ROSD: Reflective On-Policy Self-Distillation for Language Model Reasoning across Domains
Pith reviewed 2026-06-29 13:01 UTC · model grok-4.3
The pith
ROSD improves LLM reasoning by using a self-reflector to extract a corrective idea and restrict distillation to the first error span in each rollout.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
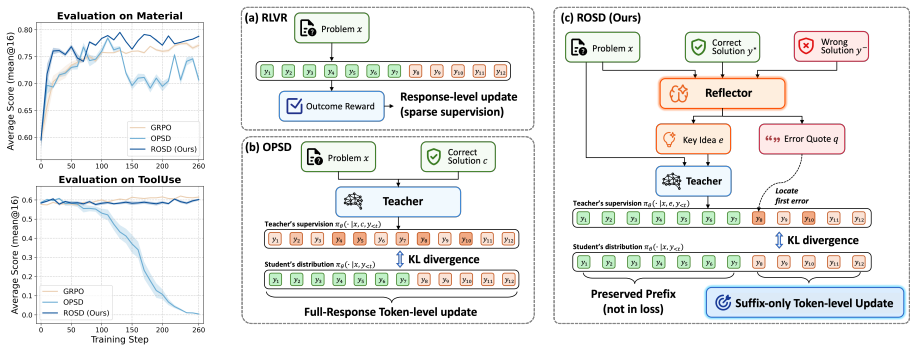
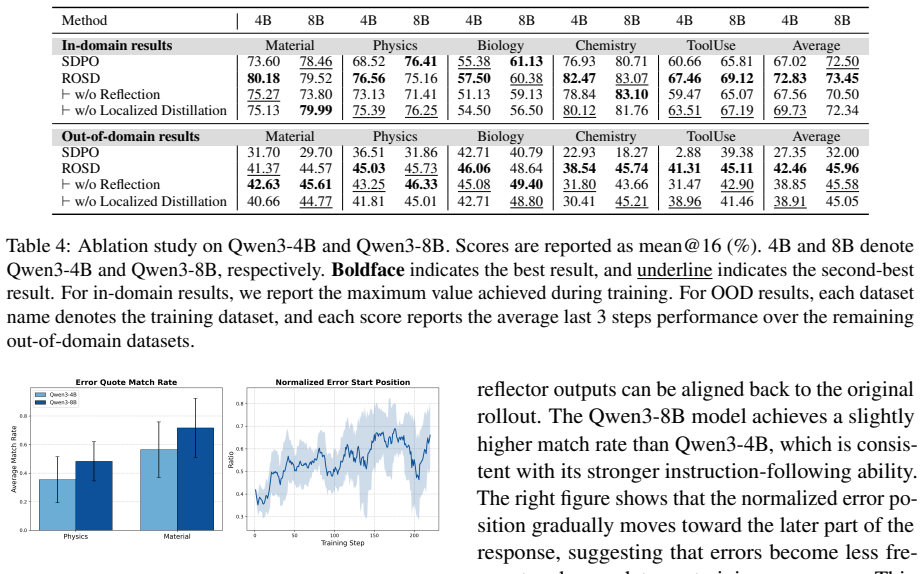
ROSD turns reference-solution imitation into targeted reasoning correction through reflection-guided, error-localized distillation. For each rollout, a self-reflector extracts a corrective idea and locates the first erroneous span. The corrective idea guides the self-teacher toward targeted supervision, while the localized error span restricts distillation to where correction is needed. This design corrects flawed reasoning while preserving valid prefixes.
What carries the argument
The self-reflector that extracts a corrective idea and locates the first erroneous span, enabling error-localized distillation instead of full-response updates.
If this is right
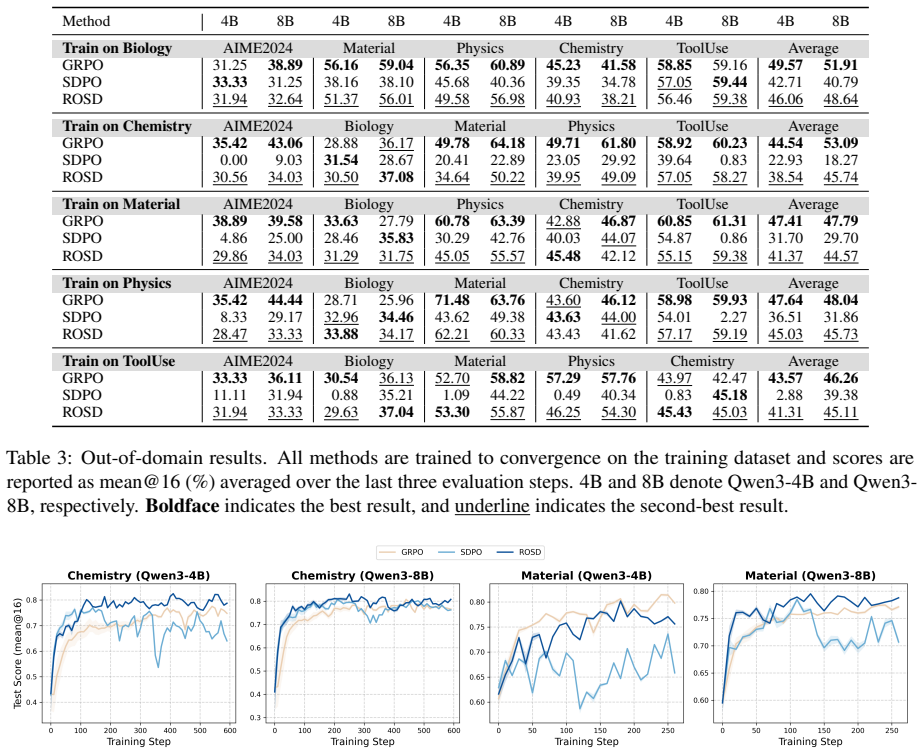
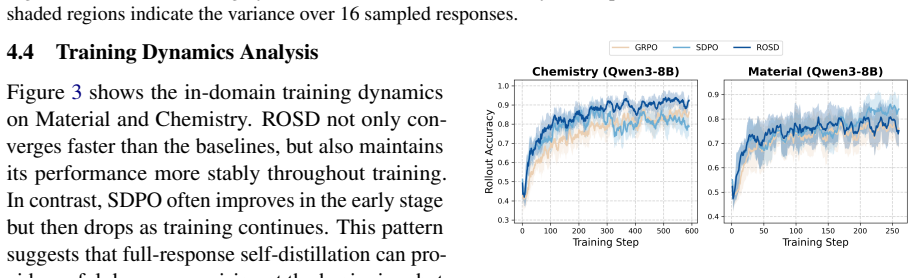
- Stronger in-domain reasoning performance overall than standard OPSD.
- Substantially better out-of-domain generalization than standard OPSD.
- Preservation of valid reasoning prefixes during the distillation step.
- Shift from imitation of reference trajectories to error-specific correction.
Where Pith is reading between the lines
- The same reflection-plus-localization pattern could be tested on non-reasoning sequence tasks such as code generation or dialogue.
- If the reflector works reliably, the method reduces dependence on large sets of verified reference solutions.
- Error localization may lower the risk of reinforcing domain-specific patterns that hurt generalization.
Load-bearing premise
A self-reflector can reliably extract a corrective idea and accurately locate the first erroneous span without introducing new errors or misidentifying valid steps.
What would settle it
An ablation that supplies the self-reflector with deliberately incorrect error locations or corrective ideas, after which out-of-domain gains over standard OPSD disappear.
Figures




read the original abstract
On-policy self-distillation (OPSD) improves the reasoning performance of large language models (LLMs) by providing dense token-level supervision for on-policy rollouts. However, existing OPSD methods often yield limited gains on in-domain reasoning and generalize poorly to out-of-domain problems. We identify two key causes: conditioning the self-teacher on a verified solution encourages imitation of training-domain reference trajectories rather than error-specific correction, and applying distillation to the full response can overwrite valid reasoning prefixes and reinforce overfitting. We propose Reflective On-policy Self-Distillation (ROSD), a framework that turns reference-solution imitation into targeted reasoning correction through reflection-guided, error-localized distillation. For each rollout, ROSD uses a self-reflector to extract a corrective idea and locate the first erroneous span. The corrective idea guides the self-teacher toward targeted supervision, while the localized error span restricts distillation to where correction is needed. This design corrects flawed reasoning while preserving valid prefixes. Experiments on multiple in-domain and out-of-domain reasoning benchmarks show that ROSD yields stronger in-domain reasoning performance overall and substantially better out-of-domain generalization than standard OPSD. Code is available at https://github.com/ZiqiZhao1/ROSD.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that standard on-policy self-distillation (OPSD) yields limited in-domain gains and poor out-of-domain generalization because it encourages imitation of reference trajectories and applies distillation over full responses. ROSD addresses this by introducing a self-reflector that extracts a corrective idea from the reference and identifies the first erroneous span in each rollout; distillation is then restricted to that span under guidance from the corrective idea. Experiments on multiple in-domain and out-of-domain reasoning benchmarks are reported to show stronger overall in-domain performance and substantially better out-of-domain generalization than standard OPSD. Code is released.
Significance. If the central mechanism proves reliable, the targeted correction approach could meaningfully advance on-policy distillation methods for LLM reasoning by reducing overfitting to training-domain trajectories while preserving valid prefixes. The public code release is a clear strength that supports reproducibility.
major comments (2)
- [Abstract, §3] Abstract and §3 (method description): the central claim that restricting distillation to the first erroneous span 'preserves valid prefixes' and supplies 'targeted correction' is load-bearing, yet the manuscript supplies no quantitative evidence (human agreement rates, precision/recall on span localization, or ablation removing the reflector) that the self-reflector meets the required reliability threshold at non-negligible rates.
- [§4] §4 (experiments): the reported gains in out-of-domain generalization are attributed to error-localized distillation, but without an ablation that compares ROSD against a version using the same corrective idea yet full-response distillation, it is unclear whether the localization step, rather than the corrective idea alone, drives the improvement.
minor comments (2)
- [§3] Notation for the self-reflector output (corrective idea and span) should be formalized with explicit symbols to avoid ambiguity when describing the modified distillation loss.
- [Abstract, §4] The abstract states 'multiple in-domain and out-of-domain reasoning benchmarks' but does not name them; the experimental section should list the exact datasets and splits used.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We respond point by point to the major comments and indicate the revisions we will make.
read point-by-point responses
-
Referee: [Abstract, §3] Abstract and §3 (method description): the central claim that restricting distillation to the first erroneous span 'preserves valid prefixes' and supplies 'targeted correction' is load-bearing, yet the manuscript supplies no quantitative evidence (human agreement rates, precision/recall on span localization, or ablation removing the reflector) that the self-reflector meets the required reliability threshold at non-negligible rates.
Authors: We agree that the manuscript does not provide direct quantitative validation of the self-reflector's span localization (e.g., human agreement rates, precision/recall) or an ablation that removes the reflector. End-to-end gains serve as indirect evidence in the current version. In revision we will add both an ablation removing the reflector and human evaluation of localization accuracy on a sampled subset of rollouts. revision: yes
-
Referee: [§4] §4 (experiments): the reported gains in out-of-domain generalization are attributed to error-localized distillation, but without an ablation that compares ROSD against a version using the same corrective idea yet full-response distillation, it is unclear whether the localization step, rather than the corrective idea alone, drives the improvement.
Authors: We concur that the experiments do not isolate the localization step from the corrective idea. We will add the requested ablation (corrective idea with full-response distillation) in the revised manuscript to clarify the contribution of error localization. revision: yes
Circularity Check
No significant circularity; empirical method with independent experimental validation
full rationale
The paper introduces ROSD as a modification to OPSD that incorporates a self-reflector for corrective idea extraction and error-span localization, then reports benchmark results showing improved in-domain and out-of-domain performance. No derivation step reduces by construction to its inputs: there are no self-definitional equations, no parameters fitted on a subset and then relabeled as predictions, and no load-bearing self-citations or uniqueness theorems. The mechanism is described procedurally and evaluated externally via experiments, making the central claims falsifiable and non-circular. The reader's assessment of score 1.0 aligns with this finding.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard assumptions of on-policy distillation and LLM fine-tuning hold for the proposed reflective mechanism.
Forward citations
Cited by 1 Pith paper
-
UCOB: Learning to Utilize and Evolve Agentic Skills via Credit-Aware On-Policy Bidirectional Self-Distillation
UCOB improves agentic RL by using return-to-go comparisons between skill-conditioned and no-skill prompts as local teachers for bidirectional self-distillation and skill memory updates.
Reference graph
Works this paper leans on
-
[1]
Self-Distillation Zero: Self-Revision Turns Binary Rewards into Dense Supervision
Self-distillation zero: Self-revision turns bi- nary rewards into dense supervision.arXiv preprint arXiv:2604.12002. Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. 2015. Distilling the knowledge in a neural network.arXiv preprint arXiv:1503.02531. Jonas Hübotter, Frederike Lübeck, Lejs Behric, An- ton Baumann, Marco Bagatella, Daniel Marta, Ido Hakimi, Id...
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[2]
Understanding R1-Zero-Like Training: A Critical Perspective
Understanding r1-zero-like training: A critical perspective.arXiv preprint arXiv:2503.20783. Kevin Lu and Thinking Machines Lab. 2025. On- policy distillation.Thinking Machines Lab: Con- nectionism. Https://thinkingmachines.ai/blog/on- policy-distillation. Fanqing Meng, Lingxiao Du, Zongkai Liu, Zhixiang Zhou, Quanfeng Lu, Daocheng Fu, Botian Shi, Wen- ha...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Mm-eureka: Exploring visual aha moment with rule-based large-scale reinforcement learning. CoRR. Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, and 1 others. 2022. Training language models to follow in- structions with human feedback.Advances in neural informat...
2022
-
[4]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Direct preference optimization: Your language model is secretly a reward model.Advances in neural information processing systems, 36:53728–53741. Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, and 1 others. 2024. Deepseekmath: Pushing the limits of mathematical reasoning in open langua...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
Kimi k1.5: Scaling Reinforcement Learning with LLMs
Kimi k1. 5: Scaling reinforcement learning with llms.arXiv preprint arXiv:2501.12599. An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, and 1 others
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Qwen3 technical report.arXiv preprint arXiv:2505.09388. Feng Yao, Liyuan Liu, Dinghuai Zhang, Chengyu Dong, Jingbo Shang, and Jianfeng Gao. 2025. Your efficient rl framework secretly brings you off-policy rl training, august 2025.URL https://fengyao. notion. site/off- policy-rl. Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
We train for 10 epochs on the science question-answering tasks and 5 epochs on the ToolUse task, using a training batch size of
that train under a fixed time budget, we use an epoch budget large enough for the methods to converge in our setting. We train for 10 epochs on the science question-answering tasks and 5 epochs on the ToolUse task, using a training batch size of
-
[8]
All algorithms are eval- uated every 10 training steps
The maximum length of the reflection prompt is 8k tokens, and the maximum length of the gener- ated reflection is 4k tokens. All algorithms are eval- uated every 10 training steps. For self-distillation methods, we use Jensen–Shannon divergence with α= 0.5 , a distillation top-k of 100, and a frozen self-teacher and self-reflector during each run. C Addit...
2026
-
[9]
Given a question and four options, please select the right answer
The prompt used as input to the self-teacher is shown in Figure 12. Given a question and four options, please select the right answer. Respond in the following format: <reasoning> ... </reasoning> <answer> ... </answer> For the answer, only output the letter corresponding to the correct option (A, B, C, or D), and nothing else. Do not restate the answer t...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.