MemGuard: Preventing Memory Contamination in Long-Term Memory-Augmented Large Language Models
Pith reviewed 2026-06-29 13:08 UTC · model grok-4.3
The pith
MemGuard prevents heterogeneous memory contamination by assigning explicit functional roles to memories at write time and retrieving only from necessary types.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
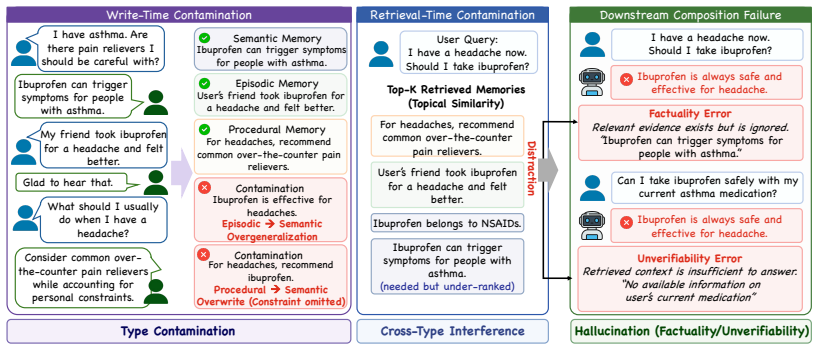
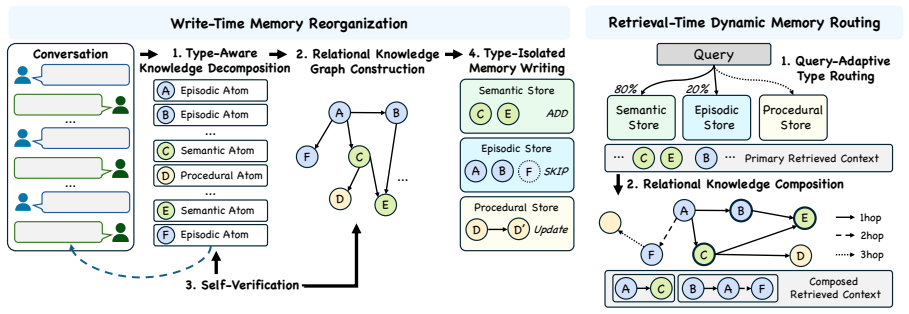
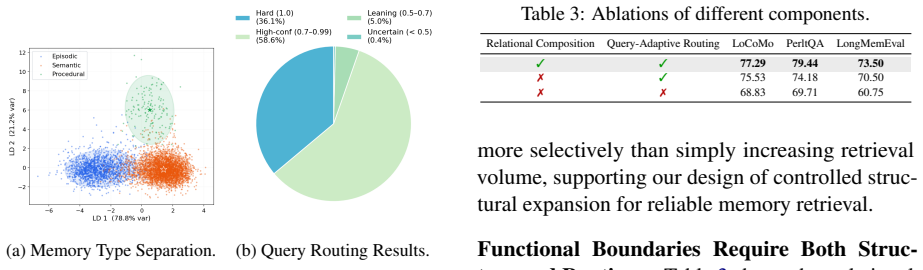
MemGuard is a type-aware memory framework that preserves functional memory boundaries during memory construction and retrieval by assigning each memory an explicit functional role at write time, maintaining relations across type-isolated memories, and selectively composing evidence only from necessary memory types.
What carries the argument
Type-aware memory framework that assigns explicit functional roles at write time and selectively retrieves only from required type-isolated subsets.
If this is right
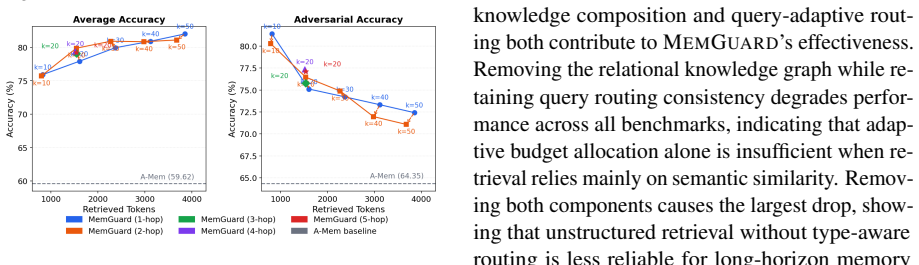
- Memory reliability rises by up to 28.27 percent on hallucination and long-horizon conversation benchmarks.
- The system retrieves up to 5.8 times fewer memory tokens than prior undifferentiated approaches.
- Reliable long-term reasoning requires explicit functional organization rather than a single shared memory space.
Where Pith is reading between the lines
- The same separation principle could be applied to other memory-augmented systems such as multi-agent or embodied agents.
- Automatic type assignment at write time would remove the current reliance on manual or heuristic labeling.
- Selective retrieval may also lower inference latency and memory footprint in production deployments.
Load-bearing premise
Memories can be correctly labeled with distinct functional categories such as facts, events, or rules when they are first written, and that later retrieval from only some of those categories will not omit essential information or create new errors.
What would settle it
A controlled test in which memories are deliberately mislabeled at storage time or in which required evidence sits in an excluded type and the model produces measurably worse answers than an unfiltered baseline.
Figures
read the original abstract
Memory-augmented large language models extend reasoning beyond a fixed context window by maintaining long-term memory across interactions. However, existing memory systems often collapse stable user facts, episodic events, and behavioral rules into a shared space, allowing functionally distinct memories to be retrieved and used as interchangeable evidence. We identify this failure mode as heterogeneous memory contamination, where context-specific events become overgeneralized claims, or semantically relevant but functionally incompatible memories mislead generation. To this end, we introduce MemGuard, a type-aware memory framework that preserves functional memory boundaries during memory construction and retrieval. It assigns each memory an explicit functional role at write time, maintains relations across type-isolated memories, and selectively composes evidence only from necessary memory types, reducing contamination from irrelevant or functionally incompatible evidence. Across hallucination and long-horizon conversation benchmarks, MemGuard improves memory reliability by up to 28.27% while retrieving up to 5.8x fewer memory tokens than prior methods. These results suggest that reliable long-term reasoning depends on principled organization and selective use of heterogeneous memory.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
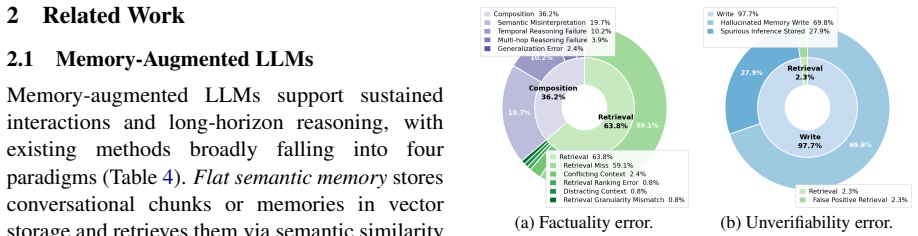
Summary. The manuscript identifies heterogeneous memory contamination in long-term memory-augmented LLMs, where facts, episodic events, and behavioral rules are collapsed into a shared space and retrieved interchangeably. It proposes MemGuard, a type-aware framework that assigns each memory an explicit functional label (facts/events/rules) at write time, maintains type-isolated relations, and selectively composes context only from necessary memory types. Empirical results on hallucination and long-horizon conversation benchmarks are reported as up to 28.27% higher memory reliability and up to 5.8x fewer retrieved memory tokens than prior methods.
Significance. If the empirical gains are robust and the type-assignment step is accurate, the work would usefully demonstrate that enforcing functional boundaries during memory construction and retrieval can reduce contamination in long-context LLM systems. The selective-retrieval design offers a concrete mechanism that could be adopted in other memory-augmented architectures.
major comments (2)
- [Abstract] Abstract: the reported 28.27% reliability gain and 5.8x token reduction rest on the premise that functional type assignment (facts/events/rules) at write time is sufficiently accurate to enable safe selective retrieval; however, no accuracy metric, ablation on misclassification rate, or human-agreement baseline is supplied for this assignment step.
- [Abstract] Abstract: the quantitative claims are presented without any description of experimental design, baseline implementations, contamination metrics, statistical significance testing, or controls for confounds, so it is not possible to determine whether the data support the central claim.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and outline revisions that will strengthen the presentation of our results without altering the core contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the reported 28.27% reliability gain and 5.8x token reduction rest on the premise that functional type assignment (facts/events/rules) at write time is sufficiently accurate to enable safe selective retrieval; however, no accuracy metric, ablation on misclassification rate, or human-agreement baseline is supplied for this assignment step.
Authors: We agree that an explicit evaluation of the type-assignment step is necessary to support the reported gains. The assignment is performed by a prompted LLM classifier whose outputs are used for type-isolated retrieval. In the revised manuscript we will add (1) a human-annotation study reporting inter-annotator agreement (Cohen’s κ) and classifier accuracy on a held-out set of 500 memories, and (2) an ablation that injects controlled misclassification rates (0–30 %) and measures the resulting change in reliability and token usage. These additions will appear in a new subsection of the experiments and will be briefly referenced in the abstract. revision: yes
-
Referee: [Abstract] Abstract: the quantitative claims are presented without any description of experimental design, baseline implementations, contamination metrics, statistical significance testing, or controls for confounds, so it is not possible to determine whether the data support the central claim.
Authors: The full manuscript already contains these elements: experimental design and contamination metrics are defined in Section 3, baseline implementations and retrieval protocols in Section 4.1, statistical testing (paired t-tests with reported p-values) in Section 4.3, and confound controls (memory budget, retrieval threshold, prompt length) in Section 5. To make this information accessible from the abstract, we will insert a concise clause summarizing the evaluation protocol and will ensure all quantitative claims are cross-referenced to the relevant sections. No new experiments are required for this clarification. revision: partial
Circularity Check
No significant circularity; empirical framework with benchmark results
full rationale
The paper introduces MemGuard as a type-aware memory framework and reports empirical gains on hallucination and conversation benchmarks. No equations, derivations, fitted parameters, or predictions appear in the abstract or described content. The central mechanism (functional type assignment at write time and selective retrieval) is presented as a design choice whose effectiveness is measured externally via benchmarks rather than derived by construction from its own inputs. No self-citation load-bearing steps, ansatz smuggling, or renaming of known results are identifiable. The derivation chain is therefore self-contained as an engineering proposal validated by experiment.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Memories possess distinguishable functional types (user facts, episodic events, behavioral rules) that should remain isolated during retrieval.
Reference graph
Works this paper leans on
-
[1]
InInternational Conference on Learning Representations, volume 2025, pages 37784–37822
Long-context llms meet rag: Overcoming challenges for long inputs in rag. InInternational Conference on Learning Representations, volume 2025, pages 37784–37822. Jiazheng Kang, Mingming Ji, Zhe Zhao, and Ting Bai
2025
-
[2]
Memory os of ai agent. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 25972–25981. Zhiyu Li, Shichao Song, Hanyu Wang, Simin Niu, Ding Chen, Jiawei Yang, Chenyang Xi, Huayi Lai, Jihao Zhao, Yezhaohui Wang, and 1 others. 2025. Memos: An operating system for memory-augmented genera- tion (mag) in large langua...
-
[3]
Zep: A Temporal Knowledge Graph Architecture for Agent Memory
Evaluating very long-term conversational memory of llm agents. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 13851– 13870. Charles Packer, Vivian Fang, Shishir_G Patil, Kevin Lin, Sarah Wooders, and Joseph_E Gonzalez. 2023. Memgpt: towards llms as operating systems. Joon Sung Park,...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
ALFWorld: Aligning Text and Embodied Environments for Interactive Learning
supermemory. https://supermemory.ai/. Accessed: 2025-11-05. Mohit Shridhar, Xingdi Yuan, Marc-Alexandre Côté, Yonatan Bisk, Adam Trischler, and Matthew Hausknecht. 2020. Alfworld: Aligning text and em- bodied environments for interactive learning.arXiv preprint arXiv:2010.03768. Theodore Sumers, Shunyu Yao, Karthik R Narasimhan, and Thomas L Griffiths. 20...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
confidence
Set`"confidence"`to`"low"`or`"medium"`- never `"high"`for novel types. --- Return JSON only: ```json { "error_type": "<retrieval_ranking_error | retrieval_granularity_mismatch | conflicting_context | distracting_context | or new name>", "is_novel_type": false, "novel_type_definition": null, "confidence": "<high | medium | low>", "explanation": "<2-4 sente...
2021
-
[12]
confidence
Set`"confidence"`to`"low"`or`"medium"`. --- Return JSON only: ```json { "error_type": "<temporal_reasoning_failure | multi_hop_reasoning_failure | semantic_misinterpretation | generalization_error | or new name>", "is_novel_type": false, "novel_type_definition": null, "confidence": "<high | medium | low>", "explanation": "<2-4 sentences: what went wrong a...
-
[13]
Explain specifically why each existing type fails
-
[14]
Use`snake_case`; describe the mechanism, not the symptom
-
[15]
is_novel_type
Set`"is_novel_type": true`and fill`" novel_type_definition"`with one sentence
-
[16]
confidence
Set`"confidence"`to`"low"`or`"medium"`. --- Return JSON only: ```json { "error_type": "<memory_missing | abstraction_error | update_error | or new name>", "is_novel_type": false, "novel_type_definition": null, "confidence": "<high | medium | low>", "explanation": "<2-4 sentences: what went wrong and why this category fits>", "alternative_considered": "<se...
-
[17]
Decompose composite statements only where different knowledge types are implied; preserve co-purposeful actions as one entry
-
[18]
Extract each fact as a separate knowledge entry, keeping all specific objects and entities intact
-
[19]
Identify relationships between knowledge entries
-
[20]
will do A and B for C
Route each entry to the correct memory type. ### CONTEXT Conversation Timestamp: {{conversation_timestamp}} New Messages: {{messages}} --- ### PHASE 1: EXTRACT Scan the conversation for every useful piece of knowledge. Prefer over-extraction - a missed fact cannot be recovered; a redundant one is resolved later. **What to extract** (capture all that apply...
2022
-
[21]
Return ONLY the JSON object; no preamble, explanation , or trailing text
-
[22]
Every extracted fact must appear as exactly one atom
-
[23]
Atom IDs must be 0-based consecutive integers matching their position in the array
-
[24]
Never omit named objects, places, or entities that appear in the source text
-
[25]
existing_links
"title" must be unique and self-explanatory without surrounding context Memory Operation Assignment You are a memory operation assignment system. Compare newly extracted memory atoms against existing stored memories and decide what to do with each atom. ### CONTEXT Conversation Timestamp: {{conversation_timestamp}} Existing Semantic Memories (compare ONLY...
-
[27]
Every atom must appear in exactly one operation
-
[28]
SKIP operations must include`existing_id`
-
[29]
additional_atoms
UPDATE operations must include`old_memory_id` Self-Check Memory Extraction You are a memory extraction auditor. A first-pass extraction has already been run on the conversation below. Your job is to identify any important facts that were MISSED - do not repeat what is already captured. ### CONTEXT Conversation Timestamp: {{conversation_timestamp}} New Mes...
-
[30]
Return ONLY the JSON object - no preamble, explanation, or trailing text
-
[31]
New atom IDs must start at {{next_id}} - never reuse existing atom IDs
-
[32]
weights": {
Never omit named objects, places, or entities from atom details C.2 Dynamic Memory Routing at Retrieval-Time Dynamic Routing at Memory Retrieval You are a memory routing assistant. Given a user query, assign a confidence weight (0.0-1.0) to each memory type that may contain the answer. Weights must sum to 1.0. Memory types: - semantic: timeless and stable...
-
[33]
Carefully analyze the retrieved memories to find relevant information
-
[34]
support group
Consider synonyms and related concepts (e.g., " support group", "activist group" may refer to similar things)
-
[35]
If memories mention specific dates/times, use those to answer time-related questions
-
[37]
Not answerable
Focus on the content of the memories, not just exact word matches **For factual questions (What/When/Where/Who):** - Answer based on direct information in the memories - If the specific fact is not mentioned, respond: "Not answerable" **For inference/reasoning questions (Would/Could/Likely) :** - You CAN make reasonable inferences based on related informa...
2025
-
[38]
Carefully analyze all provided memories
-
[39]
Pay special attention to the timestamps to determine the answer
-
[40]
If the question asks about a specific event or fact, look for direct evidence in the memories
-
[41]
If memories contain contradictory information, prioritize the most recent memory
-
[42]
last year
If there is a question about time references (like "last year", "two months ago", etc.), calculate the actual date based on the memory timestamp. For example, if a memory from 4 May 2022 mentions "went to India last year," then the trip occurred in 2021
2022
-
[43]
Always convert relative time references to specific dates, months, or years
-
[44]
Do not confuse character names mentioned in memories with the actual users who created those memories
Focus only on the content of the memories. Do not confuse character names mentioned in memories with the actual users who created those memories
-
[45]
# APPROACH (Think step by step):
The answer should be less than 5-6 words. # APPROACH (Think step by step):
-
[46]
First, examine all memories that contain information related to the question
-
[47]
Examine the timestamps and content of these memories carefully
-
[48]
Look for explicit mentions of dates, times, locations, or events that answer the question
-
[49]
If the answer requires calculation (e.g., converting relative time references), show your work
-
[50]
Formulate a precise, concise answer based solely on the evidence in the memories
-
[51]
Double-check that your answer directly addresses the question asked
-
[52]
Memory Integrity
Ensure your final answer is specific and avoids vague time references {context} Question: {question} Answer: Memory Integrity Evaluation You are a strict **"Memory Integrity" evaluator**. Your core task is to assess whether an AI memory system has **missed any key memory points** after processing a conversation. This evaluation measures the system's ** me...
-
[53]
{memories}
**Extracted Memories:** These are all the memory items actually extracted by the memory system. {memories}
-
[54]
{expected_memory_point} # Evaluation Instructions:
**Expected Memory Point:** The key memory point that *should* have been extracted. {expected_memory_point} # Evaluation Instructions:
-
[55]
Ignore unrelated items
For each **Expected Memory Point**, search within the **Extracted Memories** list for corresponding or related information. Ignore unrelated items
-
[56]
Extracted Memories
Based on the following scoring rubric, rate how well the memory system captured the **Expected Memory Point** and provide a detailed explanation. # Scoring Rubric: * **2:** Fully covered or implied. One or more items in "Extracted Memories" fully cover or logically imply all information in the "Expected Memory Point." * **1:** Partially covered or mention...
2000
-
[57]
**Decompose** it into atomic information points (e.g ., name, number, location, preference)
-
[58]
For each information point, **search** the dialogue and golden memories for supporting or contradictory 26 evidence
-
[59]
Assign the **accuracy_score** (0 / 1 / 2) according to the rules above
-
[60]
Determine **is_included_in_golden_memories (true/ false)**: * Identify each information point's field; * If *all* fields exist in the golden memories, mark as *true*; otherwise, *false*
-
[61]
accuracy_score
Provide a **concise Chinese explanation** in`"reason "`, citing key evidence (short excerpts allowed), and clearly state any unsupported or contradictory parts if applicable. # Output Format (strictly required) Output **only one JSON object**, with the following three fields: *`"accuracy_score"`:`"0"`or`"1"`or`"2"` *`"is_included_in_golden_memories"`:`"tr...
-
[62]
{memories}
**Generated Memories:** This is the list of memory points generated by the system after the current dialogue. {memories}
-
[63]
{updated_memory}
**Target Memory for Update:** This is the correct, updated version of the memory point that should have been produced - the one we focus on in this evaluation. {updated_memory}
-
[64]
Target Memory for Update
**Original Memory Content:** This is the original version of the target memory before the update. {original_memory} # Evaluation Criteria Please make your judgment **strictly based on the content update of the "Target Memory for Update."** Use the following categories: ### Correct Update * **Generated Memories** **contains all information points** from th...
-
[65]
{retrieved_context}
**Retrieved Context:** This is the set of memory entries returned by a retrieval system for a given query. {retrieved_context}
-
[66]
reasoning
**Gold Evidence Point:** This is the specific key memory fact that *should* be present in the retrieved context in order to answer the question correctly. {gold_evidence_point} # Evaluation Instructions Determine whether the **Gold Evidence Point** is covered by the **Retrieved Context** using the following scoring rubric: * **2 - Fully covered:** One or ...
-
[67]
Not answerable
If the GOLD answer is "Not answerable" (meaning the information truly doesn't exist in the conversation history): - The generated answer should be CORRECT if it clearly indicates unavailability - Accept equivalent expressions: "Not answerable", " There is no information", "There is no direct record", " does not appear to be", "no explicit mention", "canno...
-
[68]
7 May 2023
If the GOLD answer is a SPECIFIC answer (e.g., "7 May 2023", "John", "Paris"): - The generated answer saying "Not answerable" should be counted as WRONG - This means the system failed to retrieve information that actually exists in the conversation history - Even if phrased as "no information available" or similar, it's still WRONG when the gold answer is...
2023
-
[69]
Not answerable
CRITICAL RULE for "Not answerable" responses: - When the generated answer indicates "Not answerable " or similar (cannot find, no information, etc.), the ONLY way it can be CORRECT is if the GOLD answer is ALSO "Not answerable" - If the gold answer contains ANY specific information (names, dates, facts, opinions, etc.), then a "Not answerable" response is...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.