SKILLC: Learning Autonomous Skill Internalization in LLM Agents via Contrastive Credit Assignment
Pith reviewed 2026-06-29 13:09 UTC · model grok-4.3
The pith
SkillC converts task-level contrasts between skill-injected and skill-free rollouts into a direct policy update signal for autonomous LLM agent performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
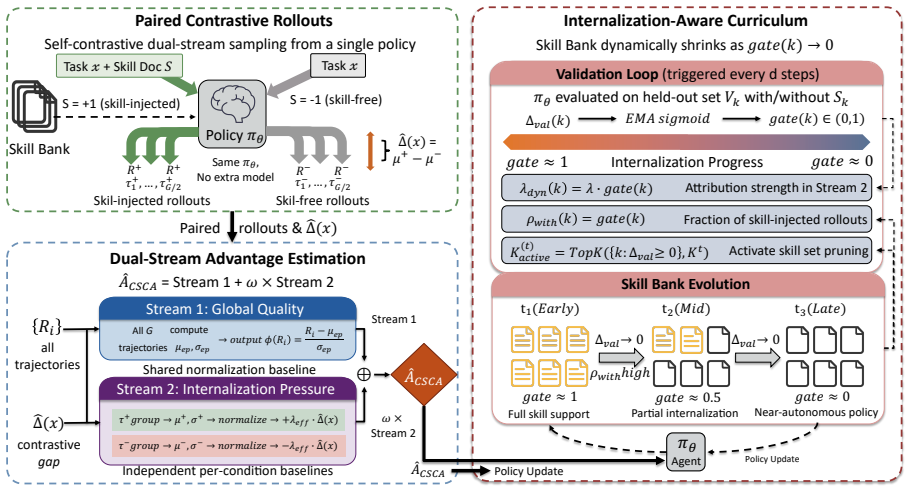
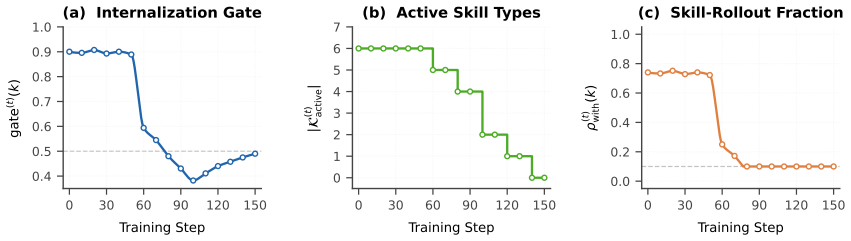
SkillC samples paired skill-injected and skill-free rollouts for tasks from active skill types within the same policy update, and injects their task-level contrast into optimization via a dual-stream advantage estimator that preserves global ranking while applying a one-sided correction toward skill-free success. A smoothed validation-level signal further drives an adaptive curriculum over attribution strength, rollout allocation, and monotonic active-set pruning.
What carries the argument
Contrastive Skill Credit Assignment (CSCA) implemented through a dual-stream advantage estimator that applies a one-sided correction toward skill-free success while preserving global ranking.
If this is right
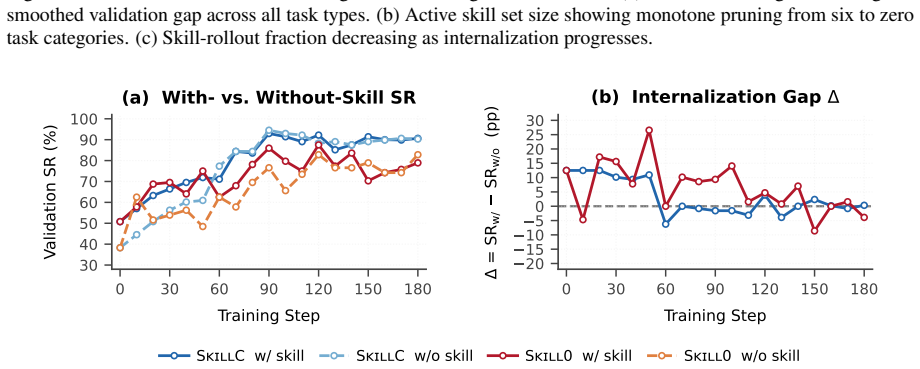
- Without runtime skill access, SkillC surpasses the strongest prior skill-internalization RL baseline by 5.5% on ALFWorld and 4.4% on WebShop.
- SkillC remains competitive with skill-augmented RL methods that retain external skills at inference time.
- The dual-stream estimator distinguishes skill-dependent success from autonomous success during policy updates.
- The adaptive curriculum uses validation signals to adjust attribution strength, rollout allocation, and active skill set size.
- Monotonic active-set pruning progressively removes skills once their contrast signal weakens.
Where Pith is reading between the lines
- The paired-rollout contrast mechanism could be applied in other RL settings where auxiliary information is available only during training.
- If the estimator isolates skill effects cleanly, similar contrastive signals might reduce the need for hand-designed curricula across agent benchmarks.
- Extending the approach to environments with noisier or partial skill prompts would test whether the one-sided correction remains effective.
Load-bearing premise
The task-level contrast between paired skill-injected and skill-free rollouts, when injected via the dual-stream advantage estimator, reliably distinguishes and promotes autonomous success rather than merely reflecting variance in rollout quality or policy stochasticity.
What would settle it
An ablation on ALFWorld or WebShop in which the dual-stream estimator is replaced by a standard advantage estimator that ignores the skill contrast, yet SkillC still shows the reported gains over prior internalization baselines.
Figures



read the original abstract
Structured skill prompts improve exploration in long-horizon agentic reinforcement learning (RL). Skill-augmented RL methods retain external skills at inference, while skill-internalization RL methods withdraw them during training to enable autonomous performance. However, existing internalization approaches only use skill-helpfulness contrast for curriculum control, leaving the policy update unchanged and unable to distinguish skill-dependent from autonomous success. We propose SkillC, a framework based on Contrastive Skill Credit Assignment (CSCA) that converts this contrast into a direct learning signal for internalization. \textsc{SkillC} samples paired skill-injected and skill-free rollouts for tasks from active skill types within the same policy update, and injects their task-level contrast into optimization via a dual-stream advantage estimator that preserves global ranking while applying a one-sided correction toward skill-free success. A smoothed validation-level signal further drives an adaptive curriculum over attribution strength, rollout allocation, and monotonic active-set pruning. Experiments on ALFWorld and WebShop show that, without runtime skill access, SkillC surpasses the strongest prior skill-internalization RL baseline by 5.5\% and 4.4\%, respectively, while remaining competitive with skill-augmented RL methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SkillC, a framework for autonomous skill internalization in LLM agents via Contrastive Skill Credit Assignment (CSCA). It samples paired skill-injected and skill-free rollouts from the same policy, injects their task-level contrast into a dual-stream advantage estimator that preserves global ranking with one-sided correction toward skill-free success, and uses a smoothed validation signal for adaptive curriculum, attribution strength, rollout allocation, and active-set pruning. On ALFWorld and WebShop, SkillC outperforms the strongest prior internalization RL baseline by 5.5% and 4.4% without runtime skill access while remaining competitive with skill-augmented RL methods.
Significance. If the central performance claims hold under rigorous controls, the work supplies a direct learning signal for internalization that prior methods lacked, converting external skill contrast into policy updates rather than mere curriculum control. This could meaningfully advance autonomous long-horizon agents by reducing reliance on runtime skill prompts.
major comments (2)
- [CSCA mechanism / dual-stream advantage estimator] The dual-stream advantage estimator (described in the abstract and the CSCA mechanism) applies a one-sided correction toward skill-free success while preserving global ranking. However, in low-success-rate, high-variance environments such as ALFWorld and WebShop, nothing in the stated construction (global ranking + one-sided correction + smoothed validation) prevents reinforcement of stochastic skill-free successes rather than internalized policy improvement. This directly affects whether the reported 5.5% and 4.4% gains can be attributed to credit assignment.
- [Experiments on ALFWorld and WebShop] The experimental claims rest on single reported success rates without mention of multiple independent seeds, error bars, or ablation on rollout stochasticity (e.g., repeated sampling of skill-free trajectories per task). If the estimator credits lucky autonomous trajectories, the comparison to prior internalization baselines becomes unreliable.
minor comments (2)
- Notation for the dual-stream advantage estimator and the smoothed validation signal should be formalized with explicit equations rather than prose description.
- The abstract states that the method 'remains competitive with skill-augmented RL methods,' but the precise baselines and whether they use the same number of environment steps should be clarified in the experimental section.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major comment below and indicate planned revisions where appropriate.
read point-by-point responses
-
Referee: [CSCA mechanism / dual-stream advantage estimator] The dual-stream advantage estimator (described in the abstract and the CSCA mechanism) applies a one-sided correction toward skill-free success while preserving global ranking. However, in low-success-rate, high-variance environments such as ALFWorld and WebShop, nothing in the stated construction (global ranking + one-sided correction + smoothed validation) prevents reinforcement of stochastic skill-free successes rather than internalized policy improvement. This directly affects whether the reported 5.5% and 4.4% gains can be attributed to credit assignment.
Authors: The paired rollout structure samples skill-injected and skill-free trajectories from the identical policy state, so the task-level contrast directly compares outcomes under matched conditions rather than independent stochastic draws. The dual-stream estimator preserves the global ranking across all trajectories while the one-sided correction only augments the advantage for skill-free successes that exceed their paired skill-injected counterpart; this prevents isolated lucky skill-free trajectories from receiving inflated credit unless they demonstrate superiority relative to the skill-injected baseline. The smoothed validation signal further modulates attribution strength and rollout allocation to dampen high-variance effects. We will add a clarifying subsection in the revised manuscript that formalizes this argument with a short derivation showing the bounded influence of stochastic outliers under the paired construction. revision: partial
-
Referee: [Experiments on ALFWorld and WebShop] The experimental claims rest on single reported success rates without mention of multiple independent seeds, error bars, or ablation on rollout stochasticity (e.g., repeated sampling of skill-free trajectories per task). If the estimator credits lucky autonomous trajectories, the comparison to prior internalization baselines becomes unreliable.
Authors: We agree that the current presentation reports aggregate success rates without explicit multi-seed statistics or stochasticity ablations. In the revised manuscript we will rerun the ALFWorld and WebShop evaluations across at least five independent random seeds, report means with standard deviations, and include an ablation that repeats skill-free trajectory sampling per task to quantify sensitivity to rollout variance. revision: yes
Circularity Check
No significant circularity; derivation and evaluation are self-contained
full rationale
The provided abstract and context describe an empirical RL framework (CSCA with dual-stream advantage estimator, paired rollouts, and adaptive curriculum) evaluated on external benchmarks ALFWorld and WebShop. No equations, fitted parameters, or self-citations are shown that reduce any reported prediction or gain to a quantity defined by the method itself. The performance claims rest on external task success rates rather than internal redefinitions or tautologies, satisfying the default expectation of non-circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Graph-of-Skills: Dependency-Aware Structural Retrieval for Massive Agent Skills
Group-in-group policy optimization for llm agent training.Advances in Neural Information Pro- cessing Systems, 38:46375–46408. Dawei Li, Zongxia Li, Hongyang Du, Xiyang Wu, Shi- hang Gui, Yongbei Kuang, and Lichao Sun. 2026a. Graph of skills: Dependency-aware structural re- trieval for massive agent skills.arXiv preprint arXiv:2604.05333. Hao Li, Chunjian...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
EvolveR: Self-Evolving LLM Agents through an Experience-Driven Lifecycle
Evolver: Self-evolving llm agents through an experience-driven lifecycle.arXiv preprint arXiv:2510.16079. Peng Xia, Jianwen Chen, Hanyang Wang, Jiaqi Liu, Kaide Zeng, Yu Wang, Siwei Han, Yiyang Zhou, Xujiang Zhao, Haifeng Chen, and 1 others
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
SkillRL: Evolving Agents via Recursive Skill-Augmented Reinforcement Learning
Skillrl: Evolving agents via recursive skill- augmented reinforcement learning.arXiv preprint arXiv:2602.08234. Renjun Xu and Yang Yan. 2026. Agent skills for large language models: Architecture, acquisition, security, and the path forward.arXiv preprint arXiv:2602.12430. An Yang, Baosong Yang, Beichen Zhang, and 1 others
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[4]
Qwen2.5 technical report.arXiv preprint arXiv:2412.15115. Chenxu Yang, Chuanyu Qin, Qingyi Si, Minghui Chen, Naibin Gu, Dingyu Yao, Zheng Lin, Weiping Wang, Jiaqi Wang, and Nan Duan. 2026. Self-distilled rlvr. arXiv preprint arXiv:2604.03128. Shunyu Yao, Howard Chen, John Yang, and Karthik Narasimhan. 2022a. Webshop: Towards scalable real-world web intera...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[5]
Self-Distilled Reasoner: On-Policy Self-Distillation for Large Language Models
Self-distilled reasoner: On-policy self- distillation for large language models.arXiv preprint arXiv:2601.18734. A Implementation Details Both ALFWorld and WebShop experiments use the same core CSCA hyperparameters, but differ in environment-specific configuration. ALFWorld.We train on 8×A100-80 GB GPUs with batch size 8 tasks/step, group size G=8, and le...
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.