C-MIG: Multi-view Information Gain-based Retrieval-Augmented Generation for Clinical Diagnosis Reasoning
Pith reviewed 2026-06-29 12:41 UTC · model grok-4.3
The pith
C-MIG estimates information gain from retrieved documents and their refinements to jointly supervise retrieval and refinement in clinical diagnosis reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
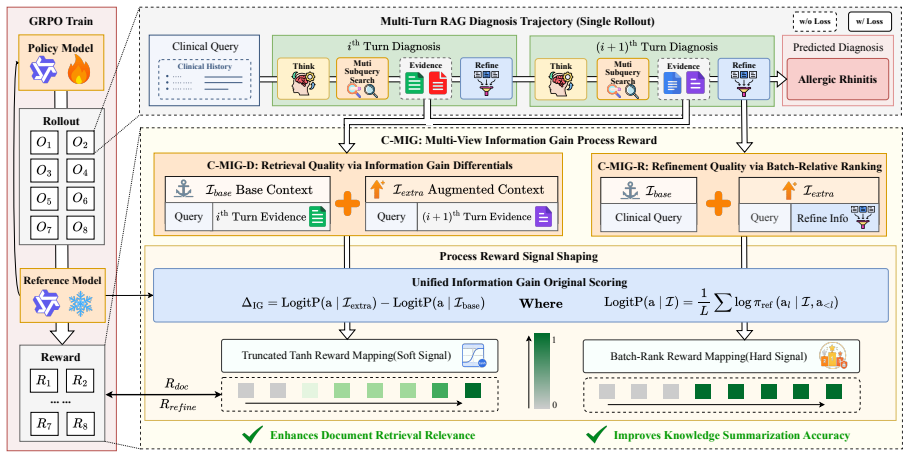
C-MIG estimates information gain under a frozen reference model from the retrieved-document view and the document-refinement view to jointly guide retrieval and refinement, thereby reducing loss of valuable learning signals from non-exact matches and improving credit assignment across heterogeneous clinical reasoning steps, while incorporating multi-subquery retrieval to boost knowledge recall coverage.
What carries the argument
Multi-view information gain estimation, which quantifies added value from both retrieved documents and their refinements to supply supervision signals for retrieval and refinement.
If this is right
- Semantically relevant but non-verbatim reasoning steps receive positive learning signals instead of zero reward.
- Heterogeneous reasoning capabilities receive multi-dimensional supervision rather than uni-dimensional binary feedback.
- Multi-subquery retrieval increases coverage of relevant medical knowledge in diagnostic queries.
- Performance improves on both in-domain and out-of-domain sets relative to prior RAG-RL methods.
- Clinical diagnosis accuracy exceeds that of state-of-the-art general-purpose large language models.
Where Pith is reading between the lines
- The same two-view information gain structure could be tested in other evidence-grounded domains such as legal case analysis or scientific hypothesis generation.
- Because the reference model remains frozen, periodic replacement with updated models may be needed to keep the gain estimates aligned with current medical knowledge.
- If the approach scales, it could support finer-grained evaluation of retrieval quality in any RAG system where exact string matches are poor proxies for usefulness.
Load-bearing premise
Information gain calculated from the two views under a frozen reference model can supervise retrieval and refinement without discarding useful signals or introducing new biases in clinical reasoning.
What would settle it
A controlled test on held-out clinical diagnosis cases in which C-MIG produces no accuracy improvement over binary-reward RAG-RL baselines despite higher measured information gain would show the multi-view signals fail to provide effective supervision.
Figures





read the original abstract
Retrieval-augmented generation combined with reinforcement learning has shown promise for grounding large language models in trustworthy medical evidence. However, existing methods rely on exact-match binary rewards, which in clinical diagnosis cause two issues: (i) semantically relevant but non-verbatim steps receive zero signal, discarding valuable learning signals; and (ii) uni-dimensional rewards cannot effectively supervise heterogeneous reasoning capabilities. To address these issues, we propose C-MIG, a Multi-view Information Gain-based retrieval-augmented generation framework for Clinical diagnosis. C-MIG estimates information gain under a frozen reference model from two complementary views, retrieved-document and document-refinement, to jointly guide what to retrieve and how to refine, alleviating the issues of valuable reward signal loss and credit assignment. We further design a multi-subquery retrieval augmentation strategy that improves knowledge recall coverage in clinical diagnostic scenarios. Comprehensive experiments on four medical benchmarks demonstrate that C-MIG achieves the best performance among all RAG-RL methods on both in-domain and out-of-domain sets, and outperforms state-of-the-art general-purpose LLMs for clinical diagnosis.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes C-MIG, a multi-view information gain-based RAG-RL framework for clinical diagnosis reasoning. It estimates information gain under a frozen reference model from retrieved-document and document-refinement views to jointly supervise retrieval and refinement, addressing the loss of learning signals from binary exact-match rewards and the limitations of uni-dimensional rewards for heterogeneous reasoning. A multi-subquery retrieval augmentation strategy is introduced to improve knowledge recall. Experiments on four medical benchmarks are claimed to show that C-MIG achieves the best performance among RAG-RL methods on both in-domain and out-of-domain sets while outperforming state-of-the-art general-purpose LLMs.
Significance. If the performance claims are substantiated with rigorous experiments, the approach could provide a more effective way to deliver dense, multi-dimensional supervision signals in RAG-RL for medical tasks, potentially improving the grounding and reliability of LLMs in clinical diagnosis without relying on verbatim matches.
major comments (2)
- Abstract: The central empirical claim (best performance among RAG-RL methods and outperformance of SOTA LLMs) is asserted without any description of experimental setup, baselines, datasets, statistical tests, error analysis, or ablation studies. This absence prevents evaluation of whether the reported gains are robust or load-bearing for the contribution.
- Abstract (Methods description): The information-gain reward is defined with respect to a frozen reference model; without the full methods section it remains unclear whether the multi-view estimates are independent of the fitting process or risk circularity in credit assignment for heterogeneous clinical reasoning steps.
Simulated Author's Rebuttal
We thank the referee for their comments. We address the major comments point by point below.
read point-by-point responses
-
Referee: Abstract: The central empirical claim (best performance among RAG-RL methods and outperformance of SOTA LLMs) is asserted without any description of experimental setup, baselines, datasets, statistical tests, error analysis, or ablation studies. This absence prevents evaluation of whether the reported gains are robust or load-bearing for the contribution.
Authors: Abstracts are concise summaries by design and do not include full experimental details. The manuscript provides comprehensive descriptions of the experimental setup, baselines, datasets (four medical benchmarks), ablations, and analyses in Sections 4 and 5, including in-domain and out-of-domain evaluations. The performance claims are substantiated with these results. We do not view changes to the abstract as necessary. revision: no
-
Referee: Abstract (Methods description): The information-gain reward is defined with respect to a frozen reference model; without the full methods section it remains unclear whether the multi-view estimates are independent of the fitting process or risk circularity in credit assignment for heterogeneous clinical reasoning steps.
Authors: The abstract states that information gain is estimated under a frozen reference model. This design choice ensures the estimates are independent of the policy being optimized during training, with the reference model held fixed to provide stable supervision. The multi-view estimates (retrieved-document and document-refinement) therefore introduce no circularity in credit assignment. Full details appear in the Methods section. revision: no
Circularity Check
No significant circularity; empirical claims rest on benchmarks, not self-referential derivation
full rationale
The paper introduces C-MIG as a framework that computes information gain from a frozen reference model across two views to supervise retrieval and refinement in RAG-RL. All load-bearing claims concern measured performance on four medical benchmarks (in-domain and out-of-domain), not a closed mathematical derivation. No equations, fitted parameters renamed as predictions, self-citations used to justify uniqueness, or ansatzes smuggled via prior work appear in the text. The reward signal is explicitly external (frozen model) and the evaluation is benchmark-driven, rendering the method self-contained against external data rather than reducing to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Exact-match binary rewards discard valuable learning signals for semantically relevant but non-verbatim reasoning steps in clinical diagnosis.
- domain assumption Uni-dimensional rewards cannot effectively supervise heterogeneous reasoning capabilities.
Reference graph
Works this paper leans on
-
[1]
Baichuan 2: Open Large-scale Language Models
Baichuan 2: Open large-scale lan- guage models.arXiv preprint arXiv:2309.10305. Junying Chen, Xidong Wang, Anningzhe Gao, Feng Jiang, Shunian Chen, Hongbo Zhang, Dingjie Song, Wenya Xie, Chuyi Kong, Jianquan Li, Xiang Wan, Haizhou Li, and Benyou Wang
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Huatuogpt- ii, one-stage training for medical adaption of llms. Preprint, arXiv:2311.09774. Mingyang Chen and 1 others. 2025a. Research: Learn- ing to reason with search for llms via reinforcement learning. InAdvances in Neural Information Pro- cessing Systems (NeurIPS). Qiang Chen and 1 others. 2025b. Lets: Learning to think-and-search via process-and-ou...
-
[3]
Med42-v2: A suite of clinical llms.arXiv preprint arXiv:2408.06142. DeepSeek-AI
-
[4]
Arsene Fansi Tchango, Rishab Goel, Zhi Wen, Julien Martel, and Joumana Ghosn
Baichuan- m2: Scaling medical capability with large verifier system.arXiv preprint arXiv:2509.02208. Arsene Fansi Tchango, Rishab Goel, Zhi Wen, Julien Martel, and Joumana Ghosn
-
[5]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948. Lei Huang, Weijiang Yu, Weitao Ma, Weihong Zhong, Zhangyin Feng, Haotian Wang, Qianglong Chen, Weihua Peng, Xiaocheng Feng, Bing Qin, and 1 oth- ers
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning
Search-r1: Training llms to rea- son and leverage search engines with reinforcement learning.arXiv preprint arXiv:2503.09516. Di Jin, Eileen Pan, Nassim Oufattole, Wei-Hung Weng, Hanyi Fang, and Peter Szolovits
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
What dis- ease does this patient have? a large-scale open do- main question answering dataset from medical ex- ams.arXiv preprint arXiv:2009.13081. Diederik P. Kingma and Jimmy Ba
-
[8]
UR$^2$: Unify RAG and Reasoning through Reinforcement Learning
Adam: A method for stochastic optimization. InInternational Conference on Learning Representations (ICLR). 9 Jiwoong Li and 1 others. 2025a. Rationale-guided re- trieval augmented generation for medical question answering. InProceedings of the 2025 Conference of the North American Chapter of the Association for Computational Linguistics (NAACL). Siran Li,...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Ehr-r1: A reasoning-enhanced foundational language model for electronic health record analysis.arXiv preprint arXiv:2510.25628. Keer Lu, Zheng Liang, Youquan Li, Jiejun Tan, Xili Wang, Da Pan, Shusen Zhang, Guosheng Dong, Bin Cui, Yunhuai Liu, and 1 others
-
[10]
Med-r 3: En- hancing medical retrieval-augmented reasoning of llms via progressive reinforcement learning.arXiv preprint arXiv:2507.23541. Shiwei Lyu, Chenfei Chi, Hongbo Cai, Lei Shi, Xiaoyan Yang, Lei Liu, Xiang Chen, Deng Zhao, Zhiqiang Zhang, Xianguo Lyu, Ming Zhang, Fangzhou Li, Xiaowei Ma, Yue Shen, Jinjie Gu, Wei Xue, and Yiran Huang
-
[11]
Rjua-qa: A comprehensive qa dataset for urology.Preprint, arXiv:2312.09785. Siqi Ma, Jiajie Huang, Fan Zhang, Jinlin Wu, Yue Shen, Guohui Fan, Zhu Zhang, and Zelin Zang
-
[12]
InInternational Conference on Learning Represen- tations, volume 2025, pages 66880–66913
Llms know more than they show: On the intrinsic representation of llm hallucinations. InInternational Conference on Learning Represen- tations, volume 2025, pages 66880–66913. Qi Peng, Jialin Cui, Jiayuan Xie, Yi Cai, and Qing Li
2025
-
[13]
Qwen2.5 technical report.Preprint, arXiv:2412.15115. Stephen E. Robertson and Steve Walker
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
R1-Searcher: Incentivizing the Search Capability in LLMs via Reinforcement Learning
R1-searcher: Incentivizing the search capability in llms via reinforcement learning. arXiv preprint arXiv:2503.05592. Guoqing Wang, Sunhao Dai, Guangze Ye, Zeyu Gan, Wei Yao, Yong Deng, Xiaofeng Wu, and Zhenzhe Ying. 2025a. Information gain-based policy opti- mization: A simple and effective approach for multi- turn llm agents.arXiv preprint arXiv:2510.14...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
Guangzhi Xiong, Qiao Jin, Zhiyong Lu, and Aidong Zhang
Mmedagent-rl: Optimizing multi-agent collaboration for multimodal medical reasoning.arXiv preprint arXiv:2506.00555. Guangzhi Xiong, Qiao Jin, Zhiyong Lu, and Aidong Zhang
-
[16]
InFindings of the Asso- ciation for Computational Linguistics, ACL 2024,, Findings of ACL, pages 6233–6251
Benchmarking retrieval-augmented generation for medicine. InFindings of the Asso- ciation for Computational Linguistics, ACL 2024,, Findings of ACL, pages 6233–6251. Association for Computational Linguistics. Guangzhi Xiong, Qiao Jin, Xiao Wang, Yin Fang, Haolin Liu, Yifan Yang, Fangyuan Chen, Zhixing Song, Dengyu Wang, Minjia Zhang, and 1 oth- ers
2024
-
[17]
Supervising the search process produces reliable and generalizable information-seeking agents
Rag-gym: Systematic optimization of language agents for retrieval-augmented generation. arXiv preprint arXiv:2502.13957. Jiashuo Xu and 1 others. 2025a. Dynamicrag: Lever- aging outputs of large language model as feedback for dynamic reranking in retrieval-augmented gener- ation. InAdvances in Neural Information Processing Systems (NeurIPS). Xuejiao Xu an...
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
R-search: Empowering llm rea- soning with search via multi-reward reinforcement learning.arXiv preprint arXiv:2506.04185. Qiaoyu Zheng, Yuze Sun, Chaoyi Wu, Weike Zhao, Pengcheng Qiu, Yongguo Yu, Kun Sun, Jian Zhang, Yanfeng Wang, Ya Zhang, and 1 others
-
[19]
End- to-end agentic rag system training for traceable diag- nostic reasoning.arXiv preprint arXiv:2508.15746. Yuxin Zuo, Shang Qu, Yifei Li, Zhangren Chen, Xuekai Zhu, Ermo Hua, Kaiyan Zhang, Ning Ding, and Bowen Zhou
-
[20]
MedXpertQA: Benchmarking Expert-Level Medical Reasoning and Understanding
Medxpertqa: Benchmarking expert-level medical reasoning and understanding. arXiv preprint arXiv:2501.18362. 11 A Prompt The prompt template used for rollout generation is given as follows: Prompt Template for Rollout Generation You are an expert physician skilled in clinical diagnosis with multi-turn search engine calling. To answer questions, you must fi...
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[21]
Non-linear Reward Composition.Following AutoRefine (Shi et al., 2026), we adopt a non- linear reward composition strategy rather than a simple linear summation
is motivated by the observation that in medical retrieval scenarios, reward signals are inherently sparse and models tend to collapse into single-turn retrieval without sufficient process-level supervi- sion. Non-linear Reward Composition.Following AutoRefine (Shi et al., 2026), we adopt a non- linear reward composition strategy rather than a simple linea...
2026
-
[22]
as the training dataset, which covers clinical diag- nostic scenarios across multiple specialties, with each sample consisting of a patient symptom de- scription and its corresponding standard diagnostic label. We uniformly sample 8,998 instances for training and 1,003 instances for validation from the original dataset. To comprehensively evaluate the gen...
-
[23]
KG rewards correct disease-family iden- tification while remaining agnostic to within- category severity differences—a deliberate design choice complemented by strict EM evaluation. • Embedding Similarity (Emb).We compute the cosine similarity between diagnosis em- beddings obtained from PubMedBERT (Gu et al., 2021), with a threshold τ= 0.6 to sup- press ...
2021
-
[24]
We can draw the following observations: (1) w/ Ref consistently outperforms w/ Pol- icy across all backbones, yielding overall aver- age improvements ranging from +0.02 to +8.90, 15 Backbone Methods MedDDx-Plus MedQA MedXpertQA RJUA OverallAvgEM KG Avg EM KG Avg EM KG Avg EM KG Avg Qwen2.5-3B C-MIG-R w/ Policy 43.17 49.55 46.36 5.50 12.20 8.854.95 11.52 8...
-
[25]
AutoRefine-ICDTree, yielding overall average improvements ranging from +0.71 to +4.94
We can draw the following conclusions: (1) Across all four backbones, bothw/ ∆(sRefine) andw/ ∆(sDoc) consistently outperform 16 Methods MedDDx-Plus MedQA MedXpertQA RJUA Overall Avg EM KG Avg EM KG Avg EM KG Avg EM KG Avg Qwen2.5-3B AutoRefine-ICDTree 43.87 64.09 53.98 3.00 12.60 7.80 4.95 9.86 7.40 9.0026.30 17.6821.72 w/∆(s Ref ine)52.54 68.85 60.69 5....
-
[26]
What are the symptoms of allergic rhinitis in pa- tients with a family history of allergies?
This case qualitatively demonstrates how the multi- subquery decomposition and multi-view informa- tion gain in C-MIG jointly enable robust diagnostic reasoning. 17 Backbone Method MedDDx-Plus MedQA MedXpertQA RJUA Overall Avg EM KG Avg EM KG Avg EM KG Avg EM KG Avg Qwen2.5-3B AutoRefineBase 48.65 51.47 50.06 7.00 12.00 9.50 3.96 8.51 6.23 8.53 24.35 16.4...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.