The Harder Text Embedding Benchmark (HTEB): Beyond One-dimensional Static Robustness
Pith reviewed 2026-06-29 12:40 UTC · model grok-4.3
The pith
Embedding robustness is multidimensional and requires dynamic evaluation to expose failures hidden by static benchmarks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
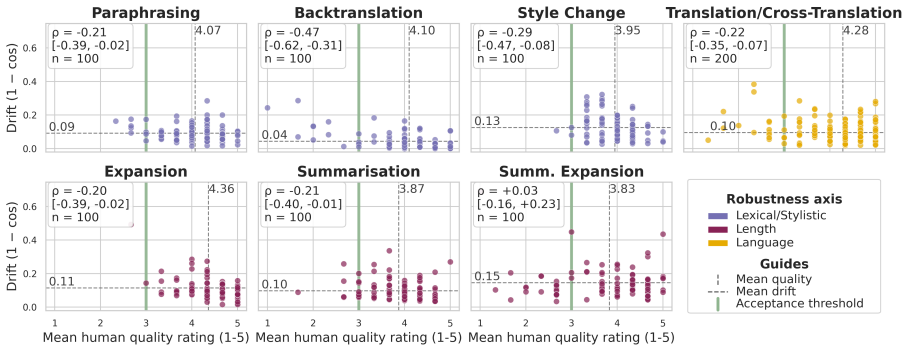
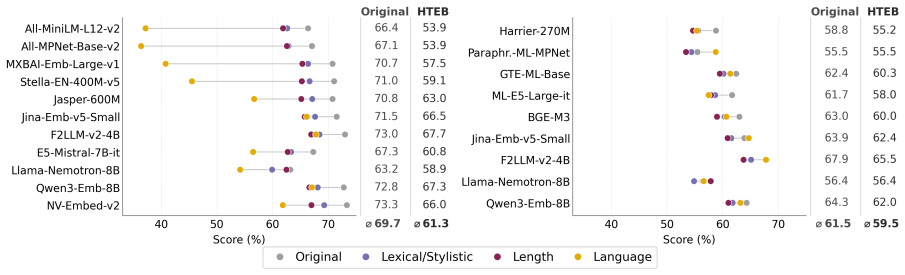
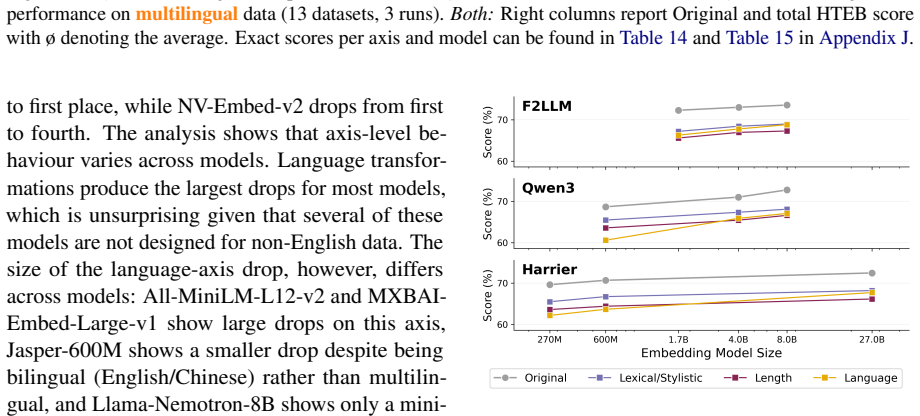
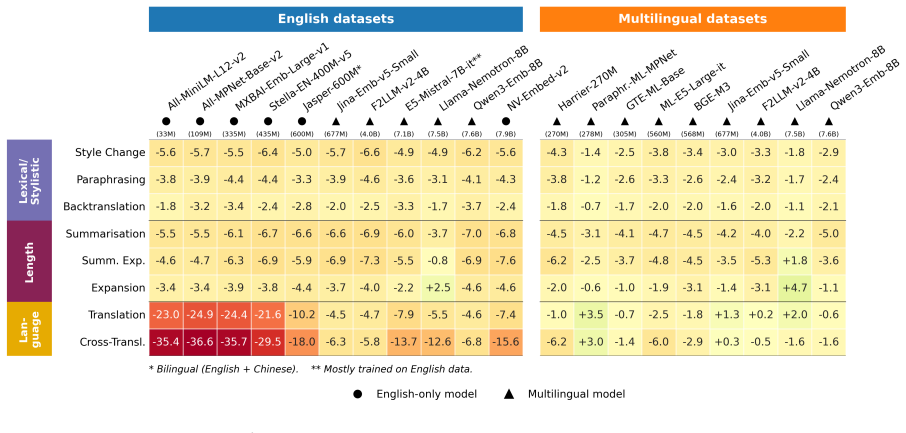
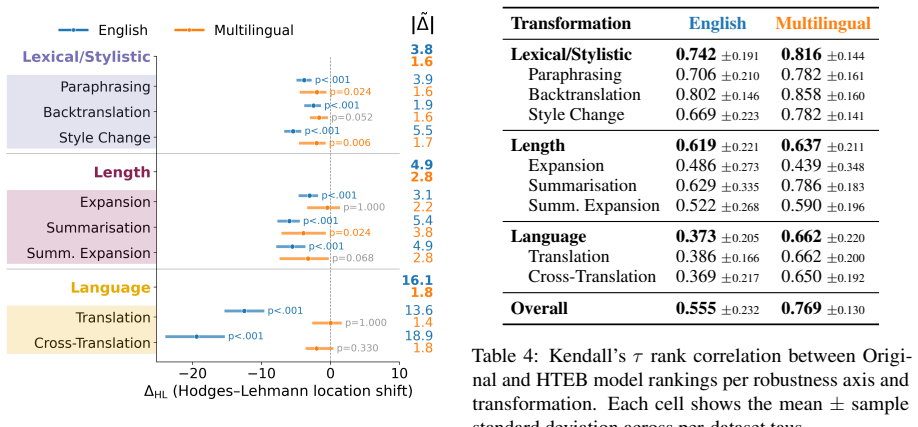
Embedding robustness is multidimensional because models respond differently to variations along lexical/stylistic, length, and language axes, and dynamic evaluation with stochastic LLM transformations at test time is needed to reveal weaknesses that static benchmarks miss. HTEB applies these transformations to 32 datasets covering 42 languages, validated by 4,800 human ratings on English data, and finds that models exhibit specific partly decoupled robustness profiles, that scale increases absolute scores but does not close the gap between original and transformed evaluations except on the language axis, and that English datasets are more sensitive to the transformations than multilingual on
What carries the argument
HTEB, a dynamic evaluation framework that applies stochastic LLM transformations to inputs at evaluation time along the Lexical/Stylistic, Length, and Language axes.
If this is right
- Models exhibit specific, partly decoupled robustness profiles across the lexical/stylistic, length, and language axes.
- Across model families, increasing scale raises absolute scores on both original and transformed inputs but does not close the performance gap except on the language axis.
- English datasets prove more sensitive to the HTEB transformations than multilingual datasets.
- Single-score embedding benchmarks miss distinctions in how models handle different types of variation.
Where Pith is reading between the lines
- Multilingual training data may confer robustness advantages that could be tested by comparing matched English-only and multilingual model pairs.
- Future benchmarks could report separate scores per axis rather than a single aggregate.
- Training objectives might be adjusted to target specific axes independently to improve overall robustness.
- The approach of on-the-fly stochastic transformations could extend to other NLP tasks such as classification or retrieval.
Load-bearing premise
The stochastic LLM transformations along the three axes represent practically relevant real-world variations without introducing artifacts, and the human ratings on an English subsample validate the transformations for all 42 languages and 32 datasets.
What would settle it
Finding that all tested models show identical robustness levels across the three axes or that increasing scale fully eliminates the performance difference between original and transformed inputs on every axis.
Figures





read the original abstract
Embedding benchmarks like MTEB report a single score per model, implicitly treating robustness as a static, scalar property. We argue that embedding robustness is multidimensional, since models respond differently to different types of variation, and requires dynamic evaluation to expose failures hidden by static benchmarks. We introduce the Harder Text Embedding Benchmark (HTEB), a dynamic evaluation framework that challenges model robustness along three practically interpretable axes (Lexical/Stylistic, Length and Language) by stochastically transforming inputs at evaluation time with an LLM. Evaluating 16 open-weight embedding models on 32 datasets covering 42 languages under transformations validated by 4,800 human ratings on an English subsample, we find three patterns: (1) Models exhibit specific, partly decoupled robustness profiles across axes. (2) Across three model families, scale increases absolute scores but does not close the gap between original and transformed evaluations. Here, scaling tends to improve specifically the Language axis. (3) English datasets are more sensitive to HTEB transformations than multilingual datasets. This demonstrates that HTEB identifies strengths and weaknesses of models along deployment-relevant axes, challenging current embedding benchmarks and arguing for multidimensional, dynamic robustness evaluation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that embedding robustness is multidimensional (models respond differently to different variations) rather than the static scalar property implied by MTEB, and introduces the Harder Text Embedding Benchmark (HTEB) as a dynamic framework. HTEB applies stochastic LLM transformations along three axes (Lexical/Stylistic, Length, Language) to inputs from 32 datasets covering 42 languages at evaluation time; after validation via 4,800 human ratings on an English subsample, evaluation of 16 open-weight models reveals three patterns: (1) specific partly decoupled robustness profiles across axes, (2) scale increases absolute scores but does not close gaps (except on the Language axis), and (3) English datasets are more sensitive than multilingual ones.
Significance. If the transformations are shown to be free of systematic artifacts across languages, HTEB would offer a practically useful dynamic evaluation tool that exposes robustness failures hidden by static benchmarks and could inform model selection and development along deployment-relevant axes.
major comments (1)
- [Abstract and evaluation description section] Abstract and evaluation description section: the central patterns (2) and (3) rest on the claim that LLM transformations produce comparable, practically relevant variations across 42 languages, yet the only external validation cited is 4,800 human ratings on an English subsample. No ratings, grammaticality checks, or artifact analysis are described for the remaining 41 languages or the full set of 32 datasets; if transformation quality (semantic fidelity, introduced bias, or grammaticality) varies systematically by language family or script, the reported higher English sensitivity and the Language-axis scaling effect could be driven by differential artifact rates rather than genuine robustness differences.
minor comments (1)
- The abstract refers to 'three model families' without naming them; the main text should explicitly list the families and the specific models within each to allow readers to assess whether the scale and axis-specific patterns generalize.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive feedback. The concern regarding the scope of human validation for the LLM transformations is well-taken and directly relevant to the strength of patterns (2) and (3). We address this point below and outline the revisions we will make.
read point-by-point responses
-
Referee: [Abstract and evaluation description section] Abstract and evaluation description section: the central patterns (2) and (3) rest on the claim that LLM transformations produce comparable, practically relevant variations across 42 languages, yet the only external validation cited is 4,800 human ratings on an English subsample. No ratings, grammaticality checks, or artifact analysis are described for the remaining 41 languages or the full set of 32 datasets; if transformation quality (semantic fidelity, introduced bias, or grammaticality) varies systematically by language family or script, the reported higher English sensitivity and the Language-axis scaling effect could be driven by differential artifact rates rather than genuine robustness differences.
Authors: We agree that the human validation is limited to an English subsample and that this constitutes a genuine limitation for claims involving cross-lingual comparisons. The 4,800 ratings were obtained on a stratified English subsample drawn from the 32 datasets to assess semantic fidelity, grammaticality, and absence of introduced bias for the three transformation axes. The same LLM (with language-specific prompts) was used to generate transformations for all 42 languages, which provides some consistency, but we did not perform equivalent human ratings or automated checks for non-English outputs. Consequently, it remains possible that differential artifact rates across language families or scripts contribute to the observed English sensitivity and the Language-axis scaling pattern. In the revised manuscript we will (a) explicitly state this limitation in both the abstract and the evaluation section, (b) add a dedicated paragraph in the Limitations section discussing the risk of language-specific artifacts and its implications for patterns (2) and (3), and (c) qualify the interpretation of the Language-axis results accordingly. We will not claim that the transformations have been shown to be free of systematic artifacts across all languages. revision: yes
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper introduces HTEB as a new dynamic benchmark using stochastic LLM transformations along three axes, with empirical patterns observed from evaluating 16 models on 32 datasets. The central claims rest on the external human validation (4,800 ratings on English subsample) and direct comparisons to the MTEB baseline, without any self-definitional loops, fitted parameters renamed as predictions, or load-bearing self-citations that reduce the result to its inputs by construction. No equations or uniqueness theorems are invoked that collapse the multidimensional robustness finding back to the benchmark definition itself. The derivation chain is independent and externally grounded.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Human ratings on an English subsample validate the quality and relevance of LLM transformations across all languages and datasets
Reference graph
Works this paper leans on
-
[1]
Mohamed Abdalla, Krishnapriya Vishnubhotla, and Saif Mohammad. 2023. https://doi.org/10.18653/v1/2023.eacl-main.55 What Makes Sentences Semantically Related ? A Textual Relatedness Dataset and Empirical Study . In Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics , pages 782--796, Dubrovnik, Croati...
-
[2]
David Ifeoluwa Adelani, Marek Masiak, Israel Abebe Azime, Jesujoba Alabi, Atnafu Lambebo Tonja, Christine Mwase, Odunayo Ogundepo, Bonaventure F. P. Dossou, Akintunde Oladipo, Doreen Nixdorf, Chris Chinenye Emezue, Sana Al-azzawi, Blessing Sibanda, Davis David, Lolwethu Ndolela, Jonathan Mukiibi, Tunde Ajayi, Tatiana Moteu, Brian Odhiambo, and 46 others. ...
-
[3]
Mohammad Kalim Akram, Saba Sturua, Nastia Havriushenko, Quentin Herreros, Michael Günther, Maximilian Werk, and Han Xiao. 2026. https://doi.org/10.48550/arXiv.2602.15547 jina-embeddings-v5-text: Task - Targeted Embedding Distillation . ArXiv:2602.15547
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2602.15547 2026
-
[4]
Adnan El Assadi, Isaac Chung, Roman Solomatin, Niklas Muennighoff, and Kenneth Enevoldsen. 2026. https://openreview.net/forum?id=rcmfu1ydAf HUME : Measuring the Human - Model Performance Gap in Text Embedding Tasks . In International Conference on Learning Representations
2026
- [5]
-
[6]
Iñigo Casanueva, Tadas Temčinas, Daniela Gerz, Matthew Henderson, and Ivan Vulić. 2020. https://doi.org/10.18653/v1/2020.nlp4convai-1.5 Efficient Intent Detection with Dual Sentence Encoders . In Proceedings of the 2nd Workshop on Natural Language Processing for Conversational AI , pages 38--45, Online. Association for Computational Linguistics
-
[7]
Daniel Cer, Mona Diab, Eneko Agirre, Iñigo Lopez-Gazpio, and Lucia Specia. 2017. https://doi.org/10.18653/v1/S17-2001 SemEval -2017 Task 1: Semantic Textual Similarity Multilingual and Crosslingual Focused Evaluation . In Proceedings of the 11th International Workshop on Semantic Evaluation ( SemEval -2017) , pages 1--14, Vancouver, Canada. Association fo...
-
[8]
Jianlyu Chen, Shitao Xiao, Peitian Zhang, Kun Luo, Defu Lian, and Zheng Liu. 2024. https://doi.org/10.18653/v1/2024.findings-acl.137 M3- Embedding : Multi - Linguality , Multi - Functionality , Multi - Granularity Text Embeddings Through Self - Knowledge Distillation . In Findings of the Association for Computational Linguistics : ACL 2024 , pages 2318--2...
-
[9]
Benjamin Clavié. 2024. https://doi.org/10.48550/arXiv.2312.16144 Towards Better Monolingual Japanese Retrievers with Multi - Vector Models . ArXiv:2312.16144
-
[10]
Arman Cohan, Sergey Feldman, Iz Beltagy, Doug Downey, and Daniel Weld. 2020. https://doi.org/10.18653/v1/2020.acl-main.207 SPECTER : Document -level representation learning using citation-informed transformers . In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics , pages 2270--2282. Association for Computational Linguistics
-
[11]
Ruchira Dhar and Anders Søgaard. 2026. https://arxiv.org/abs/2604.25923v1 Evaluation Revisited : A Taxonomy of Evaluation Concerns in Natural Language Processing . ArXiv:2604.25923
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[12]
Rotem Dror, Gili Baumer, Marina Bogomolov, and Roi Reichart. 2017. https://doi.org/10.1162/tacl_a_00074 Replicability Analysis for Natural Language Processing : Testing Significance with Multiple Datasets . Transactions of the Association for Computational Linguistics, 5:471--486
-
[13]
Rotem Dror, Gili Baumer, Segev Shlomov, and Roi Reichart. 2018. https://doi.org/10.18653/v1/P18-1128 The Hitchhiker 's Guide to Testing Statistical Significance in Natural Language Processing . In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics ( Volume 1: Long Papers ) , pages 1383--1392, Melbourne, Australia. Asso...
-
[14]
Bradley Efron and R. J. Tibshirani. 1994. https://doi.org/10.1201/9780429246593 An Introduction to the Bootstrap . Chapman and Hall/CRC, New York
-
[15]
Kenneth Enevoldsen, Isaac Chung, Imene Kerboua, Márton Kardos, Ashwin Mathur, David Stap, Jay Gala, Wissam Siblini, Dominik Krzemiński, Genta Indra Winata, Saba Sturua, Saiteja Utpala, Mathieu Ciancone, Marion Schaeffer, Diganta Misra, Shreeya Dhakal, Jonathan Rystrøm, Roman Solomatin, Ömer Veysel Çağatan, and 63 others. 2025. https://openreview.net/forum...
2025
-
[16]
Fabbri, Wojciech Kryściński, Bryan McCann, Caiming Xiong, Richard Socher, and Dragomir Radev
Alexander R. Fabbri, Wojciech Kryściński, Bryan McCann, Caiming Xiong, Richard Socher, and Dragomir Radev. 2021. https://doi.org/10.1162/tacl_a_00373 SummEval : Re -evaluating summarization evaluation . Transactions of the Association for Computational Linguistics, 9:391--409
-
[17]
Jack FitzGerald, Christopher Hench, Charith Peris, Scott Mackie, Kay Rottmann, Ana Sanchez, Aaron Nash, Liam Urbach, Vishesh Kakarala, Richa Singh, Swetha Ranganath, Laurie Crist, Misha Britan, Wouter Leeuwis, Gokhan Tur, and Prem Natarajan. 2023. https://doi.org/10.18653/v1/2023.acl-long.235 MASSIVE : A 1M - Example Multilingual Natural Language Understa...
-
[18]
Manuel Frank and Haithem Afli. 2026. https://doi.org/10.18653/v1/2026.eacl-long.130 PTEB : Towards robust text embedding evaluation via stochastic paraphrasing at evaluation time with LLMs . In Proceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics ( Volume 1: Long Papers ) , pages 2832--2851, Rabat, Mo...
-
[19]
Gemma Team , Aishwarya Kamath, Johan Ferret, Shreya Pathak, Nino Vieillard, Ramona Merhej, Sarah Perrin, Tatiana Matejovicova, Alexandre Ramé, Morgane Rivière, Louis Rouillard, Thomas Mesnard, Geoffrey Cideron, Jean-bastien Grill, Sabela Ramos, Edouard Yvinec, Michelle Casbon, Etienne Pot, Ivo Penchev, and 197 others. 2025. https://doi.org/10.48550/arXiv....
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2503.19786 2025
-
[20]
Mor Geva, Daniel Khashabi, Elad Segal, Tushar Khot, Dan Roth, and Jonathan Berant. 2021. https://doi.org/10.1162/tacl_a_00370 Did Aristotle use a laptop? A question answering benchmark with implicit reasoning strategies . Transactions of the Association for Computational Linguistics, 9:346--361
-
[21]
Danilo Giampiccolo, Bernardo Magnini, Ido Dagan, and Bill Dolan. 2007. https://aclanthology.org/W07-1401/ The third PASCAL recognizing textual entailment challenge . In Proceedings of the ACL - PASCAL Workshop on Textual Entailment and Paraphrasing , pages 1--9, Prague. Association for Computational Linguistics
2007
-
[22]
Samarth Goel, Reagan Lee, and Kannan Ramchandran. 2025. https://openreview.net/forum?id=p4f2G2XXR4 SAGE : A Realistic Benchmark for Semantic Understanding . In NeurIPS 2025 Workshop on Evaluating the Evolving LLM Lifecycle : Benchmarks , Emergent Abilities , and Scaling
2025
-
[23]
Kilem Li Gwet. 2008. https://doi.org/10.1348/000711006X126600 Computing inter-rater reliability and its variance in the presence of high agreement . British Journal of Mathematical and Statistical Psychology, 61(1):29--48
-
[24]
Minors of a Class of Riordan Arrays Related to Weighted Partial Motzkin Paths
Tim C. Hesterberg. 2015. https://doi.org/10.1080/00031305.2015.1089789 What Teachers Should Know About the Bootstrap : Resampling in the Undergraduate Statistics Curriculum . The American Statistician, 69(4):371--386
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1080/00031305.2015.1089789 2015
- [25]
-
[26]
Doris Hoogeveen, Karin M. Verspoor, and Timothy Baldwin. 2015. https://doi.org/10.1145/2838931.2838934 CQADupStack : a benchmark data set for community question-answering research . In Proceedings of the 20th Australasian Document Computing Symposium ( ADCS ) , pages 3:1--3:8, Parramatta, NSW, Australia. ACM
-
[27]
Yevhen Kostiuk and Kenneth Enevoldsen. 2026. https://doi.org/10.48550/arXiv.2605.22544 One prompt is not enough: Instruction Sensitivity Undermines Embedding Model Evaluation . ArXiv:2605.22544
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2605.22544 2026
-
[28]
Wuwei Lan, Siyu Qiu, Hua He, and Wei Xu. 2017. https://doi.org/10.18653/v1/D17-1126 A continuously growing dataset of sentential paraphrases . In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing , pages 1224--1234, Copenhagen, Denmark. Association for Computational Linguistics
-
[29]
Ken Lang. 1995. https://doi.org/10.1016/B978-1-55860-377-6.50048-7 NewsWeeder : Learning to Filter Netnews . In Machine Learning Proceedings 1995 , pages 331--339, San Francisco (CA). Morgan Kaufmann
-
[30]
Chankyu Lee, Rajarshi Roy, Mengyao Xu, Jonathan Raiman, Mohammad Shoeybi, Bryan Catanzaro, and Wei Ping. 2025. https://proceedings.iclr.cc/paper_files/paper/2025/hash/c4bf73386022473a652a18941e9ea6f8-Abstract-Conference.html NV - Embed : Improved Techniques for Training LLMs as Generalist Embedding Models . International Conference on Learning Representat...
2025
-
[31]
Sean Lee, Aamir Shakir, Darius Koenig, and Julius Lipp. 2024. https://www.mixedbread.ai/blog/mxbai-embed-large-v1 Open source strikes bread -- new fluffy embeddings model . (accessed 2025-12-19)
2024
-
[32]
Xianming Li and Jing Li. 2024. https://doi.org/10.18653/v1/2024.acl-long.101 AoE : Angle -optimized Embeddings for Semantic Textual Similarity . In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics ( Volume 1: Long Papers ) , pages 1825--1839, Bangkok, Thailand. Association for Computational Linguistics
-
[33]
Ji Lin, Jiaming Tang, Haotian Tang, Shang Yang, Wei-Ming Chen, Wei-Chen Wang, Guangxuan Xiao, Xingyu Dang, Chuang Gan, and Song Han. 2024. https://proceedings.mlsys.org/paper_files/paper/2024/hash/42a452cbafa9dd64e9ba4aa95cc1ef21-Abstract-Conference.html AWQ : Activation -aware Weight Quantization for On - Device LLM Compression and Acceleration . Proceed...
2024
-
[34]
Xueqing Liu, Chi Wang, Yue Leng, and ChengXiang Zhai. 2018. https://doi.org/10.1145/3283812.3283815 LinkSO : a dataset for learning to retrieve similar question answer pairs on software development forums . In Proceedings of the 4th ACM SIGSOFT international workshop on NLP for software engineering , Nl4se 2018, pages 2--5, Lake Buena Vista, FL, USA. Asso...
-
[35]
Lovish Madaan, Aaditya K. Singh, Rylan Schaeffer, Andrew Poulton, Sanmi Koyejo, Pontus Stenetorp, Sharan Narang, and Dieuwke Hupkes. 2024. https://doi.org/10.48550/arXiv.2406.10229 Quantifying Variance in Evaluation Benchmarks . ArXiv:2406.10229
-
[36]
Andani Madodonga, Vukosi Marivate, and Matthew Adendorff. 2023. https://doi.org/10.55492/dhasa.v4i01.4449 Izindaba- Tindzaba : Machine learning news categorisation for long and short text for isiZulu and Siswati . Journal of the Digital Humanities Association of Southern Africa (DHASA), 4(01)
-
[37]
Rahmad Mahendra, Alham Fikri Aji, Samuel Louvan, Fahrurrozi Rahman, and Clara Vania. 2021. https://aclanthology.org/2021.emnlp-main.821 IndoNLI : a natural language inference dataset for Indonesian . In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , pages 10511--10527, Online and Punta Cana, Dominican Republic. As...
2021
-
[38]
Microsoft. 2026. https://huggingface.co/microsoft/harrier-oss-v1-270m microsoft/harrier-oss-v1-270m · Hugging Face . (accessed 2026-05-13)
2026
-
[39]
Mistral AI . 2025. https://mistral.ai/news/mistral-3 Introducing Mistral 3 Mistral AI . (accessed 2025-12-18)
2025
-
[40]
MTEB. 2025. https://huggingface.co/datasets/mteb/PlscClusteringS2S.v2 Dataset PlscClusteringS2S .v2 . (accessed 2026-03-06)
2025
-
[41]
Niklas Muennighoff, Nouamane Tazi, Loic Magne, and Nils Reimers. 2023. https://doi.org/10.18653/v1/2023.eacl-main.148 MTEB : Massive Text Embedding Benchmark . In Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics , pages 2014--2037, Dubrovnik, Croatia. Association for Computational Linguistics
-
[42]
James O'Neill, Polina Rozenshtein, Ryuichi Kiryo, Motoko Kubota, and Danushka Bollegala. 2021. https://doi.org/10.18653/v1/2021.emnlp-main.568 I wish I would have loved this one, but I didn't – a multilingual dataset for counterfactual detection in product review . In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing ,...
-
[43]
Yulia Otmakhova, Thinh Hung Truong, Rahmad Mahendra, Zenan Zhai, Rongxin Zhu, Daniel Beck, and Jey Han Lau. 2026. https://doi.org/10.18653/v1/2026.findings-eacl.269 FLUKE : a linguistically-driven and task-agnostic framework for robustness evaluation . In Findings of the Association for Computational Linguistics : EACL 2026 , pages 5103--5123, Rabat, Moro...
-
[44]
Nedjma Ousidhoum, Shamsuddeen Muhammad, Mohamed Abdalla, Idris Abdulmumin, Ibrahim Ahmad, Sanchit Ahuja, Alham Aji, Vladimir Araujo, Abinew Ayele, Pavan Baswani, Meriem Beloucif, Chris Biemann, Sofia Bourhim, Christine Kock, Genet Dekebo, Oumaima Hourrane, Gopichand Kanumolu, Lokesh Madasu, Samuel Rutunda, and 8 others. 2024. https://doi.org/10.18653/v1/2...
-
[45]
Shantipriya Parida, Sambit Sekhar, Soumendra Kumar Sahoo, Swateek Jena, Abhijeet Parida, Satya Ranjan Dash, and Guneet Singh Kohli. 2023. https://huggingface.co/datasets/OdiaGenAI/sentiment_analysis_hindi OdiaGenAI : Generative AI and LLM initiative for the odia language - Dataset Card Sentiment Analysis Hindi . (accessed 2026-05-13)
2023
-
[46]
Gowtham Ramesh, Sumanth Doddapaneni, Aravinth Bheemaraj, Mayank Jobanputra, Raghavan AK, Ajitesh Sharma, Sujit Sahoo, Harshita Diddee, Mahalakshmi J, Divyanshu Kakwani, Navneet Kumar, Aswin Pradeep, Srihari Nagaraj, Kumar Deepak, Vivek Raghavan, Anoop Kunchukuttan, Pratyush Kumar, and Mitesh Shantadevi Khapra. 2022. https://doi.org/10.1162/tacl_a_00452 Sa...
-
[47]
Nils Reimers and Iryna Gurevych. 2017. https://doi.org/10.18653/v1/D17-1035 Reporting Score Distributions Makes a Difference : Performance Study of LSTM -networks for Sequence Tagging . In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing , pages 338--348, Copenhagen, Denmark. Association for Computational Linguistics
-
[48]
Nils Reimers and Iryna Gurevych. 2018. https://arxiv.org/abs/1803.09578 Why Comparing Single Performance Scores Does Not Allow to Draw Conclusions About Machine Learning Approaches . ArXiv:1803.09578
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[49]
Nils Reimers and Iryna Gurevych. 2019. https://doi.org/10.18653/v1/D19-1410 Sentence- BERT : Sentence Embeddings using Siamese BERT - Networks . In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing ( EMNLP - IJCNLP ) , pages 3982--3992, Hong Kong...
-
[50]
Nils Reimers and Iryna Gurevych. 2020. https://arxiv.org/abs/2004.09813 Making monolingual sentence embeddings multilingual using knowledge distillation . In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing , pages 4512--4525. Association for Computational Linguistics
-
[51]
Darsh Shah, Tao Lei, Alessandro Moschitti, Salvatore Romeo, and Preslav Nakov. 2018. https://doi.org/10.18653/v1/D18-1131 Adversarial domain adaptation for duplicate question detection . In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing , pages 1056--1063, Brussels, Belgium. Association for Computational Linguistics
-
[52]
Gizem Soğancıoğlu, Hakime Öztürk, and Arzucan Özgür. 2017. https://doi.org/10.1093/bioinformatics/btx238 BIOSSES : a semantic sentence similarity estimation system for the biomedical domain . Bioinformatics (Oxford, England), 33(14):i49--i58
-
[53]
Anders Søgaard. 2013. https://aclanthology.org/N13-1068/ Estimating effect size across datasets . In Proceedings of the 2013 Conference of the North American Chapter of the Association for Computational Linguistics : Human Language Technologies , pages 607--611, Atlanta, Georgia. Association for Computational Linguistics
2013
-
[54]
Anders Søgaard, Anders Johannsen, Barbara Plank, Dirk Hovy, and Hector Martínez Alonso. 2014. https://doi.org/10.3115/v1/W14-1601 What's in a p-value in NLP ? In Proceedings of the Eighteenth Conference on Computational Natural Language Learning , pages 1--10, Ann Arbor, Michigan. Association for Computational Linguistics
-
[55]
Team Olmo , Allyson Ettinger, Amanda Bertsch, Bailey Kuehl, David Graham, David Heineman, Dirk Groeneveld, Faeze Brahman, Finbarr Timbers, Hamish Ivison, Jacob Morrison, Jake Poznanski, Kyle Lo, Luca Soldaini, Matt Jordan, Mayee Chen, Michael Noukhovitch, Nathan Lambert, Pete Walsh, and 49 others. 2025. https://doi.org/10.48550/arXiv.2512.13961 Olmo 3 . A...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2512.13961 2025
-
[56]
Søren Vejlgaard Holm, Lars Kai Hansen, and Martin Carsten Nielsen. 2025. https://aclanthology.org/2025.nodalida-1.78/ Danoliteracy of Generative Large Language Models . In Proceedings of the Joint 25th Nordic Conference on Computational Linguistics and 11th Baltic Conference on Human Language Technologies ( NoDaLiDa / Baltic - HLT 2025) , pages 785--800, ...
2025
-
[57]
Henning Wachsmuth, Shahbaz Syed, and Benno Stein. 2018. https://doi.org/10.18653/v1/P18-1023 Retrieval of the best counterargument without prior topic knowledge . In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (volume 1: Long papers) , pages 241--251, Melbourne, Australia. Association for Computational Linguistics
-
[58]
David Wadden, Shanchuan Lin, Kyle Lo, Lucy Lu Wang, Madeleine van Zuylen, Arman Cohan, and Hannaneh Hajishirzi. 2020. https://doi.org/10.18653/v1/2020.emnlp-main.609 Fact or Fiction : Verifying Scientific Claims . In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing ( EMNLP ) , pages 7534--7550, Online. Association for...
-
[59]
Kexin Wang, Nils Reimers, and Iryna Gurevych. 2021. https://doi.org/10.18653/v1/2021.findings-emnlp.59 TSDAE : Using Transformer -based Sequential Denoising Auto - Encoder for Unsupervised Sentence Embedding Learning . In Findings of the Association for Computational Linguistics : EMNLP 2021 , pages 671--688, Punta Cana, Dominican Republic. Association fo...
-
[60]
Liang Wang, Nan Yang, Xiaolong Huang, Binxing Jiao, Linjun Yang, Daxin Jiang, Rangan Majumder, and Furu Wei. 2024 a . https://doi.org/10.48550/arXiv.2212.03533 Text Embeddings by Weakly - Supervised Contrastive Pre -training . ArXiv:2212.03533
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2212.03533 2024
-
[61]
Liang Wang, Nan Yang, Xiaolong Huang, Linjun Yang, Rangan Majumder, and Furu Wei. 2024 b . https://doi.org/10.18653/v1/2024.acl-long.642 Improving Text Embeddings with Large Language Models . In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics ( Volume 1: Long Papers ) , pages 11897--11916, Bangkok, Thailand. Associa...
-
[62]
Liang Wang, Nan Yang, Xiaolong Huang, Linjun Yang, Rangan Majumder, and Furu Wei. 2024 c . https://doi.org/10.48550/arXiv.2402.05672 Multilingual E5 Text Embeddings : A Technical Report . ArXiv:2402.05672
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2402.05672 2024
-
[63]
White, Theresa A
John S. White, Theresa A. O'Connell, and Francis E. O'Mara. 1994. https://aclanthology.org/1994.amta-1.25/ The ARPA MT Evaluation Methodologies : Evolution , Lessons , and Future Approaches . In Proceedings of the First Conference of the Association for Machine Translation in the Americas , Columbia, Maryland, USA
1994
-
[64]
Frank Wilcoxon. 1945. https://doi.org/10.2307/3001968 Individual Comparisons by Ranking Methods . Biometrics Bulletin, 1(6):80--83
-
[65]
Wei Xu, Chris Callison-Burch, and Bill Dolan. 2015. https://doi.org/10.18653/v1/S15-2001 SemEval -2015 task 1: Paraphrase and semantic similarity in Twitter ( PIT ) . In Proceedings of the 9th International Workshop on Semantic Evaluation ( SemEval 2015) , pages 1--11, Denver, Colorado. Association for Computational Linguistics
-
[66]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, and 41 others. 2025. https://doi.org/10.48550/arXiv.2505.09388 Qwen3 Technical Report . ArXiv:2505.09388
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2505.09388 2025
- [67]
- [68]
-
[69]
Xin Zhang, Yanzhao Zhang, Dingkun Long, Wen Xie, Ziqi Dai, Jialong Tang, Huan Lin, Baosong Yang, Pengjun Xie, Fei Huang, Meishan Zhang, Wenjie Li, and Min Zhang. 2024. https://doi.org/10.18653/v1/2024.emnlp-industry.103 mGTE : Generalized long-context text representation and reranking models for multilingual text retrieval . In Proceedings of the 2024 Con...
-
[70]
Yanzhao Zhang, Mingxin Li, Dingkun Long, Xin Zhang, Huan Lin, Baosong Yang, Pengjun Xie, An Yang, Dayiheng Liu, Junyang Lin, Fei Huang, and Jingren Zhou. 2025 c . https://doi.org/10.48550/arXiv.2506.05176 Qwen3 Embedding : Advancing Text Embedding and Reranking Through Foundation Models . ArXiv:2506.05176
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2506.05176 2025
- [71]
-
[72]
online" 'onlinestring :=
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[73]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.