DebFilter: Eradicating Biases Stashed in Value
Pith reviewed 2026-06-29 13:19 UTC · model grok-4.3
The pith
DebFilter reduces social biases in text-to-image diffusion models by applying a fixed offset to value components in cross-attention.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
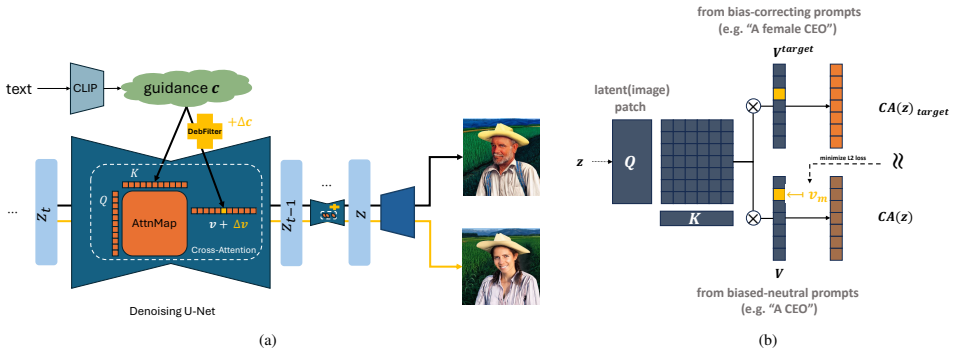
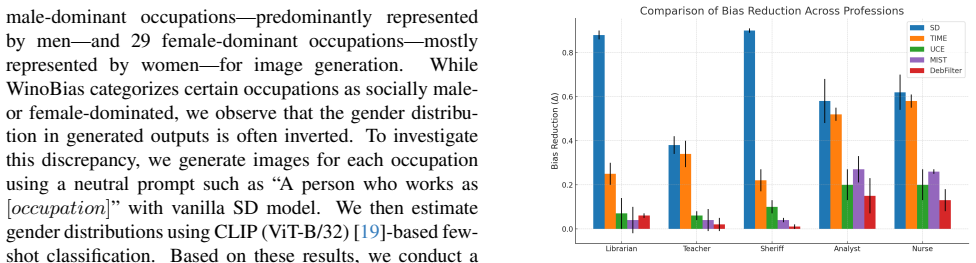
Observing that error prediction at each denoising step is primarily influenced by cross-attention dynamics, DebFilter applies a fixed offset to the slice of the guidance embedding in the value components of cross-attention. This adjustment reconfigures the score landscape to produce balanced outputs while maintaining alignment with the intended text semantics, mitigating biases related to gender and age in generated images.
What carries the argument
The bias-correction strategy that applies a fixed offset to the value components within cross-attention to steer semantic direction toward unbiased representations.
If this is right
- The method operates entirely at inference time with no additional training data or model updates.
- It produces balanced outputs for social bias categories like gender and age while keeping alignment with input text.
- It offers a scalable alternative to fine-tuning approaches for fairer text-to-image generation.
- The adjustment reconfigures the score landscape without altering the diffusion model's core parameters.
Where Pith is reading between the lines
- The offset approach might extend to other bias types beyond gender and age if cross-attention remains the dominant influence at each step.
- Similar value adjustments could be tested in related generative tasks like text-to-video to check transferability.
- If the offset choice proves sensitive to prompt wording, automated selection rules based on embedding statistics might be needed for broader use.
Load-bearing premise
The model's error prediction at each denoising step is primarily influenced by cross-attention dynamics, and a fixed offset can be chosen to reduce bias without distorting intended semantics.
What would settle it
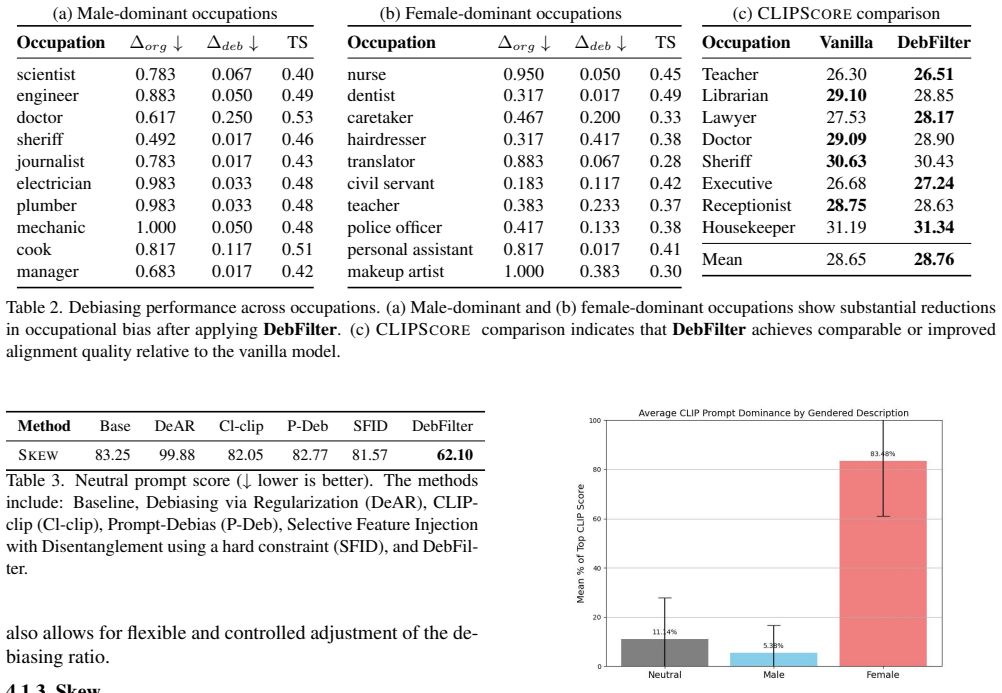
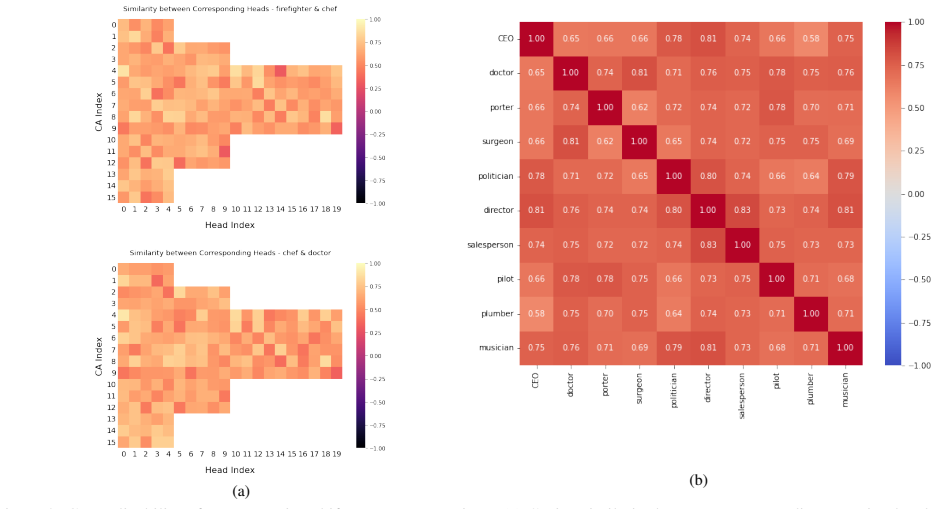
Generate images from prompts with known gender or age stereotypes before and after applying the offset, then measure if bias metrics (such as demographic parity in outputs) show no reduction or if text-image alignment scores drop substantially.
Figures



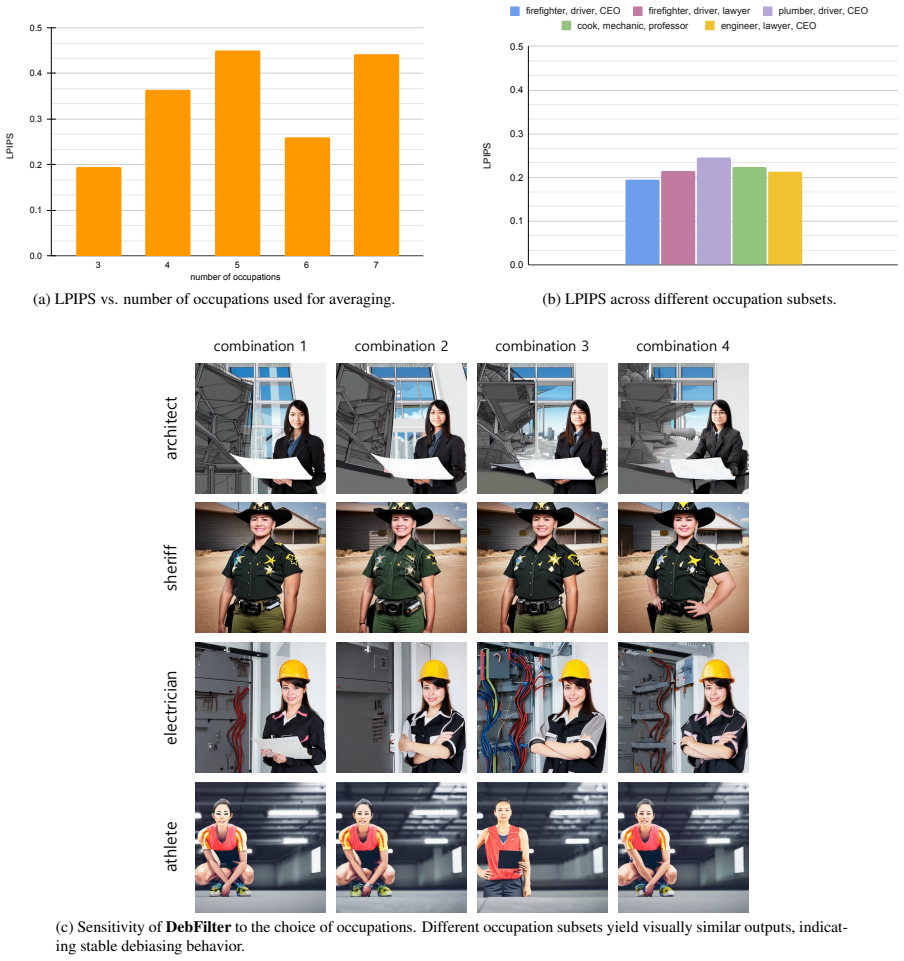




read the original abstract
Text-to-image diffusion models, which are theoretically equivalent to score-based generative models, generate images through a multi-step denoising process guided by text embeddings extracted from pretrained vision-language models such as CLIP. However, these text embeddings inherently encode social and semantic biases -- such as those related to gender and age -- that are subsequently propagated and amplified through the guidance mechanism, along with the model's training on large-scale datasets that are imbalanced with respect to these bias-related concepts, often leading to skewed outputs in text-to-image generation. We propose DebFilter, a lightweight and training-free framework for mitigating such biases in text-to-image diffusion models. Observing that the model's error prediction at each denoising step is primarily influenced by cross-attention dynamics, we introduce a bias-correction strategy that adjusts the value components within cross-attention. Specifically, we apply a fixed offset to the slice of guidance embedding, effectively steering the semantic direction of cross-attention values toward unbiased representations. This adjustment reconfigures the score landscape to produce balanced outputs while maintaining alignment with the intended text semantics. Unlike prior approaches that rely on fine-tuning or retraining, DebFilter operates entirely at inference time, requiring no additional data or model updates. Our results demonstrate that this method effectively mitigates social biases in generated images, offering an efficient and scalable pathway toward fairer and more inclusive text-to-image generation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes DebFilter, a lightweight training-free method for mitigating social biases (e.g., gender, age) in text-to-image diffusion models. It asserts that error prediction at each denoising step is primarily driven by cross-attention dynamics, and therefore applies a fixed offset to the value slice of the guidance embedding inside cross-attention. This is claimed to reconfigure the score landscape toward unbiased outputs while preserving prompt semantics, all at inference time with no additional training or data.
Significance. If the central claims were substantiated, the approach would be significant as a simple, parameter-light, inference-only intervention that avoids the cost of fine-tuning or retraining. Such a method could be broadly applicable to existing diffusion pipelines. However, the manuscript supplies neither a derivation of the offset strategy, an ablation isolating cross-attention, nor any quantitative results, so the practical significance cannot be evaluated from the current text.
major comments (3)
- [Abstract] Abstract: The key premise that 'the model's error prediction at each denoising step is primarily influenced by cross-attention dynamics' is stated without derivation, ablation study, or supporting analysis. No equations, attention-map visualizations, or comparisons to self-attention / time-embedding contributions are provided, so the subsequent bias-correction strategy does not logically follow from demonstrated evidence.
- [Abstract] Abstract: The effectiveness claim ('Our results demonstrate that this method effectively mitigates social biases') is asserted without any experimental protocol, metrics (e.g., bias scores, FID, CLIP similarity), datasets, baselines, or quantitative tables. The central claim therefore rests on an unverified assertion rather than reported evidence.
- [Abstract] Abstract: The method is described as using a 'fixed offset' applied to the value slice, yet no definition, selection procedure, or robustness analysis for this offset is given. It is unclear whether the offset is prompt-independent, bias-type-independent, or chosen by any reproducible criterion.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major comment below and agree that the manuscript requires substantial revisions to provide the missing justifications and evidence.
read point-by-point responses
-
Referee: [Abstract] Abstract: The key premise that 'the model's error prediction at each denoising step is primarily influenced by cross-attention dynamics' is stated without derivation, ablation study, or supporting analysis. No equations, attention-map visualizations, or comparisons to self-attention / time-embedding contributions are provided, so the subsequent bias-correction strategy does not logically follow from demonstrated evidence.
Authors: We agree that the premise requires explicit supporting analysis in the manuscript. The revised version will include a derivation outline, attention-map visualizations, and ablations comparing cross-attention contributions to self-attention and time-embedding components. revision: yes
-
Referee: [Abstract] Abstract: The effectiveness claim ('Our results demonstrate that this method effectively mitigates social biases') is asserted without any experimental protocol, metrics (e.g., bias scores, FID, CLIP similarity), datasets, baselines, or quantitative tables. The central claim therefore rests on an unverified assertion rather than reported evidence.
Authors: The current manuscript is a concise conceptual proposal and does not contain the experimental details referenced in the abstract. We will add a complete experimental section with protocol, metrics (bias scores, FID, CLIP similarity), datasets, baselines, and quantitative results tables. revision: yes
-
Referee: [Abstract] Abstract: The method is described as using a 'fixed offset' applied to the value slice, yet no definition, selection procedure, or robustness analysis for this offset is given. It is unclear whether the offset is prompt-independent, bias-type-independent, or chosen by any reproducible criterion.
Authors: We agree the offset description is incomplete. The revised manuscript will explicitly define the offset, detail its selection procedure (including dependence on prompt or bias type), and include robustness analysis across prompts and bias categories. revision: yes
Circularity Check
No significant circularity; heuristic method with no derivational loop
full rationale
The paper advances a training-free inference-time adjustment (fixed offset to value slice in cross-attention) motivated by a stated empirical observation rather than any mathematical derivation. No equations appear that define a quantity in terms of itself, fit a parameter on one subset then relabel a related quantity as a prediction, or import uniqueness via self-citation. The central claim therefore does not reduce to its inputs by construction; effectiveness is asserted via results, not forced by the construction itself.
Axiom & Free-Parameter Ledger
free parameters (1)
- fixed offset
axioms (1)
- domain assumption The model's error prediction at each denoising step is primarily influenced by cross-attention dynamics
Reference graph
Works this paper leans on
-
[1]
Hritik Bansal, Da Yin, Masoud Monajatipoor, and Kai-Wei Chang. How well can text-to-image generative models un- derstand ethical natural language interventions? InProceed- ings of the 2022 Conference on Empirical Methods in Natu- ral Language Processing, pages 1358–1370, 2022. 3
2022
-
[2]
Man is to computer program- mer as woman is to homemaker? debiasing word embed- dings.Advances in neural information processing systems, 29, 2016
Tolga Bolukbasi, Kai-Wei Chang, James Y Zou, Venkatesh Saligrama, and Adam T Kalai. Man is to computer program- mer as woman is to homemaker? debiasing word embed- dings.Advances in neural information processing systems, 29, 2016. 2
2016
-
[3]
Attend-and-excite: Attention-based se- mantic guidance for text-to-image diffusion models.ACM Transactions on Graphics (TOG), 42(4):1–10, 2023
Hila Chefer, Yuval Alaluf, Yael Vinker, Lior Wolf, and Daniel Cohen-Or. Attend-and-excite: Attention-based se- mantic guidance for text-to-image diffusion models.ACM Transactions on Graphics (TOG), 42(4):1–10, 2023. 8, 9
2023
-
[4]
Reproducible scal- ing laws for contrastive language-image learning
Mehdi Cherti, Romain Beaumont, Ross Wightman, Mitchell Wortsman, Gabriel Ilharco, Cade Gordon, Christoph Schuh- mann, Ludwig Schmidt, and Jenia Jitsev. Reproducible scal- ing laws for contrastive language-image learning. InPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2818–2829, 2023. 3
2023
-
[5]
Dall-eval: Probing the reasoning skills and social biases of text-to- image generation models
Jaemin Cho, Abhay Zala, and Mohit Bansal. Dall-eval: Probing the reasoning skills and social biases of text-to- image generation models. InICCV, 2023. 5
2023
-
[6]
Imagenet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In2009 IEEE conference on computer vision and pattern recognition, pages 248–255. Ieee, 2009. 2
2009
-
[7]
Diffusion models beat gans on image synthesis.Advances in neural informa- tion processing systems, 34:8780–8794, 2021
Prafulla Dhariwal and Alexander Nichol. Diffusion models beat gans on image synthesis.Advances in neural informa- tion processing systems, 34:8780–8794, 2021. 3
2021
-
[8]
Unified concept editing in diffusion models
Rohit Gandikota, Hadas Orgad, Yonatan Belinkov, Joanna Materzy´nska, and David Bau. Unified concept editing in diffusion models. InProceedings of the IEEE/CVF Win- ter Conference on Applications of Computer Vision, pages 5111–5120, 2024. 3, 5, 6
2024
-
[9]
Facet: Fairness in computer vision evaluation benchmark
Laura Gustafson, Chloe Rolland, Nikhila Ravi, Quentin Du- val, Aaron Adcock, Cheng-Yang Fu, Melissa Hall, and Can- dace Ross. Facet: Fairness in computer vision evaluation benchmark. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 20370–20382, 2023. 6
2023
-
[10]
Prompt-to-Prompt Image Editing with Cross Attention Control
Amir Hertz, Ron Mokady, Jay Tenenbaum, Kfir Aberman, Yael Pritch, and Daniel Cohen-Or. Prompt-to-prompt im- age editing with cross attention control.arXiv preprint arXiv:2208.01626, 2022. 8, 9
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[11]
Classifier-Free Diffusion Guidance
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance.arXiv preprint arXiv:2207.12598, 2022. 2, 3
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[12]
Denoising dif- fusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising dif- fusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020. 2
2020
-
[13]
A unified debi- asing approach for vision-language models across modalities and tasks.Advances in Neural Information Processing Sys- tems, 37:21034–21058, 2024
Hoin Jung, Taeuk Jang, and Xiaoqian Wang. A unified debi- asing approach for vision-language models across modalities and tasks.Advances in Neural Information Processing Sys- tems, 37:21034–21058, 2024. 3, 7
2024
-
[14]
Auto-Encoding Variational Bayes
Diederik P Kingma. Auto-encoding variational bayes.arXiv preprint arXiv:1312.6114, 2013. 3
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[15]
Yumeng Li, Margret Keuper, Dan Zhang, and Anna Khoreva. Divide & bind your attention for improved generative seman- tic nursing.arXiv preprint arXiv:2307.10864, 2023. 8, 9
-
[16]
Microsoft coco: Common objects in context
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Doll´ar, and C Lawrence Zitnick. Microsoft coco: Common objects in context. In European conference on computer vision, pages 740–755. Springer, 2014. 2
2014
-
[17]
Edit- ing implicit assumptions in text-to-image diffusion models
Hadas Orgad, Bahjat Kawar, and Yonatan Belinkov. Edit- ing implicit assumptions in text-to-image diffusion models. arXiv:2303.08084, 2023. 3, 5, 6, 8
-
[18]
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas M ¨uller, Joe Penna, and Robin Rombach. Sdxl: Improving latent diffusion mod- els for high-resolution image synthesis.arXiv preprint arXiv:2307.01952, 2023. 7
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[19]
Learning transferable visual models from natural language supervi- sion
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervi- sion. InInternational conference on machine learning, pages 8748–8763. PMLR, 2021. 3, 6
2021
-
[20]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj ¨orn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022. 1
2022
-
[21]
U- net: Convolutional networks for biomedical image segmen- tation
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U- net: Convolutional networks for biomedical image segmen- tation. InMedical image computing and computer-assisted intervention–MICCAI 2015: 18th international conference, Munich, Germany, October 5-9, 2015, proceedings, part III 18, pages 234–241. Springer, 2015. 1
2015
-
[22]
Laion-5b: An open large-scale dataset for training next generation image-text models.Advances in Neural In- formation Processing Systems, 35:25278–25294, 2022
Christoph Schuhmann, Romain Beaumont, Richard Vencu, Cade Gordon, Ross Wightman, Mehdi Cherti, Theo Coombes, Aarush Katta, Clayton Mullis, Mitchell Worts- man, et al. Laion-5b: An open large-scale dataset for training next generation image-text models.Advances in Neural In- formation Processing Systems, 35:25278–25294, 2022. 2
2022
-
[23]
Dear: De- biasing vision-language models with additive residuals
Ashish Seth, Mayur Hemani, and Chirag Agarwal. Dear: De- biasing vision-language models with additive residuals. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition (CVPR), pages 12345–12354,
-
[24]
Denoising Diffusion Implicit Models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models.arXiv preprint arXiv:2010.02502, 2020. 2
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[25]
Generative modeling by esti- mating gradients of the data distribution.Advances in neural information processing systems, 32, 2019
Yang Song and Stefano Ermon. Generative modeling by esti- mating gradients of the data distribution.Advances in neural information processing systems, 32, 2019. 1, 2
2019
-
[26]
Score-Based Generative Modeling through Stochastic Differential Equations
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Ab- hishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equa- tions.arXiv preprint arXiv:2011.13456, 2020. 1, 2 9
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[27]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszko- reit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017. 4
2017
-
[28]
Jialu Wang, Yang Liu, and Xin Eric Wang. Are gender- neutral queries really gender-neutral? mitigating gender bias in image search.arXiv preprint arXiv:2109.05433, 2021. 2, 3
-
[29]
Hidir Yesiltepe, Kiymet Akdemir, and Pinar Yanardag. Mist: Mitigating intersectional bias with disentangled cross- attention editing in text-to-image diffusion models.arXiv preprint arXiv:2403.19738, 2024. 3
-
[30]
Iti- gen: Inclusive text-to-image generation
Cheng Zhang, Xuanbai Chen, Siqi Chai, Chen Henry Wu, Dmitry Lagun, Thabo Beeler, and Fernando De la Torre. Iti- gen: Inclusive text-to-image generation. InProceedings of the IEEE/CVF International Conference on Computer Vi- sion, pages 3969–3980, 2023. 3, 5
2023
-
[31]
Gender Bias in Coreference Resolution: Evaluation and Debiasing Methods
Jieyu Zhao, Tianlu Wang, Mark Yatskar, Vicente Ordonez, and Kai-Wei Chang. Gender bias in coreference resolu- tion: Evaluation and debiasing methods.arXiv preprint arXiv:1804.06876, 2018. 5 10 DebFilter: Eradicating Biases Stashed in Value Supplementary Material A. Configuration of Denoising U-Net Index of CA 1 2 3 4 5 6 7 8 Number of Heads 5 5 10 10 20 2...
work page internal anchor Pith review Pith/arXiv arXiv 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.