VidPrism: Heterogeneous Mixture of Experts for Image-to-Video Transfer
Pith reviewed 2026-06-29 12:56 UTC · model grok-4.3
The pith
VidPrism deploys specialized experts in a heterogeneous MoE to prevent homogenization in video transfer from image models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
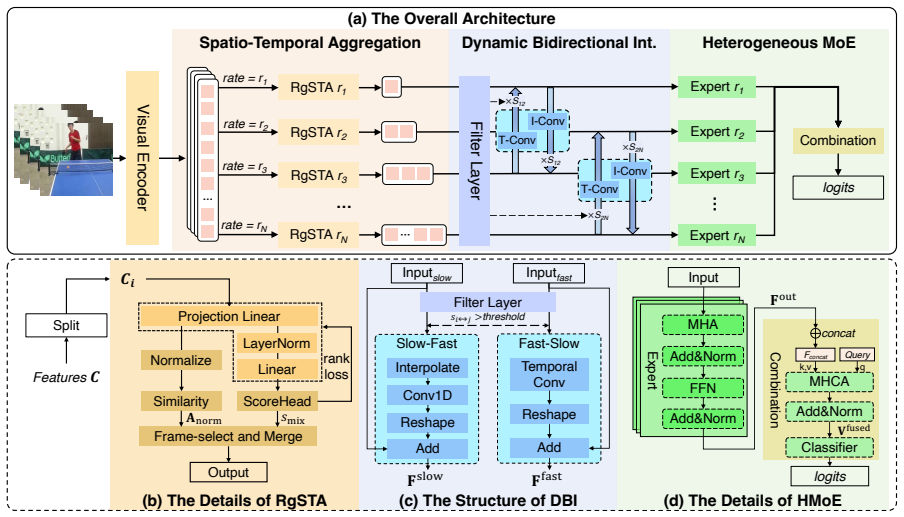
VidPrism is a heterogeneous temporal Mixture-of-Experts framework that assigns distinct roles to experts ranging from spatial understanding to temporal modeling, fed by content-aware multi-rate sampling streams and integrated via dynamic bidirectional fusion, achieving superior video representations.
What carries the argument
The heterogeneous temporal Mixture-of-Experts with content-aware multi-rate sampling module and dynamic bidirectional fusion mechanism.
Load-bearing premise
That deploying specialized experts with multi-rate inputs will overcome homogenization without creating new training instabilities or requiring heavy tuning.
What would settle it
Running the model on a benchmark and finding no performance gain over standard MoE or observing that experts produce similar outputs instead of distinct ones.
Figures



read the original abstract
With the rapid development of pre-training technologies, adapting large-scale Vision-Language Models (VLMs) for video understanding \emph{\ie} image-to-video transfer learning has become a dominant paradigm. To achieve superior performance, it raises as an effective strategy among recent advances to employ Mixture-of-Experts (MoE) to enhance VLMs' temporal modeling capabilities. However, conventional MoE designs suffer from expert homogenization, where all experts act as identical generalists, inefficiently learning spatio-temporal features from undifferentiated video streams. To overcome this problem, we propose VidPrism, a novel heterogeneous temporal Mixture-of-Experts framework. VidPrism pioneers a division of labor by deploying functionally specialized experts, each assuming a role ranging from spatial understanding to temporal modeling. To feed these specialists appropriately, we introduce a content-aware, multi-rate sampling module that dynamically generates streams ranging from semantically rich to motion-focused representations, providing specialized inputs for experts. Furthermore, a dynamic, bidirectional fusion mechanism enables synergistic information exchange between these pathways, leading to a comprehensive video representation. Extensive experiments on various video recognition benchmarks demonstrate that VidPrism achieves state-of-the-art performance and effectively fosters expert specialization. Our source code is available at \href{https://github.com/Lrrrr549/VidPrism.git}{https://github.com/Lrrrr549/VidPrism.git}.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes VidPrism, a heterogeneous temporal Mixture-of-Experts (MoE) architecture for image-to-video transfer in Vision-Language Models. It claims to overcome expert homogenization in standard MoE designs by deploying functionally specialized experts (spatial to temporal roles), a content-aware multi-rate sampling module that produces semantically rich to motion-focused streams, and a dynamic bidirectional fusion mechanism for synergistic exchange. The authors assert that extensive experiments show state-of-the-art results on video recognition benchmarks together with effective expert specialization, and release the source code.
Significance. If the central mechanism claims hold, the work could advance MoE usage in temporal video modeling by providing a concrete way to induce division of labor rather than homogenization. The public code release supports reproducibility and is a clear strength. However, the significance remains provisional given the absence of quantitative signatures for specialization in the presented material.
major comments (2)
- [Abstract] Abstract: the claim that VidPrism 'effectively fosters expert specialization' is load-bearing for the 'overcomes homogenization' thesis, yet the text supplies no quantitative signatures (routing entropy, per-expert task breakdown, or controlled ablation against a homogeneous MoE given identical streams) that would confirm the mechanism rather than capacity gains or routing changes.
- [Abstract] Abstract: the assertion of 'state-of-the-art performance' on 'various video recognition benchmarks' is presented without any numerical results, specific dataset names, or baseline comparisons, preventing assessment of whether the reported gains are attributable to the proposed heterogeneous design.
Simulated Author's Rebuttal
Thank you for the constructive review and for highlighting areas where the presentation can be strengthened. We address each major comment below and will update the manuscript to improve clarity and evidentiary support.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that VidPrism 'effectively fosters expert specialization' is load-bearing for the 'overcomes homogenization' thesis, yet the text supplies no quantitative signatures (routing entropy, per-expert task breakdown, or controlled ablation against a homogeneous MoE given identical streams) that would confirm the mechanism rather than capacity gains or routing changes.
Authors: We agree that the abstract itself does not contain these quantitative signatures. The body of the manuscript includes ablation studies and routing visualizations that illustrate differences in expert behavior under the heterogeneous design. To make the specialization claim more robust and directly responsive to the concern, we will add explicit quantitative metrics (routing entropy, per-expert breakdown, and a homogeneous-MoE control with matched streams) in the revised version. revision: yes
-
Referee: [Abstract] Abstract: the assertion of 'state-of-the-art performance' on 'various video recognition benchmarks' is presented without any numerical results, specific dataset names, or baseline comparisons, preventing assessment of whether the reported gains are attributable to the proposed heterogeneous design.
Authors: The abstract is intentionally concise and therefore omits specific numbers and dataset names. The experimental section of the manuscript reports results on the relevant benchmarks together with baseline comparisons. To allow readers to evaluate the abstract claim immediately, we will revise the abstract to include key numerical results, dataset references, and a brief statement on the role of the heterogeneous design. revision: yes
Circularity Check
No circularity: empirical architecture proposal with no derivation chain or fitted predictions shown
full rationale
The paper describes a new MoE architecture (specialized experts + multi-rate sampling + bidirectional fusion) and asserts SOTA results plus specialization from experiments. No equations, no parameter-fitting steps, no predictions of quantities from fitted inputs, and no self-citation chains are present in the supplied text. The central claim rests on empirical validation rather than any closed mathematical loop, making the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Vivit: A video vi- sion transformer
Anurag Arnab, Mostafa Dehghani, Georg Heigold, Chen Sun, Mario Lu ˇci´c, and Cordelia Schmid. Vivit: A video vi- sion transformer. InICCV, pages 6836–6846, 2021. 2
2021
-
[2]
Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E Hinton. Layer normalization.arXiv:1607.06450, 2016. 3
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[3]
Frozen feature augmentation for few-shot image classification
Andreas B ¨ar, Neil Houlsby, Mostafa Dehghani, and Manoj Kumar. Frozen feature augmentation for few-shot image classification. InCVPR, pages 16046–16057, 2024. 1
2024
-
[4]
Is space-time attention all you need for video understanding? InICML, page 4, 2021
Gedas Bertasius, Heng Wang, and Lorenzo Torresani. Is space-time attention all you need for video understanding? InICML, page 4, 2021. 2
2021
-
[5]
Quo vadis, action recognition? a new model and the kinetics dataset
Joao Carreira and Andrew Zisserman. Quo vadis, action recognition? a new model and the kinetics dataset. InCVPR, pages 6299–6308, 2017. 2, 6
2017
-
[6]
Ef- ficient transfer learning for video-language foundation mod- els
Haoxing Chen, Zizheng Huang, Yan Hong, Yanshuo Wang, Zhongcai Lyu, Zhuoer Xu, Jun Lan, and Zhangxuan Gu. Ef- ficient transfer learning for video-language foundation mod- els. InCVPR, pages 29129–29138, 2025. 1, 2, 6, 7
2025
-
[7]
Ost: Refining text knowledge with optimal spatio-temporal descriptor for general video recog- nition
Tongjia Chen, Hongshan Yu, Zhengeng Yang, Zechuan Li, Wei Sun, and Chen Chen. Ost: Refining text knowledge with optimal spatio-temporal descriptor for general video recog- nition. InCVPR, pages 18888–18898, 2024. 6, 7
2024
-
[8]
Multiscale vision transformers
Haoqi Fan, Bo Xiong, Karttikeya Mangalam, Yanghao Li, Zhicheng Yan, Jitendra Malik, and Christoph Feichtenhofer. Multiscale vision transformers. InICCV, pages 6824–6835,
-
[9]
Convolutional two-stream network fusion for video action recognition
Christoph Feichtenhofer, Axel Pinz, and Andrew Zisserman. Convolutional two-stream network fusion for video action recognition. InCVPR, pages 1933–1941, 2016. 2
1933
-
[10]
Slowfast networks for video recognition
Christoph Feichtenhofer, Haoqi Fan, Jitendra Malik, and Kaiming He. Slowfast networks for video recognition. In ICCV, pages 6202–6211, 2019. 2
2019
-
[11]
Separate visual pathways for perception and action.Trends in neurosciences, 15(1):20–25, 1992
Melvyn A Goodale and A David Milner. Separate visual pathways for perception and action.Trends in neurosciences, 15(1):20–25, 1992. 2
1992
-
[12]
The” something something” video database for learning and evaluating visual common sense
Raghav Goyal, Samira Ebrahimi Kahou, Vincent Michal- ski, Joanna Materzynska, Susanne Westphal, Heuna Kim, Valentin Haenel, Ingo Fruend, Peter Yianilos, Moritz Mueller-Freitag, et al. The” something something” video database for learning and evaluating visual common sense. InICCV, pages 5842–5850, 2017. 6
2017
-
[13]
Focus: Knowledge-enhanced adaptive visual compression for few- shot whole slide image classification
Zhengrui Guo, Conghao Xiong, Jiabo Ma, Qichen Sun, Lishuang Feng, Jinzhuo Wang, and Hao Chen. Focus: Knowledge-enhanced adaptive visual compression for few- shot whole slide image classification. InCVPR, pages 15590–15600, 2025. 1
2025
-
[14]
Tube convolu- tional neural network (t-cnn) for action detection in videos
Rui Hou, Chen Chen, and Mubarak Shah. Tube convolu- tional neural network (t-cnn) for action detection in videos. InICCV, pages 5822–5831, 2017. 2
2017
-
[15]
Prompting visual-language models for efficient video understanding
Chen Ju, Tengda Han, Kunhao Zheng, Ya Zhang, and Weidi Xie. Prompting visual-language models for efficient video understanding. InECCV, pages 105–124. Springer, 2022. 7
2022
-
[16]
Coarse-fine net- works for temporal activity detection in videos
Kumara Kahatapitiya and Michael S Ryoo. Coarse-fine net- works for temporal activity detection in videos. InCVPR, pages 8385–8394, 2021. 2
2021
-
[17]
Kuehne, H
H. Kuehne, H. Jhuang, E. Garrote, T. Poggio, and T. Serre. Hmdb: A large video database for human motion recogni- tion. InICCV, pages 2556–2563, 2011. 6
2011
-
[18]
Tsm: Temporal shift module for efficient video understanding
Ji Lin, Chuang Gan, and Song Han. Tsm: Temporal shift module for efficient video understanding. InICCV, pages 7083–7093, 2019. 2
2019
-
[19]
Frozen clip models are efficient video learners
Ziyi Lin, Shijie Geng, Renrui Zhang, Peng Gao, Gerard De Melo, Xiaogang Wang, Jifeng Dai, Yu Qiao, and Hong- sheng Li. Frozen clip models are efficient video learners. In ECCV, pages 388–404. Springer, 2022. 2
2022
-
[20]
Revisiting temporal modeling for clip-based image-to-video knowledge transferring
Ruyang Liu, Jingjia Huang, Ge Li, Jiashi Feng, Xinglong Wu, and Thomas H Li. Revisiting temporal modeling for clip-based image-to-video knowledge transferring. InCVPR, pages 6555–6564, 2023. 6
2023
-
[21]
Video swin transformer
Ze Liu, Jia Ning, Yue Cao, Yixuan Wei, Zheng Zhang, Stephen Lin, and Han Hu. Video swin transformer. InCVPR, pages 3202–3211, 2022. 2
2022
-
[22]
Muhammad Maaz, Hanoona Rasheed, Salman Khan, and Fa- had Khan. Videogpt+: Integrating image and video encoders for enhanced video understanding.arXiv:2406.09418, 2024. 2
-
[23]
Expanding language-image pretrained models for gen- eral video recognition
Bolin Ni, Houwen Peng, Minghao Chen, Songyang Zhang, Gaofeng Meng, Jianlong Fu, Shiming Xiang, and Haibin Ling. Expanding language-image pretrained models for gen- eral video recognition. InECCV, pages 1–18. Springer,
-
[24]
St-adapter: Parameter-efficient image-to-video transfer learning.NeurIPS, 35:26462–26477, 2022
Junting Pan, Ziyi Lin, Xiatian Zhu, Jing Shao, and Hong- sheng Li. St-adapter: Parameter-efficient image-to-video transfer learning.NeurIPS, 35:26462–26477, 2022. 2, 6
2022
-
[25]
Dual- path adaptation from image to video transformers
Jungin Park, Jiyoung Lee, and Kwanghoon Sohn. Dual- path adaptation from image to video transformers. InCVPR, pages 2203–2213, 2023. 6
2023
-
[26]
Learn- ing transferable visual models from natural language super- vision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learn- ing transferable visual models from natural language super- vision. InICML, pages 8748–8763. PmLR, 2021. 1, 2, 6, 7
2021
-
[27]
Fine-tuned clip models are efficient video learners
Hanoona Rasheed, Muhammad Uzair Khattak, Muhammad Maaz, Salman Khan, and Fahad Shahbaz Khan. Fine-tuned clip models are efficient video learners. InCVPR, pages 6545–6554, 2023. 7
2023
-
[28]
Slow-fast architecture for video multi-modal large lan- guage models.arXiv:2504.01328, 2025
Min Shi, Shihao Wang, Chieh-Yun Chen, Jitesh Jain, Kai Wang, Junjun Xiong, Guilin Liu, Zhiding Yu, and Humphrey Shi. Slow-fast architecture for video multi-modal large lan- guage models.arXiv:2504.01328, 2025. 2
-
[29]
Two-stream convolutional networks for action recognition in videos
Karen Simonyan and Andrew Zisserman. Two-stream convolutional networks for action recognition in videos. NeurIPS, 27, 2014. 2
2014
-
[30]
UCF101: A Dataset of 101 Human Actions Classes From Videos in The Wild
Khurram Soomro, Amir Roshan Zamir, and Mubarak Shah. Ucf101: A dataset of 101 human actions classes from videos in the wild.arXiv:1212.0402, 2012. 1, 6
work page internal anchor Pith review Pith/arXiv arXiv 2012
-
[31]
V Team, Wenyi Hong, Wenmeng Yu, et al. Glm-4.5 v and glm-4.1 v-thinking: Towards versatile multimodal reason- ing with scalable reinforcement learning.arXiv:2507.01006,
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
A closer look at spatiotemporal convolutions for action recognition
Du Tran, Heng Wang, Lorenzo Torresani, Jamie Ray, Yann LeCun, and Manohar Paluri. A closer look at spatiotemporal convolutions for action recognition. InCVPR, pages 6450– 6459, 2018. 2
2018
-
[33]
Step-3 is large yet afford- able: Model-system co-design for cost-effective decoding
Bin Wang, Bojun Wang, Changyi Wan, Guanzhe Huang, Hanpeng Hu, Haonan Jia, Hao Nie, Mingliang Li, Nuo Chen, Siyu Chen, et al. Step-3 is large yet afford- able: Model-system co-design for cost-effective decoding. arXiv:2507.19427, 2025. 2
-
[34]
Action recognition with improved trajectories
Heng Wang and Cordelia Schmid. Action recognition with improved trajectories. InICCV, pages 3551–3558, 2013. 2
2013
-
[35]
Grounded-videollm: Sharpening fine- grained temporal grounding in video large language models
Haibo Wang, Zhiyang Xu, Yu Cheng, Shizhe Diao, Yu- fan Zhou, Yixin Cao, Qifan Wang, Weifeng Ge, and Lifu Huang. Grounded-videollm: Sharpening fine- grained temporal grounding in video large language models. arXiv:2410.03290, 2024. 2
-
[36]
Temporal segment networks: Towards good practices for deep action recogni- tion
Limin Wang, Yuanjun Xiong, Zhe Wang, Yu Qiao, Dahua Lin, Xiaoou Tang, and Luc Van Gool. Temporal segment networks: Towards good practices for deep action recogni- tion. InECCV, pages 20–36. Springer, 2016. 2
2016
-
[37]
Videomae v2: Scaling video masked autoencoders with dual masking
Limin Wang, Bingkun Huang, Zhiyu Zhao, Zhan Tong, Yi- nan He, Yi Wang, Yali Wang, and Yu Qiao. Videomae v2: Scaling video masked autoencoders with dual masking. In CVPR, pages 14549–14560, 2023. 7
2023
-
[38]
arXiv preprint arXiv:2109.08472 (2021)
Mengmeng Wang, Jiazheng Xing, and Yong Liu. Ac- tionclip: A new paradigm for video action recognition. arXiv:2109.08472, 2021. 2, 6, 7
-
[39]
M2-clip: A multimodal, multi-task adapting framework for video action recognition.AAAI, 2024
Mengmeng Wang, Jiazheng Xing, Boyuan Jiang, Jun Chen, Jianbiao Mei, Xingxing Zuo, Guang Dai, Jingdong Wang, and Yong Liu. M2-clip: A multimodal, multi-task adapting framework for video action recognition.AAAI, 2024. 6
2024
-
[40]
Action detail matters: Refining video recognition with local action queries
Mengmeng Wang, Zeyi Huang, Xiangjie Kong, Guojiang Shen, Guang Dai, Jingdong Wang, and Yong Liu. Action detail matters: Refining video recognition with local action queries. InCVPR, pages 19132–19142, 2025. 2, 6
2025
-
[41]
Temporal pyramid pooling-based convolutional neural network for action recognition.IEEE TCSVT, 27(12):2613–2622, 2016
Peng Wang, Yuanzhouhan Cao, Chunhua Shen, Lingqiao Liu, and Heng Tao Shen. Temporal pyramid pooling-based convolutional neural network for action recognition.IEEE TCSVT, 27(12):2613–2622, 2016. 2
2016
-
[42]
Internvid: A large-scale video-text dataset for multimodal understanding and generation.ICLR, 2023
Yi Wang, Yinan He, Yizhuo Li, Kunchang Li, Jiashuo Yu, Xin Ma, Xinhao Li, Guo Chen, Xinyuan Chen, Yaohui Wang, et al. Internvid: A large-scale video-text dataset for multimodal understanding and generation.ICLR, 2023. 1, 2, 7
2023
-
[43]
InternVideo2.5: Empowering Video MLLMs with Long and Rich Context Modeling
Yi Wang, Xinhao Li, Ziang Yan, Yinan He, Jiashuo Yu, Xi- angyu Zeng, Chenting Wang, Changlian Ma, Haian Huang, Jianfei Gao, et al. Internvideo2. 5: Empowering video mllms with long and rich context modeling.arXiv:2501.12386,
work page internal anchor Pith review Pith/arXiv arXiv
-
[44]
Vita-clip: Video and text adaptive clip via multimodal prompting
Syed Talal Wasim, Muzammal Naseer, Salman Khan, Fa- had Shahbaz Khan, and Mubarak Shah. Vita-clip: Video and text adaptive clip via multimodal prompting. InCVPR, pages 23034–23044, 2023. 6
2023
-
[45]
Revisiting clas- sifier: Transferring vision-language models for video recog- nition
Wenhao Wu, Zhun Sun, and Wanli Ouyang. Revisiting clas- sifier: Transferring vision-language models for video recog- nition. InAAAI, pages 2847–2855, 2023. 1, 6
2023
-
[46]
Videoclip: Contrastive pre-training for zero-shot video-text understanding
Hu Xu, Gargi Ghosh, Po-Yao Huang, Dmytro Okhonko, Armen Aghajanyan, Florian Metze, Luke Zettlemoyer, and Christoph Feichtenhofer. Videoclip: Contrastive pre-training for zero-shot video-text understanding. InEMNLP, 2021. 1, 2
2021
-
[47]
Mingze Xu, Mingfei Gao, Zhe Gan, Hong-You Chen, Zhengfeng Lai, Haiming Gang, Kai Kang, and Afshin De- hghan. Slowfast-llava: A strong training-free baseline for video large language models.arXiv:2407.15841, 2024. 2
-
[48]
Mingze Xu, Mingfei Gao, Shiyu Li, Jiasen Lu, Zhe Gan, Zhengfeng Lai, Meng Cao, Kai Kang, Yinfei Yang, and Afshin Dehghan. Slowfast-llava-1.5: A family of token- efficient video large language models for long-form video understanding.arXiv:2503.18943, 2025. 2
-
[49]
Larger norm more transferable: An adaptive feature norm approach for unsupervised domain adaptation
Ruijia Xu, Guanbin Li, Jihan Yang, and Liang Lin. Larger norm more transferable: An adaptive feature norm approach for unsupervised domain adaptation. InICCV, pages 1426– 1435, 2019. 3
2019
-
[50]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chen- gen Huang, Chenxu Lv, et al. Qwen3 technical report. arXiv:2505.09388, 2025. 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[51]
Temporal pyramid network for action recognition
Ceyuan Yang, Yinghao Xu, Jianping Shi, Bo Dai, and Bolei Zhou. Temporal pyramid network for action recognition. In CVPR, pages 591–600, 2020. 2
2020
-
[52]
Aim: Adapting image models for efficient video action recognition.ICLR, 2023
Taojiannan Yang, Yi Zhu, Yusheng Xie, Aston Zhang, Chen Chen, and Mu Li. Aim: Adapting image models for efficient video action recognition.ICLR, 2023. 2, 6
2023
-
[53]
Rethink- ing the smaller-norm-less-informative assumption in channel pruning of convolution layers.ICLR, 2018
Jianbo Ye, Xin Lu, Zhe Lin, and James Z Wang. Rethink- ing the smaller-norm-less-informative assumption in channel pruning of convolution layers.ICLR, 2018. 3
2018
-
[54]
Mote: Reconciling generalization with specialization for visual-language to video knowledge transfer.NeurIPS, 37: 55403–55424, 2024
Minghao Zhu, Zhengpu Wang, Mengxian Hu, Ronghao Dang, Xiao Lin, Xun Zhou, Chengju Liu, and Qijun Chen. Mote: Reconciling generalization with specialization for visual-language to video knowledge transfer.NeurIPS, 37: 55403–55424, 2024. 1, 2, 6, 7
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.