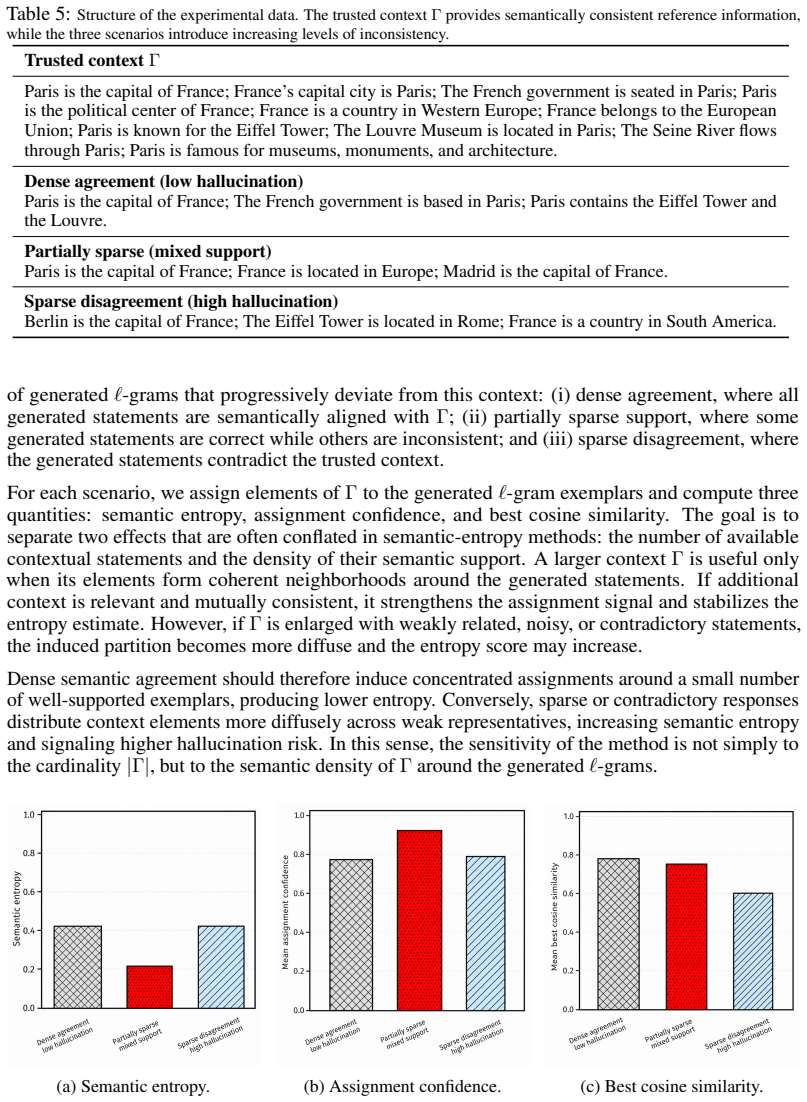
The paper establishes that semantic consistency with a trusted context induces a string-submodular objective over a lattice of textual sequences, which allows hallucination mitigation to be reformulated as a Markov chain accept-reject process possessing provable convergence and near-optimality properties.
What carries the argument
String-submodular objective over a lattice of textual sequences, which supports the Markov chain accept-reject reconfiguration process.
If this is right
- Hallucination mitigation operates directly on meaning rather than token likelihoods.
- Detection and mitigation become a single iterative process instead of separate stages.
- The method supplies explicit convergence guarantees for the refinement steps.
- Performance gains appear on both question-answering and multi-agent reasoning tasks.
- Computational cost stays comparable to existing baselines.
Where Pith is reading between the lines
- The lattice formulation could be tested on sequence tasks outside language, such as planning or program synthesis, if similar consistency measures can be defined.
- If string-submodularity holds for other uncertainty proxies, the same Markov chain machinery might apply to calibration or safety filtering in generative models.
- The trusted-context requirement suggests the method may work best in settings where reliable reference text is already available, such as retrieval-augmented systems.
Load-bearing premise
Semantic consistency between a generated response and a provided trusted context reliably signals the absence of hallucination and makes the objective string-submodular.
What would settle it
A dataset where multiple responses that score high on consistency with the trusted context nevertheless contain clear factual errors, or a run of the Markov chain that fails to reach the claimed near-optimal consistency level.
Figures














read the original abstract
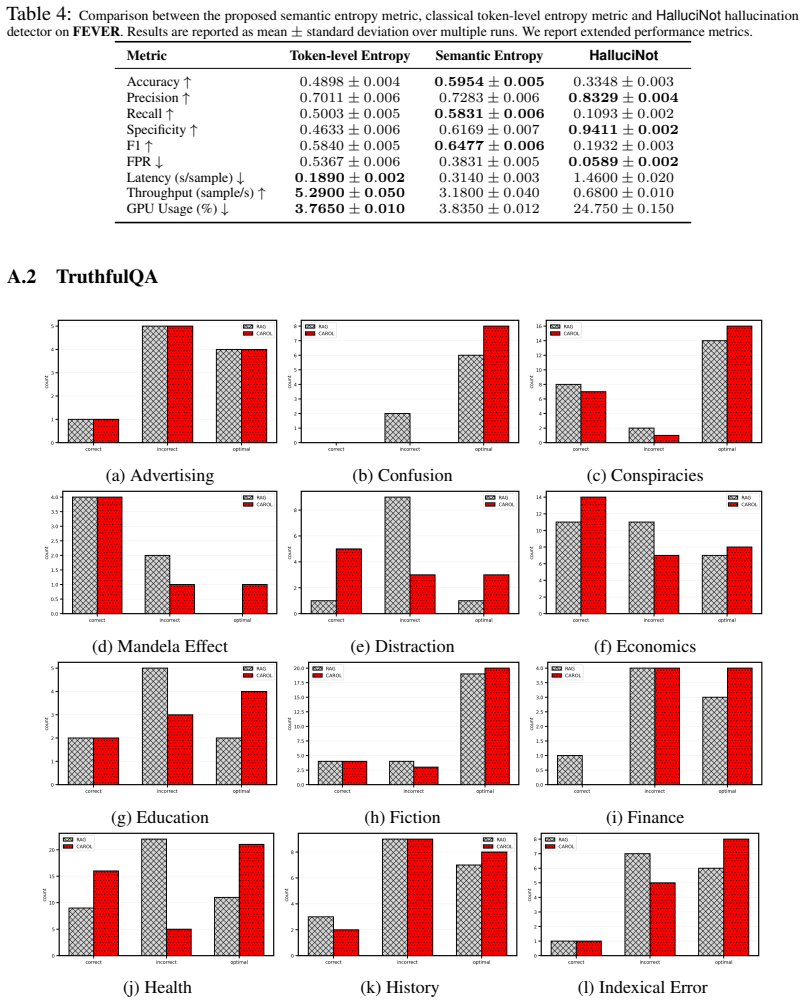
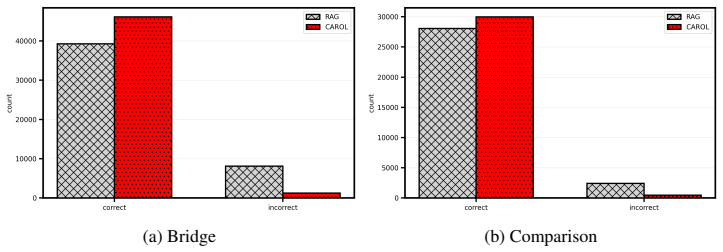
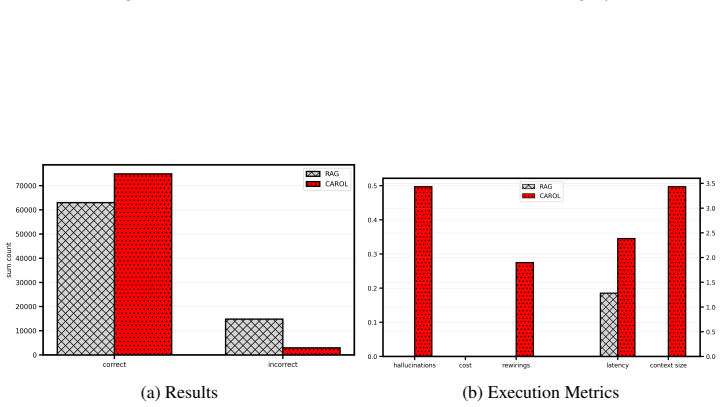
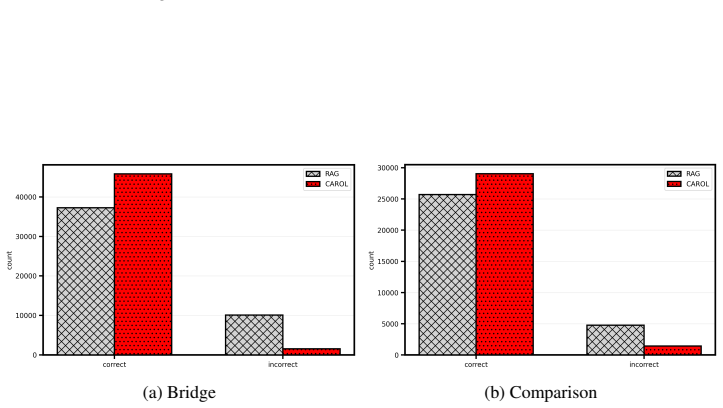
We introduce CAROL (Chain-based Adaptive Reconfiguration Over Lattices), a probabilistic framework for test-time hallucination reduction in large language models. Rather than relying on token-level uncertainty, CAROL defines a semantic uncertainty measure based on the consistency between generated responses and a trusted context, inducing a string-submodular objective over a lattice of textual sequences. This formulation enables hallucination mitigation to be cast as a Markov chain accept-reject process with provable convergence and near-optimality guarantees, allowing the model to iteratively refine outputs toward semantic consistency. By operating at the level of meaning, CAROL unifies hallucination detection and mitigation within a single framework. Empirical results on question answering and multi-agent reasoning benchmarks show that CAROL significantly reduces hallucinations and improves reliability and interpretability compared to likelihood-based and retrieval-augmented baselines, while maintaining competitive computational efficiency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CAROL, a probabilistic framework for test-time hallucination reduction in LLMs. It defines a semantic uncertainty measure from consistency between generated responses and a trusted context, inducing a string-submodular objective over a lattice of textual sequences. This allows casting hallucination mitigation as a Markov chain accept-reject process with claimed provable convergence and near-optimality guarantees. The approach unifies detection and mitigation at the semantic level. Empirical results on question answering and multi-agent reasoning benchmarks are reported to show significant hallucination reduction and improved reliability compared to likelihood-based and retrieval-augmented baselines, with competitive efficiency.
Significance. If the submodularity of the induced objective and the associated Markov chain convergence/near-optimality results hold, the work would offer a principled semantic-level alternative to token-level uncertainty methods for LLM reliability. The unification of detection and mitigation, along with the lattice-based formulation, could influence test-time adaptation techniques in NLP and multi-agent systems.
major comments (2)
- [Abstract] Abstract (paragraph describing the framework): the central claim that the semantic consistency measure 'induces a string-submodular objective' enabling 'provable convergence and near-optimality guarantees' for the Markov chain accept-reject process is load-bearing, yet no explicit definition of the measure, submodularity proof, or Markov chain analysis is supplied. This prevents verification of whether the guarantees follow from the construction.
- [Abstract] Abstract (empirical results sentence): the claim of 'significantly reduces hallucinations' on QA and multi-agent reasoning benchmarks is presented without reference to specific quantitative results, tables, baselines details, or error analysis, which is necessary to substantiate the practical improvement over likelihood-based and RAG methods.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the abstract. We address each point below and will revise the manuscript accordingly to improve clarity and substantiation of claims.
read point-by-point responses
-
Referee: [Abstract] Abstract (paragraph describing the framework): the central claim that the semantic consistency measure 'induces a string-submodular objective' enabling 'provable convergence and near-optimality guarantees' for the Markov chain accept-reject process is load-bearing, yet no explicit definition of the measure, submodularity proof, or Markov chain analysis is supplied. This prevents verification of whether the guarantees follow from the construction.
Authors: The abstract is a concise summary and does not contain the full technical details due to space constraints. The semantic consistency measure is explicitly defined in Section 3.1, string-submodularity is proven in Theorem 1 (Section 4), and the Markov chain accept-reject process with convergence and near-optimality analysis appears in Section 5 (with full proofs in Appendix A). We will revise the abstract to include a brief parenthetical reference to these sections so readers can immediately locate the supporting material. revision: yes
-
Referee: [Abstract] Abstract (empirical results sentence): the claim of 'significantly reduces hallucinations' on QA and multi-agent reasoning benchmarks is presented without reference to specific quantitative results, tables, baselines details, or error analysis, which is necessary to substantiate the practical improvement over likelihood-based and RAG methods.
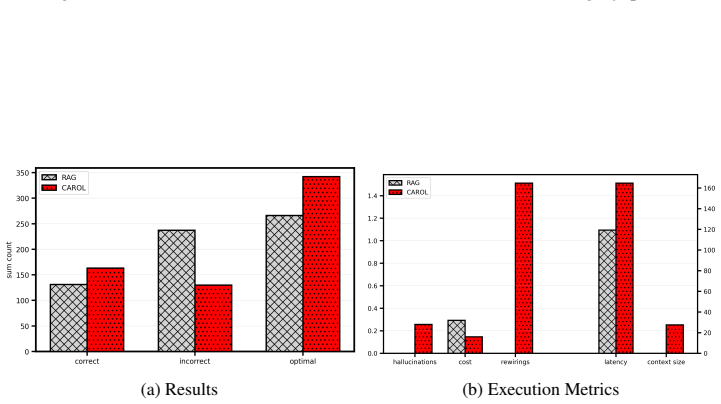
Authors: We agree the abstract would be stronger with more specificity. The quantitative results, including hallucination rate reductions, accuracy metrics, baseline comparisons (likelihood-based and RAG), and error analysis, are reported in Section 6 with Tables 1–3 and Figure 4. We will revise the abstract to reference these results and tables explicitly while keeping the summary concise. revision: yes
Circularity Check
No significant circularity
full rationale
The derivation defines a semantic uncertainty measure from consistency with a trusted context, induces a string-submodular objective over a lattice, and casts hallucination mitigation as a Markov chain accept-reject process. No quoted step reduces by construction to a fitted parameter, self-citation chain, or renamed input; the submodularity and convergence claims are positioned as following from the stated objective without internal reduction to the inputs themselves. The framework is therefore self-contained against external baselines.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption A trusted context exists and semantic consistency with it measures hallucination absence
- ad hoc to paper The semantic measure induces a string-submodular objective
invented entities (1)
-
CAROL framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Ian Davidson, Michael Livanos, Antoine Gourru, Peter Walker, Julien Velcin, and S
URLhttps://api.semanticscholar.org/CorpusID:18114361. Ian Davidson, Michael Livanos, Antoine Gourru, Peter Walker, Julien Velcin, and S. S. Ravi. Explainable clustering via exemplars: Complexity and efficient approximation algorithms, 2022. URLhttps://arxiv.org/abs/2209.09670. Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-tra...
-
[2]
URLhttps://arxiv.org/abs/2310.11324. James Thorne, Andreas Vlachos, Christos Christodoulopoulos, and Arpit Mittal. FEVER: A large- scale dataset for fact extraction and VERification. InProceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Tech- nologies, Volume 1 (Long Papers), St...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1109/cdc57313.2025.11312997 2018
-
[3]
arXiv preprint arXiv:2106.11426 (2021) https://doi.org/10.48550/arXiv
URLhttps://arxiv.org/abs/2311.07226. Zhenliang Zhang, Edwin K. P. Chong, Ali Pezeshki, and William Moran. String submodular functions with curvature constraints. 2013. doi: 10.48550/ARXIV .1303.3018. URL https: //arxiv.org/abs/1303.3018. 12 A Extended results In this appendix we present the breakdown of the results for each dataset. By looking closer at t...
work page internal anchor Pith review doi:10.48550/arxiv 2013
-
[4]
E.4 Equivalence of Algorithm 1 to Gibbs Sampling Remark E.1(Gibbs accept–reject step).Following Gotovos et al
result for greedy maximization under the cardinality constraint|S| ≤ℓyields f(S)≥(1−e −1)f(S ⋆), which proves the claim. E.4 Equivalence of Algorithm 1 to Gibbs Sampling Remark E.1(Gibbs accept–reject step).Following Gotovos et al. [2015], CAROL induces a distribu- tion over a finite candidate setVofℓ-grams, p(S)∝exp(βF(S)),S⊆V ∗, withF(S) =I(S; Γ). Given...
2015
-
[5]
ThePlannerprovides(q,Γ)
-
[6]
3.CAROLevaluatesS t via the submodular objective, Algorithm 1
TheResearchergenerates a candidate stringS t. 3.CAROLevaluatesS t via the submodular objective, Algorithm 1
-
[7]
fever", split=
TheReasoneraggregates accepted responses. Importantly, CAROL treats each Researcher output as a semantic unit (i.e., an ℓ-gram), aligning with the agent-level abstraction rather than token-level generation. Determinism and reproducibility.To ensure reproducibility, we enforce: • Fixed random seeds for all stochastic components (LLM sampling,CAROLacceptanc...
2080
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.