Recognition: 2 theorem links
· Lean TheoremKL for a KL: On-Policy Distillation with Control Variate Baseline
Pith reviewed 2026-05-11 03:23 UTC · model grok-4.3
The pith
vOPD stabilizes on-policy distillation by subtracting a closed-form per-token negative reverse KL value function as a detached baseline.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By recasting on-policy distillation as policy-gradient RL, the paper shows that the associated value function is exactly the per-token negative reverse KL divergence between student and teacher policies. Because this quantity is produced by the ordinary forward pass, it can be used directly as a control-variate baseline that is subtracted from the single-sample reward signal, lowering gradient variance without bias, without extra critics, and without computing the full-vocabulary reverse KL.
What carries the argument
The control-variate baseline formed by the per-token negative reverse KL divergence between student and teacher, which is detached from the gradient and subtracted from the Monte Carlo estimator.
If this is right
- The single-sample estimator stays unbiased and computationally cheap because the baseline is detached and requires no extra forward passes.
- A top-k truncation of the baseline further reduces compute while preserving downstream task performance.
- Training stability improves enough for vOPD to match the accuracy of full-vocabulary reverse-KL methods at lower cost.
- The same baseline construction applies directly to any OPD run that already computes per-token log-probabilities.
Where Pith is reading between the lines
- The same closed-form baseline trick could be tested on other single-sample policy-gradient objectives in language-model alignment where the value function also has an analytic expression.
- If top-k truncation works reliably, it suggests that full-vocabulary KL computations are often unnecessary for variance reduction even outside distillation.
- The approach leaves open whether learned or adaptive baselines could be added while still avoiding any extra inference cost.
Load-bearing premise
The value function of the on-policy distillation objective admits an exact closed-form expression as the per-token negative reverse KL divergence that can be read off the existing forward pass with no additional computation or model.
What would settle it
An empirical measurement showing that subtracting the proposed baseline either introduces measurable bias into the gradient estimates or leaves their variance unchanged, or that vOPD-trained models fail to outperform vanilla OPD on the mathematical and scientific reasoning benchmarks.
Figures

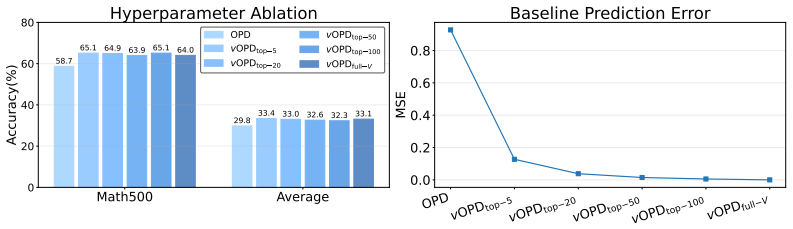
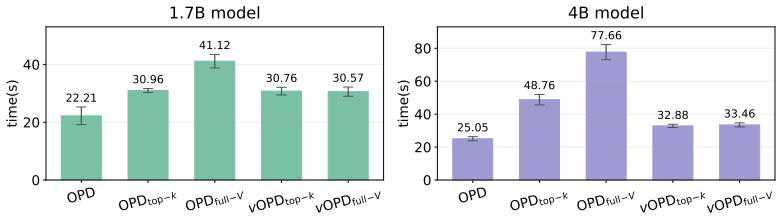


read the original abstract
On-Policy Distillation (OPD) has emerged as a dominant post-training paradigm for large language models, especially for reasoning domains. However, OPD remains unstable in practice due to the high gradient variance of its single-sample Monte Carlo estimator, and recipes for stable training are still immature. We propose vOPD (On-Policy Distillation with a control variate baseline), which casts OPD as policy-gradient RL and stabilizes it by introducing a control variate baseline-canonically a value function -- from the RL literature. We show that the OPD value function admits a closed form as the per-token negative reverse KL divergence between the student and the teacher, available directly from the already-computed forward pass with no additional critic or inference. Existing stabilization methods either compute the full token-level reverse KL over the entire vocabulary, adding significant overhead, or restrict it to a top-k support, biasing the objective. vOPD instead preserves the lightweight single-sample estimator, subtracting the value function as a detached baseline to keep the gradient unbiased while reducing variance. Furthermore, we show that a top-k approximation of the baseline further lowers cost without compromising performance. Across mathematical and scientific reasoning benchmarks, vOPD consistently outperforms vanilla OPD and matches the most expensive full-vocabulary baseline, offering an efficient stabilization of On-Policy Distillation through principled RL variance reduction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces vOPD, a variance-reduced variant of On-Policy Distillation (OPD) for LLMs. It frames the OPD objective J(θ) = E[sum_t KL(π_θ(·|s_t) || π_teacher(·|s_t))] as a policy-gradient RL problem and proposes a control-variate baseline given by the per-token negative reverse KL, which is asserted to be available directly from the forward pass with no extra computation or critic. The method subtracts this detached baseline from the single-sample Monte Carlo estimator to reduce variance while preserving unbiasedness, and further applies a top-k approximation to the baseline for lower cost. Experiments on mathematical and scientific reasoning benchmarks show vOPD outperforming vanilla OPD and matching the performance of the more expensive full-vocabulary KL baseline.
Significance. If the closed-form baseline is correctly derived and the empirical gains are robust, vOPD would supply a lightweight, theoretically grounded stabilization technique for OPD that avoids both the overhead of full-vocabulary KL computation and the bias of restricted-support approximations. The explicit use of RL control-variate machinery inside distillation is a clean idea that could generalize to other on-policy objectives in LLM post-training.
major comments (2)
- [Abstract] Abstract: The claim that 'the OPD value function admits a closed form as the per-token negative reverse KL divergence' is load-bearing for the unbiasedness argument. Under the stated objective, the true value function satisfies the Bellman relation V(s_t) = -KL(s_t) + E[V(s_{t+1}) | s_t] (assuming maximization of -J). Using only the instantaneous term as the baseline is not the value function unless future expected KL terms are identically zero or the derivation explicitly treats the return as myopic; either case requires a detailed derivation showing why the gradient estimator remains unbiased and why variance is reduced.
- [Abstract] Abstract and method description: The paper states that subtracting the (detached) baseline 'keeps the gradient unbiased while reducing variance.' Because the per-token KL is a function of the state s_t only (not the sampled action a_t), any state-dependent baseline preserves unbiasedness in principle. However, if the baseline is set exactly to the instantaneous KL term that appears in the estimator, the resulting multiplier becomes zero for that component, which would nullify the contribution of the current token; the manuscript must clarify the precise form of the return estimator and the subtraction to avoid this degeneracy.
minor comments (3)
- The experimental protocol (number of seeds, statistical tests, exact hyper-parameters for the top-k approximation) is not described in sufficient detail to allow reproduction or to assess whether the reported gains are statistically significant.
- Ablation results isolating the contribution of the baseline versus the top-k approximation would strengthen the empirical claims; currently only aggregate benchmark numbers are referenced.
- Notation for the single-sample estimator and the precise control-variate formula should be given explicitly (e.g., as an equation) rather than described only in prose.
Simulated Author's Rebuttal
We thank the referee for their thorough review and constructive comments on our work. We believe the suggested clarifications will strengthen the presentation of the theoretical foundations of vOPD. We address the major comments point-by-point below and plan to incorporate the necessary revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that 'the OPD value function admits a closed form as the per-token negative reverse KL divergence' is load-bearing for the unbiasedness argument. Under the stated objective, the true value function satisfies the Bellman relation V(s_t) = -KL(s_t) + E[V(s_{t+1}) | s_t] (assuming maximization of -J). Using only the instantaneous term as the baseline is not the value function unless future expected KL terms are identically zero or the derivation explicitly treats the return as myopic; either case requires a detailed derivation showing why the gradient estimator remains unbiased and why variance is reduced.
Authors: We thank the referee for this observation. Our derivation shows that the control variate baseline corresponds to the negative reverse KL, which arises as the expected per-token reward when sampling actions from the teacher distribution rather than the student. This choice ensures the baseline is state-dependent only and thus preserves unbiasedness of the policy gradient estimator. Although the standard value function under a myopic reward of -KL would follow the mentioned Bellman equation, our setup uses the pointwise log-ratio as the reward signal for the single-sample estimator. We will include a detailed step-by-step derivation in the revised manuscript that demonstrates the unbiasedness and variance reduction properties explicitly, addressing the myopic vs. non-myopic aspects. revision: yes
-
Referee: [Abstract] Abstract and method description: The paper states that subtracting the (detached) baseline 'keeps the gradient unbiased while reducing variance.' Because the per-token KL is a function of the state s_t only (not the sampled action a_t), any state-dependent baseline preserves unbiasedness in principle. However, if the baseline is set exactly to the instantaneous KL term that appears in the estimator, the resulting multiplier becomes zero for that component, which would nullify the contribution of the current token; the manuscript must clarify the precise form of the return estimator and the subtraction to avoid this degeneracy.
Authors: We appreciate the need for this clarification. In our method, the single-sample estimator uses the pointwise reward r(a_t, s_t) = log(π_θ(a_t|s_t)) - log(π_teacher(a_t|s_t)), and the baseline is the negative reverse KL, which equals the expectation of r under the teacher distribution: b(s_t) = E_{a ~ π_teacher} [r(a, s_t)]. The adjusted multiplier is therefore r(a_t, s_t) - b(s_t), which is nonzero in general since the sampled action a_t is drawn from the student policy, not the teacher. This does not lead to degeneracy. We will update the method section and abstract to explicitly define the return estimator, the baseline, and the subtraction operation to make this clear. revision: yes
Circularity Check
No significant circularity; derivation applies standard RL variance reduction to existing OPD terms.
full rationale
The paper identifies the per-token reverse KL (already computed in the distillation forward pass) as the value function for a control-variate baseline and invokes canonical RL theory for unbiased gradient reduction. This identification is presented as a direct mathematical consequence rather than a redefinition of inputs as outputs. No self-citation chains, fitted parameters renamed as predictions, ansatz smuggling, or uniqueness theorems are load-bearing. The top-k baseline approximation is an efficiency step that does not alter the core derivation. The central claim remains independent of its own fitted values and is self-contained against external RL benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Casting on-policy distillation as a policy-gradient reinforcement learning problem permits the direct application of control-variate variance reduction.
- domain assumption The value function for the OPD objective has a closed-form expression equal to the per-token negative reverse KL divergence between student and teacher.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
V^πθ(ct) = E[rt(ct,yt)] = -DKL(πθ(·|ct) || πT(·|ct)) ... subtracting the value function as a detached baseline
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
casts OPD as policy-gradient RL ... single-sample Monte Carlo estimator
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Gkd: Generalized knowledge distillation for auto- regressive sequence models,
Rishabh Agarwal, Nino Vieillard, Yongchao Zhou, Piotr Stanczyk, Sabela Ramos Garea, Matthieu Geist, and Olivier Bachem. On-policy distillation of language models: Learning from self-generated mistakes. InInternational Conference on Learning Representations, 2024. URL https://arxiv.org/abs/2306.13649
-
[2]
Back to basics: Revisiting reinforce-style optimization for learning from human feedback in llms
Arash Ahmadian, Chris Cremer, Matthias Gallé, Marzieh Fadaee, Julia Kreutzer, Olivier Pietquin, Ahmet Üstün, and Sara Hooker. Back to basics: Revisiting reinforce-style optimization for learning from human feedback in llms. InAnnual Meeting of the Association for Computa- tional Linguistics, 2024. URLhttps://aclanthology.org/2024.acl-long.662/
work page 2024
-
[3]
MiniMax-M1: Scaling Test-Time Compute Efficiently with Lightning Attention
Aili Chen, Aonian Li, Bangwei Gong, Binyang Jiang, Bo Fei, Bo Yang, Boji Shan, Changqing Yu, Chao Wang, Cheng Zhu, et al. Minimax-m1: Scaling test-time compute efficiently with lightning attention.arXiv preprint arXiv:2506.13585, 2025. URL https://arxiv.org/abs/ 2506.13585
work page internal anchor Pith review arXiv 2025
-
[4]
Deepseek-v4: Towards highly efficient million-token context intelligence,
DeepSeek-AI. Deepseek-v4: Towards highly efficient million-token context intelligence,
-
[5]
URL https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro/blob/main/ DeepSeek_V4.pdf
-
[6]
Sciknoweval: Evaluating multi-level scientific knowledge of large language models
Kehua Feng, Xinyi Shen, Weijie Wang, Xiang Zhuang, Yuqi Tang, Qiang Zhang, and Keyan Ding. Sciknoweval: Evaluating multi-level scientific knowledge of large language models. arXiv preprint arXiv:2406.09098, 2024. URLhttps://arxiv.org/abs/2406.09098
-
[7]
Evan Greensmith, Peter L. Bartlett, and Jonathan Baxter. Variance reduction techniques for gradient estimates in reinforcement learning.Journal of Machine Learning Research, 2004. URLhttps://www.jmlr.org/papers/volume5/greensmith04a/greensmith04a.pdf
work page 2004
-
[8]
MiniLLM: On-Policy Distillation of Large Language Models
Yuxian Gu, Li Dong, Furu Wei, and Minlie Huang. MiniLLM: Knowledge distillation of large language models. InInternational Conference on Learning Representations, 2024. URL https://arxiv.org/abs/2306.08543
work page internal anchor Pith review arXiv 2024
-
[9]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025. URL https: //arxiv.org/abs/2501.12948
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Measuring Mathematical Problem Solving With the MATH Dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the MATH dataset. InAdvances in Neural Information Processing Systems Datasets and Benchmarks Track, 2021. URLhttps://arxiv.org/abs/2103.03874
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[11]
LoRA: Low-Rank Adaptation of Large Language Models
Edward J Hu, yelong shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models. In International Conference on Learning Representations, 2022. URL https://arxiv.org/ abs/2106.09685
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[12]
Reinforcement Learning via Self-Distillation
Jonas Hübotter, Frederike Lübeck, Lejs Behric, Anton Baumann, Marco Bagatella, Daniel Marta, Ido Hakimi, Idan Shenfeld, Thomas Kleine Buening, Carlos Guestrin, et al. Reinforcement learning via self-distillation.arXiv preprint arXiv:2601.20802, 2026. URL https://arxiv. org/abs/2601.20802
work page internal anchor Pith review arXiv 2026
-
[13]
Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richardson, Ahmed El-Kishky, Aiden Low, Alec Helyar, Aleksander Madry, Alex Beutel, Alex Carney, et al. Openai o1 system card.arXiv preprint arXiv:2412.16720, 2024. URLhttps://arxiv.org/abs/2412.16720
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
Entropy-aware on-policy distillation of language models
Woogyeol Jin, Taywon Min, Yongjin Yang, Swanand Ravindra Kadhe, Yi Zhou, Dennis Wei, Nathalie Baracaldo, and Kimin Lee. Entropy-aware on-policy distillation of language models. arXiv preprint arXiv:2603.07079, 2026. URLhttps://arxiv.org/abs/2603.07079
-
[15]
Dhillon, David Brandfonbrener, and Rishabh Agarwal
Devvrit Khatri, Lovish Madaan, Rishabh Tiwari, Rachit Bansal, Sai Surya Duvvuri, Manzil Zaheer, Inderjit S Dhillon, David Brandfonbrener, and Rishabh Agarwal. The art of scaling reinforcement learning compute for llms.arXiv preprint arXiv:2510.13786, 2025. URL https://arxiv.org/abs/2510.13786. 11
-
[16]
Why Does Self-Distillation (Sometimes) Degrade the Reasoning Capability of LLMs?
Jeonghye Kim, Xufang Luo, Minbeom Kim, Sangmook Lee, Dohyung Kim, Jiwon Jeon, Dongsheng Li, and Yuqing Yang. Why does self-distillation (sometimes) degrade the reasoning capability of llms?arXiv preprint arXiv:2603.24472, 2026. URL https://arxiv.org/abs/ 2603.24472
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[17]
arXiv preprint arXiv:2603.11137 , year =
Jongwoo Ko, Sara Abdali, Young Jin Kim, Tianyi Chen, and Pashmina Cameron. Scaling reasoning efficiently via relaxed on-policy distillation.arXiv preprint arXiv:2603.11137, 2026. URLhttps://arxiv.org/abs/2603.11137
-
[18]
Efficient Memory Management for Large Language Model Serving with PagedAttention
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention. InProceedings of the 29th symposium on operating systems principles, 2023. URLhttps://arxiv.org/pdf/2309.06180
work page internal anchor Pith review arXiv 2023
-
[19]
Tulu 3: Pushing Frontiers in Open Language Model Post-Training
Nathan Lambert, Jacob Morrison, Valentina Pyatkin, Shengyi Huang, Hamish Ivison, Faeze Brahman, Lester James V Miranda, Alisa Liu, Nouha Dziri, Shane Lyu, et al. Tulu 3: Pushing frontiers in open language model post-training.arXiv preprint arXiv:2411.15124, 2024. URL https://arxiv.org/abs/2411.15124
work page internal anchor Pith review arXiv 2024
-
[20]
Solving Quantitative Reasoning Problems with Language Models
Aitor Lewkowycz, Anders Andreassen, David Dohan, Ethan Dyer, Henryk Michalewski, Vinay Ramasesh, Ambrose Slone, Cem Anil, Imanol Schlag, Theo Gutman-Solo, et al. Solving quantitative reasoning problems with language models. InAdvances in Neural Information Processing Systems, 2022. URLhttps://arxiv.org/abs/2206.14858
work page internal anchor Pith review arXiv 2022
-
[22]
URLhttps://arxiv.org/abs/2604.13016
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step. In International Conference on Learning Representations, 2024. URL https://arxiv.org/ abs/2305.20050
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
Part i: Tricks or traps? a deep dive into rl for llm reasoning, 2025
Zihe Liu, Jiashun Liu, Yancheng He, Weixun Wang, Jiaheng Liu, Ling Pan, Xinyu Hu, Shaopan Xiong, Ju Huang, Jian Hu, Shengyi Huang, Siran Yang, Jiamang Wang, Wenbo Su, and Bo Zheng. Tricks or traps? a deep dive into RL for LLM reasoning. InInternational Conference on Learning Representations, 2026. URLhttps://arxiv.org/abs/2508.08221
-
[25]
https://thinkingmachines.ai/blog/ on-policy-distillation/
Kevin Lu and Thinking Machines Lab. On-policy distillation.Thinking Machines Lab: Connec- tionism, 2025. doi: 10.64434/tml.20251026. URL https://thinkingmachines.ai/blog/ on-policy-distillation
-
[26]
American Invitational Mathematics Examination, 2026
Mathematical Association of America. American Invitational Mathematics Examination, 2026. URLhttps://maa.org/maa-invitational-competitions/
work page 2026
-
[27]
American Mathematics Competitions, 2026
Mathematical Association of America. American Mathematics Competitions, 2026. URL https://maa.org/student-programs/amc/
work page 2026
-
[28]
Asynchronous methods for deep reinforcement learning.arXiv preprint arXiv:1602.01783,
V olodymyr Mnih, Adria Puigdomenech Badia, Mehdi Mirza, Alex Graves, Timothy Lilli- crap, Tim Harley, David Silver, and Koray Kavukcuoglu. Asynchronous methods for deep reinforcement learning. InInternational conference on machine learning, 2016. URL https://arxiv.org/abs/1602.01783
-
[29]
Team Olmo, Allyson Ettinger, Amanda Bertsch, Bailey Kuehl, David Graham, David Heineman, Dirk Groeneveld, Faeze Brahman, Finbarr Timbers, Hamish Ivison, et al. Olmo 3.arXiv preprint arXiv:2512.13961, 2025. URLhttps://arxiv.org/abs/2512.13961
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
Training language mod- els to follow instructions with human feedback
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language mod- els to follow instructions with human feedback. InAdvances in Neural Information Pro- cessing Systems, 2022. URL https://proceedings.neurips.cc/paper/2022/hash/ b1efde53be364a73914f588...
work page 2022
-
[31]
Unlocking on-policy distillation for any model family, 2025
Carlos Miguel Patiño, Kashif Rasul, Quentin Gallouédec, Ben Burtenshaw, Sergio Paniego, Vaibhav Srivastav, Thibaud Frere, Ed Beeching, Lewis Tunstall, Leandro von Werra, and Thomas Wolf. Unlocking on-policy distillation for any model family, 2025. URL https: //huggingface.co/spaces/HuggingFaceH4/on-policy-distillation
work page 2025
-
[32]
Marc’Aurelio Ranzato, Sumit Chopra, Michael Auli, and Wojciech Zaremba. Sequence level training with recurrent neural networks. InInternational Conference on Learning Representa- tions, 2016. URLhttps://arxiv.org/abs/1511.06732
-
[33]
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R. Bowman. GPQA: A graduate-level google-proof q&a benchmark. InConference on Language Modeling, 2024. URL https://arxiv.org/abs/ 2311.12022
work page internal anchor Pith review arXiv 2024
-
[34]
High-Dimensional Continuous Control Using Generalized Advantage Estimation
John Schulman, Philipp Moritz, Sergey Levine, Michael Jordan, and Pieter Abbeel. High- dimensional continuous control using generalized advantage estimation. InInternational Con- ference on Learning Representations, 2016. URLhttps://arxiv.org/abs/1506.02438
work page internal anchor Pith review arXiv 2016
-
[35]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017. URL https://arxiv. org/abs/1707.06347
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[36]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024. URL https: //arxiv.org/abs/2402.03300
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[37]
Self-Distillation Enables Continual Learning
Idan Shenfeld, Mehul Damani, Jonas Hübotter, and Pulkit Agrawal. Self-distillation enables continual learning.arXiv preprint arXiv:2601.19897, 2026. URL https://arxiv.org/abs/ 2601.19897
work page internal anchor Pith review arXiv 2026
-
[38]
Policy gradient methods for reinforcement learning with function approximation
Richard S Sutton, David McAllester, Satinder Singh, and Yishay Mansour. Policy gradient methods for reinforcement learning with function approximation. InAdvances in Neural Information Processing Systems, 1999. URL https://proceedings.neurips.cc/paper_ files/paper/1999/file/464d828b85b0bed98e80ade0a5c43b0f-Paper.pdf
work page 1999
-
[39]
arXiv preprint arXiv:2506.09477 , year=
Yunhao Tang and Rémi Munos. On a few pitfalls in kl divergence gradient estimation for rl. arXiv preprint arXiv:2506.09477, 2025. URLhttps://arxiv.org/abs/2506.09477
-
[40]
Kimi Team, Angang Du, Bofei Gao, Bowei Xing, Changjiu Jiang, Cheng Chen, Cheng Li, Chenjun Xiao, Chenzhuang Du, Chonghua Liao, et al. Kimi k1. 5: Scaling reinforcement learning with llms.arXiv preprint arXiv:2501.12599, 2025. URL https://arxiv.org/abs/ 2501.12599
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[41]
TRL: Transformers Rein- forcement Learning, 2020
Leandro von Werra, Younes Belkada, Lewis Tunstall, Edward Beeching, Tristan Thrush, Nathan Lambert, Shengyi Huang, Kashif Rasul, and Quentin Gallouédec. TRL: Transformers Rein- forcement Learning, 2020. URLhttps://github.com/huggingface/trl
work page 2020
-
[42]
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, brian ichter, Fei Xia, Ed H. Chi, Quoc V Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models. InAdvances in Neural Information Processing Systems, 2022. URL https: //arxiv.org/abs/2201.11903
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[43]
Ronald J Williams. Simple statistical gradient-following algorithms for connectionist reinforce- ment learning.Machine learning, 8(3):229–256, 1992. URL https://link.springer.com/ content/pdf/10.1007/BF00992696.pdf
-
[44]
Single-stream policy optimization.arXiv preprint arXiv:2509.13232,
Zhongwen Xu and Zihan Ding. Single-stream policy optimization. InInternational Conference on Learning Representations, 2026. URLhttps://arxiv.org/abs/2509.13232
-
[45]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025. URLhttps://arxiv.org/abs/2505.09388. 13
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[46]
Zhuolin Yang, Zihan Liu, Yang Chen, Wenliang Dai, Boxin Wang, Sheng-Chieh Lin, Chankyu Lee, Yangyi Chen, Dongfu Jiang, Jiafan He, et al. Nemotron-cascade 2: Post-training llms with cascade rl and multi-domain on-policy distillation.arXiv preprint arXiv:2603.19220, 2026. URLhttps://arxiv.org/abs/2603.19220
-
[47]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, YuYue, Weinan Dai, Tiantian Fan, Gaohong Liu, Juncai Liu, LingJun Liu, Xin Liu, Haibin Lin, Zhiqi Lin, Bole Ma, Guangming Sheng, Yuxuan Tong, Chi Zhang, Mofan Zhang, Ru Zhang, Wang Zhang, Hang Zhu, Jinhua Zhu, Jiaze Chen, Jiangjie Chen, Chengyi Wang, Hongli Yu, Yuxuan Song, Xiangpeng Wei, Hao ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[48]
GLM-5: from Vibe Coding to Agentic Engineering
Aohan Zeng, Xin Lv, Zhenyu Hou, Zhengxiao Du, Qinkai Zheng, Bin Chen, Da Yin, Chendi Ge, Chenghua Huang, Chengxing Xie, et al. Glm-5: from vibe coding to agentic engineering. arXiv preprint arXiv:2602.15763, 2026. URLhttps://arxiv.org/abs/2602.15763
work page internal anchor Pith review arXiv 2026
-
[49]
Dongxu Zhang, Zhichao Yang, Sepehr Janghorbani, Jun Han, Andrew Ressler II, Qian Qian, Gregory D Lyng, Sanjit Singh Batra, and Robert E Tillman. Fast and effective on-policy distillation from reasoning prefixes.arXiv preprint arXiv:2602.15260, 2026. URL https: //arxiv.org/abs/2602.15260
-
[50]
The Illusion of Certainty: Decoupling Capability and Calibration in On-Policy Distillation
Jiaxin Zhang, Xiangyu Peng, Qinglin Chen, Qinyuan Ye, Caiming Xiong, and Chien-Sheng Wu. The illusion of certainty: Decoupling capability and calibration in on-policy distillation.arXiv preprint arXiv:2604.16830, 2026. URLhttps://arxiv.org/abs/2604.16830
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[51]
Group Sequence Policy Optimization
Chujie Zheng, Shixuan Liu, Mingze Li, Xiong-Hui Chen, Bowen Yu, Chang Gao, Kai Dang, Yuqiong Liu, Rui Men, An Yang, et al. Group sequence policy optimization.arXiv preprint arXiv:2507.18071, 2025. URLhttps://arxiv.org/abs/2507.18071. 14 A Theoretical Derivations This appendix provides derivations omitted from § 2 and § 3. Following the main sections, we d...
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.