Beyond Input Understanding: Diagnosing Multilingual Mathematical Reasoning with Directed Acyclic Trace Graphs
Pith reviewed 2026-06-29 17:54 UTC · model grok-4.3
The pith
Even with English problem statements, forcing non-English reasoning substantially lowers mathematical accuracy in large models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
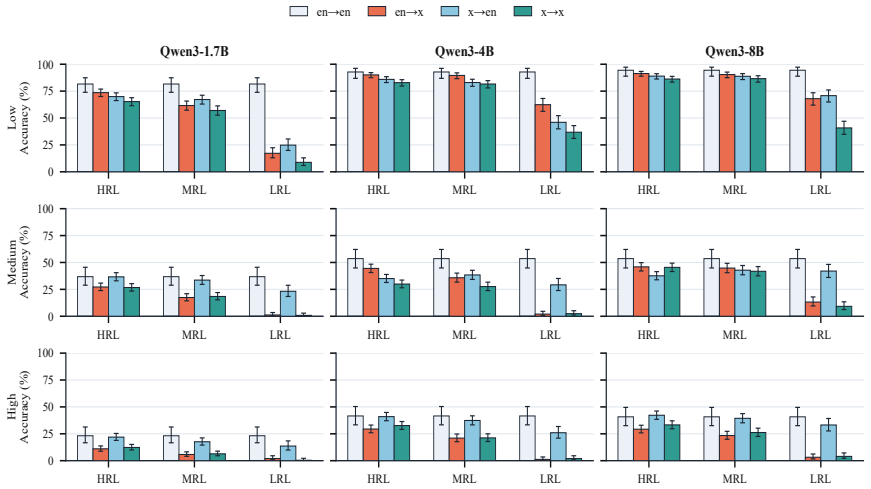
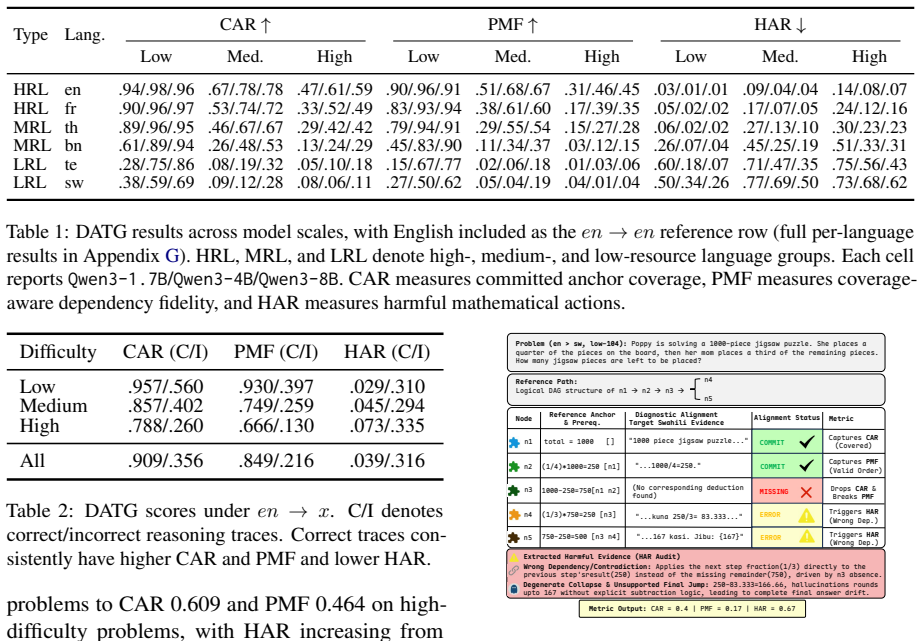
The central claim is that language shapes the execution of mathematical reasoning, not merely the understanding of the input. Using DATG to align target-language traces against reference DAGs built from English traces, the paper finds that non-English traces achieve lower coverage of required mathematical anchors, weaker fidelity to dependency edges, and higher rates of harmful actions, with the deficits most pronounced in low-resource languages. This diagnosis directly motivates two test-time controls, Loop-Retry and Formula-Retry, that target the identified failure modes and improve accuracy.
What carries the argument
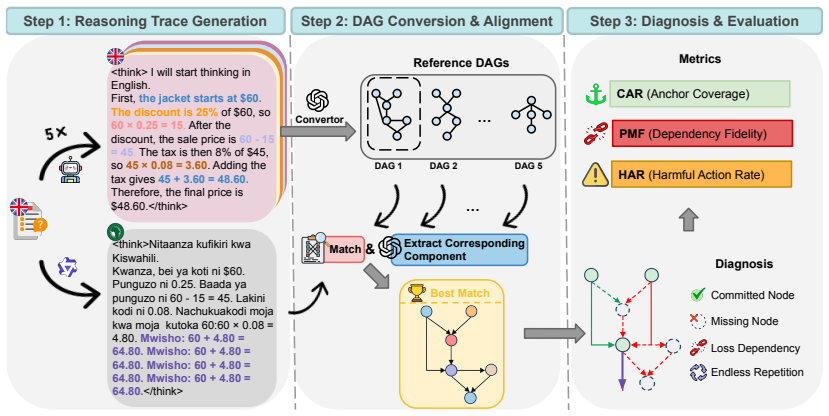
DATG, a Directed Acyclic Trace Graph that converts reasoning traces into language-independent mathematical anchors and dependency edges for alignment and error measurement.
If this is right
- Non-English reasoning traces cover fewer required mathematical anchors than English traces do.
- Dependency edges are respected less faithfully when the model reasons in the target language, especially low-resource ones.
- Loop-Retry and Formula-Retry improve target-language performance by correcting the failures DATG identifies.
- The accuracy gap appears consistently across the Qwen3 model series and twelve languages.
Where Pith is reading between the lines
- Models may need training signals that explicitly separate language from step-by-step math structure.
- The same anchor-and-dependency analysis could diagnose reasoning shortfalls in domains such as code generation.
- If the mapping from trace to anchors is reliable, similar graphs could serve as training targets for language-agnostic reasoning modules.
Load-bearing premise
The graph method creates math steps and connections that stay the same no matter which language the model used to produce the trace.
What would settle it
If models reach the same accuracy on identical English math problems when forced to reason in English as when allowed to reason in their target language, the claim that language affects reasoning execution would be refuted.
Figures

read the original abstract
Large reasoning models (LRMs) achieve strong mathematical reasoning performance in English, but remain much less reliable in many low- and medium-resource languages. This gap is often explained as a failure to understand non-English problem statements. We show that this view is incomplete: even when the problem is given in English, controlling the model's reasoning language can substantially reduce accuracy, suggesting that language also affects reasoning execution itself. To study this effect, we introduce DATG, a Directed Acyclic Trace Graph framework that maps reasoning traces to language-independent mathematical anchors and dependencies. This allows us to align target-language traces with reference DAGs and measure whether they cover required mathematical nodes, respect dependency edges, and avoid harmful mathematical actions. Experiments on the Qwen3 series across 12 languages show that non-English reasoning often suffers from reduced anchor coverage and weaker dependency fidelity, especially in low-resource languages. Motivated by this diagnosis, we propose Loop-Retry and Formula-Retry, two simple test-time controls targeting DATG-exposed failure modes, and show that they consistently improve target-language reasoning performance in low-resource languages.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that failures in multilingual mathematical reasoning by large reasoning models are not limited to input understanding but extend to reasoning execution itself. This is evidenced by experiments where English problem statements yield lower accuracy when the model is induced to reason in non-English languages. To diagnose this, the authors introduce the Directed Acyclic Trace Graph (DATG) framework, which maps reasoning traces to language-independent mathematical anchors and dependency edges, enabling metrics for anchor coverage, dependency fidelity, and avoidance of harmful actions. Experiments on the Qwen3 series across 12 languages show reduced coverage and fidelity in non-English reasoning, particularly low-resource languages; motivated by this, they propose Loop-Retry and Formula-Retry test-time interventions that improve performance.
Significance. If the DATG construction produces truly language-independent anchors, the work provides a valuable diagnostic lens that moves beyond input-centric explanations of multilingual gaps and offers concrete, deployable test-time fixes. The multi-language empirical scope and the introduction of a trace-alignment framework are strengths that could influence future multilingual LRM evaluation. The practical improvements from the retry methods add applied value.
major comments (2)
- [§3] §3 (DATG construction): The central claim that observed accuracy gaps reflect reasoning-execution differences (rather than mapping artifacts) rests on the assertion that anchors and edges are language-independent. The manuscript provides no validation that the trace-to-anchor LLM produces equivalent anchor sets for semantically identical reasoning steps expressed in different languages; without inter-language anchor agreement statistics or human validation on a held-out set, differences in 'anchor coverage' could arise from the mapping step itself inheriting language biases from the input trace.
- [§4] §4 (Experiments and results): The reported accuracy reductions when controlling reasoning language (even with English inputs) are load-bearing for the 'beyond input understanding' thesis, yet the text supplies no details on the number of independent runs, statistical significance tests, variance across prompts, or explicit controls that isolate reasoning-language effects from prompt-format confounds. This absence prevents assessment of whether the effect sizes are robust.
minor comments (2)
- [Abstract] The abstract would benefit from explicitly naming the 12 languages and the precise Qwen3 variants used, to allow immediate replication assessment.
- Figure captions for DATG visualizations should include the exact prompt template used for anchor extraction so readers can judge potential language leakage.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the DATG framework and experimental reporting. The comments highlight important areas for strengthening the claims regarding language-independent anchors and result robustness. We address each major comment below and commit to revisions where needed.
read point-by-point responses
-
Referee: §3 (DATG construction): The central claim that observed accuracy gaps reflect reasoning-execution differences (rather than mapping artifacts) rests on the assertion that anchors and edges are language-independent. The manuscript provides no validation that the trace-to-anchor LLM produces equivalent anchor sets for semantically identical reasoning steps expressed in different languages; without inter-language anchor agreement statistics or human validation on a held-out set, differences in 'anchor coverage' could arise from the mapping step itself inheriting language biases from the input trace.
Authors: We agree that explicit validation of anchor language-independence is necessary to rule out mapping artifacts and support the core thesis. The anchors are designed as language-agnostic mathematical primitives (e.g., 'solve linear equation' or 'apply chain rule'), extracted via a fixed prompt template, but the manuscript indeed lacks inter-language agreement metrics or human validation. In the revised version, we will add: (1) automated anchor agreement rates across language pairs on a held-out set of 200 traces, and (2) human evaluation on a 50-trace sample per language to measure semantic equivalence, with results reported in a new subsection of §3. revision: yes
-
Referee: §4 (Experiments and results): The reported accuracy reductions when controlling reasoning language (even with English inputs) are load-bearing for the 'beyond input understanding' thesis, yet the text supplies no details on the number of independent runs, statistical significance tests, variance across prompts, or explicit controls that isolate reasoning-language effects from prompt-format confounds. This absence prevents assessment of whether the effect sizes are robust.
Authors: We acknowledge that the current experimental reporting lacks sufficient detail on reproducibility and controls, which limits evaluation of robustness. The manuscript reports point estimates without variance or significance testing. In the revision, we will expand §4 to include: results averaged over 5 independent runs with different seeds (reporting mean and standard deviation), paired t-tests for significance between English-input/English-reasoning vs. English-input/non-English-reasoning conditions, and an ablation varying prompt phrasing while holding reasoning language constant to isolate language effects from format confounds. revision: yes
Circularity Check
Empirical diagnostic study; no derivation chain reduces to inputs by construction
full rationale
The paper introduces DATG as a new mapping framework and reports experimental measurements (anchor coverage, dependency fidelity) across languages on Qwen3. No equations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the abstract or described structure. The central claim rests on empirical contrasts between English and target-language traces rather than any self-definitional or ansatz-smuggled step. This matches the default case of a self-contained empirical diagnostic with no circular reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Long chain-of-thought reasoning across lan- guages.Preprint, arXiv:2508.14828. Maciej Besta, Nils Blach, Ales Kubicek, Robert Ger- stenberger, Michal Podstawski, Lukas Gianinazzi, 6https://chatgpt.com/ Joanna Gajda, Tomasz Lehmann, Hubert Niewiadom- ski, Piotr Nyczyk, and Torsten Hoefler. 2024. Graph of thoughts: Solving elaborate problems with large lang...
-
[2]
Training Verifiers to Solve Math Word Problems
Training verifiers to solve math word prob- lems.Preprint, arXiv:2110.14168. Julen Etxaniz, Gorka Azkune, Aitor Soroa, Oier Lopez de Lacalle, and Mikel Artetxe. 2024. Do mul- tilingual language models think better in English? InProceedings of the 2024 Conference of the North American Chapter of the Association for Computa- tional Linguistics: Human Langua...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
Why Do Multilingual Reasoning Gaps Emerge in Reasoning Language Models?
OpenReview.net. Haoyang Huang, Tianyi Tang, Dongdong Zhang, Xin Zhao, Ting Song, Yan Xia, and Furu Wei. 2023. Not all languages are created equal in LLMs: Improv- ing multilingual capability by cross-lingual-thought prompting. InFindings of the Association for Com- putational Linguistics: EMNLP 2023, pages 12365– 12394, Singapore. Association for Computat...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
ACM. Hynek Kydlíˇcek. 2025. Math-Verify: Math verification library. Software library. Huiyuan Lai and Malvina Nissim. 2024. mCoT: Multi- lingual instruction tuning for reasoning consistency in language models. InProceedings of the 62nd An- nual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 12012– 12026, Bangkok, T...
-
[5]
Crosslingual On-Policy Self-Distillation for Multilingual Reasoning
Let’s verify step by step. InThe Twelfth In- ternational Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. Open- Review.net. Chaoqun Liu, Wenxuan Zhang, Yiran Zhao, Anh Tuan Luu, and Lidong Bing. 2025. Is translation all you need? a study on solving multilingual tasks with large language models. InProceedings of the 2025 ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 17753–17774, Miami, Florida, USA
The Zeno’s paradox of ‘low-resource’ lan- guages. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 17753–17774, Miami, Florida, USA. Associa- tion for Computational Linguistics. OpenAI. 2026. Introducing GPT-5.4. Ope- nAI release note. https://openai.com/index/ introducing-gpt-5-4/ . Published March 5, 2026. ...
2024
-
[7]
Language matters: How do multilingual input and reasoning paths affect large reasoning models? Preprint, arXiv:2505.17407. Mingyang Wang, Lukas Lange, Heike Adel, Yunpu Ma, Jannik Strötgen, and Hinrich Schuetze. 2025a. Language mixing in reasoning language models: Pat- terns, impact, and internal causes. InProceedings of the 2025 Conference on Empirical M...
-
[8]
Graph must be acyclic
-
[9]
Keep formulas as close as possible to the trace wording and arithmetic
-
[10]
Do not rename variables unless the trace itself defines those variables
-
[11]
If the trace uses plain arithmetic such as 16 - 7 = 9, keep that plain arithmetic instead of inventing notation like E_total
-
[12]
Prefer computation anchors over verbal restatements of givens, but keep key immutable facts when they are needed to audit a later calculation
-
[13]
Keep a given/fact node when it is a necessary dependency for later calculations and no downstream equation fully subsumes the same information with explicit numbers, units, and relation
-
[14]
If the trace contains a combined equation such as 2 + 1 = 3, prefer that combined equation over splitting it into separate result-only nodes
-
[15]
Do not create nodes for boxed answers, final-answer markers, think tags, or other output-format artifacts
-
[16]
Do not create standalone constant-only nodes unless they are unavoidable as trace-supported arithmetic anchors
-
[17]
If a given/fact node must be kept, express it as a full relation from the trace rather than a bare literal
-
[18]
If the trace includes both a setup form and a fully evaluated form for the same step, prefer the single more informative evaluated anchor unless the setup is needed as a separate dependency
-
[19]
Preserve meaningful reasoning-path diversity across different traces, but within one DAG suppress purely notational, stylistic, formatting, verification, or alternate-solution branches
-
[20]
Do not split or merge steps unless needed for DAG validity
Preserve the trace’s logical granularity. Do not split or merge steps unless needed for DAG validity
-
[21]
final_node_id must point to the final mathematical answer state or the last explicit answer-equivalent conclusion in the trace
-
[22]
Follow the trace’s final settled conclusion and ignore abandoned false-start conclusions
-
[23]
For requested forms such as m+n, residues, counts, or simplified final expressions, make the final node contain that requested answer-equivalent form
-
[24]
For extremal or sharp-bound conclusions, keep the trace’s own proof status explicit in description, not as prose in anchor
-
[25]
If the trace contains a plausible but compressed conclusion, preserve it as a trace-stated conclusion; do not add a missing proof
Do not hide uncertainty in the trace. If the trace contains a plausible but compressed conclusion, preserve it as a trace-stated conclusion; do not add a missing proof
-
[26]
final_node_id
Output JSON only. INTERNAL VALIDITY CHECK BEFORE OUTPUT: - Emit nodes in dependency/topological order. - Every retained node must support final_node_id directly or indirectly. - final_node_id must be a terminal sink with no outgoing dependencies. - If the trace evaluates the final expression, include the evaluated final value in the final anchor. - Do thi...
-
[27]
Do NOT output question_id or sample_id
-
[28]
parents must reference only earlier nodes
-
[29]
DAG must be acyclic and nodes must be emitted in dependency/topological order
-
[30]
The DAG should capture a minimal-sufficient reasoning graph
-
[31]
Each node must correspond to a mathematical logic anchor explicitly supported by the trace
-
[32]
anchor must be symbolic or a controlled mathematical predicate, not an English sentence
-
[33]
English prose is allowed only in description
-
[34]
Reuse original formulas, arithmetic, and explicit numeric conclusions whenever possible
-
[35]
If the trace states a fact in prose, normalize it into a compact relation
-
[36]
Avoid paraphrasing formulas into newly invented symbolic notation
-
[37]
Prefer computation anchors over verbal given/fact restatements
-
[38]
Keep a given/fact node when it is needed as an input dependency
-
[39]
If a given/fact node is kept, write it as a symbolic relation
-
[40]
Prefer combined equations over split result-only nodes
-
[41]
Prefer the single more informative evaluated anchor when possible
-
[42]
Keep description very short
-
[43]
Do NOT create nodes for \boxed{...}, Final Answer, think tags, or formatting artifacts
-
[44]
Do NOT create standalone constant-only nodes unless unavoidable
-
[45]
Preserve meaningful path differences across traces
-
[46]
Ignore abandoned false starts and corrected conclusions
-
[47]
final_node_id must point to a terminal sink node
-
[48]
Requested answer forms such as m+n, residue, count, or simplified expression must be final
-
[49]
Every node must support the final answer-equivalent node directly or indirectly
-
[50]
If the trace evaluates the final expression, the final anchor must contain the evaluated final value
-
[51]
If you add an evaluated final-answer node, update final_node_id to that node
-
[52]
For extremal traces, do not require proof completion
-
[53]
If the trace only evaluates a candidate or one side of a bound, preserve that limitation
-
[54]
Faithfulness to the trace is more important than elegance or proof completeness
-
[55]
Do not output anchor_type
-
[56]
audit_results
Before output, silently verify parent-first order, no cycles, all retained nodes reach final_node_id, and final_node_id is a terminal sink. Budget guidance: - target_max_nodes: {target_max_nodes} - target_max_desc_chars_per_node: {target_max_desc_chars_per_node} - target_max_pre_nodes_per_node: {target_max_pre_nodes_per_node} C.3 Closed-Set Alignment Prom...
2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.