Data-Efficient On-Policy Distillation for Automatic Speech Recognition
Pith reviewed 2026-06-29 11:59 UTC · model grok-4.3
The pith
On-policy distillation from a larger teacher lets a 0.6B ASR model beat its same-scale baseline on four of five benchmarks after training on 100k hours of speech.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors claim that teacher-guided on-policy training substantially closes the performance gap for compact ASR models under a much smaller audio budget, with the proposed recipe improving over supervised fine-tuning alone across benchmarks and outperforming the same-scale Qwen3-ASR-0.6B baseline on four of five evaluation sets while the 1.7B model remains stronger.
What carries the argument
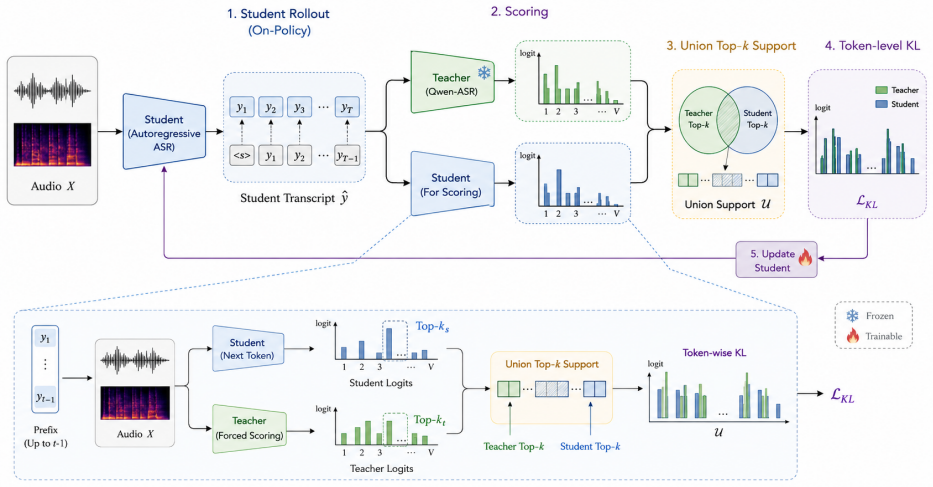
On-policy distillation, where the student generates its own outputs and the teacher provides guidance on those outputs, together with a support-overlap diagnostic that measures local student-teacher compatibility.
If this is right
- Compact models can narrow much of the accuracy gap to models three times larger while using orders of magnitude less supervised audio.
- The support-overlap diagnostic can serve as a practical signal for deciding when distillation is likely to help.
- ASR specialization and reproduction become feasible with far smaller data budgets than previously reported.
- The same training pattern may allow repeated teacher-guided refinement without collecting new labeled audio each time.
Where Pith is reading between the lines
- The technique could be applied to other audio tasks such as speaker verification or spoken language understanding to test whether data reduction generalizes.
- Similar on-policy guidance might lower data needs in related sequence tasks outside speech, such as text-to-speech or machine translation.
- Holding the data budget fixed while varying student size could expose new scaling relationships between model capacity and distillation benefit.
Load-bearing premise
The performance gains are produced by the on-policy distillation step itself rather than by other details of data selection or hyperparameter choices.
What would settle it
Retrain the student using the identical supervised fine-tuning stage but without the on-policy distillation stage and check whether the reported advantage over the same-scale baseline disappears.
Figures

read the original abstract
Building competitive automatic speech recognition (ASR) models usually requires large-scale au- dio supervision, which makes reproduction and specialization expensive. We study Ark-ASR, a 0.6B- parameter audio-conditioned language model trained with 100k hours of speech, and examine whether a strong Qwen-ASR teacher can transfer additional recognition capability through on-policy distillation. Across Mandarin and English ASR benchmarks, the proposed training recipe consistently improves over supervised fine-tuning alone and outperforms the same-scale Qwen3-ASR-0.6B baseline on four of five evaluation sets. This is achieved with only 100k hours of speech, compared with the 20M hours of super- vised audio reported for the Qwen3-Omni AuT encoder. The larger Qwen3-ASR-1.7B remains stronger, but the results show that teacher-guided on-policy training can substantially close the gap for compact ASR models under a much smaller audio budget. A support-overlap diagnostic further suggests that the teacher-data stage improves local student-teacher compatibility, matching recent analyses of when on-policy distillation is effective.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Ark-ASR, a 0.6B-parameter audio-conditioned language model trained on 100k hours of speech. It examines on-policy distillation from a Qwen-ASR teacher and claims that the proposed training recipe consistently improves over supervised fine-tuning alone while outperforming the same-scale Qwen3-ASR-0.6B baseline on four of five Mandarin and English ASR benchmarks. This is achieved with far less data than the 20M hours reported for the Qwen3-Omni AuT encoder. A support-overlap diagnostic is introduced to indicate improved local student-teacher compatibility.
Significance. If the reported gains can be rigorously attributed to on-policy distillation, the work would demonstrate a practical route to data-efficient improvement of compact ASR models, narrowing the gap to larger systems under a much smaller audio budget. The support-overlap diagnostic could also supply a reusable tool for predicting when teacher-guided training is effective.
major comments (3)
- [Abstract] Abstract and results presentation: performance improvements on benchmarks are stated without error bars, number of runs, statistical tests, ablation controls, or description of baseline matching, so the data-to-claim link cannot be evaluated.
- [§4] Experiments section: no ablation studies hold data, hyperparameters, and architecture fixed while toggling only the on-policy distillation stage, leaving the attribution of WER gains to the distillation step (rather than data selection or other recipe details) unproven.
- [§5] Support-overlap diagnostic: the claim that the metric identifies when the teacher-data stage improves compatibility is presented without quantitative validation, correlation analysis against actual WER improvements, or controls showing it outperforms simpler overlap measures.
minor comments (1)
- [Abstract] The abstract contains a line-break hyphenation artifact ('au- dio').
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments correctly identify gaps in statistical rigor, ablation design, and validation of the diagnostic. We will revise the manuscript to address these points where possible, strengthening the attribution of gains and the support-overlap analysis. Responses to each major comment follow.
read point-by-point responses
-
Referee: [Abstract] Abstract and results presentation: performance improvements on benchmarks are stated without error bars, number of runs, statistical tests, ablation controls, or description of baseline matching, so the data-to-claim link cannot be evaluated.
Authors: We agree the current presentation lacks error bars, run counts, and statistical tests, weakening the evidential link. The manuscript reports single-run WERs on the five benchmarks. In revision we will add: (i) a clear description of baseline matching (identical 0.6B architecture, same 100k-hour training distribution, and identical decoding settings for the SFT and on-policy variants); (ii) error bars computed from three independent runs for the key comparisons; and (iii) a brief note on the absence of formal significance testing due to compute limits, while still reporting the observed deltas. Ablation controls will be expanded in §4 rather than the abstract. revision: partial
-
Referee: [§4] Experiments section: no ablation studies hold data, hyperparameters, and architecture fixed while toggling only the on-policy distillation stage, leaving the attribution of WER gains to the distillation step (rather than data selection or other recipe details) unproven.
Authors: The referee is correct that the existing comparison (SFT vs. full recipe) does not isolate the distillation stage while freezing data, hyperparameters, and architecture. The manuscript therefore cannot yet rigorously attribute gains solely to on-policy distillation. We will add a controlled ablation in the revised §4 that trains two models on identical data and hyperparameters, differing only in the presence of the on-policy distillation objective, and report the resulting WER deltas on the same five benchmarks. revision: yes
-
Referee: [§5] Support-overlap diagnostic: the claim that the metric identifies when the teacher-data stage improves compatibility is presented without quantitative validation, correlation analysis against actual WER improvements, or controls showing it outperforms simpler overlap measures.
Authors: We acknowledge that the support-overlap diagnostic is introduced without the requested quantitative validation. The current text offers only a qualitative interpretation. In revision we will add: (i) a correlation plot and coefficient between support-overlap scores and per-benchmark WER reductions across multiple teacher-student configurations; (ii) a direct comparison against simpler baselines such as token-level or n-gram overlap; and (iii) a short discussion of whether the metric provides predictive value beyond those simpler measures. revision: yes
Circularity Check
No circularity: empirical results with no derivation chain
full rationale
The paper reports empirical ASR training outcomes using on-policy distillation on 100k hours of data, with benchmark WER comparisons to baselines. No equations, fitted parameters, or derivations are presented that reduce to inputs by construction. Claims rest on observed performance deltas rather than any self-definitional, fitted-input, or self-citation load-bearing steps. The support-overlap diagnostic is described as suggestive but not used as a mathematical reduction. This matches the expected non-finding for an empirical methods paper whose central results are externally falsifiable via replication on the reported benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Awni Hannun, Carl Case, Jared Casper, Bryan Catanzaro, Greg Diamos, Erich Elsen, Ryan Prenger, Sanjeev Satheesh, Shubho Sengupta, Adam Coates, and Andrew Y. Ng. Deep speech: Scaling up end-to-end speech recognition.arXiv preprint arXiv:1412.5567, 2014. doi: 10.48550/arXiv.1412.5567. URLhttps://arxiv.org/abs/1412.5567
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1412.5567 2014
-
[2]
Anmol Gulati, James Qin, Chung-Cheng Chiu, Niki Parmar, Yu Zhang, Jiahui Yu, Wei Han, Shibo Wang, Zhengdong Zhang, Yonghui Wu, and Ruoming Pang. Conformer: Convolution-augmented transformer 7 for speech recognition.arXiv preprint arXiv:2005.08100, 2020. doi: 10.48550/arXiv.2005.08100. URL https://arxiv.org/abs/2005.08100
-
[3]
Robust Speech Recognition via Large-Scale Weak Supervision
Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, and Ilya Sutskever. Robust speech recognition via large-scale weak supervision.arXiv preprint arXiv:2212.04356, 2022. doi: 10.48550/arXiv.2212.04356. URLhttps://arxiv.org/abs/2212.04356
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2212.04356 2022
-
[4]
Jin Xu, Zhifang Guo, Hangrui Hu, Yunfei Chu, Xiong Wang, Jinzheng He, Yuxuan Wang, Xian Shi, Ting He, Xinfa Zhu, et al. Qwen3-omni technical report.arXiv preprint arXiv:2509.17765, 2025. doi: 10.48550/arXiv.2509.17765. URLhttps://arxiv.org/abs/2509.17765
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2509.17765 2025
-
[5]
Distilling the Knowledge in a Neural Network
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in a neural network.arXiv preprint arXiv:1503.02531, 2015. doi: 10.48550/arXiv.1503.02531. URL https://arxiv.org/abs/ 1503.02531
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1503.02531 2015
- [6]
-
[7]
Rethinking On-Policy Distillation of Large Language Models: Phenomenology, Mechanism, and Recipe
Yaxuan Li, Yuxin Zuo, Bingxiang He, Jinqian Zhang, Chaojun Xiao, Cheng Qian, Tianyu Yu, Huan-ang Gao, Wenkai Yang, Zhiyuan Liu, and Ning Ding. Rethinking on-policy distillation of large language models: Phenomenology, mechanism, and recipe.arXiv preprint arXiv:2604.13016, 2026. doi: 10.48550/arXiv.2604.13016. URLhttps://arxiv.org/abs/2604.13016
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2604.13016 2026
-
[8]
AISHELL-1: An Open-Source Mandarin Speech Corpus and A Speech Recognition Baseline
Hui Bu, Jiayu Du, Xingyu Na, Bengu Wu, and Hao Zheng. Aishell-1: An open-source mandarin speech corpus and a speech recognition baseline.arXiv preprint arXiv:1709.05522, 2017. doi: 10.48550/arXiv.1709.05522. URLhttps://arxiv.org/abs/1709.05522
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1709.05522 2017
-
[9]
Binbin Zhang, Hang Lv, Pengcheng Guo, Qijie Shao, Chao Yang, Lei Xie, Xin Xu, Hui Bu, Xiaoyu Chen, Chenchen Zeng, Di Wu, and Zhendong Peng. Wenetspeech: A 10000+ hours multi-domain mandarin corpus for speech recognition.arXiv preprint arXiv:2110.03370, 2022. doi: 10.48550/arXiv.2110.03370. URLhttps://arxiv.org/abs/2110.03370
-
[10]
Librispeech: An asr corpus based on public domain audio books
Vassil Panayotov, Guoguo Chen, Daniel Povey, and Sanjeev Khudanpur. Librispeech: An asr corpus based on public domain audio books. In2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 5206–5210, 2015. doi: 10.1109/ICASSP.2015.7178964. URL https://doi.org/10.1109/ICASSP.2015.7178964
-
[11]
In: Medical Imaging with Deep Learning (MIDL)
Xun Gong, Zhikai Zhou, and Yanmin Qian. Knowledge transfer and distillation from autoregressive to non-autoregressive speech recognition.arXiv preprint arXiv:2207.10600, 2022. doi: 10.48550/arXiv. 2207.10600. URLhttps://arxiv.org/abs/2207.10600
work page internal anchor Pith review doi:10.48550/arxiv 2022
-
[12]
KL for a KL: On-Policy Distillation with Control Variate Baseline
Minjae Oh, Sangjun Song, Gyubin Choi, Yunho Choi, and Yohan Jo. Kl for a kl: On-policy distillation with control variate baseline.arXiv preprint arXiv:2605.07865, 2026. doi: 10.48550/arXiv.2605.07865. URLhttps://arxiv.org/abs/2605.07865
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2605.07865 2026
-
[13]
Prefix Teach, Suffix Fade: Local Teachability Collapse in Strong-to-Weak On-Policy Distillation
Kaiyuan Liu, Ziyuan Zhuang, Yang Bai, Bing Wang, Rongxiang Weng, and Jieping Ye. Prefix teach, suffix fade: Local teachability collapse in strong-to-weak on-policy distillation.arXiv preprint arXiv:2605.13643, 2026. doi: 10.48550/arXiv.2605.13643. URL https://arxiv.org/abs/2605. 13643
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2605.13643 2026
-
[14]
GLM-ASR: A robust, open-source speech recognition model
Z.ai. GLM-ASR: A robust, open-source speech recognition model. GitHub repository, 2025. URL https://github.com/zai-org/GLM-ASR. 8
2025
-
[15]
GlmAsr model documentation
Hugging Face. GlmAsr model documentation. Transformers documentation, 2025. URL https: //huggingface.co/docs/transformers/model_doc/glmasr. 9
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.